Planning Stealthy Backdoor Attacks in MDPs with Observation-Based Triggers
Pith reviewed 2026-05-22 18:42 UTC · model grok-4.3
The pith
An attacker jointly optimizes a backdoor policy and observation-based trigger in Markov decision processes using only a black-box simulator to create stealthy attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that backdoor attack planning in MDPs can be cast as a constrained Markov game. Player 0 learns a backdoor policy that maximizes attack rewards when the trigger is active yet behaves near-optimally when the trigger is inactive. Player 1 designs a finite-memory trigger based on partial state observations. A switching gradient-based optimization algorithm jointly solves for both the policy and the trigger, and case-study experiments confirm that the resulting attacks remain stealthy while achieving high success rates.
What carries the argument
A constrained Markov game on an augmented state space in which one player optimizes the backdoor policy and the other designs the finite-memory, observation-based trigger.
If this is right
- The backdoor policy passes testing because it remains near-optimal whenever the trigger is absent.
- The trigger activates the attack only through finite memory of partial observations and small dynamic perturbations.
- Attack performance changes predictably with parameters that control how stealthy the backdoor policy must appear.
- The joint optimization produces attacks that succeed without requiring full state information at runtime.
Where Pith is reading between the lines
- Similar game formulations could be used by defenders to search for possible triggers in existing control policies.
- The method suggests that simulation-based red-teaming should become standard practice for certifying safety-critical MDPs.
- Extending the trigger design to continuous observation spaces would test whether the same switching-gradient approach remains tractable.
Load-bearing premise
The attacker has access to a black-box simulator of the original MDP and can introduce small perturbations to the transition dynamics while only observing partial states.
What would settle it
If experiments on the case-study MDP show that the learned policy either performs substantially worse than optimal in the untriggered original system or fails to activate the malicious behavior under the partial observations available at runtime, the central claim would be falsified.
Figures

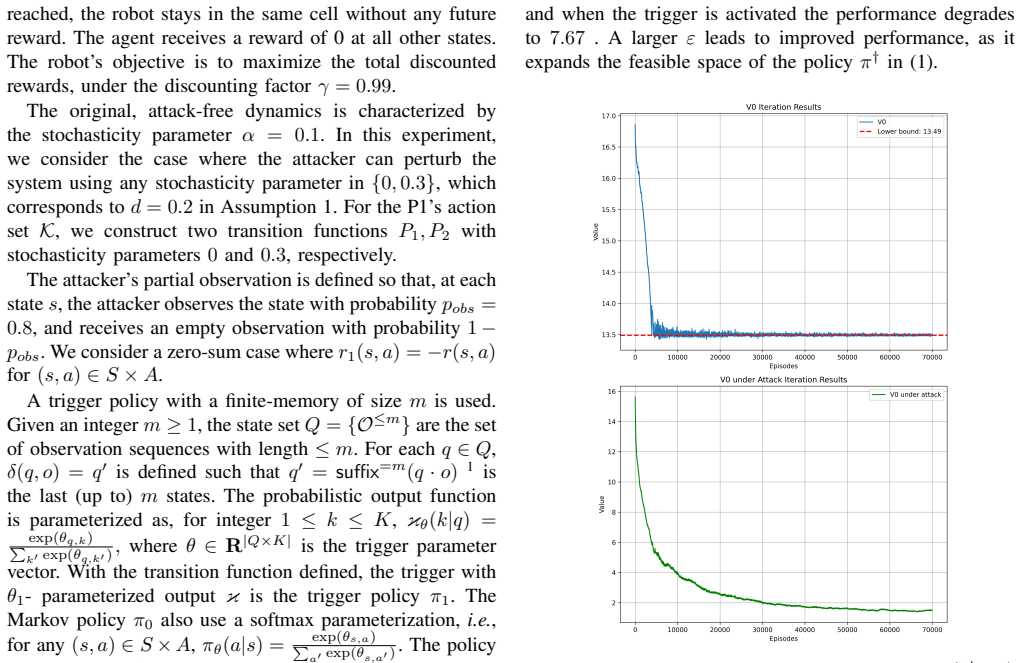
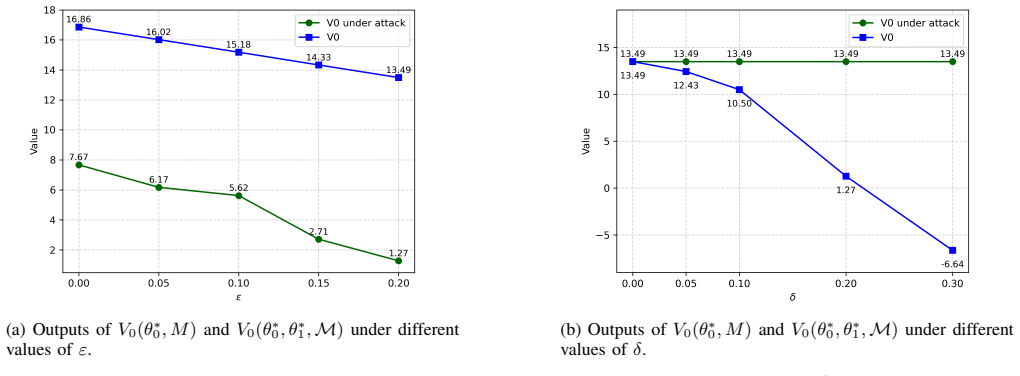

read the original abstract
