Surrogate to Poincar\'e inequalities on manifolds for dimension reduction in nonlinear feature spaces
Pith reviewed 2026-05-22 16:33 UTC · model grok-4.3
The pith
Convex surrogates to Poincaré inequality losses outperform direct minimization for learning dimension-reducing maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce new convex surrogates to the loss function J(g) derived from Poincaré inequalities on manifolds. By invoking concentration inequalities they obtain suboptimality results that apply to polynomials and to a wide class of input probability measures. Numerical experiments on several benchmarks demonstrate that minimizing the surrogates yields lower approximation errors for the target function u than standard iterative minimization of the training loss, particularly when the number of training samples is small or the reduced dimension m is one.
What carries the argument
Convex surrogates to the Poincaré inequality loss J(g), built from concentration inequalities to bound the suboptimality of the resulting dimension-reducing map g.
If this is right
- Suboptimality bounds hold for all polynomials and a wide family of input measures.
- The surrogates yield lower approximation error than direct iterative minimization of the training loss.
- The performance advantage is most pronounced for small training sets and when the target dimension m equals one.
- The two-stage approximation procedure f composed with g benefits directly from the easier optimization of the surrogates.
Where Pith is reading between the lines
- The same concentration-inequality technique could be used to construct convex surrogates for other manifold-based losses arising in nonlinear dimension reduction.
- The observed gains at small sample sizes suggest the surrogates may be especially useful in data-scarce regimes where direct non-convex optimization tends to overfit or get stuck.
- If the uniform concentration assumption holds for larger classes of functions beyond polynomials, the method could extend to richer families of maps g without losing the suboptimality guarantees.
Load-bearing premise
The concentration inequalities used to build the surrogates and prove suboptimality hold uniformly for the chosen class of maps g, including polynomials, and for the input probability measures under study.
What would settle it
An experiment on one of the paper's benchmark problems in which minimizing a surrogate produces a strictly larger approximation error than iterative minimization of the original loss J(g) for a polynomial g, small training set, and m=1.
Figures
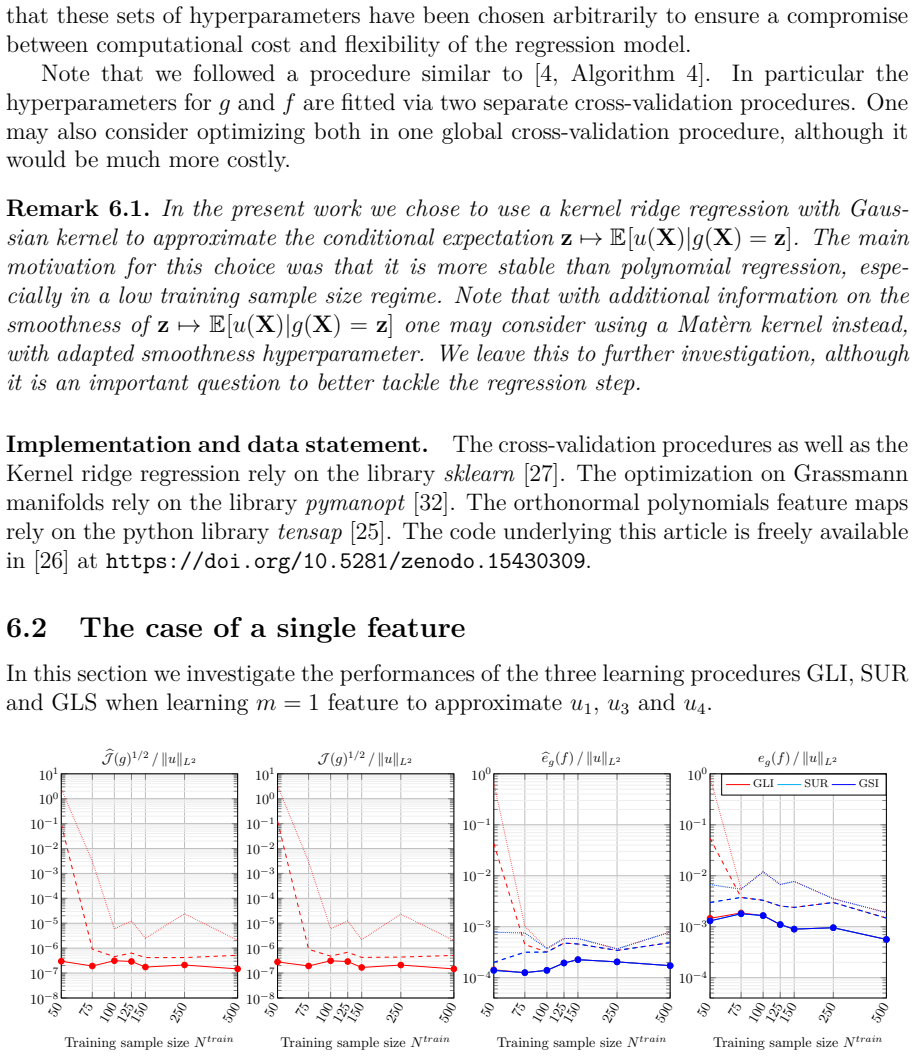
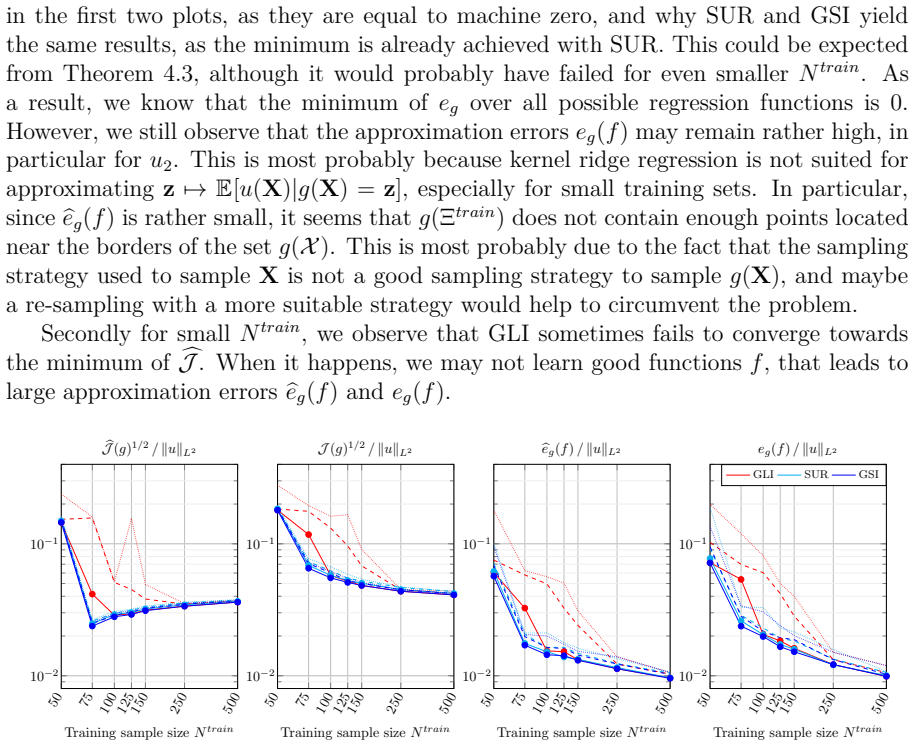


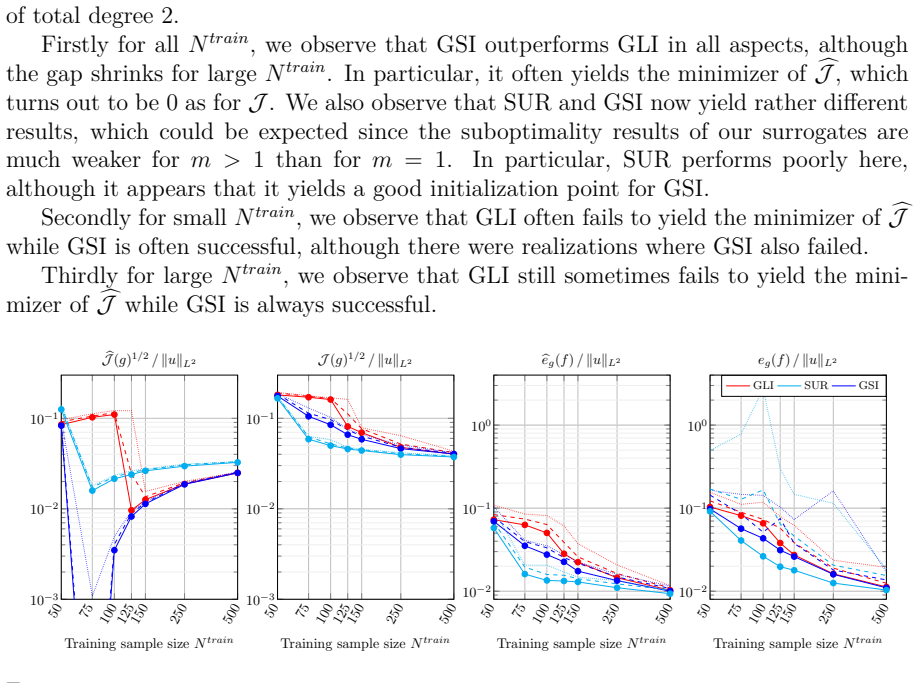
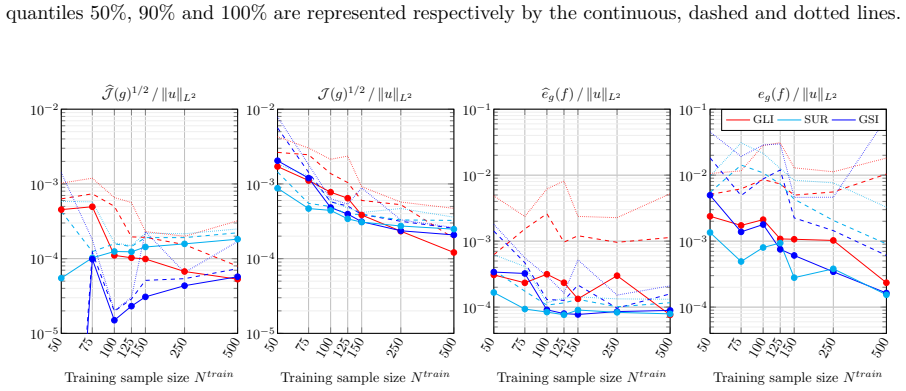
read the original abstract
We aim to approximate a continuously differentiable function $u:\mathbb{R}^d \rightarrow \mathbb{R}$ by a composition of functions $f\circ g$ where $g:\mathbb{R}^d \rightarrow \mathbb{R}^m$, $m\leq d$, and $f : \mathbb{R}^m \rightarrow \mathbb{R}$ are built in a two stage procedure. For a fixed $g$, we build $f$ using classical regression methods, involving evaluations of $u$. Recent works proposed to build a nonlinear $g$ by minimizing a loss function $\mathcal{J}(g)$ derived from Poincar\'e inequalities on manifolds, involving evaluations of the gradient of $u$. A problem is that minimizing $\mathcal{J}$ may be a challenging task. Hence in this work, we introduce new convex surrogates to $\mathcal{J}$. Leveraging concentration inequalities, we provide suboptimality results for a class of functions $g$, including polynomials, and a wide class of input probability measures. We investigate performances on different benchmarks for various training sample sizes. We show that our approach outperforms standard iterative methods for minimizing the training Poincar\'e inequality based loss, often resulting in better approximation errors, especially for small training sets and $m=1$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes convex surrogate losses for the Poincaré inequality functional J(g) used to construct nonlinear feature maps g for dimension reduction in function approximation. Using concentration inequalities, it establishes suboptimality guarantees for polynomial maps g and a broad class of probability measures. Numerical experiments on benchmarks indicate that minimizing the surrogates yields better approximation errors than direct optimization of J, especially for small sample sizes and embedding dimension m=1.
