Adapting Foundation Vision-Language Models to Medical Diagnosis via Query-Driven Expert Bridging
Pith reviewed 2026-05-22 01:40 UTC · model grok-4.3
The pith
MedBridge adapts vision-language models to medical diagnosis by injecting learnable query tokens that align domains and route expert models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedBridge transforms pretrained VLMs into multi-view query encoders that inject a compact set of learnable query tokens into intermediate layers, enabling non-destructive domain alignment while preserving fine-grained pathological cues via multi-view high-resolution sampling. These query tokens further act as routing signals for a mixture-of-experts, dynamically integrating heterogeneous foundation models for multi-label reasoning without requiring a shared representation space.
What carries the argument
Compact set of learnable query tokens injected into intermediate VLM layers that perform domain alignment and serve as dynamic routing signals for a mixture-of-experts.
If this is right
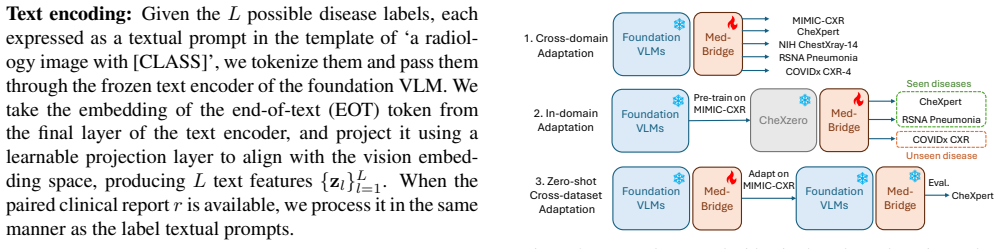
- MedBridge yields 6-15% AUC gains over prior adaptation methods on five chest radiograph datasets for multi-label thoracic disease diagnosis.
- The gains appear in both cross-domain generalization and same-distribution fine-tuning settings.
- The framework works across at least eight different pretrained VLMs without modification to the core approach.
- It removes the requirement to train large medical-specific models from scratch on limited clinical data.
Where Pith is reading between the lines
- The same query-token routing might allow combining models trained on entirely different imaging modalities more readily than methods that force a common embedding space.
- If the number of query tokens can be kept small while retaining performance, the method could scale to even larger foundation models with minimal added compute.
- The multi-view sampling step suggests that resolution handling might be separable from the alignment step in future adaptations of other vision tasks.
Load-bearing premise
A small number of learnable query tokens placed in intermediate layers can align domains and preserve pathological details without destroying original model knowledge or requiring a shared space across experts.
What would settle it
Evaluating MedBridge on the same five chest radiograph benchmarks and obtaining AUC gains below 6% or no gain over strong baseline adaptation methods would show the performance claim does not hold.
Figures



read the original abstract
Vision-language foundation models achieve promising performance in natural image classification, yet their direct application to medical imaging is limited by severe domain shifts, resolution mismatches, and the multi-label nature of clinical diagnosis. Training dedicated medical foundation models from scratch, however, is costly and data-intensive. Here, we propose MedBridge, a lightweight adaptation framework that opens a new direction in domain-gap mitigation by jointly combining domain alignment, resolution preservation, and multi-label reasoning via complementary VLM experts for medical image diagnosis. Specifically, MedBridge transforms pretrained VLMs into multi-view query encoders that inject a compact set of learnable query tokens into intermediate layers, enabling non-destructive domain alignment while preserving fine-grained pathological cues via multi-view high-resolution sampling. These query tokens further act as routing signals for a mixture-of-experts, dynamically integrating heterogeneous foundation models for multi-label reasoning without requiring a shared representation space. We evaluated MedBridge on five chest radiograph benchmarks in three key adaptation tasks. MedBridge demonstrates superior performance in both cross-domain generalization (out-of-distribution transfer) and in-domain specialization (same-distribution tuning) settings, yielding a significant 6-15% AUC improvement over state-of-the-art adaptation methods for multi-label thoracic disease diagnosis. Furthermore, MedBridge is model-agnostic and demonstrates broad extensibility across eight diverse VLMs (e.g., CLIP, LLaVA, Qwen-VL, MedGemma), highlighting its ability to flexibly adapt arbitrary foundation models into a powerful medical diagnostic tool. Our code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MedBridge, a lightweight adaptation framework that transforms pretrained vision-language models into multi-view query encoders by injecting a compact set of learnable query tokens into intermediate layers. These tokens enable non-destructive domain alignment while preserving fine-grained pathological cues via multi-view high-resolution sampling, and additionally serve as routing signals for a mixture-of-experts that dynamically integrates heterogeneous VLMs for multi-label reasoning without requiring a shared representation space. The framework is evaluated on five chest radiograph benchmarks across cross-domain generalization and in-domain specialization tasks, reporting 6-15% AUC gains over state-of-the-art adaptation methods, with extensibility demonstrated across eight VLMs including CLIP, LLaVA, Qwen-VL, and MedGemma.