This paper investigates backdoor attack planning in stochastic control systems modeled as Markov Decision Processes (MDPs). A backdoor attack involves an adversary deploying a policy that performs well in the original MDP to pass testing, but behaves maliciously at runtime when combined with a trigger that perturbs system dynamics. We consider a sophisticated attacker capable of jointly optimizing the backdoor policy and its trigger using only a blackbox simulator. During execution, the attacker has access only to partial observations of the system state and is restricted to introduce small perturbations to the system's transition dynamics. We formulate the attack planning problem as a constrained Markov game with an augmented state space and two players: Player 0 learns a backdoor policy that maximizes attack rewards when the trigger is active. However, when the trigger is inactive, the backdoor policy behaves near-optimally in the original MDP; Player 1 designs a finite-memory, observation-based trigger to activate the attack. We propose a switching gradient-based optimization algorithm to jointly solve for the backdoor policy and trigger. Experiments on a case study demonstrate the effectiveness of our method in achieving stealthy and successful backdoor attacks, and how the attack performance varies under different parameters related to the stealthiness of the backdoor attack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates backdoor attack planning in MDPs as a constrained Markov game on an augmented state space. Player 0 optimizes a backdoor policy that is near-optimal on the clean MDP but malicious when an observation-based trigger is active; Player 1 designs a finite-memory trigger. The attacker is assumed to have black-box simulator access and may apply only small perturbations to the transition kernel while observing partial states. A switching gradient-based algorithm is proposed to jointly solve the game, with effectiveness shown via a single case study.
Significance. If the central algorithmic claim holds, the work would be significant for security analysis of stochastic control systems, as it provides a concrete planning procedure for stealthy, observation-triggered backdoors under partial information. The constrained-game formulation and joint optimization of policy and trigger are technically interesting and could inform both attack and defense research in MDPs. However, the absence of convergence analysis or quantitative experimental detail currently limits the result's immediate impact.
major comments (2)
- [§4] §4 (Switching Gradient-Based Optimization): the manuscript presents the switching gradient algorithm for jointly solving the constrained Markov game but supplies neither a convergence proof nor an analysis of the non-stationarity induced by the switching rule or the augmented state. This is load-bearing for the central claim that the algorithm reliably produces a stealthy backdoor policy and trigger.
