SMART: Self-Generating and Self-Validating Multi-Dimensional Assessment for LLMs' Mathematical Problem Solving
Pith reviewed 2026-05-22 13:42 UTC · model grok-4.3
The pith
A new benchmark splits mathematical problem-solving into four cognitive dimensions to show that LLMs have uneven capabilities hidden by standard tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
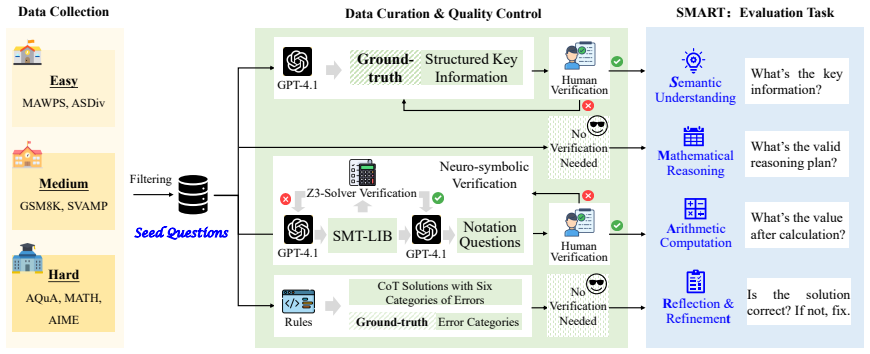
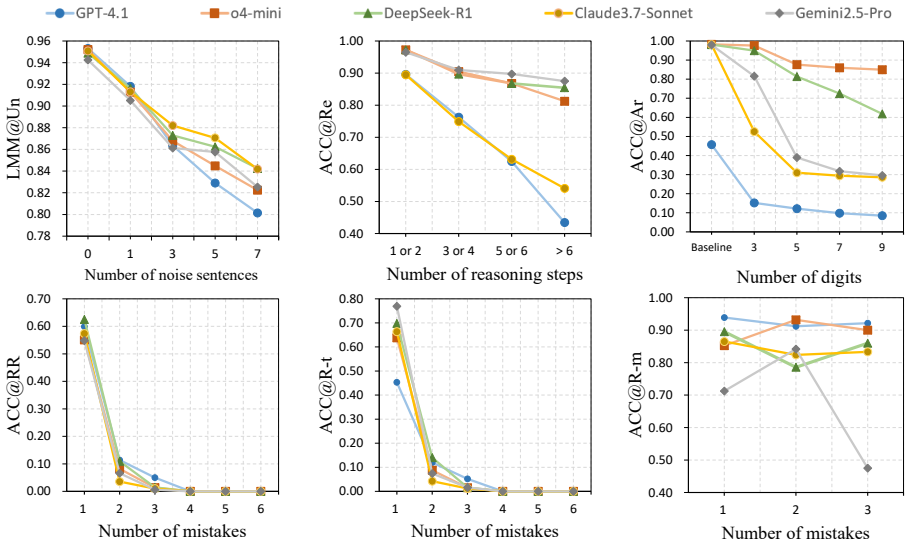
Mathematical problem-solving consists of four distinct cognitive dimensions that current benchmarks do not measure separately. The SMART benchmark introduces dimension-specific tasks to isolate and evaluate Semantic Understanding, Mathematical Reasoning, Arithmetic Computation, and Reflection & Refinement. When run on 22 state-of-the-art LLMs, the results expose substantial discrepancies in model performance across these areas. These gaps indicate real limitations in current systems and support the All-Pass Score as a metric that requires success on all dimensions to reflect true problem-solving capability more faithfully than final-answer accuracy alone.
What carries the argument
The SMART benchmark and its dimension-specific tasks that separately measure the four cognitive processes of Semantic Understanding, Mathematical Reasoning, Arithmetic Computation, and Reflection & Refinement.
If this is right
- LLMs display inconsistent strengths and weaknesses across the four dimensions instead of uniform capability.
- Many models succeed on final answers yet fail on reflection and refinement tasks.
- The All-Pass Score offers a stricter metric that better distinguishes genuine problem-solving from partial success.
- Model development should target improvements in each dimension separately rather than overall accuracy.
Where Pith is reading between the lines
- Developers could design training methods that strengthen the weakest dimension for a given model.
- The same multi-dimensional breakdown might help evaluate LLM performance in non-mathematical domains such as scientific reasoning.