Significance. The work addresses a practical challenge in optimizing manifold-based dimension reduction losses by introducing convex surrogates with theoretical support. If the suboptimality results are uniform as claimed, this could facilitate more reliable training in nonlinear feature learning, with particular benefits in low-data settings. The empirical superiority for m=1 is noteworthy for applications requiring minimal embedding dimensions.
major comments (2)
- [§3.2] §3.2 (Suboptimality bounds): The derivation of suboptimality for polynomials invokes concentration inequalities that must hold uniformly over the function class and measures; the constants appear to depend on polynomial degree and measure tails, which risks non-uniformity in the small-sample, m=1 regimes highlighted in the experiments and abstract.
- [§4] §4 (Experimental protocol): The comparison to iterative minimization of the training loss lacks explicit details on optimization hyperparameters, convergence criteria, and variance across runs, making it hard to confirm that the reported gains are robust rather than tied to specific implementation choices.
minor comments (2)
- [§2] Notation for the surrogate loss and the original J(g) should be introduced with a clear side-by-side comparison in §2 to aid readability.
- [§4] Figure captions in the experimental section would benefit from explicit mention of training set sizes and embedding dimensions used in each panel.
Simulated Author's Rebuttal
We are grateful to the referee for the positive assessment of our work and the constructive suggestions. We respond to each major comment in turn and outline the planned revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Suboptimality bounds): The derivation of suboptimality for polynomials invokes concentration inequalities that must hold uniformly over the function class and measures; the constants appear to depend on polynomial degree and measure tails, which risks non-uniformity in the small-sample, m=1 regimes highlighted in the experiments and abstract.
Authors: The concentration inequalities used in §3.2 are standard and apply uniformly over the class of polynomials of a given degree for measures with appropriate moment conditions. The explicit dependence of the constants on the degree and tail parameters is derived in the proofs (see Theorem 3.1 and its proof). For the low-degree polynomials and m=1 setting in our experiments, this dependence does not lead to vacuous bounds, as confirmed by the numerical results. To address the concern, we will add a paragraph in §3.2 discussing the scaling of the constants with degree and sample size, and clarify that the bounds are intended to be informative rather than sharp for very high degrees. revision: partial
-
Referee: [§4] §4 (Experimental protocol): The comparison to iterative minimization of the training loss lacks explicit details on optimization hyperparameters, convergence criteria, and variance across runs, making it hard to confirm that the reported gains are robust rather than tied to specific implementation choices.
Authors: We agree that additional details on the experimental setup are needed for full reproducibility and to substantiate the robustness of the observed gains. In the revised manuscript, we will expand §4 to include the specific optimization algorithm and hyperparameters (such as step size and iteration count) used for minimizing the training loss J(g), the convergence criteria employed, and standard deviations or error bars computed over multiple independent runs. revision: yes
Circularity Check
No circularity: surrogates derived from standard concentration inequalities
full rationale
The derivation introduces convex surrogates to the Poincaré loss J(g) by applying concentration inequalities to bound the difference between surrogate and original loss, then proves suboptimality over polynomials and wide measure classes. These steps rely on external concentration results and do not reduce by the paper's equations to a fitted parameter renamed as prediction, a self-definition, or a load-bearing self-citation chain. The original J(g) is referenced from prior literature but is not used to force the new surrogate bounds. The central claims remain independently supported by the invoked inequalities and are not equivalent to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption u is continuously differentiable from R^d to R