- [§5] §5 (Case Study): the abstract and summary state that experiments demonstrate effectiveness, yet no quantitative metrics, ablation studies on the switching rule or stealthiness bound, or comparisons to baselines are reported. Without these, the empirical support for the joint-optimization claim cannot be evaluated.
minor comments (1)
- [§3] The notation for the augmented state and the finite-memory trigger could be clarified with an explicit diagram or pseudocode in §3.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address the major concerns point by point below, clarifying our position and outlining planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Switching Gradient-Based Optimization): the manuscript presents the switching gradient algorithm for jointly solving the constrained Markov game but supplies neither a convergence proof nor an analysis of the non-stationarity induced by the switching rule or the augmented state. This is load-bearing for the central claim that the algorithm reliably produces a stealthy backdoor policy and trigger.
Authors: We acknowledge that the manuscript does not include a formal convergence proof for the switching gradient algorithm. The switching mechanism and augmented state do introduce non-stationarity, which precludes direct application of standard policy-gradient convergence results. In the revised version we will add a dedicated subsection that (i) explicitly discusses the sources of non-stationarity, (ii) provides a sketch of why a full proof is technically difficult under the current formulation, and (iii) reports empirical convergence diagnostics (e.g., value-function trajectories and trigger-activation statistics) from the case study to support practical reliability. We will also analyze the effect of the augmented state dimension on gradient variance. revision: partial
-
Referee: [§5] §5 (Case Study): the abstract and summary state that experiments demonstrate effectiveness, yet no quantitative metrics, ablation studies on the switching rule or stealthiness bound, or comparisons to baselines are reported. Without these, the empirical support for the joint-optimization claim cannot be evaluated.
Authors: We agree that the experimental section is currently limited and would benefit from additional quantitative detail. The single case study was intended as a proof-of-concept illustration rather than a comprehensive evaluation. In the revision we will expand §5 to report concrete metrics (attack success rate when the trigger is active, clean-MDP performance degradation as a stealthiness measure, and trigger activation frequency), include ablation studies on the switching interval and trigger memory length, and add comparisons against two baselines: a fixed (non-learned) trigger and a non-joint optimization approach that alternates between policy and trigger updates without the switching gradient rule. revision: yes
Circularity Check
No significant circularity; formulation and algorithm are independent of results
full rationale
The paper formulates the attack planning problem as a constrained Markov game with augmented state space, defines two players for the backdoor policy and observation-based trigger, and proposes a switching gradient-based optimization algorithm to jointly solve it. Effectiveness is shown via experiments on a single case study under varying stealthiness parameters. No load-bearing step reduces a claimed result to a fitted parameter, self-defined quantity, or self-citation chain by construction; the optimization procedure and empirical demonstration remain external to the inputs rather than tautological. The derivation chain is self-contained against the stated MDP model and black-box simulator assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- perturbation magnitude bound
axioms (1)
- domain assumption System dynamics can be modeled as an MDP with partial observations
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate the attack planning problem as a constrained Markov game with an augmented state space and two players... We propose a switching gradient-based optimization algorithm to jointly solve for the backdoor policy and trigger.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the stealthy backdoor strategy... V₀(M_π†) ≥ (1−ε)V*₀(M)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
TrojDRL: Evaluation of Backdoor Attacks on Deep Reinforcement Learning,
P. Kiourti, K. Wardega, S. Jha, and W. Li, “TrojDRL: Evaluation of Backdoor Attacks on Deep Reinforcement Learning,” in2020 57th ACM/IEEE Design Automation Conference (DAC), pp. 1–6, July 2020. ISSN: 0738-100X
work page 2020
-
[2]
BAFFLE: Hiding Backdoors in Offline Reinforcement Learning Datasets,
C. Gong, Z. Yang, Y . Bai, J. He, J. Shi, K. Li, A. Sinha, B. Xu, X. Hou, D. Lo, and T. Wang, “BAFFLE: Hiding Backdoors in Offline Reinforcement Learning Datasets,” Mar. 2024. arXiv:2210.04688 [cs]
-
[3]
BadRL: Sparse Targeted Backdoor Attack against Reinforcement Learning,
J. Cui, Y . Han, Y . Ma, J. Jiao, and J. Zhang, “BadRL: Sparse Targeted Backdoor Attack against Reinforcement Learning,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 11687–11694, Mar. 2024
work page 2024
-
[4]
Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and Defenses,
M. Goldblum, D. Tsipras, C. Xie, X. Chen, A. Schwarzschild, D. Song, A. M ˛ adry, B. Li, and T. Goldstein, “Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and Defenses,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, pp. 1563–1580, Feb. 2023. Conference Name: IEEE Transactions on Pattern Analysis and Mach...
