Beyond the Frame: Generating 360 Panoramic Videos from Perspective Videos
Pith reviewed 2026-05-22 19:50 UTC · model grok-4.3
The pith
A model generates realistic and coherent 360-degree videos from ordinary perspective videos by training on filtered online 360 pairs with geometry- and motion-aware operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By curating high-quality pairwise training data from online 360 videos through a filtering pipeline and introducing geometry- and motion-aware operations, the model produces realistic 360 panoramic videos that remain spatially and temporally consistent with the given perspective input.
What carries the argument
A series of geometry- and motion-aware operations that enforce spatial layout understanding and object dynamics during the learning of perspective-to-360 mappings.
If this is right
- The generated panoramas can be used to stabilize the original perspective video by providing a wider consistent reference.
- Viewpoint control becomes possible, allowing users to change the virtual camera direction within the generated 360 output.
- Interactive visual question answering can operate on the full surrounding scene rather than the limited original frame.
Where Pith is reading between the lines
- The same data-curation and operation approach might be adapted to generate 360 content for virtual-reality playback from consumer phone videos.
- Applying the method to dynamic scenes such as sports or driving could surface previously hidden elements outside the original camera cone.
- A natural next test is to measure how well the model handles rapid camera motion or lighting changes that were not dominant in the filtered training pairs.
Load-bearing premise
The high-quality data filtering pipeline successfully curates pairwise training data from online 360 videos that accurately captures the required spatial and temporal mappings without significant biases or inconsistencies.
What would settle it
Generate 360 videos from perspective inputs of scenes that also have real captured 360 ground truth and check whether object positions and trajectories remain consistent when the output is compared directly to the true 360 recording.
Figures















read the original abstract
360{\deg} videos have emerged as a promising medium to represent our dynamic visual world. Compared to the "tunnel vision" of standard cameras, their borderless field of view offers a more complete perspective of our surroundings. While existing video models excel at producing standard videos, their ability to generate full panoramic videos remains elusive. In this paper, we investigate the task of video-to-360{\deg} generation: given a perspective video as input, our goal is to generate a full panoramic video that is consistent with the original video. Unlike conventional video generation tasks, the output's field of view is significantly larger, and the model is required to have a deep understanding of both the spatial layout of the scene and the dynamics of objects to maintain spatio-temporal consistency. To address these challenges, we first leverage the abundant 360{\deg} videos available online and develop a high-quality data filtering pipeline to curate pairwise training data. We then carefully design a series of geometry- and motion-aware operations to facilitate the learning process and improve the quality of 360{\deg} video generation. Experimental results demonstrate that our model can generate realistic and coherent 360{\deg} videos from in-the-wild perspective video. In addition, we showcase its potential applications, including video stabilization, camera viewpoint control, and interactive visual question answering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a method for video-to-360° generation: given a perspective video input, produce a full panoramic video that maintains spatio-temporal consistency. The approach first curates pairwise training data from abundant online 360° videos via a high-quality filtering pipeline, then applies a series of geometry- and motion-aware operations to facilitate learning. The central claim is that the resulting model generates realistic and coherent 360° videos from in-the-wild perspective inputs, with additional demonstrations in applications such as video stabilization, viewpoint control, and interactive VQA.
Significance. If the results hold, the work opens a new direction in video generation by addressing the challenge of expanding limited field-of-view inputs to borderless panoramic outputs. The use of online 360° data for scalable training is a practical strength, and the geometry/motion-aware design directly targets the spatial-layout and dynamics requirements of the task. Successful validation would support downstream uses in immersive media and video editing.
major comments (2)
- [§3] §3 (Data Filtering Pipeline): The pipeline is described only via high-level steps for curating pairwise perspective-360 training data from online sources. No quantitative checks are reported (e.g., reprojection error, temporal flow consistency, motion statistics, or bias analysis on selected clips). Because the central claim of realistic and coherent 360° output depends on these pairs faithfully encoding the required spatial expansion and temporal dynamics, this omission is load-bearing; unmeasured biases could embed into the learned operations.
