SVL: Spike-based Vision-language Pretraining for Efficient 3D Open-world Understanding
Pith reviewed 2026-05-22 02:07 UTC · model grok-4.3
The pith
A spike-based vision-language pretraining framework enables spiking neural networks to match or exceed artificial networks in zero-shot 3D classification and open-world tasks while preserving energy efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SVL combines Multi-scale Triple Alignment for contrastive learning across 3D, image, and text modalities with Re-parameterizable Vision-Language Integration to produce a lightweight spiking model. The resulting network reaches 85.4 percent top-1 accuracy on zero-shot 3D classification, surpassing several advanced artificial networks, and delivers consistent gains over prior spiking models on 3D classification, DVS action recognition, 3D detection, and 3D segmentation. The same pretraining also supports open-world 3D question answering, sometimes exceeding artificial-network baselines while retaining spike-driven efficiency.
What carries the argument
Multi-scale Triple Alignment (MTA), a label-free triplet contrastive objective that aligns features from 3D, image, and text modalities at multiple scales to build cross-modal representations.
If this is right
- Spiking models gain 6.1 percent on 3D classification tasks compared with earlier spiking networks.
- Performance rises 2.1 percent on DVS action recognition and 1.1 percent on 3D detection.
- 3D segmentation improves by 2.1 percent while inference stays spike-driven and low-power.
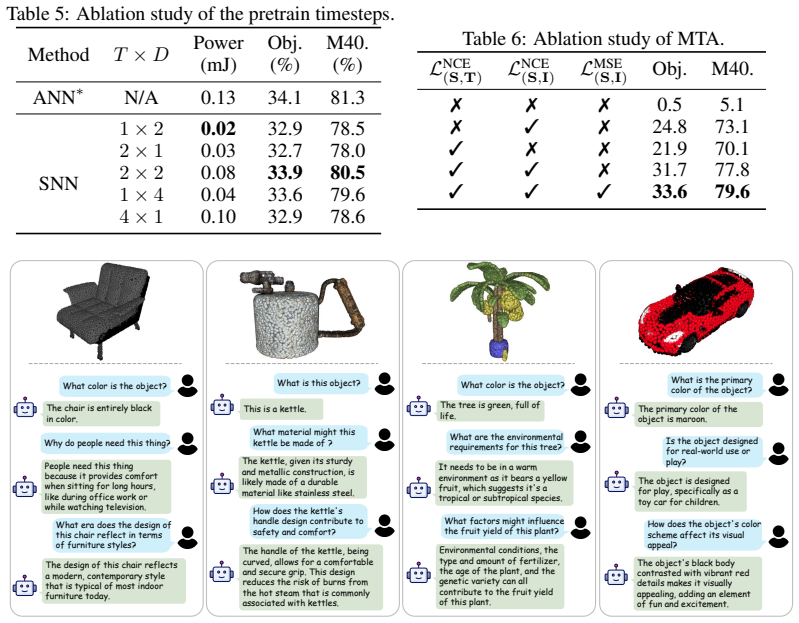
- The framework supports open-world 3D question answering without task-specific retraining.
Where Pith is reading between the lines
- The re-parameterization step could allow the same pretrained weights to run on resource-constrained edge devices that lack floating-point units.
- Extending the triplet alignment to include temporal sequences might improve handling of dynamic 3D scenes such as video-based navigation.
- If the alignment proves robust, similar contrastive pretraining could be applied to other spiking modalities like audio or tactile sensing.
Load-bearing premise
The contrastive alignment learned from the chosen 3D-image-text triplets will transfer to new open-world 3D tasks without domain-specific biases or undisclosed tuning.
What would settle it
A test on a 3D dataset drawn from a different distribution, such as indoor scenes after training on outdoor data, showing accuracy falling below prior spiking baselines would falsify the generalization claim.
