Benchmarking Audio Deepfake Detection Robustness in Real-world Communication Scenarios
Pith reviewed 2026-05-22 19:40 UTC · model grok-4.3
The pith
A data augmentation strategy improves audio deepfake detection performance under codec compression and packet loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
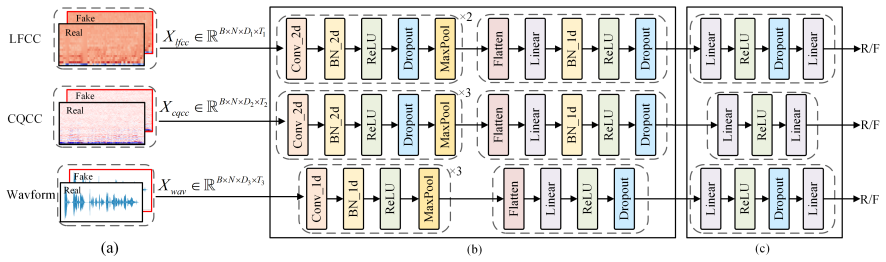
The authors create the ADD-C dataset to evaluate ADD systems under varied audio codec compressions and packet loss rates that occur in real communication. Benchmarking three baseline models on ADD-C shows a significant decline in robustness. A novel Data Augmentation strategy is proposed that significantly enhances ADD performance on the ADD-C dataset, supporting more practical and generalisable detection systems.
What carries the argument
The Data Augmentation (DA) strategy that augments training audio with simulated codec and packet-loss degradations to increase model robustness to communication effects.
If this is right
- Standard ADD models experience a marked drop in accuracy when evaluated on audio subjected to common codecs and packet losses.
- The DA strategy produces clear gains in detection accuracy on the ADD-C test set compared with unaugmented training.
- The ADD-C benchmark provides a practical tool for developing and comparing future detection systems intended for real communication platforms.
Where Pith is reading between the lines
- The same augmentation idea could be adapted to improve robustness in related tasks such as speaker verification or speech recognition over lossy channels.
- Developers might combine the method with channel estimation at inference time to apply condition-specific augmentation or model selection.
- Longer-term validation would require comparing ADD-C results against performance on large-scale collections of genuine recorded calls containing deepfakes.
Load-bearing premise
The chosen combinations of audio codecs and packet loss rates in ADD-C accurately represent the degradations present in actual real-world communication channels.
What would settle it
Testing the augmented models on a set of deepfake and genuine audio recordings captured directly from real VoIP calls or video platforms where the ground-truth labels and exact channel conditions are known.
Figures


read the original abstract
Existing Audio Deepfake Detection (ADD) systems often struggle to generalise effectively due to the significantly degraded audio quality caused by audio codec compression and channel transmission effects in real-world communication scenarios. To address this challenge, we developed a rigorous benchmark to evaluate the performance of the ADD system under such scenarios. We introduced ADD-C, a new test dataset to evaluate the robustness of ADD systems under diverse communication conditions, including different combinations of audio codecs for compression and packet loss rates. Benchmarking three baseline ADD models on the ADD-C dataset demonstrated a significant decline in robustness under such conditions. A novel Data Augmentation (DA) strategy was proposed to improve the robustness of ADD systems. Experimental results demonstrated that the proposed approach significantly enhances the performance of ADD systems on the proposed ADD-C dataset. Our benchmark can assist future efforts towards building practical and robustly generalisable ADD systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ADD-C dataset to benchmark audio deepfake detection (ADD) systems under simulated real-world communication degradations from audio codecs and packet loss rates. It reports performance declines for three baseline models on ADD-C, proposes a data augmentation strategy, and claims that experiments demonstrate significant robustness improvements on the proposed dataset.
Significance. If the central claims hold, the work provides a practical benchmark and mitigation approach for an important deployment challenge in ADD systems. The new dataset could support future robustness research, and the empirical focus on communication-channel effects is timely. However, the absence of validation for the synthetic degradations limits the strength of the real-world applicability claims.
major comments (2)
- [Dataset Construction] The construction of the ADD-C dataset relies on specific combinations of audio codecs and packet loss rates, but the manuscript reports no validation against real communication channel traces (e.g., captured VoIP/RTP streams), acoustic statistics, or perceptual metrics such as PESQ/MOS scores. This is load-bearing for the title and abstract claims of applicability to 'real-world communication scenarios,' because unverified synthetic effects may differ in frequency response or temporal structure from live networks.