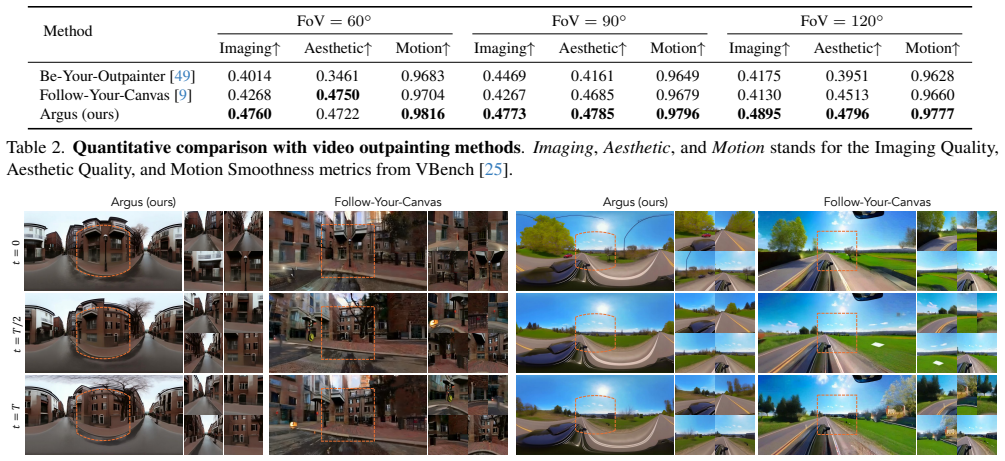
- [§4] §4 (Experiments): The experimental section asserts that the model produces realistic and coherent 360° videos, yet provides no quantitative metrics, error analysis, or detailed comparisons against baselines for panorama quality, temporal consistency, or out-of-frame hallucination. This weakens support for the main claim relative to the task's difficulty.
minor comments (2)
- [Figures 4-6] Figure captions and axis labels in the qualitative results could more explicitly annotate the input perspective region versus the generated panoramic extension to aid reader interpretation.
- [§3.3] Ensure all symbols used in the geometry-aware operations (e.g., projection mappings) are defined at first use in §3.3.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the significance of addressing video-to-360 generation. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§3] §3 (Data Filtering Pipeline): The pipeline is described only via high-level steps for curating pairwise perspective-360 training data from online sources. No quantitative checks are reported (e.g., reprojection error, temporal flow consistency, motion statistics, or bias analysis on selected clips). Because the central claim of realistic and coherent 360° output depends on these pairs faithfully encoding the required spatial expansion and temporal dynamics, this omission is load-bearing; unmeasured biases could embed into the learned operations.
Authors: We agree that quantitative validation of the data curation pipeline would strengthen the manuscript. In the revised version we will expand §3 with a new subsection reporting average reprojection error after alignment, temporal flow consistency scores computed via optical flow, motion magnitude statistics, and a brief bias analysis across scene categories in the selected clips. These additions will directly address the concern that unmeasured issues could affect the learned operations. revision: yes
-
Referee: [§4] §4 (Experiments): The experimental section asserts that the model produces realistic and coherent 360° videos, yet provides no quantitative metrics, error analysis, or detailed comparisons against baselines for panorama quality, temporal consistency, or out-of-frame hallucination. This weakens support for the main claim relative to the task's difficulty.
Authors: We acknowledge that the current experiments are primarily qualitative. Because this is a newly defined task, established quantitative benchmarks do not yet exist. In the revision we will add quantitative support by reporting FID scores for visual realism, optical-flow-based temporal consistency errors, and a small-scale user study on perceived coherence and hallucination quality. We will also include comparisons against adapted baselines where feasible. revision: yes
Circularity Check
No significant circularity; derivation relies on external data curation and independent model design
full rationale
The paper's core pipeline starts from abundant external online 360° videos, applies a described filtering process to produce pairwise training data, then introduces geometry- and motion-aware operations for learning. No self-definitional mappings, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described chain. The output generation is trained rather than algebraically forced from the inputs, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Abundant online 360 videos can be filtered into high-quality pairwise perspective-to-panoramic training data that supports learning consistent generation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first leverage the abundant 360° videos available online and develop a high-quality data filtering pipeline to curate pairwise training data. We then carefully design a series of geometry- and motion-aware operations...