- Single-metric benchmarks likely overestimate real reasoning ability by overlooking dimension-specific failures.
Load-bearing premise
The four cognitive dimensions are distinct, non-overlapping processes that can be isolated and measured independently by the introduced tasks.
What would settle it
Re-evaluating the 22 models and finding that scores on the four dimension-specific tasks are highly correlated with each other and with standard final-answer accuracy, with no meaningful gaps or added value from the All-Pass Score.
Figures


















read the original abstract
Large Language Models (LLMs) have achieved remarkable performance across a wide range of mathematical benchmarks. However, concerns remain as to whether these successes reflect genuine reasoning or superficial pattern recognition. Existing evaluation methods, which typically focus either on the final answer or on the intermediate reasoning steps, reduce mathematical reasoning to a shallow input-output mapping, overlooking its inherently multi-stage and multi-dimensional cognitive nature. Inspired by Polya's problem-solving theory, we propose SMART, a benchmark that decomposes mathematical problem-solving into four cognitive dimensions: Semantic Understanding, Mathematical Reasoning, Arithmetic Computation, and Reflection & Refinement, and introduces dimension-specific tasks to measure the corresponding cognitive processes of LLMs. We apply SMART to 22 state-of-the-art open- and closed-source LLMs and uncover substantial discrepancies in their capabilities across dimensions. Our findings reveal genuine weaknesses in current models and motivate a new metric, the All-Pass Score, designed to better capture true problem-solving capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SMART, a benchmark that decomposes mathematical problem-solving into four cognitive dimensions inspired by Polya's theory—Semantic Understanding, Mathematical Reasoning, Arithmetic Computation, and Reflection & Refinement—and uses self-generated, self-validated dimension-specific tasks to evaluate LLMs. It reports results on 22 open- and closed-source models, documents substantial cross-dimension discrepancies, and proposes the All-Pass Score as a stricter metric for genuine problem-solving capability.
Significance. If the dimension-isolation claim holds, the work would provide a more granular diagnostic tool than existing single-score math benchmarks, directly addressing concerns about superficial pattern matching versus multi-stage reasoning. The self-generation/self-validation pipeline and the All-Pass Score are concrete, falsifiable contributions that could be adopted or extended by the community.
major comments (2)
- [§3.2 and §4.1] §3.2 (Dimension-Specific Task Construction) and §4.1 (Validation Procedure): The central claim that the four dimensions are distinct, non-overlapping processes rests on the assertion that the introduced tasks isolate each cognitive component. No ablation, correlation matrix, or difficulty-matched control is reported showing that, for example, Semantic Understanding items are solved independently of Mathematical Reasoning ability. Without such evidence the reported discrepancies and the All-Pass Score cannot be interpreted as dimension-specific profiles rather than correlated general capabilities.
- [§4.2 and Table 2] §4.2 (Experimental Results) and Table 2: The All-Pass Score is defined as requiring success on all four dimension-specific tasks for a given problem. Because the tasks may share latent factors (e.g., overall model scale or instruction-following), the metric risks simply re-ranking models by a stricter but still unidimensional threshold; a sensitivity analysis or comparison against a single combined task is needed to establish added value.
minor comments (2)
- [Abstract] The abstract and introduction repeatedly use “self-validating” without a concise operational definition; a one-sentence gloss in the abstract would improve readability.
- [Figure 3] Figure 3 (dimension radar plots) would benefit from error bars or per-model variance across the self-generated task sets to indicate stability of the reported discrepancies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§3.2 and §4.1] §3.2 (Dimension-Specific Task Construction) and §4.1 (Validation Procedure): The central claim that the four dimensions are distinct, non-overlapping processes rests on the assertion that the introduced tasks isolate each cognitive component. No ablation, correlation matrix, or difficulty-matched control is reported showing that, for example, Semantic Understanding items are solved independently of Mathematical Reasoning ability. Without such evidence the reported discrepancies and the All-Pass Score cannot be interpreted as dimension-specific profiles rather than correlated general capabilities.
