gen2seg: Generative Models Enable Generalizable Instance Segmentation
Pith reviewed 2026-05-22 14:28 UTC · model grok-4.3
The pith
Finetuning generative models on indoor furnishings and cars with an instance coloring loss produces category-agnostic instance segmentation that generalizes to unseen object types and styles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
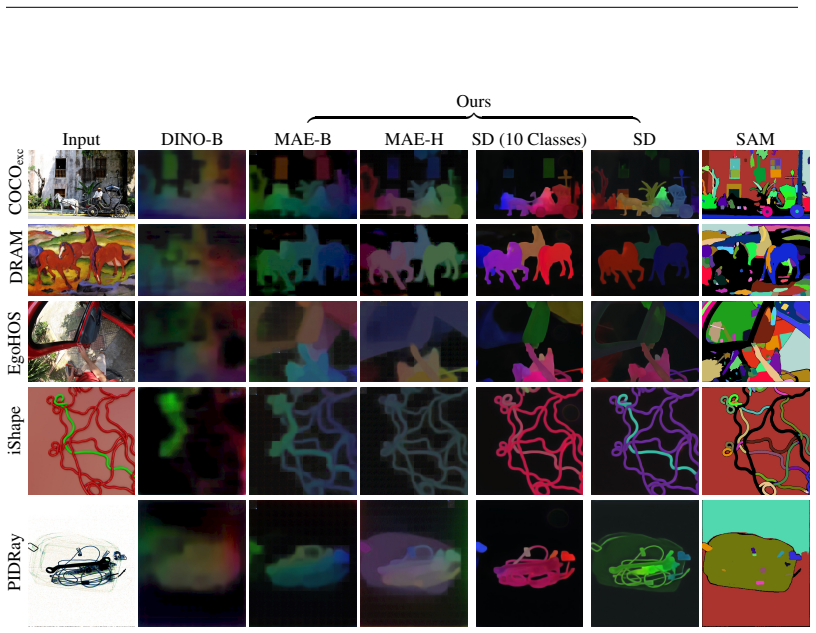
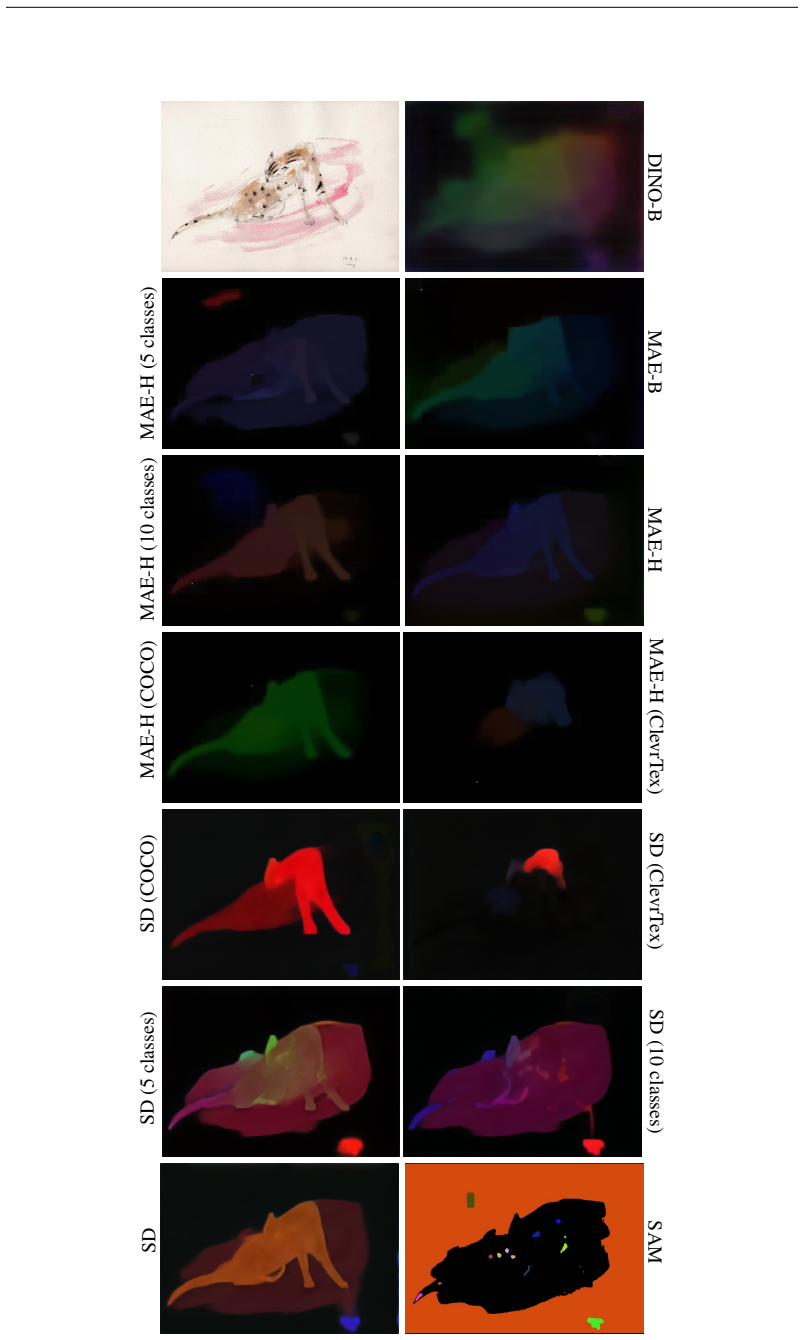
Finetuning Stable Diffusion and MAE with an instance coloring loss exclusively on indoor furnishings and cars induces a general grouping mechanism that transfers to arbitrary unseen object types, styles, and domains, allowing the models to approach the accuracy of heavily supervised SAM while outperforming it on fine structures and ambiguous boundaries.
What carries the argument
Instance coloring loss applied to finetune generative models, which repurposes their built-in understanding of boundaries and compositions into a category-agnostic segmentation output.
Load-bearing premise
The narrow finetuning on indoor furnishings and cars induces a general category-agnostic grouping mechanism that transfers without further adaptation or data overlap.
What would settle it
Evaluating the finetuned models on a held-out dataset of object categories and visual styles with no overlap to indoor furnishings or cars and measuring whether segmentation accuracy falls well below SAM levels.
Figures

















read the original abstract