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
View-Based Frame Alignment... Blended Decoding... Long Video Generation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
360-degree image completion by two-stage condi- tional gans
Naofumi Akimoto, Seito Kasai, Masaki Hayashi, and Yoshim- itsu Aoki. 360-degree image completion by two-stage condi- tional gans. In ICIP, 2019. 2
work page 2019
-
[2]
Stochastic variational video prediction
Mohammad Babaeizadeh, Chelsea Finn, Dumitru Erhan, Roy H Campbell, and Sergey Levine. Stochastic variational video prediction. In ICLR, 2018. 2
work page 2018
-
[3]
Extreme rotation estimation in the wild
Hana Bezalel, Dotan Ankri, Ruojin Cai, and Hadar Averbuch-Elor. Extreme rotation estimation in the wild. arXiv:2411.07096, 2024. 1
-
[4]
ipoke: Poking a still image for controlled stochastic video synthesis
Andreas Blattmann, Timo Milbich, Michael Dorkenwald, and Bj¨orn Ommer. ipoke: Poking a still image for controlled stochastic video synthesis. In ICCV, 2021. 2
work page 2021
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv:2311.15127, 2023. 1, 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. In CVPR, 2023. 1
work page 2023
-
[7]
Extreme rotation estimation using dense cor- relation volumes
Ruojin Cai, Bharath Hariharan, Noah Snavely, and Hadar Averbuch-Elor. Extreme rotation estimation using dense cor- relation volumes. In CVPR, 2021. 1
work page 2021
-
[8]
Im- proved conditional vrnns for video prediction
Lluis Castrejon, Nicolas Ballas, and Aaron Courville. Im- proved conditional vrnns for video prediction. In ICCV, 2019. 2
work page 2019
-
[9]
Follow-your-canvas: Higher-resolution video outpainting with extensive content generation
Qihua Chen, Yue Ma, Hongfa Wang, Junkun Yuan, Wenzhe Zhao, Qi Tian, Hongmei Wang, Shaobo Min, Qifeng Chen, and Wei Liu. Follow-your-canvas: Higher- resolution video outpainting with extensive content genera- tion. arXiv:2409.01055, 2024. 2, 5, 6, 3
-
[10]
On the importance of noise scheduling for diffu- sion models
Ting Chen. On the importance of noise scheduling for diffu- sion models. arXiv:2301.10972, 2023. 6, 2
-
[11]
Latentpaint: Image inpainting in latent space with diffusion models
Ciprian Corneanu, Raghudeep Gadde, and Aleix M Martinez. Latentpaint: Image inpainting in latent space with diffusion models. In WACV, 2024. 2
work page 2024
-
[12]
Complete and temporally consistent video out- painting
Lo¨ıc Dehan, Wiebe Van Ranst, Patrick Vandewalle, and Toon Goedem´e. Complete and temporally consistent video out- painting. In CVPR, 2022. 2, 3
work page 2022
-
[13]
Stochastic video generation with a learned prior
Emily Denton and Rob Fergus. Stochastic video generation with a learned prior. In ICML, 2018. 2
work page 2018
-
[14]
Stochastic image-to-video synthesis using cinns
Michael Dorkenwald, Timo Milbich, Andreas Blattmann, Robin Rombach, Konstantinos G Derpanis, and Bjorn Ommer. Stochastic image-to-video synthesis using cinns. In CVPR,
-
[15]
Hierar- chical masked 3d diffusion model for video outpainting
Fanda Fan, Chaoxu Guo, Litong Gong, Biao Wang, Tiezheng Ge, Yuning Jiang, Chunjie Luo, and Jianfeng Zhan. Hierar- chical masked 3d diffusion model for video outpainting. In ACM MM, 2023. 2
work page 2023
-
[16]
Two-frame motion estimation based on polynomial expansion
Gunnar Farneb¨ack. Two-frame motion estimation based on polynomial expansion. In Image Analysis, 2003. 1
work page 2003
-
[17]
Long video generation with time-agnostic vqgan and time-sensitive transformer
Songwei Ge, Thomas Hayes, Harry Yang, Xi Yin, Guan Pang, David Jacobs, Jia-Bin Huang, and Devi Parikh. Long video generation with time-agnostic vqgan and time-sensitive transformer. In ECCV, 2022. 2