Figures


read the original abstract
Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. However, existing SNNs still exhibit a significant performance gap compared to Artificial Neural Networks (ANNs) due to inadequate pre-training strategies. These limitations manifest as restricted generalization ability, task specificity, and a lack of multimodal understanding, particularly in challenging tasks such as multimodal question answering and zero-shot 3D classification. To overcome these challenges, we propose a Spike-based Vision-Language (SVL) pretraining framework that empowers SNNs with open-world 3D understanding while maintaining spike-driven efficiency. SVL introduces two key components: (i) Multi-scale Triple Alignment (MTA) for label-free triplet-based contrastive learning across 3D, image, and text modalities, and (ii) Re-parameterizable Vision-Language Integration (Rep-VLI) to enable lightweight inference without relying on large text encoders. Extensive experiments show that SVL achieves a top-1 accuracy of 85.4% in zero-shot 3D classification, surpassing advanced ANN models, and consistently outperforms prior SNNs on downstream tasks, including 3D classification (+6.1%), DVS action recognition (+2.1%), 3D detection (+1.1%), and 3D segmentation (+2.1%) with remarkable efficiency. Moreover, SVL enables SNNs to perform open-world 3D question answering, sometimes outperforming ANNs. To the best of our knowledge, SVL represents the first scalable, generalizable, and hardware-friendly paradigm for 3D open-world understanding, effectively bridging the gap between SNNs and ANNs in complex open-world understanding tasks. Code is available https://github.com/bollossom/SVL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SVL, a spike-based vision-language pretraining framework for SNNs targeting efficient 3D open-world understanding. It introduces Multi-scale Triple Alignment (MTA) for label-free triplet contrastive learning across 3D, image, and text modalities and Re-parameterizable Vision-Language Integration (Rep-VLI) to support lightweight inference without large text encoders. Reported results include 85.4% top-1 accuracy on zero-shot 3D classification (surpassing advanced ANN models), plus gains on downstream tasks (3D classification +6.1%, DVS action recognition +2.1%, 3D detection +1.1%, 3D segmentation +2.1%), with additional capability for open-world 3D question answering. Code is released.
Significance. If the performance numbers are robust and the efficiency gains are realized through the SNN pipeline and Rep-VLI without reliance on unreplaced large encoders at test time, the work could meaningfully advance energy-efficient multimodal 3D models and reduce the SNN-ANN gap in open-world settings. Code availability aids reproducibility.
major comments (2)
- [3.2] §3.2: The zero-shot 3D classification protocol yielding 85.4% top-1 accuracy does not explicitly confirm that only the re-parameterized Rep-VLI branch is active at inference while the large text encoder is disabled. This detail is load-bearing for the efficiency, hardware-friendly, and superiority-over-ANN claims, as the numerical result cannot otherwise be attributed to the proposed SNN+SVL pipeline rather than a standard CLIP-style encoder.
- [4] §4 (experimental results): The reported percentage improvements on downstream tasks lack accompanying details on run count, variance, or statistical tests. Without these, the cross-task outperformance claims over prior SNNs rest on single-point comparisons whose robustness cannot be assessed.
minor comments (2)
- [Abstract] The abstract and §1 refer to 'remarkable efficiency' without providing concrete metrics (e.g., energy per inference or latency) relative to the ANN and SNN baselines.
- [3.1] Notation for the multi-scale alignment weights should be introduced once and used consistently; the current description leaves their exact functional form ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [3.2] §3.2: The zero-shot 3D classification protocol yielding 85.4% top-1 accuracy does not explicitly confirm that only the re-parameterized Rep-VLI branch is active at inference while the large text encoder is disabled. This detail is load-bearing for the efficiency, hardware-friendly, and superiority-over-ANN claims, as the numerical result cannot otherwise be attributed to the proposed SNN+SVL pipeline rather than a standard CLIP-style encoder.
Authors: We appreciate the referee for highlighting this important clarification. The Rep-VLI component is specifically introduced to re-parameterize the vision-language fusion learned during pretraining, so that the large text encoder can be removed entirely at inference. The zero-shot 3D classification protocol uses only the SNN with the re-parameterized Rep-VLI branch; the text encoder participates solely in the MTA pretraining stage. To make this explicit and remove any ambiguity, we will add a dedicated paragraph in Section 3.2 describing the inference pipeline and insert a confirming statement in the experimental setup section. These changes will appear in the revised manuscript. revision: yes
-
Referee: [4] §4 (experimental results): The reported percentage improvements on downstream tasks lack accompanying details on run count, variance, or statistical tests. Without these, the cross-task outperformance claims over prior SNNs rest on single-point comparisons whose robustness cannot be assessed.