By pretraining to synthesize coherent images from perturbed inputs, generative models inherently learn to understand object boundaries and scene compositions. How can we repurpose these generative representations for general-purpose perceptual organization? We finetune Stable Diffusion and MAE (encoder+decoder) for category-agnostic instance segmentation using our instance coloring loss exclusively on a narrow set of object types (indoor furnishings and cars). Surprisingly, our models exhibit strong zero-shot generalization, accurately segmenting objects of types and styles unseen in finetuning. This holds even for MAE, which is pretrained on unlabeled ImageNet-1K only. When evaluated on unseen object types and styles, our best-performing models closely approach the heavily supervised SAM, and outperform it when segmenting fine structures and ambiguous boundaries. In contrast, existing promptable segmentation architectures or discriminatively pretrained models fail to generalize. This suggests that generative models learn an inherent grouping mechanism that transfers across categories and domains, even without internet-scale pretraining. Please see our website for additional qualitative figures, code, and a demo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces gen2seg, which finetunes generative models (Stable Diffusion and MAE) using an instance coloring loss exclusively on indoor furnishings and cars. It claims this induces a category-agnostic grouping mechanism enabling strong zero-shot instance segmentation on unseen object types, styles, and domains, with performance approaching or exceeding SAM on fine structures and ambiguous boundaries while outperforming discriminatively pretrained alternatives.