work page 2022
-
[18]
Auto- directed video stabilization with robust l1 optimal camera paths
Matthias Grundmann, Vivek Kwatra, and Irfan Essa. Auto- directed video stabilization with robust l1 optimal camera paths. In CVPR, 2011. 4
work page 2011
-
[19]
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yao- hui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. In ICLR, 2024. 3
work page 2024
-
[20]
Rv-gan: Recurrent gan for unconditional video generation
Sonam Gupta, Arti Keshari, and Sukhendu Das. Rv-gan: Recurrent gan for unconditional video generation. In CVPR,
-
[21]
Venhancer: Generative space-time enhancement for video generation
Jingwen He, Tianfan Xue, Dongyang Liu, Xinqi Lin, Peng Gao, Dahua Lin, Yu Qiao, Wanli Ouyang, and Ziwei Liu. Venhancer: Generative space-time enhancement for video generation. arXiv:2407.07667, 2024. 2
-
[22]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion mod- els. arXiv:2210.02303, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Cascaded diffusion models for high fidelity image generation
Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation. JMLR, 2022. 2, 3
work page 2022
-
[24]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. In NeurIPS, 2022. 1, 2
work page 2022
-
[25]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. In CVPR, 2024. 4, 5, 6, 2
work page 2024
-
[26]
Cubediff: Repurposing diffusion-based image models for panorama generation
Nikolai Kalischek, Michael Oechsle, Fabian Manhardt, Philipp Henzler, Konrad Schindler, and Federico Tombari. Cubediff: Repurposing diffusion-based image models for panorama generation. In ICLR, 2025. 2
work page 2025
-
[27]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In NeurIPS, 2022. 3, 4
work page 2022
-
[28]
Megasam: Accurate, fast, and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holyn- ski, and Noah Snavely. Megasam: Accurate, fast, and robust structure and motion from casual dynamic videos. arXiv:2412.04463, 2024. 5, 7, 2 9
-
[29]
Bundled camera paths for video stabilization
Shuaicheng Liu, Lu Yuan, Ping Tan, and Jian Sun. Bundled camera paths for video stabilization. ACM TOG, 2013. 7, 8
work page 2013
-
[30]
Transformation-based adversarial video prediction on large- scale data
Pauline Luc, Aidan Clark, Sander Dieleman, Diego de Las Casas, Yotam Doron, Albin Cassirer, and Karen Simonyan. Transformation-based adversarial video prediction on large- scale data. arXiv:2003.04035, 2020. 2
-
[31]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In CVPR,
-
[32]
Vidpanos: Generative panoramic videos from casual panning videos
Jingwei Ma, Erika Lu, Roni Paiss, Shiran Zada, Aleksander Holynski, Tali Dekel, Brian Curless, Michael Rubinstein, and Forrester Cole. Vidpanos: Generative panoramic videos from casual panning videos. In SIGGRAPH Asia, 2024. 2
work page 2024
-
[33]
Bips: Bi-modal in- door panorama synthesis via residual depth-aided adversarial learning
Changgyoon Oh, Wonjune Cho, Yujeong Chae, Daehee Park, Lin Wang, and Kuk-Jin Yoon. Bips: Bi-modal in- door panorama synthesis via residual depth-aided adversarial learning. In ECCV, 2022. 2
work page 2022
-
[34]
Understanding 3d object interaction from a single image
Shengyi Qian and David F Fouhey. Understanding 3d object interaction from a single image. In CVPR, 2023. 6, 2, 3
work page 2023
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021. 3
work page 2021
-
[36]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022. 2, 3
work page 2022
- [37]
-
[38]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In SIG- GRAPH, 2022. 2
work page 2022
-
[39]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. In ICLR, 2023. 1, 2
work page 2023
-