work page 2023
-
[5]
Planting Undetectable Backdoors in Machine Learning Models : [Extended Abstract],
S. Goldwasser, M. P. Kim, V . Vaikuntanathan, and O. Zamir, “Planting Undetectable Backdoors in Machine Learning Models : [Extended Abstract],” in2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS), pp. 931–942, Oct. 2022. ISSN: 2575- 8454
work page 2022
-
[6]
S. Li, S. Ma, M. Xue, and B. Z. H. Zhao, “Deep Learning Backdoors,” inSecurity and Artificial Intelligence: A Crossdisciplinary Approach (L. Batina, T. Bäck, I. Buhan, and S. Picek, eds.), pp. 313–334, Cham: Springer International Publishing, 2022
work page 2022
-
[7]
Robust Control of Markov Decision Processes with Uncertain Transition Matrices,
A. Nilim and L. El Ghaoui, “Robust Control of Markov Decision Processes with Uncertain Transition Matrices,”Operations Research, vol. 53, pp. 780–798, Oct. 2005. Publisher: INFORMS
work page 2005
-
[8]
Robust Markov Decision Processes,
W. Wiesemann, D. Kuhn, and B. Rustem, “Robust Markov Decision Processes,”Mathematics of Operations Research, vol. 38, pp. 153– 183, Feb. 2013
work page 2013
-
[9]
Provable Defense against Backdoor Policies in Reinforcement Learning,
S. Bharti, X. Zhang, A. Singla, and J. Zhu, “Provable Defense against Backdoor Policies in Reinforcement Learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 14704–14714, Dec. 2022
work page 2022
-
[10]
Cooperative Back- door Attack in Decentralized Reinforcement Learning with Theoretical Guarantee,
M. Gao, Y . Zou, Z. Zhang, X. Cheng, and D. Yu, “Cooperative Back- door Attack in Decentralized Reinforcement Learning with Theoretical Guarantee,” May 2024. arXiv:2405.15245 [cs]
-
[11]
Solving POMDPs by Searching the Space of Finite Policies
N. Meuleau, K.-E. Kim, L. P. Kaelbling, and A. R. Cassandra, “Solving pomdps by searching the space of finite policies,”arXiv preprint arXiv:1301.6720, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[12]
Independent Learning in Con- strained Markov Potential Games,
P. Jordan, A. Barakat, and N. He, “Independent Learning in Con- strained Markov Potential Games,” inProceedings of The 27th Inter- national Conference on Artificial Intelligence and Statistics, pp. 4024– 4032, PMLR, Apr. 2024. ISSN: 2640-3498
work page 2024
-
[13]
Stochastic first-order methods for convex and nonconvex functional constrained optimization,
D. Boob, Q. Deng, and G. Lan, “Stochastic first-order methods for convex and nonconvex functional constrained optimization,”Mathe- matical Programming, vol. 197, pp. 215–279, Jan. 2023
work page 2023
-
[14]
Z. Jia and B. Grimmer, “First-Order Methods for Nonsmooth Non- convex Functional Constrained Optimization with or without Slater Points,” Jan. 2025. arXiv:2212.00927 [math]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.