Language Model Networks: Supervision-Efficient Learning through Dense Communication
Pith reviewed 2026-05-22 14:46 UTC · model grok-4.3
The pith
Language model networks learn dense vector communication between pre-trained nodes to enable end-to-end optimization with limited supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
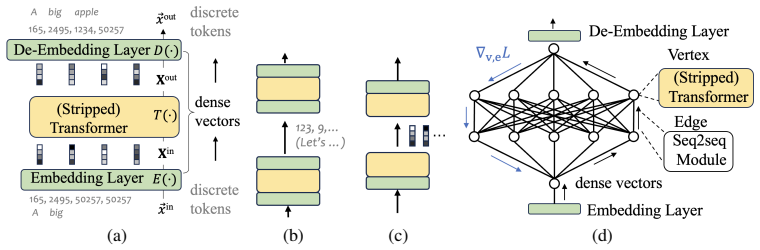
LMNet realizes language model networks by using stripped pre-trained LLMs as vertex modules and trainable seq2seq modules as communication edges, enabling intermediate nodes to exchange dense vectors while preserving natural-language input and output at the system boundary and thereby achieving efficient information transfer, end-to-end gradient optimization, and learned communication protocols beyond hand-designed ones.
What carries the argument
LMNet architecture, in which pre-trained language models function as reusable nodes connected by trainable seq2seq modules that pass dense vectors to support differentiable communication across the network.
If this is right
- The full network can be optimized end-to-end from the final task objective.
- Performance gains appear with only small additional training cost for the communication modules.
- The system adapts to new tasks under limited supervision while keeping natural language at the boundaries.
- Communication protocols emerge automatically instead of relying on manually specified formats.
Where Pith is reading between the lines
- Similar dense links could reduce the number of tokens generated at intermediate steps and thereby lower inference latency in multi-model pipelines.
- The approach might extend to networks that mix language models with other differentiable modules such as vision encoders.
- Learned vector protocols could transfer across related tasks if the seq2seq modules are kept frozen after initial training.
Load-bearing premise
Trainable seq2seq modules can learn effective dense communication protocols from end-task supervision alone without degrading the capabilities of the pre-trained LLM nodes or requiring extensive additional data.
What would settle it
Train an LMNet on a concrete task such as multi-step reasoning and compare its accuracy against both the strongest single pre-trained model and a baseline network that communicates only through generated natural language text; if the dense version shows no gain or a loss, the claim of effective learned communication fails.
Figures



read the original abstract
Language models are increasingly used not only as standalone predictors but also as components in larger inference systems, from test-time scaling to multi-agent collaboration. We study language model networks, where pre-trained language models serve as reusable nodes and intelligence emerges from their topology, communication, and optimization. Existing systems mostly communicate through natural language: easy to deploy, but discrete, inefficient, and hard to optimize from end-task supervision. We propose LMNet, a dense and differentiable realization of this paradigm. LMNet uses stripped LLMs as vertex modules and trainable seq2seq modules as communication edges, enabling intermediate nodes to exchange dense vectors while preserving natural-language input and output at the system boundary. By bypassing intermediate embedding and de-embedding, LMNet enables efficient information transfer, end-to-end gradient optimization, and learned communication beyond hand-designed protocols. Experiments show performance with small additional training cost and effective adaptation under limited supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LMNet, a network architecture in which pre-trained language models serve as reusable nodes connected by trainable seq2seq modules that exchange dense vector representations. This design bypasses intermediate embedding and de-embedding steps to enable efficient, differentiable communication, end-to-end gradient flow, and learned protocols that adapt under limited supervision, with claims of small additional training cost relative to natural-language baselines.