[40]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In ICLR, 2021. 6
work page 2021
-
[41]
Transnet v2: An effective deep network architecture for fast shot transition detection
Tom´as Soucek and Jakub Lokoc. Transnet v2: An effective deep network architecture for fast shot transition detection. In ACM MM, 2024. 1
work page 2024
-
[42]
Imagine360: Immersive 360 video generation from perspective anchor
Jing Tan, Shuai Yang, Tong Wu, Jingwen He, Yuwei Guo, Ziwei Liu, and Dahua Lin. Imagine360: Immersive 360 video generation from perspective anchor. arXiv:2412.03552, 2024. 2
-
[43]
Mvdiffusion: Enabling holistic multi- view image generation with correspondence-aware diffusion
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Furukawa. Mvdiffusion: Enabling holistic multi- view image generation with correspondence-aware diffusion. In NeurIPS, 2023. 2
work page 2023
-
[44]
A good image generator is what you need for high-resolution video synthesis
Yu Tian, Jian Ren, Menglei Chai, Kyle Olszewski, Xi Peng, Dimitris N Metaxas, and Sergey Tulyakov. A good image generator is what you need for high-resolution video synthesis. In ICLR, 2021. 2
work page 2021
-
[45]
Mocogan: Decomposing motion and content for video generation
Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. Mocogan: Decomposing motion and content for video generation. In CVPR, 2018. 2
work page 2018
-
[46]
Fvd: A new metric for video generation
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Rapha¨el Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. In ICLR, 2019. 6, 2
work page 2019
-
[47]
Gen- erating videos with scene dynamics
Carl V ondrick, Hamed Pirsiavash, and Antonio Torralba. Gen- erating videos with scene dynamics. In NeurIPS, 2016. 2
work page 2016
-
[48]
From an image to a scene: Learning to imagine the world from a million 360° videos
Matthew Wallingford, Anand Bhattad, Aditya Kusupati, Vivek Ramanujan, Matt Deitke, Aniruddha Kembhavi, Roozbeh Mottaghi, Wei-Chiu Ma, and Ali Farhadi. From an image to a scene: Learning to imagine the world from a million 360° videos. In NeurIPS, 2024. 3, 1
work page 2024
-
[49]
Be- your-outpainter: Mastering video outpainting through input- specific adaptation
Fu-Yun Wang, Xiaoshi Wu, Zhaoyang Huang, Xiaoyu Shi, Dazhong Shen, Guanglu Song, Yu Liu, and Hongsheng Li. Be- your-outpainter: Mastering video outpainting through input- specific adaptation. In ECCV, 2024. 2, 5, 6, 3
work page 2024
-
[50]
360dvd: Controllable panorama video generation with 360-degree video diffusion model
Qian Wang et al. 360dvd: Controllable panorama video generation with 360-degree video diffusion model. In CVPR,
-
[51]
Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms
Yunbo Wang, Mingsheng Long, Jianmin Wang, Zhifeng Gao, and Philip S Yu. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. In NeurIPS,
-
[52]
Biomechanics and motor control of human movement
David A Winter. Biomechanics and motor control of human movement. John wiley & sons, 2009. 4
work page 2009
-
[53]
Godiva: Generating open-domain videos from natural descriptions
Chenfei Wu, Lun Huang, Qianxi Zhang, Binyang Li, Lei Ji, Fan Yang, Guillermo Sapiro, and Nan Duan. Godiva: Generating open-domain videos from natural descriptions. arXiv:2104.14806, 2021. 2
-
[54]
N ¨uwa: Visual synthesis pre- training for neural visual world creation
Chenfei Wu, Jian Liang, Lei Ji, Fan Yang, Yuejian Fang, Daxin Jiang, and Nan Duan. N ¨uwa: Visual synthesis pre- training for neural visual world creation. In ECCV, 2022. 2
work page 2022
-
[55]
Panodif- fusion: 360-degree panorama outpainting via diffusion
Tianhao Wu, Chuanxia Zheng, and Tat-Jen Cham. Panodif- fusion: 360-degree panorama outpainting via diffusion. In ICLR, 2023. 2, 4, 5, 6, 3