Significance. If the zero-shot generalization is verified to be free of data leakage or category overlap, the result would indicate that generative pretraining objectives capture transferable perceptual organization principles with minimal supervision. This could reduce dependence on large-scale labeled datasets for segmentation and highlight advantages of generative representations over purely discriminative ones for boundary and grouping tasks.
major comments (3)
- [§4] §4 (Experimental Setup and Results): The manuscript reports strong generalization on 'unseen object types and styles' but provides no explicit enumeration of finetuning categories versus test categories, no overlap statistics, and no ablation removing near-neighbor classes. This information is load-bearing for the central claim that performance reflects a general mechanism rather than partial transfer from shared visual statistics.
- [§4.3] §4.3 (MAE experiments): MAE is pretrained on ImageNet-1K, which contains cars, furniture, and household objects. The zero-shot evaluation on 'unseen' objects requires explicit checks for pretraining-test distribution overlap or contamination; without similarity metrics or held-out analysis, the MAE result cannot securely support the claim of generalization from generative pretraining alone.
- [§5] §5 (Discussion): The assertion that the instance coloring loss produces a 'category-agnostic grouping mechanism' lacks supporting ablations (e.g., comparing against a discriminative baseline trained on the same narrow set) to isolate the contribution of the generative backbone versus the loss itself.
minor comments (2)
- [Abstract] The abstract and §1 should include a direct URL or DOI to the promised website, code, and demo for reproducibility.
- [Table 1] Table 1 and Figure 4: Clarify the exact metrics (e.g., mIoU, boundary F-score) and report statistical significance or variance across runs to support comparisons with SAM.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify and strengthen the evidence for zero-shot generalization in gen2seg. We address each major comment point by point below, committing to revisions where appropriate to better support the central claims.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup and Results): The manuscript reports strong generalization on 'unseen object types and styles' but provides no explicit enumeration of finetuning categories versus test categories, no overlap statistics, and no ablation removing near-neighbor classes. This information is load-bearing for the central claim that performance reflects a general mechanism rather than partial transfer from shared visual statistics.
Authors: We agree that explicit documentation is essential to substantiate the zero-shot claims. In the revised manuscript we will add a table listing all finetuning categories (specific indoor furnishings such as chairs, tables, sofas, lamps, and cars) alongside the test categories drawn from the evaluation benchmarks. We will also report category-overlap statistics confirming zero direct overlap and include an ablation that removes any visually near-neighbor classes from the test set, reporting the resulting performance to demonstrate that gains arise from a transferable grouping mechanism rather than residual visual similarity. revision: yes
-
Referee: [§4.3] §4.3 (MAE experiments): MAE is pretrained on ImageNet-1K, which contains cars, furniture, and household objects. The zero-shot evaluation on 'unseen' objects requires explicit checks for pretraining-test distribution overlap or contamination; without similarity metrics or held-out analysis, the MAE result cannot securely support the claim of generalization from generative pretraining alone.
Authors: We acknowledge the need for quantitative checks on pretraining distribution overlap. Although MAE pretraining is fully unsupervised and the subsequent finetuning uses only a narrow labeled set, we will add feature-similarity analysis (average cosine similarity of MAE embeddings between finetuning and test images) together with a held-out ablation that excludes the most similar ImageNet classes. These additions will be presented in §4.3 of the revision; we note that strong performance on out-of-domain styles absent from ImageNet already suggests the instance-coloring objective induces generalization beyond pretraining contamination. revision: yes
-
Referee: [§5] §5 (Discussion): The assertion that the instance coloring loss produces a 'category-agnostic grouping mechanism' lacks supporting ablations (e.g., comparing against a discriminative baseline trained on the same narrow set) to isolate the contribution of the generative backbone versus the loss itself.