- domain assumption Concentration inequalities apply to the class of g including polynomials and the considered input measures
Reference graph
Works this paper leans on
- [1]
-
[2]
Kofi P. Adragni and R. Dennis Cook. Sufficient dimension reduction and prediction in regression.Phil. Trans. R. Soc. A., 367(1906):4385–4405, November 2009
work page 1906
-
[3]
Inequalities for the gamma function.Research report collection, 12(1), 2009
Necdet Batir. Inequalities for the gamma function.Research report collection, 12(1), 2009
work page 2009
-
[4]
Daniele Bigoni, Youssef Marzouk, Clémentine Prieur, and Olivier Zahm. Nonlinear dimension reduction for surrogate modeling using gradient information.Information and Inference: A Journal of the IMA, 11(4):1597–1639, December 2022
work page 2022
-
[5]
S. G. Bobkov and F. L. Nazarov. Sharp dilation-type inequalities with a fixed parameter of convexity.J Math Sci, 152(6):826–839, August 2008
work page 2008
-
[6]
Sergey G. Bobkov and Michel Ledoux. On weighted isoperimetric and Poincaré-type inequalities. InInstitute of Mathematical Statistics Collections, pages 1–29. Institute of Mathematical Statistics, Beachwood, Ohio, USA, 2009
work page 2009
-
[7]
C. Borell. Convex set functions ind-space.Period Math Hung, 6(2):111–136, June 1975. 40
work page 1975
-
[8]
Convex measures on locally convex spaces.Ark
Christer Borell. Convex measures on locally convex spaces.Ark. Mat., 12(1-2):239– 252, December 1974
work page 1974
-
[9]
Robert A. Bridges, Anthony D. Gruber, Christopher Felder, Miki Verma, and Chelsey Hoff. Active Manifolds: A non-linear analogue to Active Subspaces. In Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 764–772. PMLR, 2019
work page 2019
-
[10]
Constantine, Eric Dow, and Qiqi Wang
Paul G. Constantine, Eric Dow, and Qiqi Wang. Active Subspace Methods in Theory andPractice: ApplicationstoKrigingSurfaces.SIAM J. Sci. Comput., 36(4):A1500– A1524, January 2014
work page 2014
-
[11]
Dennis Cook and Sanford Weisberg
R. Dennis Cook and Sanford Weisberg. Sliced Inverse Regression for Dimension Reduction: Comment.Journal of the American Statistical Association, 86(414):328, June 1991
work page 1991
-
[12]
Matthieu Fradelizi. Concentration inequalities for $s$-concave measures of dilations of Borel sets and applications.Electron. J. Probab., 14(none), January 2009
work page 2009
-
[13]
An upper bound for the condition number of a matrix in spectral norm
Ayşe Dilek Güngör. Erratum to “An upper bound for the condition number of a matrix in spectral norm” [J. Comput. Appl. Math. 143 (2002) 141–144].Journal of Computational and Applied Mathematics, 234(1):316, May 2010
work page 2002
-
[14]
Springer International Publishing, Cham, 2019
Wolfgang Hackbusch.Tensor Spaces and Numerical Tensor Calculus, volume 56 of Springer Series in Computational Mathematics. Springer International Publishing, Cham, 2019
work page 2019
-
[15]
Jeffrey M. Hokanson and Paul G. Constantine. Data-Driven Polynomial Ridge Ap- proximation Using Variable Projection.SIAM J. Sci. Comput., 40(3):A1566–A1589, January 2018
work page 2018
-
[16]
Christos Lataniotis, Stefano Marelli, and Bruno Sudret. Extending classical surro- gate modelling to high dimensions through supervised dimensionality reduction: A data-driven approach.Int. J. UncertaintyQuantification, 10(1):55–82, 2020
work page 2020
-
[17]
A general theory for nonlinear sufficient dimension reduction: Formulation and estimation.Ann
Kuang-Yao Lee, Bing Li, and Francesca Chiaromonte. A general theory for nonlinear sufficient dimension reduction: Formulation and estimation.Ann. Statist., 41(1), February 2013
work page 2013
-
[18]
Nonlinear sufficient dimension reduction for functional data
Bing Li and Jun Song. Nonlinear sufficient dimension reduction for functional data. Ann. Statist., 45(3), June 2017
work page 2017
-
[19]
Dimension reduction for functional data based on weak conditional moments.Ann
Bing Li and Jun Song. Dimension reduction for functional data based on weak conditional moments.Ann. Statist., 50(1), February 2022