Significance. If the central claims are substantiated, the work would offer a concrete mechanism for supervision-efficient multi-LLM systems by replacing discrete text exchanges with dense, optimizable channels. The approach directly addresses a practical bottleneck in current multi-model inference pipelines and could influence designs for collaborative reasoning systems.
major comments (2)
- [Abstract] Abstract: The statement that 'experiments show performance with small additional training cost and effective adaptation under limited supervision' is load-bearing for the central claim, yet the manuscript provides no information on datasets, model sizes, training-set cardinalities, baselines, ablations isolating the dense-communication benefit, or statistical controls. Without these, the empirical support for supervision efficiency cannot be evaluated.
- [Architecture description] Proposed architecture (implicit in the description of stripped LLMs as nodes and seq2seq as edges): The claim that trainable seq2seq modules can discover communication vectors compatible with the internal hidden-state distributions of frozen pre-trained LLMs rests on the assumption that end-task gradients alone will align the output distribution of the seq2seq modules with the expectations of the transformer layers. No analysis or ablation is supplied to show that this alignment occurs without degrading node capabilities or requiring large additional data.
minor comments (1)
- [Abstract] The abstract refers to 'stripped LLMs' without defining what layers or components are removed; a brief clarification of the node interface would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our submission. The comments have helped us identify areas where additional clarity and analysis would strengthen the manuscript. We address each major comment below and have incorporated revisions to improve the presentation of our experimental support and architectural assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that 'experiments show performance with small additional training cost and effective adaptation under limited supervision' is load-bearing for the central claim, yet the manuscript provides no information on datasets, model sizes, training-set cardinalities, baselines, ablations isolating the dense-communication benefit, or statistical controls. Without these, the empirical support for supervision efficiency cannot be evaluated.
Authors: We agree that the abstract would benefit from greater specificity to support the central claims. While the full manuscript details the experimental setup—including datasets, model scales, training cardinalities, natural-language baselines, communication ablations, and statistical reporting—in the Experiments section, we have revised the abstract to include a concise high-level summary of these elements along with references to the relevant sections. This change makes the empirical support more immediately evaluable without substantially increasing length. revision: yes
-
Referee: [Architecture description] Proposed architecture (implicit in the description of stripped LLMs as nodes and seq2seq as edges): The claim that trainable seq2seq modules can discover communication vectors compatible with the internal hidden-state distributions of frozen pre-trained LLMs rests on the assumption that end-task gradients alone will align the output distribution of the seq2seq modules with the expectations of the transformer layers. No analysis or ablation is supplied to show that this alignment occurs without degrading node capabilities or requiring large additional data.
Authors: We appreciate this observation on the implicit assumptions of the architecture. The manuscript currently supports the claim through end-to-end performance gains under limited supervision, but we concur that direct evidence of alignment and non-degradation would be valuable. In the revised version we have added a dedicated analysis subsection with ablations that quantify distribution alignment between seq2seq outputs and LLM hidden states, measure any capability degradation on the frozen nodes, and report the additional data required for stable training. revision: yes
Circularity Check
No circularity: LMNet proposal introduces new architecture with empirical claims
full rationale
The paper proposes LMNet as a system architecture using stripped pre-trained LLMs as nodes and trainable seq2seq modules as edges. Claims of efficient dense communication, end-to-end optimization, and limited-supervision adaptation rest on the introduction of these components and reported experimental outcomes rather than any derivation that reduces to its own inputs by construction. No equations, predictions, or uniqueness theorems are presented that loop back to fitted parameters or self-referential definitions. The central premise is a methodological suggestion whose value is asserted via performance results, not tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- seq2seq module parameters
axioms (2)
- domain assumption Pre-trained language models can serve as reusable vertex modules after stripping
- domain assumption Dense vector exchange preserves necessary information for system-level tasks
invented entities (1)
-
LMNet architecture with seq2seq communication edges
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use such stripped LLMs as vertexes and optimizable seq2seq modules as edges to construct LMNet, with similar structure as MLPs.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By bypassing intermediate embedding and de-embedding, LMNet enables efficient information transfer, end-to-end gradient optimization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.