High-Dimensional Private Linear Regression with Optimal Rates
Pith reviewed 2026-05-22 02:46 UTC · model grok-4.3
The pith
Differentially private gradient descent achieves the optimal non-asymptotic risk of order gamma plus gamma squared over rho squared for high-dimensional linear regression on well-conditioned data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For well-conditioned data, DP-GD upon properly choosing clipping constant and learning rate achieves the non-asymptotic risk of O(γ + γ² / ρ²) in the regime d/n → γ, and this rate is minimax optimal. The analysis rests on a deterministic equivalent for the clipped DP-GD trajectory expressed as a system of ordinary differential equations, which captures the effect of aggressive clipping. In the ill-conditioned power-law case the risk instead exhibits power-like scaling whose exponent depends on the privacy parameter ρ.
What carries the argument
Deterministic equivalent of the clipped DP-GD trajectory expressed as a system of ordinary differential equations that tracks the finite-n,d behavior under random design.
If this is right
- Properly chosen clipping and learning-rate schedules make one-pass DP-GD minimax optimal for well-conditioned high-dimensional regression.
- The same ODE analysis yields explicit power-law exponents for risk when the covariance spectrum decays as a power law.
- Aggressive gradient clipping smaller than typical per-sample norms improves the privacy-utility tradeoff in this regime.
- Decaying learning-rate schedules further reduce the privacy-induced error term.
- The derived rates hold non-asymptotically and remain valid as both n and d grow large with fixed ratio gamma.
Where Pith is reading between the lines
- The ODE technique could be reused to analyze privacy in other first-order methods such as stochastic gradient descent on non-convex problems.
- If the power-law scaling carries over to neural networks, it would predict how privacy cost grows with model width under heavy-tailed feature spectra.
- Practitioners could use the clipping threshold formula to set hyperparameters directly from estimates of gamma and rho without extensive tuning.
Load-bearing premise
The data follows a random design model with d/n approaching gamma and the covariance spectrum is either well-conditioned or power-law distributed, and the ODE deterministic equivalent accurately describes the clipped DP-GD trajectory.
What would settle it
Simulate random-design linear regression data with d/n close to a fixed gamma, run DP-GD with the paper's recommended clipping and learning-rate schedule, and check whether the observed excess risk stays within a constant factor of gamma plus gamma squared over rho squared or deviates substantially for large n.
Figures

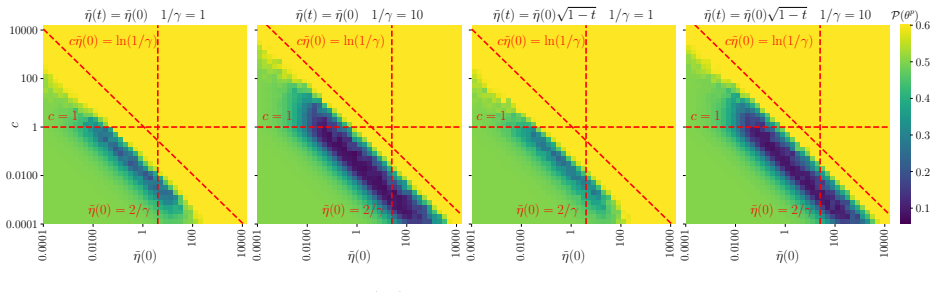
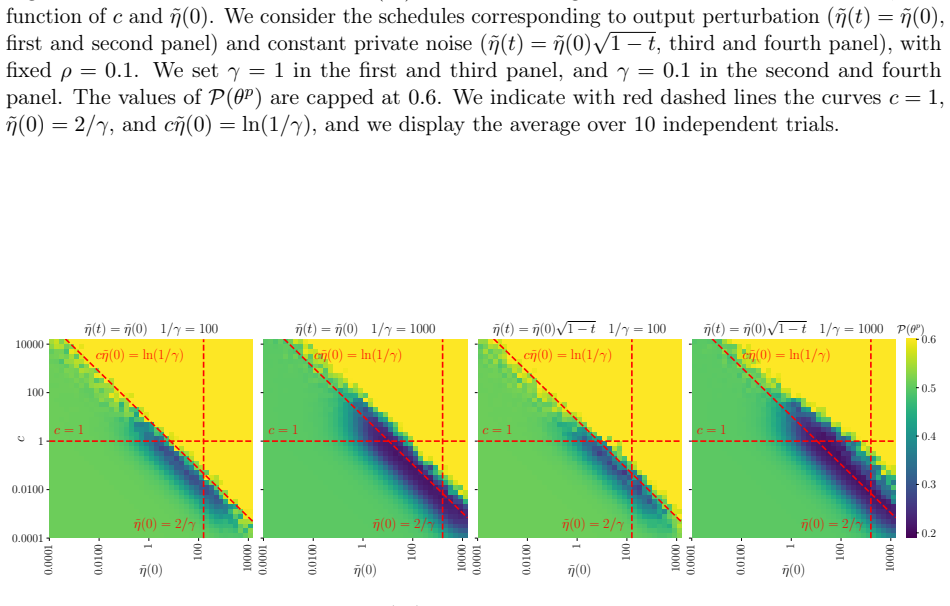
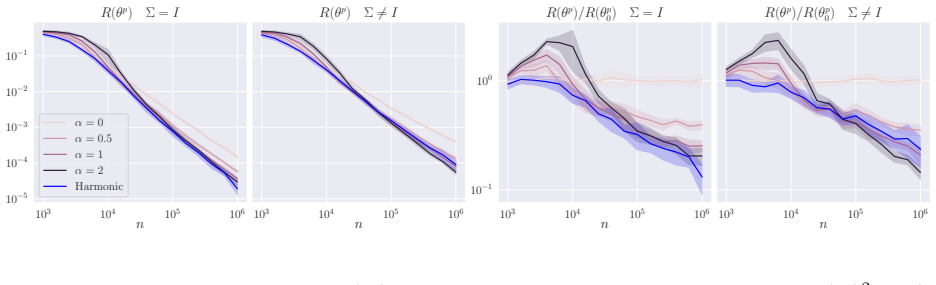



read the original abstract