Authors: We thank the referee for this observation. The current manuscript reports the percentage gains from primary experimental runs without variance or run-count information. We agree that providing these details would better substantiate the robustness of the improvements. In the revised version we will rerun the key downstream experiments with three independent random seeds, report mean and standard deviation for each metric, and add a brief note on the consistency of the observed gains across runs. revision: yes
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper introduces SVL as a pretraining method with MTA contrastive alignment and Rep-VLI reparameterization, then reports measured accuracies on standard datasets (e.g., 85.4% zero-shot 3D classification, +6.1% on 3D classification). These are presented as experimental outcomes, not as mathematical predictions or first-principles derivations that reduce to the inputs by construction. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The work is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work to force its central claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-scale alignment weights
axioms (1)
- domain assumption Spiking neural networks can be effectively optimized with contrastive objectives originally developed for artificial neural networks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Multi-scale Triple Alignment (MTA) for label-free triplet-based contrastive learning across 3D, image, and text modalities... LNCE(S,T) + LNCE(S,I) + LMSE(S,I)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Re-parameterizable Vision-Language Integration (Rep-VLI)... W_L_i = e^τ E_T_θ(T^t_i)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards spike-based machine intelligence with neuromorphic computing
Kaushik Roy, Akhilesh Jaiswal, Priyadarshini Panda, and ruijie zhu. Towards spike-based machine intelligence with neuromorphic computing. Nature, 575(7784):607–617, 2019
work page 2019
-
[2]
Towards artificial general intelligence with hybrid tianjic chip architecture
Jing Pei, Lei Deng, Sen Song, Mingguo Zhao, Youhui Zhang, Shuang Wu, Guanrui Wang, Zhe Zou, Zhenzhi Wu, Wei He, et al. Towards artificial general intelligence with hybrid tianjic chip architecture. Nature, 572(7767):106–111, 2019
work page 2019
-
[3]
Networks of spiking neurons: the third generation of neural network models
Wolfgang Maass. Networks of spiking neurons: the third generation of neural network models. Neural networks, 10(9):1659–1671, 1997
work page 1997
-
[4]
Spike-based dynamic computing with asynchronous sensing-computing neuromorphic chip
Man Yao, Ole Richter, Guangshe Zhao, Ning Qiao, Yannan Xing, Dingheng Wang, Tianxiang Hu, Wei Fang, Tugba Demirci, Michele De Marchi, et al. Spike-based dynamic computing with asynchronous sensing-computing neuromorphic chip. Nature Communications, 15(1):4464, 2024
work page 2024
-
[5]
Efficient 3d recognition with event-driven spike sparse convolution
Xuerui Qiu, Man Yao, Jieyuan Zhang, Yuhong Chou, Ning Qiao, Shibo Zhou, Bo Xu, and Guoqi Li. Efficient 3d recognition with event-driven spike sparse convolution. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 39, pages 20086–20094, 2025
work page 2025
-
[6]
Scaling spike-driven transformer with efficient spike firing approximation training
Man Yao, Xuerui Qiu, Tianxiang Hu, Jiakui Hu, Yuhong Chou, Keyu Tian, Jianxing Liao, Luziwei Leng, Bo Xu, and Guoqi Li. Scaling spike-driven transformer with efficient spike firing approximation training. IEEE Transactions on Pattern Analysis and Machine Intelligence, (01):1–18, 2025
work page 2025
-
[7]
Spikformer v2: Join the high accuracy club on imagenet with an snn ticket
Zhaokun Zhou, Kaiwei Che, Wei Fang, Keyu Tian, Yuesheng Zhu, Shuicheng Yan, Yonghong Tian, and Li Yuan. Spikformer v2: Join the high accuracy club on imagenet with an snn ticket. arXiv preprint arXiv:2401.02020, 2024
-
[8]
Chankyu Lee, Priyadarshini Panda, Gopalakrishnan Srinivasan, and Kaushik Roy. Training deep spiking convolutional neural networks with stdp-based unsupervised pre-training followed by supervised fine-tuning. Frontiers in Neuroscience, 12:435, 2018
work page 2018
-
[9]
Spikebert: A language spikformer trained with two-stage knowl- edge distillation from bert
Changze Lv, Tianlong Li, Jianhan Xu, Chenxi Gu, Zixuan Ling, Cenyuan Zhang, Xiaoqing Zheng, and Xuanjing Huang. Spikebert: A language spikformer trained with two-stage knowl- edge distillation from bert. arXiv preprint arXiv:2308.15122, 2023
-
[10]
Spikingbert: Distilling bert to train spiking language models using implicit differentiation