- [Experimental Results] The abstract and experimental results sections provide no exact performance metrics, error bars, statistical tests, or dataset construction details to support the reported 'significant decline' in baselines and 'significant enhancements' from the augmentation. This limits verification of the central empirical claims.
minor comments (2)
- [Abstract] Clarify the exact list of codecs and packet loss rates used to generate ADD-C, ideally with a table.
- Ensure all figures include axis labels, legends, and error indicators where applicable.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects for strengthening the claims regarding real-world applicability and empirical rigor. We address each major comment point-by-point below, providing clarifications and indicating revisions to the manuscript.
read point-by-point responses
-
Referee: [Dataset Construction] The construction of the ADD-C dataset relies on specific combinations of audio codecs and packet loss rates, but the manuscript reports no validation against real communication channel traces (e.g., captured VoIP/RTP streams), acoustic statistics, or perceptual metrics such as PESQ/MOS scores. This is load-bearing for the title and abstract claims of applicability to 'real-world communication scenarios,' because unverified synthetic effects may differ in frequency response or temporal structure from live networks.
Authors: We agree that explicit validation against captured real-world traces would further bolster the applicability claims. The codec types and packet loss rates in ADD-C were chosen to reflect standard parameters from ITU-T recommendations and commonly reported conditions in VoIP literature (e.g., G.711, Opus at typical bitrates, and 1-10% loss rates observed in mobile networks). However, the original submission did not include direct comparisons to live traces or perceptual scores. In the revised manuscript, we have added a dedicated subsection in Section 3 that justifies the parameter choices with references to real-world network studies and reports average PESQ scores computed on the degraded samples to quantify perceptual impact. We have also tempered the abstract and title phrasing slightly to emphasize 'simulated communication conditions representative of real-world scenarios' while retaining the benchmark's practical value. These changes address the concern without requiring new data collection. revision: yes
-
Referee: [Experimental Results] The abstract and experimental results sections provide no exact performance metrics, error bars, statistical tests, or dataset construction details to support the reported 'significant decline' in baselines and 'significant enhancements' from the augmentation. This limits verification of the central empirical claims.
Authors: We acknowledge that the abstract and high-level summaries in the original submission omitted specific numerical values, which reduces immediate verifiability. The full results, including per-condition EER/accuracy tables for the three baselines and the augmentation method, are presented in Section 4 with dataset split details. To improve transparency, the revised version now includes error bars (standard deviation over 5 runs), p-values from paired statistical tests confirming significance of the observed declines and improvements, and expanded dataset construction details (e.g., exact codec configurations and loss simulation method) in Section 3. The abstract has been updated with key quantitative highlights, such as the range of baseline degradation and post-augmentation recovery. These additions allow full verification of the empirical claims. revision: yes
Circularity Check
No significant circularity in empirical benchmarking study
full rationale
This is an empirical benchmarking and data-augmentation study. The paper constructs the ADD-C dataset using chosen codec combinations and packet-loss rates, reports performance drops for baseline ADD models, proposes a DA strategy, and shows improved results on ADD-C. No mathematical derivations, equations, or predictions exist that reduce to fitted parameters or inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations are present. The central claims rest on experimental outcomes rather than any closed logical loop. The skeptic concern about real-world validation is an assumption-validity issue, not circularity. This matches the default expectation for non-circular empirical papers.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A novel Data Augmentation (DA) strategy was proposed to improve the robustness of ADD systems. Experimental results demonstrated that the proposed approach significantly enhances the performance of ADD systems on the proposed ADD-C dataset.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Acoustic features anal- ysis for explainable machine learning-based audio spoofing detection,