Differentially private (DP) linear regression has received significant attention in the recent theoretical literature, with several approaches proposed to improve error rates. Our work considers the popular high-dimensional regime with random data, where the number of training samples $n$ and the input dimension $d$ grow at a proportional rate $d / n \to \gamma$, and it studies a family of one-pass DP gradient descent (DP-GD) algorithms satisfying $\rho^2 / 2$ zero concentrated DP. In this setting, we establish a deterministic equivalent for the DP-GD trajectory in terms of a system of ordinary differential equations. This allows to analyze the effect of gradient clipping constants that are smaller than the typical norm of the per-sample gradients - a setup shown to improve performance in practice. For well-conditioned data, we show that DP-GD, upon properly choosing clipping constant and learning rate, achieves the non-asymptotic risk of $O(\gamma + \gamma^2 / \rho^2)$, and we establish that this rate is minimax optimal. Then, we consider the ill-conditioned case where the data covariance spectrum follows a power-law distribution, and we show that the risk displays a power-like scaling law in $\gamma$, highlighting the change in the exponent as a function of the privacy parameter $\rho$. Overall, our analysis demonstrates the benefits of practical algorithmic design choices, including aggressive gradient clipping and decaying learning rate schedules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes one-pass DP gradient descent (DP-GD) for linear regression in the high-dimensional regime d/n → γ under ρ²/2 zero-concentrated DP. It derives a deterministic equivalent for the clipped DP-GD trajectory via a system of ODEs, which permits analysis of aggressive clipping (clipping constants below typical per-sample gradient norms). For well-conditioned covariances the authors obtain the non-asymptotic risk O(γ + γ²/ρ²) and prove it is minimax optimal; for power-law spectra they derive explicit scaling laws whose exponents depend on ρ. The analysis also covers decaying learning-rate schedules.
Significance. If the central claims hold, the work supplies the first rigorous high-dimensional justification for aggressive gradient clipping in private linear regression, a choice known to help empirically but previously difficult to analyze. The ODE deterministic-equivalent technique, the matching minimax lower bound, and the explicit power-law scaling results for ill-conditioned data are genuine strengths. The derivation avoids post-hoc fitting and works directly from the random-design model and the ODE limit.
major comments (1)
- [Section 3] Derivation of the deterministic equivalent (Section 3, statement of the ODE system and accompanying approximation theorem): the manuscript replaces the clipped DP-GD trajectory by the ODE solution even when the clipping threshold lies below the typical per-sample gradient norm. In this regime the clipping operator is non-Lipschitz and the injected noise is state-dependent. Standard concentration arguments then yield an approximation error whose leading term is typically Θ(1/√n). The paper does not explicitly show that this error is o(γ²/ρ²) uniformly in the high-dimensional limit d/n → γ. Because the claimed rate O(γ + γ²/ρ²) is precisely the term that would be affected by such fluctuations, a rigorous bound on the ODE approximation error under aggressive clipping is load-bearing for the main result.
minor comments (2)
- The precise relationship between the chosen clipping constant, the typical gradient norm, and the resulting bias-variance trade-off is only sketched in the text; a short illustrative plot or explicit inequality would improve readability.