Malyaban Bal and Abhronil Sengupta. Spikingbert: Distilling bert to train spiking language models using implicit differentiation. In Proceedings of the AAAI conference on artificial intelligence (AAAI), volume 38, pages 10998–11006, 2024
work page 2024
-
[11]
Spikeclip: A contrastive language-image pretrained spiking neural network
Changze Lv, Tianlong Li, Wenhao Liu, Yufei Gu, Jianhan Xu, Cenyuan Zhang, Muling Wu, Xiaoqing Zheng, and Xuanjing Huang. Spikeclip: A contrastive language-image pretrained spiking neural network. Neural Networks, page 107475, 2025
work page 2025
-
[12]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. In European Conference on Computer Vision (ECCV), pages 131–147, 2024
work page 2024
-
[13]
A. Radford, J. W. Kim, C. Hallacy, and et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML), pages 8748–8763. PMLR, 2021
work page 2021
-
[14]
Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding
Le Xue, Mingfei Gao, Chen Xing, Roberto Mart’in-Mart’in, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1179–1189, 2023. 10
work page 2023
-
[15]
Ulip-2: Towards scalable multimodal pre-training for 3d understanding
Le Xue, Ning Yu, Shu Zhang, Artemis Panagopoulou, Junnan Li, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, et al. Ulip-2: Towards scalable multimodal pre-training for 3d understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27091–27101, 2024
work page 2024
-
[16]
Openshape: Scaling up 3d shape representation towards open-world understanding
Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xuanlin Li, Shizhong Han, Hong Cai, Fatih Porikli, and Hao Su. Openshape: Scaling up 3d shape representation towards open-world understanding. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, pages 44860–44879, 2023
work page 2023
-
[17]
A synaptic model of memory: long-term potentiation in the hippocampus
Tim VP Bliss and Graham L Collingridge. A synaptic model of memory: long-term potentiation in the hippocampus. Nature, 361(6407):31–39, 1993
work page 1993
-
[18]
Spikformer: When spiking neural network meets transformer
Zhaokun Zhou, Yuesheng Zhu, Chao He, Yaowei Wang, Shuicheng YAN, Yonghong Tian, and Li Yuan. Spikformer: When spiking neural network meets transformer. In The Eleventh International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[19]
Pointclip: Point cloud understanding by clip
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Jiao Qiao, Peng Gao, and Hongsheng Li. Pointclip: Point cloud understanding by clip. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8542–8552, 2021
work page 2021
-
[20]
Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning
Xiangyang Zhu, Renrui Zhang, Bowei He, Ziyu Guo, Ziyao Zeng, Zipeng Qin, Shanghang Zhang, and Peng Gao. Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning. IEEE/CVF International Conference on Computer Vision (ICCV), pages 2639–2650, 2022
work page 2022
-
[21]
Clip2: Contrastive language-image-point pretraining from real-world point cloud data
Yi Zeng, Chenhan Jiang, Jiageng Mao, Jianhua Han, Chao Ye, Qingqiu Huang, Dit-Yan Yeung, Zhen Yang, Xiaodan Liang, and Hang Xu. Clip2: Contrastive language-image-point pretraining from real-world point cloud data. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15244–15253, 2023
work page 2023
-
[22]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 652–660, 2017
work page 2017
-
[23]
Space-time event clouds for ges- ture recognition: From rgb cameras to event cameras
Qinyi Wang, Yexin Zhang, Junsong Yuan, and Yilong Lu. Space-time event clouds for ges- ture recognition: From rgb cameras to event cameras. In 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1826–1835. IEEE, 2019
work page 2019
-
[24]
3d shapenets: A deep representation for volumetric shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1912–1920, 2015
work page 1912
-
[25]
Spiking pointnet: Spiking neural networks for point clouds
Dayong Ren, Zhe Ma, Yuanpei Chen, Weihang Peng, Xiaode Liu, Yuhan Zhang, and Yufei Guo. Spiking pointnet: Spiking neural networks for point clouds. Advances in Neural Information Processing Systems (NeurIPS), 36:41797–41808, 2024
work page 2024
-
[26]
Point-to-spike residual learning for energy-efficient 3d point cloud classification
Qiaoyun Wu, Quanxiao Zhang, Chunyu Tan, Yun Zhou, and Changyin Sun. Point-to-spike residual learning for energy-efficient 3d point cloud classification. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 38, pages 6092–6099, 2024
work page 2024
-
[27]
Spikingpoint: Rethink- ing point as spike for efficient 3d point cloud analysis