C. Bisogni, V . Loia, M. Nappi, and C. Pero, “Acoustic features anal- ysis for explainable machine learning-based audio spoofing detection,” Computer Vision and Image Understanding, vol. 249, p. 104145, 2024
work page 2024
-
[2]
Audio-deepfake detection: Adversarial attacks and countermeasures,
M. Rabhi, S. Bakiras, and R. Di Pietro, “Audio-deepfake detection: Adversarial attacks and countermeasures,”Expert Systems with Appli- cations, vol. 250, p. 123941, 2024
work page 2024
-
[3]
Fraudsters cloned company director’s voice in $35 million heist, police find,
T. Brewster, “Fraudsters cloned company director’s voice in $35 million heist, police find,”F orbes, 2021
work page 2021
-
[4]
Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild,
X. Liuet al., “Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2507–2522, 2023
work page 2021
-
[5]
A study on data augmentation in voice anti-spoofing,
A. Cohenet al., “A study on data augmentation in voice anti-spoofing,” Speech Communication, vol. 141, pp. 56–67, 2022
work page 2022
- [6]
-
[7]
V oice over internet protocol (voip),
B. Goode, “V oice over internet protocol (voip),”Proceedings of the IEEE, vol. 90, no. 9, pp. 1495–1517, 2002
work page 2002
-
[8]
Deepfake audio detection via mfcc features using machine learning,
A. Hamzaet al., “Deepfake audio detection via mfcc features using machine learning,”IEEE Access, vol. 10, pp. 134 018–134 028, 2022
work page 2022
-
[9]
Audio deepfake detection with self-supervised xls-r and sls classifier,
Q. Zhanget al., “Audio deepfake detection with self-supervised xls-r and sls classifier,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 6765–6773
work page 2024
-
[10]
A comparative study on physical and perceptual features for deepfake audio detection,
M. Li, Y . Ahmadiadli, and X.-P. Zhang, “A comparative study on physical and perceptual features for deepfake audio detection,” in Proceedings of the 1st International Workshop on Deepfake Detection for Audio Multimedia, 2022, pp. 35–41
work page 2022
-
[11]
A lightweight feature extraction technique for deepfake audio detection,
N. Chakravarty and M. Dua, “A lightweight feature extraction technique for deepfake audio detection,”Multimedia Tools and Applications, vol. 83, no. 26, pp. 67 443–67 467, 2024
work page 2024
-
[12]
Classification of deep fake audio using mfcc technique,
S. Met al., “Classification of deep fake audio using mfcc technique,” in IEEE International Conference on Information Technology, Electronics and Intelligent Communication Systems, 2024, pp. 1–6
work page 2024
-
[14]
Fake speech detection using vggish with attention block,
T. Kanwalet al., “Fake speech detection using vggish with attention block,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2024, no. 1, p. 35, 2024
work page 2024
-
[15]
Detecting audio deepfakes: Integrating cnn and bilstm with multi-feature concatenation,
T. M. Waniet al., “Detecting audio deepfakes: Integrating cnn and bilstm with multi-feature concatenation,” inProceedings of the 2024 ACM Workshop on Information Hiding and Multimedia Security, 2024, pp. 271–276
work page 2024
-
[16]
An explainable deepfake of speech detection method with spectrograms and waveforms,
N. Yu, L. Chen, T. Leng, Z. Chen, and X. Yi, “An explainable deepfake of speech detection method with spectrograms and waveforms,”Journal of Information Security and Applications, vol. 81, p. 103720, 2024
work page 2024
-
[17]
J. Xueet al., “Audio deepfake detection based on a combination of f0 information and real plus imaginary spectrogram features,” in Proceedings of the 1st international workshop on deepfake detection for audio multimedia, 2022, pp. 19–26
work page 2022
-
[18]
Using self attention dnns to discover phonemic features for audio deep fake detection,
H. Dhamyal, A. Ali, I. A. Qazi, and A. A. Raza, “Using self attention dnns to discover phonemic features for audio deep fake detection,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2021, pp. 1178–1184
work page 2021
-
[19]
Bts-e: Audio deep- fake detection using breathing-talking-silence encoder,
T.-P. Doan, L. Nguyen-Vu, S. Jung, and K. Hong, “Bts-e: Audio deep- fake detection using breathing-talking-silence encoder,” in2023 IEEE International Conference on Acoustics, Speech and Signal Processing, 2023, pp. 1–5
work page 2023
-
[20]
Who are you(i really wanna know)? detecting audio deepfakes through vocal tract reconstruction,
L. Blueet al., “Who are you(i really wanna know)? detecting audio deepfakes through vocal tract reconstruction,” in31st USENIX Security Symposium (USENIX Security 22), 2022, pp. 2691–2708
work page 2022
-
[21]
The vicomtech audio deepfake detection system based on wav2vec2 for the 2022 add challenge,
J. M. Mart ´ın-Do˜nas and A. ´Alvarez, “The vicomtech audio deepfake detection system based on wav2vec2 for the 2022 add challenge,” inIEEE International Conference on Acoustics, Speech and Signal Processing, 2022, pp. 9241–9245