- A few recent references on high-dimensional DP-SGD (e.g., works using similar ODE techniques for non-private GD) are missing from the related-work discussion.
Simulated Author's Rebuttal
We thank the referee for their thorough review and positive evaluation of the significance of our results on high-dimensional DP linear regression. We address the major comment below and will strengthen the presentation of the approximation error bounds in the revised version.
read point-by-point responses
-
Referee: [Section 3] Derivation of the deterministic equivalent (Section 3, statement of the ODE system and accompanying approximation theorem): the manuscript replaces the clipped DP-GD trajectory by the ODE solution even when the clipping threshold lies below the typical per-sample gradient norm. In this regime the clipping operator is non-Lipschitz and the injected noise is state-dependent. Standard concentration arguments then yield an approximation error whose leading term is typically Θ(1/√n). The paper does not explicitly show that this error is o(γ²/ρ²) uniformly in the high-dimensional limit d/n → γ. Because the claimed rate O(γ + γ²/ρ²) is precisely the term that would be affected by such fluctuations, a rigorous bound on the ODE approximation error under aggressive clipping is load-bearing for the main result.
Authors: We appreciate this precise identification of a point that merits clearer exposition. The approximation theorem (Theorem 3.1) is formulated to cover aggressive clipping regimes where the threshold is below typical per-sample gradient norms; the proof proceeds via a martingale argument that controls the deviation between the stochastic trajectory and the ODE flow, using a truncation to handle the non-Lipschitz clipping operator and state-dependent noise. While the existing argument already implies that the approximation error is o_p(γ²/ρ²) under the high-dimensional scaling (via the same concentration tools used for the well-conditioned case), we agree that an explicit uniform bound stated as a separate proposition would strengthen the manuscript. In the revision we will add such a proposition, deriving the required o(γ²/ρ²) control uniformly in the d/n → γ limit by combining a smoothed-clipping approximation with a refined Gronwall-type estimate that absorbs the Θ(1/√n) fluctuation term. revision: yes
Circularity Check
Derivation relies on ODE deterministic equivalent and separate minimax argument with no reduction to inputs by construction
full rationale
The central risk bound O(γ + γ²/ρ²) is obtained by analyzing the clipped DP-GD trajectory through a system of ODEs that serve as a deterministic equivalent under the random-design model with d/n → γ. This is a standard mean-field approximation technique applied to the algorithm dynamics, not a redefinition or fit of the target quantity. The minimax optimality is established via an independent lower-bound argument rather than self-citation or parameter fitting. No quoted step equates a prediction to a fitted input or imports a uniqueness result solely from prior author work. The analysis remains self-contained against the stated assumptions and external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- gradient clipping constant
- learning rate schedule
axioms (2)
- domain assumption Random design with d/n → γ
- domain assumption Covariance is well-conditioned or follows power-law spectrum
Reference graph
Works this paper leans on
-
[1]
Differentially private inference via noisy optimiza- tion.The Annals of Statistics, 51(5):2067–2092,
Marco Avella-Medina, Casey Bradshaw, and Po-Ling Loh. Differentially private inference via noisy optimiza- tion.The Annals of Statistics, 51(5):2067–2092,
work page 2067
-
[2]
Privacy and Statistical Risk: Formalisms and Minimax Bounds
Rina Foygel Barber and John C Duchi. Privacy and statistical risk: Formalisms and minimax bounds.arXiv preprint arXiv:1412.4451,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Raef Bassily, Adam Smith, and Abhradeep Thakurta