Zhaokun Zhou, Yijie Lu, Jiaqiyu Zhan, Guibo Luo, and Yuesheng Zhu. Spikingpoint: Rethink- ing point as spike for efficient 3d point cloud analysis. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
work page 2025
-
[28]
Brain inspired computing: A systematic survey and future trends
Guoqi Li, Lei Deng, Huajing Tang, Gang Pan, Yonghong Tian, Kaushik Roy, and Wolfgang Maass. Brain inspired computing: A systematic survey and future trends. Authorea Preprints, 2023
work page 2023
-
[29]
Spatio-temporal backpropagation for training high-performance spiking neural networks
Yujie Wu, Lei Deng, Guoqi Li, Jun Zhu, and Luping Shi. Spatio-temporal backpropagation for training high-performance spiking neural networks. Frontiers in Neuroscience, 12:331, 2018. 11
work page 2018
-
[30]
Xinhao Luo, Man Yao, Yuhong Chou, Bo Xu, and Guoqi Li. Integer-valued training and spike-driven inference spiking neural network for high-performance and energy-efficient object detection. arXiv preprint arXiv:2407.20708, 2024
-
[31]
Quantized spike-driven transformer
Xuerui Qiu, Jieyuan Zhang, Wenjie Wei, Honglin Cao, Junsheng Guo, Rui-Jie Zhu, Yimeng Shan, Yang Yang, Malu Zhang, and Haizhou Li. Quantized spike-driven transformer. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[32]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
work page 2016
-
[33]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[34]
A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[35]
Representation Learning with Contrastive Predictive Coding
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. ArXiv, abs/1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Towards open world active learning for 3d object detection
Zhuoxiao Chen, Yadan Luo, Zixin Wang, Zijian Wang, Xin Yu, and Zi Huang. Towards open world active learning for 3d object detection. arXiv preprint arXiv:2310.10391, 2023
-
[37]
Ego- lifter: Open-world 3d segmentation for egocentric perception
Qiao Gu, Zhaoyang Lv, Duncan Frost, Simon Green, Julian Straub, and Chris Sweeney. Ego- lifter: Open-world 3d segmentation for egocentric perception. In European Conference on Computer Vision (ECCV), pages 382–400. Springer, 2025
work page 2025
-
[38]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip, 2021
work page 2021
-
[39]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (ICCV), pages 19313–19322, 2022
work page 2022
-
[40]
Submanifold Sparse Convolutional Networks
Benjamin Graham, Laurens Van der Maaten, Zhu Ruijie, and Li Guoqi. Submanifold sparse convolutional networks. arXiv preprint arXiv:1706.01307, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13142–13153, 2023
work page 2023
-
[42]
Attention spiking neural networks
Man Yao, Guangshe Zhao, Hengyu Zhang, Yifan Hu, Lei Deng, Yonghong Tian, Bo Xu, and Guoqi Li. Attention spiking neural networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(8):9393–9410, 2023
work page 2023
-
[43]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Albert Li, Pascale Fung, and Steven C. H. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023
work page 2023
-
[45]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, pages 34892–34916, 2023. 12
work page 2023
-
[46]
Mikaela Angelina Uy, Quang-Hieu Pham, Binh-Son Hua, Thanh Nguyen, and Sai-Kit Yeung. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In IEEE/CVF International Conference on Computer Vision (ICCV), pages 1588–1597, 2019
work page 2019
-
[47]
Semantickitti: A dataset for semantic scene understanding of lidar sequences
Jens Behley, Martin Garbade, Andres Milioto, Jan Quenzel, Sven Behnke, Cyrill Stachniss, and Jurgen Gall. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9297–9307, 2019
work page 2019
-
[49]
A low power, fully event-based gesture recognition system
Arnon Amir, Brian Taba, David Berg, Timothy Melano, Jeffrey McKinstry, Carmelo Di Nolfo, Tapan Nayak, Alexander Andreopoulos, Guillaume Garreau, Marcela Mendoza, et al. A low power, fully event-based gesture recognition system. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7243–7252, 2017
work page 2017
-
[50]
Neuromorphic vision datasets for pedestrian detection, action recognition, and fall detection
Shu Miao, Guang Chen, Xiangyu Ning, Yang Zi, Kejia Ren, Zhenshan Bing, and Alois Knoll. Neuromorphic vision datasets for pedestrian detection, action recognition, and fall detection. Frontiers in Neurorobotics, 13:38, 2019
work page 2019
-
[51]
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 16259–16268, 2021
work page 2021
-
[52]
Efficient converted spiking neural network for 3d and 2d classification