Authors: We acknowledge that the manuscript does not report ablations, inter-dimension correlations, or explicit difficulty-matched controls to empirically demonstrate the independence of the four dimensions. The task construction in §3.2 is intentionally designed to isolate processes (e.g., Semantic Understanding tasks require only problem parsing without solution steps, while Mathematical Reasoning tasks assume semantic input and focus on strategy), and §4.1 validates task quality via self-validation. However, we agree that additional evidence is needed to rule out shared latent factors. In the revised manuscript we will add a correlation matrix of model performances across dimensions, report any available controls from the generation pipeline, and discuss the implications for interpreting the discrepancies as dimension-specific. revision: yes
-
Referee: [§4.2 and Table 2] §4.2 (Experimental Results) and Table 2: The All-Pass Score is defined as requiring success on all four dimension-specific tasks for a given problem. Because the tasks may share latent factors (e.g., overall model scale or instruction-following), the metric risks simply re-ranking models by a stricter but still unidimensional threshold; a sensitivity analysis or comparison against a single combined task is needed to establish added value.
Authors: The All-Pass Score is proposed to capture the requirement of succeeding at every stage of problem-solving rather than permitting compensation across dimensions, which distinguishes it from standard aggregate accuracy. We recognize that without further analysis it could be viewed as a stricter unidimensional threshold. To address this, the revised manuscript will include a sensitivity analysis that compares the All-Pass Score against performance on a single combined task, examines its correlation with model scale and instruction-following ability, and quantifies the additional diagnostic value it provides over existing metrics. revision: yes
Circularity Check
No significant circularity; benchmark and metric are independently constructed
full rationale
The paper defines four dimensions inspired by Polya's problem-solving theory, introduces dimension-specific tasks to measure them, applies the resulting SMART benchmark to 22 LLMs to obtain empirical performance data, and defines the All-Pass Score as a new aggregate metric based on those measurements. No load-bearing step reduces by construction to a fitted parameter, self-referential definition, or self-citation chain. The discrepancies and metric are direct outputs of the evaluation rather than tautological restatements of the input design. The derivation chain is self-contained against external benchmarks and does not rely on any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Polya's problem-solving theory supplies a valid decomposition of mathematical reasoning into four distinct cognitive dimensions that can be separately assessed.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery from Law of Logic unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Inspired by Pólya’s problem-solving theory, we propose SMART, a benchmark that decomposes mathematical problem-solving into four cognitive dimensions: Semantic Understanding, Mathematical Reasoning, Arithmetic Computation, and Reflection & Refinement
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Chengwu Liu, Jianhao Shen, Huajian Xin, Zhengying Liu, Ye Yuan, Haiming Wang, Wei Ju, Chuanyang Zheng, Yichun Yin, Lin Li, Ming Zhang, and Qun Liu. 2023. Fimo: A challenge formal dataset for auto- mated theorem proving.Preprint, arXiv:2309.04295. Xuetao Ma, Wenbin Jiang, and Hua Huang. 2025. Pr...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A diverse corpus for evaluating and developing english math word problem solvers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 975–984. Seyed Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. 2025. Gsm-symbolic: Understanding the limitations of mathematic...
work page 2025
-
[3]
Leonardo de Moura and Sebastian Ullrich
https://huggingface.co/mistralai/ Mistral-Small-Instruct-2409. Leonardo de Moura and Sebastian Ullrich. 2021. The lean 4 theorem prover and programming language. In Automated Deduction–CADE 28: 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021, Proceedings 28, pages 625–635. Springer. OpenAI. 2024. Learning to reason wi...
work page 2021
-
[4]
Are nlp models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094. George Polya. 2014.How to solve it: A new aspect of mathematical method, volume 34. Princeton univer- sity press. George Pólya and ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819– 46836. Junyuan Zhang, Qintong Zhang, Bin Wang, Linke Ouyang, Zichen Wen, Ying Li, Ka-Ho Chow, Con- ghui He, and Wentao Zhang. 2025. Ocr hinders rag: Evaluating the cascading impact of ocr on retrieval-augmented ...
work page 2025
-
[6]
InInternational Conference on Learning Representations
minif2f: a cross-system benchmark for for- mal olympiad-level mathematics. InInternational Conference on Learning Representations. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others
-
[7]
Kaijie Zhu, Jiaao Chen, Jindong Wang, Neil Zhenqiang Gong, Diyi Yang, and Xing Xie
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Pro- cessing Systems, 36:46595–46623. Kaijie Zhu, Jiaao Chen, Jindong Wang, Neil Zhenqiang Gong, Diyi Yang, and Xing Xie. 2023. Dyval: Dy- namic evaluation of large language models for reason- ing tasks. InThe Twelfth International Conference on Learning Representations....