doi: 10.1017/S0962492921000027. Raef Bassily, Adam Smith, and Abhradeep Thakurta. Private empirical risk minimization: Efficient algorithms and tight error bounds. In2014 IEEE 55th Annual Symposium on Foundations of Computer Science,
-
[4]
doi: 10.1073/pnas.2423072122. Gavin R Brown, Krishnamurthy Dj Dvijotham, Georgina Evans, Daogao Liu, Adam Smith, and Abhradeep Guha Thakurta. Private gradient descent for linear regression: Tighter error bounds and instance-specific uncertainty estimation. InInternational Conference on Machine Learning,
-
[5]
arXiv preprint arXiv:2303.07152 , year =
T. Tony Cai, Yichen Wang, and Linjun Zhang. Score attack: A lower bound technique for optimal differentially private learning.arXiv preprint arXiv:2303.07152,
-
[6]
The high-dimensional asymptotics of first order methods with random data
Michael Celentano, Chen Cheng, and Andrea Montanari. The high-dimensional asymptotics of first order methods with random data.arXiv preprint arXiv:2112.07572,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Elizabeth Collins-Woodfin and Inbar Seroussi
doi: 10.1214/24-AOS2449. Elizabeth Collins-Woodfin and Inbar Seroussi. Exact dynamics of multi-class stochastic gradient descent. arXiv preprint arXiv:2510.14074,
-
[8]
Elizabeth Collins-Woodfin, Courtney Paquette, Elliot Paquette, and Inbar Seroussi. Hitting the high- dimensional notes: an ode for sgd learning dynamics on glms and multi-index models.Information and Inference: A Journal of the IMA, 13(4):iaae028, 2024a. ISSN 2049-8772. doi: 10.1093/imaiai/iaae028. 28 Elizabeth Collins-Woodfin, Inbar Seroussi, Begoña Garc...
-
[9]
Soham De, Leonard Berrada, Jamie Hayes, Samuel L. Smith, and Borja Balle. Unlocking high-accuracy differentially private image classification through scale.arXiv preprint arXiv:2204.13650,
-
[10]
Calibrating noise to sensitivity in private data analysis
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. InTheory of Cryptography, Third Theory of Cryptography Conference, TCC 2006,
work page 2006
-
[11]
Private stochastic convex optimization: optimal rates in linear time
29 Vitaly Feldman, Tomer Koren, and Kunal Talwar. Private stochastic convex optimization: optimal rates in linear time. InProceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, STOC 2020,
work page 2020
-
[12]
Ferdinando Fioretto, Cuong Tran, Pascal Van Hentenryck, and Keyu Zhu. Differential privacy and fairness in decisions and learning tasks: A survey.arXiv preprint arXiv:2202.08187,
-
[13]
Entrywise dynamics and universality of general first order methods.arXiv preprint arXiv:2406.19061,
Qiyang Han. Entrywise dynamics and universality of general first order methods.arXiv preprint arXiv:2406.19061,
-
[14]
Michael B. Hawes. Implementing Differential Privacy: Seven Lessons From the 2020 United States Census. Harvard Data Science Review, 2(2), apr 30
work page 2020
-
[15]
Prateek Jain and Abhradeep Guha Thakurta
doi: 10.1214/aos/1176342503. Prateek Jain and Abhradeep Guha Thakurta. (near) dimension independent risk bounds for differentially private learning. InInternational Conference on Machine Learning,
-
[16]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[17]
Toward training at imagenet scale with differential privacy.arXiv preprint arXiv:2201.12328,
Alexey Kurakin, Shuang Song, Steve Chien, Roxana Geambasu, Andreas Terzis, and Abhradeep Thakurta. Toward training at imagenet scale with differential privacy.arXiv preprint arXiv:2201.12328,
-
[18]
Improved scaling laws in linear regression via data reuse
Licong Lin, Jingfeng Wu, and Peter L Bartlett. Improved scaling laws in linear regression via data reuse. arXiv preprint arXiv:2506.08415, 2025a. Shurong Lin, Eric D Kolaczyk, Adam Smith, and Elliot Paquette. High-dimensional privacy-utility dynamics of noisy stochastic gradient descent on least squares.arXiv preprint arXiv:2510.16687, 2025b. Xiyang Liu, ...