Authors: We will strengthen the discussion by adding a controlled ablation that trains a discriminative segmentation head on the identical narrow finetuning set and loss formulation (adapted for discriminative supervision). Performance of this baseline on the same zero-shot test sets will be reported alongside the generative results, allowing direct isolation of the generative backbone's contribution. Existing comparisons to large-scale discriminatively pretrained models already indicate an advantage, but the requested same-set ablation will make the argument more rigorous. revision: yes
Circularity Check
No circularity: empirical generalization measured on held-out categories
full rationale
The paper presents an empirical study: generative models are finetuned on a narrow training distribution (indoor furnishings and cars) using an instance-coloring loss, then evaluated for zero-shot performance on explicitly held-out object types and styles. No mathematical derivation chain, fitted-parameter prediction, or self-citation load-bearing step is present in the provided text. The central claim is a measured experimental outcome on disjoint test data rather than a quantity defined in terms of the training inputs themselves. This is the standard non-circular pattern for empirical generalization papers.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We finetune Stable Diffusion and MAE ... using our instance coloring loss exclusively on a narrow set of object types (indoor furnishings and cars).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
generative models inherently learn to understand object boundaries and scene compositions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Label- efficient semantic segmentation with diffusion models.arXiv preprint arXiv:2112.03126,
Dmitry Baranchuk, Ivan Rubachev, Andrey V oynov, Valentin Khrulkov, and Artem Babenko. Label- efficient semantic segmentation with diffusion models.arXiv preprint arXiv:2112.03126,
-
[3]
Yohann Cabon, Naila Murray, and Martin Humenberger
URLhttps://arxiv.org/abs/2306.00987. Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual kitti 2.arXiv preprint arXiv:2001.10773,
-
[4]
Cascade R-CNN: High Quality Object Detection and Instance Segmentation
URLhttps://arxiv.org/abs/1906.09756. 10 Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pp. 213–229. Springer,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[5]
Using diffusion priors for video amodal seg- mentation.arXiv preprint arXiv:2412.04623,
Kaihua Chen, Deva Ramanan, and Tarasha Khurana. Using diffusion priors for video amodal seg- mentation.arXiv preprint arXiv:2412.04623,
-
[6]
De- tect what you can: Detecting and representing objects using holistic models and body parts
Xianjie Chen, Roozbeh Mottaghi, Xiaobai Liu, Sanja Fidler, Raquel Urtasun, and Alan Yuille. De- tect what you can: Detecting and representing objects using holistic models and body parts. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1971–1978,
work page 1971
-
[7]
Semantic Instance Segmentation with a Discriminative Loss Function
ISSN 1467-8659. doi: 10.1111/cgf.14473. Bert De Brabandere, Davy Neven, and Luc Van Gool. Semantic instance segmentation with a discriminative loss function.arXiv preprint arXiv:1708.02551,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1111/cgf.14473
-
[8]
URLhttps://openaccess.thecvf.com/content/ ICCV2023/papers/Dravid_Rosetta_Neurons_Mining_the_Common_Units_ in_a_Model_Zoo_ICCV_2023_paper.pdf. Yue Fan, Yongqin Xian, Xiaohua Zhai, Alexander Kolesnikov, Muhammad Ferjad Naeem, Bernt Schiele, and Federico Tombari. Toward a diffusion-based generalist for dense vision tasks.arXiv preprint arXiv:2407.00503,
-
[9]
Gonzalo Martin Garcia, Karim Abou Zeid, Christian Schmidt, Daan de Geus, Alexander Hermans, and Bastian Leibe. Fine-tuning image-conditional diffusion models is easier than you think.arXiv preprint arXiv:2409.11355,
-
[10]
Unsupervised Representation Learning by Predicting Image Rotations
Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Unsupervised representation learning by predicting image rotations.arXiv preprint arXiv:1803.07728,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hy- pothesis.arXiv preprint arXiv:2405.07987,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Laurynas Karazija, Iro Laina, and Christian Rupprecht. Clevrtex: A texture-rich benchmark for unsupervised multi-object segmentation.arXiv preprint arXiv:2111.10265,
-
[13]
Markus Karmann and Onay Urfalioglu. Repurposing stable diffusion attention for training-free unsupervised interactive segmentation.arXiv preprint arXiv:2411.10411,
-
[14]
Theodoros Kouzelis, Ioannis Kakogeorgiou, Spyros Gidaris, and Nikos Komodakis. Eq-vae: Equivariance regularized latent space for improved generative image modeling.arXiv preprint arXiv:2502.09509,
-
[15]
Li, Mihir Prabhudesai, Shivam Duggal, Ellis Brown, and Deepak Pathak
Alexander C. Li, Mihir Prabhudesai, Shivam Duggal, Ellis Brown, and Deepak Pathak. Your dif- fusion model is secretly a zero-shot classifier.arXiv preprint arXiv:2303.16203, 2023a. URL https://arxiv.org/abs/2303.16203. Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer back- bones for object detection,
-
[16]
Ziyi Li, Qinye Zhou, Xiaoyun Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie
URLhttps://arxiv.org/abs/2203.16527. Ziyi Li, Qinye Zhou, Xiaoyun Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Open-vocabulary object segmentation with diffusion models. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pp. 7667–7676, 2023b. Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, P...