work page 2023
-
[8]
semantic- strong but computation-weak
decomposes students’ performance on math- ematical word problems into sequential skills that closely mirror Pólya’s stages, and is widely used to diagnose where in the problem-solving process students fail. Following this line of work, the four evaluation dimensions in SMART are designed as an LLM- oriented realization of Pólya’s theory and are di- rectly...
work page 2021
-
[9]
Define Variables: Use abstract variable names (e.g., a, b, c) that do not reflect the actual meaning of the variables in the problem
-
[10]
Formulate Constraints: Use mathematical relationships from the problem to establish constraints for the SMT-LIB formula
-
[11]
The logic should be set to QF_NRA or QF_NIA as appropriate
SMT-LIB Syntax: Use proper SMT-LIB syntax. The logic should be set to QF_NRA or QF_NIA as appropriate. Include (check-sat) and (get-value ...) commands to verify satisfiability and extract the result
-
[12]
Check: Ensure all the variables in SMT-LIB formula are declared
-
[13]
Do not write comments. Three-shot Examples [Examples] The Given Question: [Seed question] Now, analyze the next math problem. Generate the symbolic expression of the math word problem. Strictly following the steps and formatting provided. Be precise, logical, and concise in your responses. The Answer of Task: [SMT-LIB] Figure 8: The prompt for LLMs to con...
-
[14]
Arithmetic Number Error Definition: Randomly selects a number in the CoT and replaces it with a different, randomly generated number. Example: The number of downloads of the program in the second month increased to 3*60 = <<3*60=180>>180. In the first two months, the total number of downloads of the program was 180+60 = <<180+60=280>>280. In the third mon...
-
[15]
Skipped Step Error Definition: Randomly removes one sentence (a segment delimited by a period) from the CoT. Example: The number of downloads of the program in the second month increased to 3*60 = <<3*60=180>>180. In the first two months, the total number of downloads of the program was 180+60 = <<180+60=240>>240. In the third month, the number of downloa...
-
[16]
Hallucinatory Insertion Error Definition: Randomly selects a sentence from another CoT and inserts it into a random position in the primary CoT. Example: The number of downloads of the program in the second month increased to 3*60 = <<3*60=180>>180. In the first two months, the total number of downloads of the program was 180+60 = <<180+60=240>>240. In th...
-
[17]
Logical Order Error Definition: Randomly selects two sentences in the CoT and swaps their positions. Example: In the first two months, the total number of downloads of the program was 180+60 = <<180+60=240>>240. The number of downloads of the program in the second month increased to 3*60 = <<3*60=180>>180. In the third month, the number of downloads of th...
-
[18]
Redundant Output Error Definition: Randomly selects a sentence in the CoT, duplicates it, and inserts the copy into a random position. Example: The number of downloads of the program in the second month increased to 3*60 = <<3*60=180>>180. In the first two months, the total number of downloads of the program was 180+60 = <<180+60=240>>240. In the third mo...
-
[19]
Incorrect Operator Error Definition: Replaces a mathematical operator (+, -, ×, ÷) in the CoT with a different, randomly selected operator. Example: The number of downloads of the program in the second month increased to 3*60 = <<3*60=180>>180. In the first two months, the total number of downloads of the program was 180+60 = <<180+60=240>>240. In the thi...
-
[25]
Modify Operator: Replaces a mathematical operator (+, -, ×, ÷) in the CoT with a different, randomly selected operator. Please carefully review each step in the CoT and determine whether any of the above types of errors are present. If you find errors, output the corresponding error type name and numbers. Three-shot Examples [Examples] The Given Question:...
-
[26]
Change Number: Randomly selects a number in the CoT and replaces it with a different, randomly generated number
-
[27]
Delete Segment: Randomly removes one sentence (a segment delimited by a period) from the CoT
-
[28]
Insert Segment: Randomly selects a sentence from another CoT (cot2) and inserts it into a random position in the primary CoT
-
[29]
Swap Segments: Randomly selects two sentences in the CoT and swaps their positions
-
[30]
Duplicate Segment: Randomly selects a sentence in the CoT, duplicates it, and inserts the copy into a random position
-
[31]
Refinement complete – reasoning strengthened
Modify Operator: Replaces a mathematical operator (+, -, ×, ÷) in the CoT with a different, randomly selected operator. Please carefully review each step in the CoT and determine whether any of the above types of errors are present. More than one errors are in the CoT. Output all the corresponding error type namse and numbers. Three-shot Examples [Example...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.