-
[19]
Choquette-Choo, Badih Ghazi, George Kaissis, Ravi Kumar, Ruibo Liu, Da Yu, and Chiyuan Zhang
Ryan McKenna, Yangsibo Huang, Amer Sinha, Borja Balle, Zachary Charles, Christopher A. Choquette-Choo, Badih Ghazi, George Kaissis, Ravi Kumar, Ruibo Liu, Da Yu, and Chiyuan Zhang. Scaling laws for differentially private language models.arXiv preprint arXiv:2501.18914,
-
[20]
Courtney Paquette, Elliot Paquette, Ben Adlam, and Jeffrey Pennington
doi: 10.1214/22-AOS2181. Courtney Paquette, Elliot Paquette, Ben Adlam, and Jeffrey Pennington. Implicit regularization or implicit conditioning? exact risk trajectories of sgd in high dimensions. InAdvances in Neural Information Processing Systems,
-
[21]
Courtney Paquette, Elliot Paquette, Ben Adlam, and Jeffrey Pennington. Homogenization of sgd in high- dimensions: exact dynamics and generalization properties.Mathematical Programming, 2024a. doi: 10.1007/s10107-024-02171-3. Elliot Paquette, Courtney Paquette, Lechao Xiao, and Jeffrey Pennington. 4+ 3 phases of compute-optimal neural scaling laws.Advances...
-
[22]
A framework to characterize performance of LASSO algorithms
Mihailo Stojnic. A framework to characterize performance of lasso algorithms.arXiv preprint arXiv:1303.7291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
ISBN 978-0-387-79052-7. doi: 10.1007/b13794. Prateek Varshney, Abhradeep Thakurta, and Prateek Jain. (nearly) optimal private linear regression for sub-gaussian data via adaptive clipping. InConference on Learning Theory,
-
[24]
Yu-Xiang Wang. Revisiting differentially private linear regression: optimal and adaptive prediction & estimation in unbounded domain.arXiv preprint arXiv:1803.02596,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Diyuan Wu, Lehan Chen, Theodor Misiakiewicz, and Marco Mondelli. Improved scaling laws via weak-to- strong generalization in random feature ridge regression.arXiv preprint arXiv:2603.05691,
-
[26]
32 A Proofs on differential privacy The notion of zCDP can be converted to(ε, δ)-DP, which in turn is defined below. Definition A.1((ε, δ)-DP [Dwork et al., 2006]).A randomized algorithmA satisfies( ε, δ)-differential privacy if for any pair of adjacent datasetsD, D′, and for any subset of the parameters spaceS⊆R d, we have P(A(D)∈S)≤e εP A(D′)∈S +δ.(A.1)...
work page 2006
-
[27]
Furthermore, for anyθ, θ′ ∈R d, we have ∇θℓk,Cclip(x⊤ k θ−y k)− ∇ θℓk,Cclip(x⊤ k θ′ −y k) 2 =∥x k∥2 ℓ′ k,Cclip(x⊤ k θ−y k)−ℓ ′ k,Cclip(x⊤ k θ′ −y k) ≤ ∥x k∥2 x⊤ k θ−θ ′ ≤ ∥x k∥2 2 θ−θ ′ 2 , (A.6) where the second step follows from the fact thatℓ′ k,Cclip(z)is a 1-Lipschitz function. Let us now define ¯ℓk,Cclip(z) = min 1, 2 ∥xk∥2 2 ηk ! ℓk,Cclip(z).(A.7) ...
work page 2020
-
[28]
Proof.Consider the notationu k =θ k −θ ∗
Then, with overwhelming probability, we have sup t∈[0,1) q(Θt −θ ∗)−q(θ ⌊tn⌋ −θ ∗) =O log2 n√n ,(C.3) 38 uniformly for all functionsq∈Q. Proof.Consider the notationu k =θ k −θ ∗. We have the following update rule fork∈[n]: uk =u k−1 −¯ηk¯gk + 2c √ dσkbk,(C.4) where we recall that ¯ηk = min ηk, 2 ∥xk∥2 ,¯g k =g k min 1, c √ d ∥gk∥2 ! , g k = (⟨xk, uk⟩ −z k...
work page 2025
-
[29]
In a similar way, we introduce the shorthandVt = Θt −θ ∗ such that V0 = u0. Using Itô’s formula on (4.14), for any quadratic functionq, we have that dq(Vt) =−¯η(t)µc(Vt)⟨ΣVt,∇q(V t)⟩dt+ ¯η2(t)νc(Vt)P(V t) 1 n tr Σ∇2q(Vt) dt + 2 d n2 c2˜σ2(t) tr ∇2q(Vt) dt+ dM H-DP-GD t , (C.9) where we introduced the shorthand dMH-DP-GD t :=⟨∇q(V t), r 2¯η(t)2νc(Θt)P(Θ t)...