-
[17]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Scaling properties of diffusion models for perceptual tasks.arXiv preprint arXiv:2411.08034,
Rahul Ravishankar, Zeeshan Patel, Jathushan Rajasegaran, and Jitendra Malik. Scaling properties of diffusion models for perceptual tasks.arXiv preprint arXiv:2411.08034,
-
[20]
Xudong Wang, Rohit Girdhar, Stella X Yu, and Ishan Misra
doi: 10.1109/CVPR52688.2022.01378. Xudong Wang, Rohit Girdhar, Stella X Yu, and Ishan Misra. Cut and learn for unsupervised object detection and instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 3124–3134, 2023b. XuDong Wang, Jingfeng Yang, and Trevor Darrell. Segment anything without supervisi...
-
[21]
Libo Zhang, Lutao Jiang, Ruyi Ji, and Heng Fan
URLhttps: //arxiv.org/abs/2109.15068. Libo Zhang, Lutao Jiang, Ruyi Ji, and Heng Fan. Pidray: A large-scale x-ray benchmark for real- world prohibited item detection, 2022a. URLhttps://arxiv.org/abs/2211.10763. Lingzhi Zhang, Shenghao Zhou, Simon Stent, and Jianbo Shi. Fine-grained egocentric hand-object segmentation: Dataset, model, and applications, 202...
-
[22]
Diception: A generalist diffusion model for visual perceptual tasks.arXiv preprint arXiv:2502.17157,
Canyu Zhao, Mingyu Liu, Huanyi Zheng, Muzhi Zhu, Zhiyue Zhao, Hao Chen, Tong He, and Chunhua Shen. Diception: A generalist diffusion model for visual perceptual tasks.arXiv preprint arXiv:2502.17157,
-
[23]
allowed” categories. We also pruned any images with more than 35% of image area that is “not allowed
which enables deterministic one-step prediction. This has been shown to outperform multi-step stochastic inference with standard diffusion training for other perceptual tasks. To train it in pixel space, we fix the timestep to the highest (999). We replace the input with our image’s V AE latent without adding any noise. We set the CLIP embedding to the nu...
work page 2025
-
[24]
these layers are the ones most responsible for synthesizing images, for which understanding object grouping is frozen. Finally, in Table 7, we quantitatively evaluate emergent part-based grouping on the Pascal-Part Chen et al. (2014) dataset, which annotates part-level masks for the PASCAL VOC 2012 set. Bolded values represent classes for MAE-H or SD wher...
work page 2014
-
[25]
We do this intentionally, as described in (Ke et al., 2024), to mix gradients between images sampled from Hypersim and Virtual Kitti
work page 2024
-
[26]
We train our model for 30,000 iterations, which takes about 29 hours for SDv2 and 12 hours for MAE ViT-H. However, our models show no signs of overfitting, and performance would likely benefit from additional iterations, but we didn’t explore this due to timing constraints. We sometimes struggle with memory constraints when finetuning Stable Diffusion, as...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.