work page 2022
-
[20]
On Directional Regression for Dimension Reduction
Bing Li and Shaoli Wang. On Directional Regression for Dimension Reduction. Journal of the American Statistical Association, 102(479):997–1008, September 2007
work page 2007
-
[21]
Ker-Chau Li. Sliced Inverse Regression for Dimension Reduction.Journal of the American Statistical Association, 86(414):316–327, June 1991. 41
work page 1991
-
[22]
Matthew T C Li, Tiangang Cui, Fengyi Li, Youssef Marzouk, and Olivier Zahm. Sharp detection of low-dimensional structure in probability measures via dimensional logarithmic Sobolev inequalities.Information and Inference: A Journal of the IMA, 14(3):iaaf021, June 2025
work page 2025
-
[23]
Li, Youssef Marzouk, and Olivier Zahm
Matthew T.C. Li, Youssef Marzouk, and Olivier Zahm. Principal feature detection viaϕ-Sobolev inequalities.Bernoulli, 30(4), November 2024
work page 2024
-
[24]
F. Nazarov, M. Sodin, and A. Volberg. The geometric Kannan-Lovasz-Simonovits lemma, dimension-free estimates for volumes of sublevel sets of polynomials, and dis- tribution of zeroes of random analytic functions.St. Petersburg Math. J., 14(2):351– 366, 2003
work page 2003
-
[25]
Anthony Nouy and Erwan Grelier. Anthony-nouy/tensap: V1.5. Zenodo, July 2023
work page 2023
-
[26]
Alexandre-pasco/tensap: V1.6.2-poincare- learning-paper
Anthony Nouy and Alexandre Pasco. Alexandre-pasco/tensap: V1.6.2-poincare- learning-paper. Zenodo, May 2025
work page 2025
-
[27]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blon- del, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Courna- peau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
work page 2011
-
[28]
G. Piazza and T. Politi. An upper bound for the condition number of a matrix in spectral norm.Journal of Computational and Applied Mathematics, 143(1):141–144, June 2002
work page 2002
-
[29]
Cambridge University Press, 1 edition, August 2015
Allan Pinkus.Ridge Functions. Cambridge University Press, 1 edition, August 2015
work page 2015
-
[30]
Francesco Romor, Marco Tezzele, Andrea Lario, and Gianluigi Rozza. Kernel- based active subspaces with application to computational fluid dynamics parametric problems using the discontinuous Galerkin method.Numerical Meth Engineering, 123(23):6000–6027, December 2022
work page 2022
-
[31]
Generalized bounds for active subspaces.Electron
Mario Teixeira Parente, Jonas Wallin, and Barbara Wohlmuth. Generalized bounds for active subspaces.Electron. J. Statist., 14(1), January 2020
work page 2020
-
[32]
James Townsend, Niklas Koep, and Sebastian Weichwald. Pymanopt: A python toolbox for optimization on manifolds using automatic differentiation.Journal of Machine Learning Research, 17(137):1–5, 2016
work page 2016
-
[33]
Romain Verdière, Clémentine Prieur, and Olivier Zahm. Diffeomorphism-based fea- ture learning using Poincaré inequalities on augmented input space.Journal of Machine Learning Research, 26(139):1–31, June 2025
work page 2025
-
[34]
Nonlinear Dimension Reduction with Kernel Sliced Inverse Regression.IEEE Trans
Yi-Ren Yeh, Su-Yun Huang, and Yuh-Jye Lee. Nonlinear Dimension Reduction with Kernel Sliced Inverse Regression.IEEE Trans. Knowl. Data Eng., 21(11):1590–1603, November 2009
work page 2009
-
[35]
Constantine, Clémentine Prieur, and Youssef M
Olivier Zahm, Paul G. Constantine, Clémentine Prieur, and Youssef M. Mar- zouk. Gradient-Based Dimension Reduction of Multivariate Vector-Valued Func- tions.SIAM J. Sci. Comput., 42(1):A534–A558, January 2020. 42
work page 2020
-
[36]
Certified dimension reduction in nonlinear Bayesian inverse problems.Math
Olivier Zahm, Tiangang Cui, Kody Law, Alessio Spantini, and Youssef Marzouk. Certified dimension reduction in nonlinear Bayesian inverse problems.Math. Comp., 91(336):1789–1835, April 2022
work page 2022
-
[37]
Learning nonlinear level sets for dimensionality reduction in function approximation
Guannan Zhang, Jiaxin Zhang, and Jacob Hinkle. Learning nonlinear level sets for dimensionality reduction in function approximation. InAdvances in Neural Infor- mation Processing Systems, volume 32. Curran Associates, Inc., 2019. 43
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.