work page 2025
-
[30]
Then, following Lemma 3 in Marshall et al
(for |MGrad ⌊tn⌋ (q)|, |MHess ⌊tn⌋ (q)| and |P⌊tn⌋ k=1 E[∆E Hess k (q) | F k]|), Lemma C.2 (for |MNoise ⌊tn⌋ (q)| and |P⌊tn⌋ k=1 E[∆E Noise k (q) | F k]|), Lemma C.3 (for |MH-DP-GD t (q)|), and Lemma C.5 (for |MStep ⌊tn⌋(q)|), there are two constantsC2(∥Σ∥op,¯η, M, c, γ)andC 3(∥Σ∥op,¯η, M, c)>0such that M ≤C 2n−1/2 log2 n+C 3 ,(C.13) 40 with probability a...
work page 2025
-
[31]
Since bk ∼ N (0, Id)and independent, using the Hanson-Wright inequality (Theorem 6.2.1 in Vershynin [2018]) we have that, for somec >0andK= maxi∈[d] ∥bk+1,i∥ψ2, P 1 n2 tr (b⊗2 k −I d Ck)≥t ≤2 exp −cmin t2n4 K4∥Ck∥2 , tn2 K2∥Ck∥op ≤2 exp −c′ min t2n4 d , tn2 , for some c′ > 0independent of k, d, n. To justify the last passage, note that, by the structure o...
work page 2018
-
[32]
We, therefore, have that∥ 1 n2 ⟨b⊗2 k −I d, Ck⟩∥ψ1 ≤Cn −1,for some constantC(ρ, c, C η,1)>0
Using the above bound, we obtain that ∥Ck∥op ≤ 2dn2c2σ2 k∥q∥C2 ≤ 8c2/ρ2Cη,1, and similarly ∥Ck∥ ≤ 8 √ dc2/ρ2Cη,1. We, therefore, have that∥ 1 n2 ⟨b⊗2 k −I d, Ck⟩∥ψ1 ≤Cn −1,for some constantC(ρ, c, C η,1)>0. For the first term, by Eq. (89) in Marshall et al. [2025], the norm ofq is bounded for the stopped processu τ k as follows: ∥∇q(u)∥ ≤ ∥∇ 2q∥op∥u∥+∥∇q(...
work page 2025
-
[33]
for some absolute constantC >0for allt >0: P sup 1≤k≤n∧τ |MNoise k (q)−EM Noise 0 (q)| ≥t ! ≤2 exp −min{ t Cmax k∈[n] ϕk,1 , t2 CPn i=1 ϕ2 i,1 } ! (C.24) ≤2 exp −Cnmin{t, t 2} . As we assume thatn is proportional tod and noting thatEMNoise 0 (q) = 0by definition, we then have that, for anyy∈[1, n], sup 1≤k≤(n∧τ) |MNoise k (q)| ≤Cn − 1 2 y,(C.25) with prob...
work page 2025
-
[34]
The quadratic variation of the martingale is then bounded a.s
Using Itô’s formula for any quadratic functionq: dq(Vt) =−¯η(t)µc(Θt)∇P(Θ t)⊤∇q(Vt)dt+ ¯η2(t)νc(Θt)P(Θ t) 1 n tr Σ∇2q dt + 2 d n2 c2˜σ2(t) tr ∇2q dt+ dM H-DP-GD t , dMH-DP-GD t :=⟨∇q(V t), r 2¯η(t)2νc(Θt)P(Θ t)Σ n + 4 d n2 c2˜σ(t)2Id dBt⟩, (C.27) with Bt being a standardd dimensional Brownian motion. The quadratic variation of the martingale is then bound...
work page 2025
-
[35]
also guarantees that∥bn∥2 = O( √ d + u)with probability at least 1−2 exp −c1u2 , for some absolute constantc1 >0. Thus, with this probability, we have 4¯ηn¯g⊤ n ΣCclipσnbn = 4¯ηn¯g⊤ n ΣCclip ηn ρ bn =O 1 n √ d √ d 1 n( √ d+u) =O 1√ d + u d ,(C.55) which gives 2R(θn)− Σ1/2 θn−1 −θ ∗ + 2CclipσnΣ1/2bn 2 2 =O 1 + p R(θn−1)√ d + u d ! .(C.56) Similarly, we hav...