Yuxiang Lan, Yachao Zhang, Xu Ma, Yanyun Qu, and Yun Fu. Efficient converted spiking neural network for 3d and 2d classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9211–9220, 2023
work page 2023
-
[53]
A free lunch from ann: Towards efficient, accurate spiking neural networks calibration
Yuhang Li, Shikuang Deng, Xin Dong, Ruihao Gong, and Shi Gu. A free lunch from ann: Towards efficient, accurate spiking neural networks calibration. In International conference on machine learning (ICML), pages 6316–6325. PMLR, 2021
work page 2021
-
[54]
Gated attention coding for training high-performance and efficient spiking neural networks
Xuerui Qiu, Rui-Jie Zhu, Yuhong Chou, Zhaorui Wang, Liang-jian Deng, and Guoqi Li. Gated attention coding for training high-performance and efficient spiking neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume 38, pages 601–610, 2024
work page 2024
-
[55]
Online training through time for spiking neural networks
Mingqing Xiao, Qingyan Meng, Zongpeng Zhang, Di He, and Zhouchen Lin. Online training through time for spiking neural networks. Advances in Neural Information Processing Systems (NeurIPS), 35:20717–20730, 2022
work page 2022
-
[56]
JiaKui Hu, Man Yao, Xuerui Qiu, Yuhong Chou, Yuxuan Cai, Ning Qiao, Yonghong Tian, Bo Xu, and Guoqi Li. High-performance temporal reversible spiking neural networks with o(l) training memory and o(1) inference cost. arXiv preprint arXiv:2405.16466, 2024
-
[57]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (ICCV), pages 5828–5839, 2017
work page 2017
-
[58]
3d-llm: Injecting the 3d world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, pages 44860–44879, 2023
work page 2023
-
[59]
Ziyu Guo, Renrui Zhang, Xiangyang Zhu, Yiwen Tang, Xianzheng Ma, Jiaming Han, Kexin Chen, Peng Gao, Xianzhi Li, Hongsheng Li, et al. Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following. arXiv preprint arXiv:2309.00615, 2023. 13
-
[60]
Direct training for spiking neural networks: Faster, larger, better
Yujie Wu, Lei Deng, Guoqi Li, Jun Zhu, Yuan Xie, and Luping Shi. Direct training for spiking neural networks: Faster, larger, better. In Proceedings of the AAAI conference on artificial intelligence (AAAI), volume 33, pages 1311–1318, 2019
work page 2019
-
[61]
1.1 computing’s energy problem (and what we can do about it)
Mark Horowitz. 1.1 computing’s energy problem (and what we can do about it). In 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), pages 10–14. IEEE, 2014
work page 2014
-
[62]
Nitin Rathi and Kaushik Roy. Diet-snn: A low-latency spiking neural network with direct input encoding and leakage and threshold optimization. IEEE Transactions on Neural Networks and Learning Systems, 34(6):3174–3182, 2021
work page 2021
-
[63]
Vtsnn: a virtual temporal spiking neural network
Xue-Rui Qiu, Zhao-Rui Wang, Zheng Luan, Rui-Jie Zhu, Xiao Wu, Ma-Lu Zhang, and Liang- Jian Deng. Vtsnn: a virtual temporal spiking neural network. Frontiers in Neuroscience, 17:1091097, 2023
work page 2023
-
[64]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, Raquel Urtasun, and ruijie zhu. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3354–3361, 2012
work page 2012
-
[65]
V oxel r-cnn: Towards high performance voxel-based 3d object detection
Jiajun Deng, Shaoshuai Shi, Peiwei Li, Wengang Zhou, Yanyong Zhang, and Houqiang Li. V oxel r-cnn: Towards high performance voxel-based 3d object detection. InProceedings of the AAAI conference on artificial intelligence (AAAI), volume 35, pages 1201–1209, 2021
work page 2021
-
[66]
Openpcdet: An open-source toolbox for 3d object detection from point clouds, 2020
OpenPCDet Development Team. Openpcdet: An open-source toolbox for 3d object detection from point clouds, 2020
work page 2020
-
[67]
Pointcept: A codebase for point cloud perception research, 2023
Pointcept Contributors. Pointcept: A codebase for point cloud perception research, 2023
work page 2023
-
[68]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, Silvio Savarese, and zhu ruijie. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Rattern Recognition (CVPR), pages 3075–3084, 2019
work page 2019
-
[69]
Masked scene contrast: A scalable framework for unsupervised 3d representation learning
Xiaoyang Wu, Xin Wen, Xihui Liu, and Hengshuang Zhao. Masked scene contrast: A scalable framework for unsupervised 3d representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Rattern Recognition (CVPR), pages 9415–9424, 2023. 14 Appendix A Backpropagation process of I-LIF There exist two primary methods of training high-pe...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.