work page 2022
-
[22]
H. Taket al., “Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation,”arXiv preprint arXiv:2202.12233, 2022
-
[23]
Audio deepfake detection with self-supervised wavlm and multi-fusion attentive classifier,
Y . Guoet al., “Audio deepfake detection with self-supervised wavlm and multi-fusion attentive classifier,” inIEEE International Conference on Acoustics, Speech and Signal Processing, 2024, pp. 12 702–12 706
work page 2024
-
[24]
End-to-end anti-spoofing with rawnet2,
H. Taket al., “End-to-end anti-spoofing with rawnet2,” in2021 IEEE International Conference on Acoustics, Speech and Signal Processing, 2021, pp. 6369–6373
work page 2021
-
[25]
Domain generalization via aggregation and separation for audio deepfake detection,
Y . Xieet al., “Domain generalization via aggregation and separation for audio deepfake detection,”IEEE Transactions on Information F orensics and Security, vol. 19, pp. 344–358, 2024
work page 2024
-
[26]
Y . Wen, Z. Lei, Y . Yang, C. Liu, and M. Ma, “Multi-path gmm-mobilenet based on attack algorithms and codecs for synthetic speech and deepfake detection.” inINTERSPEECH, 2022, pp. 4795–4799
work page 2022
-
[27]
A. F. Molisch,Wireless communications. John Wiley & Sons, 2012, vol. 34
work page 2012
-
[28]
Overview of compression and packet loss effects in speech biometrics,
L. Besacieret al., “Overview of compression and packet loss effects in speech biometrics,”IEE Proceedings-Vision, Image and Signal Process- ing, vol. 150, no. 6, pp. 372–376, 2003
work page 2003
-
[29]
Constant q cepstral coeffi- cients: A spoofing countermeasure for automatic speaker verification,
M. Todisco, H. Delgado, and N. Evans, “Constant q cepstral coeffi- cients: A spoofing countermeasure for automatic speaker verification,” Computer Speech & Language, vol. 45, pp. 516–535, 2017
work page 2017
-
[30]
The adaptive multirate wideband speech codec (amr- wb),
B. Bessetteet al., “The adaptive multirate wideband speech codec (amr- wb),”IEEE Transactions on Speech and Audio Processing, vol. 10, no. 8, pp. 620–636, 2002
work page 2002
-
[31]
Standardization of the new 3gpp evs codec,
S. Bruhnet al., “Standardization of the new 3gpp evs codec,” inIEEE International Conference on Acoustics, Speech and Signal Processing, 2015, pp. 5703–5707
work page 2015
-
[32]
ETSI, “Lte; 5g; codec for immersive voice and audio services - detailed algorithmic description incl. rtp payload format and sdp parameter definitions,” 2024. [Online]. Available: https://www.etsi.org/
work page 2024
-
[33]
High-Quality, Low-Delay Music Coding in the Opus Codec
J.-M. Valinet al., “High-quality, low-delay music coding in the opus codec,”arXiv preprint arXiv:1602.04845, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
Speex: A Free Codec For Free Speech
J.-M. Valin, “Speex: A free codec for free speech,”arXiv preprint arXiv:1602.08668, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Rtp payload format and file storage format for silk speech and audio codec,
H. Astromet al., “Rtp payload format and file storage format for silk speech and audio codec,” 2009. [Online]. Available: https://datatracker.ietf.org/doc/draft-spittka-silk-payload-format/00/
work page 2009
-
[36]
Aasist: Audio anti-spoofing using integrated spectro- temporal graph attention networks,
J.-w. Junget al., “Aasist: Audio anti-spoofing using integrated spectro- temporal graph attention networks,” inIEEE International Conference on Acoustics, Speech and Signal Processing, 2022, pp. 6367–6371
work page 2022
-
[37]
For: A dataset for synthetic speech detection,
R. Reimao and V . Tzerpos, “For: A dataset for synthetic speech detection,” in2019 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), 2019, pp. 1–10
work page 2019
-
[38]
Wavefake: A data set to facilitate audio deepfake detection,
J. Frank and L. Sch ¨onherr, “Wavefake: A data set to facilitate audio deepfake detection,”arXiv preprint arXiv:2111.02813, 2021
-
[39]
K. Ito and L. Johnson, “The lj speech dataset,” 2017. [Online]. Available: https://keithito.com/LJ-Speech-Dataset/
work page 2017
-
[40]
Mlaad: The multi-language audio anti-spoofing dataset,
N. M. M ¨ulleret al., “Mlaad: The multi-language audio anti-spoofing dataset,” in2024 International Joint Conference on Neural Networks (IJCNN), 2024, pp. 1–7
work page 2024
-
[41]
“The m-ailabs speech dataset,” 2024. [Online]. Available: https: //github.com/imdatceleste/m-ailabs-dataset
work page 2024
-
[42]
Adam: A method for stochastic optimization,
D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inInternational Conference on Learning Representations, 2015
work page 2015
-
[43]
Optimization methods for large- scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large- scale machine learning,”SIAM review, vol. 60, no. 2, pp. 223–311, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.