work page 2018
-
[36]
The second one, due to(C.60), is a random variable Z such that Z≤ (1 + u)/ √ d with probability at least1− 2 exp −c4 min( √ du, u2) . Thus, √ dZis sub-exponential with norm smaller than a constant, which implies E Z2 =O 1 d .(C.64) Plugging (C.63) and (C.64) in (C.62), and using Cauchy-Schwartz inequality, gives the desired result. D Proofs for Section 5 ...
work page 2012
-
[37]
This is a direct application of Theorem 1.3 in Teschl [2012]
Thus, ifR(0) =R ′(0), and dR=f(t, R),dR ′ =f ′(t, R′),(D.6) with f ′(t, R′(t))≥f(t, R ′(t)),(D.7) for allt∈[0,1], we have that R′(t)≥R(t)for allt∈[0,1].(D.8) 50 The same statement holds also for the opposite inequality, and will be used extensively to bound the solutions of R(t)for different schedules. This is a direct application of Theorem 1.3 in Teschl...
work page 2012
-
[38]
R ′ (t∗) = 0and R ′ (t) < 0for all t∈ (t∗, t∗ + δ)
In fact, if this is not the case, by continuity ofR ′ , there exists an interval(t∗, t∗ + δ) ⊆ [0, 1]s.t. R ′ (t∗) = 0and R ′ (t) < 0for all t∈ (t∗, t∗ + δ). However, if R ′ (t∗) = 0, then the derivative ofR ′ evaluated att ∗ is>0, which is a contradiction. As a result, we have f(t, R ′ (t))< f ′ (t, R ′ (t)),for allt∈[0,1].(D.117) Again, by Lemma B.2, we...
work page 2012
-
[39]
≤ 1 3γ √ A+ 90 ≤ 1 3γ √ 90 .(D.121) Thus, noting that R(1) + c2˜η2(1)γ2 ρ2 =O γ λmax λ4 min γ+ 1 λ4 min γ2 ρ2 , the desired result follows from Theorem 1 and Propositions 4.4 and D.1. D.4 Proofs on the minimax rates In this section, we consider the notation D = ( X, Y )and D′ i = ( X ′ i, Y ′ i ), with X, X′ i ∈R n×d and Y, Y ′ i ∈R n, where the two neigh...
work page 2021
-
[40]
Then, plugging (D.130) in (D.127) and taking the expectation over the priorπofθ ∗, we get Eπ X i∈[n] E[A i(M(D))] =ζ 2Eπ X j∈[d] ∂ ∂θ ∗ j gj(θ∗) .(D.132) Consider the priorπ on θ∗ such that all the entriesθ∗ j are independent and distributed according to πj(z) = 15d5/2 16 1 d −z 2 2 ,(D.133) with support inz∈ (−d−1/2, d−1/2). This prior is s...
work page 2025
-
[41]
Furthermore, sinceλ > 2and n > d, due to concentration of the norm of Gaussian vectors we have thatP(A)≥1−2e −c1d for some absolute constantc1. Then, we also have inf M Eθ∗∼πE[R(M B)]≥inf M Eθ∗∼πE[R(M)] = ζ2 n E h tr (X ⊤X/n+λI) −1Σ i ≥ ζ2 n tr E h Σ−1/2(X ⊤X/n+λI)Σ −1/2 i −1 = ζ2 n tr I+λΣ −1 −1 ≥ ζ2 2λn tr (Σ) = ζ2d 4λmaxn , (D.157) where the second ste...
work page 2022
-
[42]
(E.8) Furthermore, again due to Lemma B.2, sincec≲ 1, we havec2 ≍ν c(R(s))(R(s) +ζ2/2)
Then, since F, K and J are all uniformly≍ to decreasing functions, we have F(Γ(t))≳F(cF(t)) K(Γ(t)−Γ(s))≳K(cF(t)−cF(s)) J(Γ(t)−Γ(s))≳J(cF(t)−cF(s)). (E.8) Furthermore, again due to Lemma B.2, sincec≲ 1, we havec2 ≍ν c(R(s))(R(s) +ζ2/2). Thus, since all terms on the RHS of(E.2) are positive, and dropping numerical constants, we get the first part of the th...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.