work page 2023
-
[56]
Recognizing scene viewpoint using panoramic place representation
Jianxiong Xiao, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Recognizing scene viewpoint using panoramic place representation. In CVPR, 2012. 1
work page 2012
-
[57]
VideoGPT: Video Generation using VQ-VAE and Transformers
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srini- vas. Videogpt: Video generation using vq-vae and transform- ers. arXiv:2104.10157, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[58]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffu- sion models with an expert transformer. arXiv:2408.06072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Dptext-detr: Towards better scene text detection with dynamic points in transformer
Maoyuan Ye, Jing Zhang, Shanshan Zhao, Juhua Liu, Bo Du, and Dacheng Tao. Dptext-detr: Towards better scene text detection with dynamic points in transformer. In AAAI, 2023. 1
work page 2023
-
[60]
Camfreediff: Camera-free image to panorama genera- tion with diffusion model
Xiaoding Yuan, Shitao Tang, Kejie Li, Alan Yuille, and Peng Wang. Camfreediff: Camera-free image to panorama genera- tion with diffusion model. arXiv:2407.07174, 2024. 2
-
[61]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018. 6, 2
work page 2018
-
[62]
Deep hough transform for semantic line detec- tion
Kai Zhao, Qi Han, Chang-Bin Zhang, Jun Xu, and Ming- Ming Cheng. Deep hough transform for semantic line detec- tion. TPAMI, 2021. 6, 2, 3 10 Beyond the Frame: Generating 360◦ Panoramic Videos from Perspective Videos Supplementary Material
work page 2021
-
[63]
Accompanying this supplemen- tary file is our project page
Supplementary Material Overview In this supplementary material, we provide additional dataset and implementation details. Accompanying this supplemen- tary file is our project page
-
[64]
Dataset Collection and Statistics While 360° videos have been utilized on a small scale for various vision applications [3, 7, 56], their potential remains largely unexplored at greater magnitudes. In this section, we introduce a scalable data curation strategy for training a video-to-360◦ diffusion model. Then we show examples from our dataset and introd...
-
[65]
Format Filtering. We sample frames from each video and detect horizontal lines in the center or vertical lines at the boundaries to verify the equirectangular format. Hor- izontal line detection removes up-down formatted 360◦ videos, while vertical line detection filters out perspective videos and posters
-
[66]
Intra-frame Filtering. We compute LPIPS between the left and right halves to filter 180◦ videos and between the top and bottom halves to filter improperly formatted 360◦ videos
-
[67]
Inter-frame Filtering. To ensure scene dynamics, we sample frames at random intervals and calculate the pixel variance. Static videos with minimal inter-frame variation are removed. After coarse filtering, the videos are split into 10-second clips. We then apply fine-grained filtering using optical flow [16] to detect low-motion clips, TransNetv2 [ 41] to...
-
[68]
Implementation Details and Analyses 3.1. Perspective to Equirectangular Projection We detail the mathematical process of mapping perspective video pixels to equirectangular maps. This includes equa- tions for coordinate normalization, rotation, and spherical mapping. To map a pixel coordinate (u, v) from an image with a given field of view, roll, pitch, a...
-
[69]
Additional Qualitative Results Additional comparison, application, and in-the-wild video generation results are available in our project page. 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.