Significance. If the reported results hold, this work offers a practical and scalable approach to bridging domain gaps in medical imaging by adapting existing foundation VLMs rather than training new models from scratch. The model-agnostic design and ability to handle both out-of-distribution transfer and in-distribution tuning while supporting multi-label diagnosis represent a meaningful advance. Explicit credit is due for the planned code release, which directly supports reproducibility and follow-on research.
minor comments (2)
- Abstract: the phrase 'three key adaptation tasks' is used without enumeration; explicitly listing these tasks (e.g., cross-domain, in-domain, and perhaps a third) would improve reader orientation from the outset.
- Experimental section: while the abstract and skeptic note indicate ablations and baselines are present, ensure that all comparison methods are referenced with citations and that any statistical significance testing for the 6-15% AUC deltas is clearly reported with p-values or confidence intervals.
Simulated Author's Rebuttal
We thank the referee for the supportive review and recommendation for minor revision. We appreciate the recognition of MedBridge's practical contributions to VLM adaptation for medical diagnosis, including its model-agnostic nature and extensibility. No specific major comments were provided in the report, so we will incorporate minor improvements for clarity and presentation in the revised manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper introduces MedBridge as an empirical adaptation framework relying on learnable query tokens injected into VLMs and dynamic expert routing for medical diagnosis. All performance claims (6-15% AUC gains) are grounded in direct experimental evaluation across five external benchmarks, multiple VLMs, and both in-domain and cross-domain splits. No derivation chain, equations, or first-principles predictions are presented that reduce outputs to fitted parameters, self-defined quantities, or self-citation chains by construction. The architecture and results remain self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable query tokens
axioms (1)
- domain assumption Pretrained VLMs contain transferable features that can be aligned to medical domains via lightweight query injection without destructive modification.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Query-Encoder (QEncoder): The QEncoder adds Q learnable queries Q={q_i} to interact with the M frozen tokens M={m_i} from foundation VLMs... Zi = [Mi;Qi] + MHSA(Norm([Mi;Qi]))
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mixture of Experts (MoE): ... gating network G ... gk(QG) = exp(w_k^T QG + b_k) / sum ... v = sum gk(QG) * a_k
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. Openflamingo: An open- source framework for training large autoregressive vision- language models.arXiv preprint arXiv:2308.01390, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hin- ton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven QH Truong, Chu The Chuong, and Curtis P Langlotz. Chexpert plus: Augmenting a large chest x-ray dataset with text ra- diology reports, patient demographics and additional image formats.arXiv preprint arXiv:2405.19538, 2024. 5, 6, 8
-
[4]
Adapting pretrained vision-language foundational models to medical imaging do- mains
Pierre Joseph Marcel Chambon, Christian Bluethgen, Cur- tis Langlotz, and Akshay Chaudhari. Adapting pretrained vision-language foundational models to medical imaging do- mains. InNeurIPS 2022 Foundation Models for Decision Making Workshop. 3
work page 2022
-
[5]
Meta-adapter: an online few-shot learner for vision-language model
Cheng Cheng, Lin Song, Ruoyi Xue, Hang Wang, Hongbin Sun, Yixiao Ge, and Ying Shan. Meta-adapter: an online few-shot learner for vision-language model. InProceedings of the 37th International Conference on Neural Information Processing Systems, pages 55361–55374, 2023. 1
work page 2023
-
[6]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023. 1, 2
work page 2023
-
[7]
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters.International Journal of Computer Vision, 132(2): 581–595, 2024. 1, 2, 5, 6, 7
work page 2024
-
[8]
Gemini: A Family of Highly Capable Multimodal Models
Team Gemini. Gemini: A family of highly capable multi- modal models.arXiv preprint arXiv:2312.11805, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Mmrl: Multi-modal rep- resentation learning for vision-language models
Yuncheng Guo and Xiaodong Gu. Mmrl: Multi-modal rep- resentation learning for vision-language models. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 1, 2, 5, 6, 7
work page 2025
-
[10]
Gregory Holste, Yiliang Zhou, Song Wang, Ajay Jaiswal, Mingquan Lin, Sherry Zhuge, Yuzhe Yang, Dongkyun Kim, Trong-Hieu Nguyen-Mau, Minh-Triet Tran, et al. Towards long-tailed, multi-label disease classification from chest x- ray: Overview of the cxr-lt challenge.Medical Image Anal- ysis, page 103224, 2024. 1
work page 2024
-
[11]
Adapting visual-language models for generalizable anomaly detection in medical im- ages
Chaoqin Huang, Aofan Jiang, Jinghao Feng, Ya Zhang, Xin- chao Wang, and Yanfeng Wang. Adapting visual-language models for generalizable anomaly detection in medical im- ages. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 11375–11385,
-
[12]
Shih-Cheng Huang, Liyue Shen, Matthew P Lungren, and Serena Yeung. Gloria: A multimodal global-local represen- tation learning framework for label-efficient medical image recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 3942–3951, 2021. 3
work page 2021
-
[13]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InProceedings of the 38th International Conference on Machine Learning, pages 4904–4916. PMLR, 2021. 1
work page 2021
-
[14]
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de- identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019. 5, 6, 7, 8
work page 2019
-
[15]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
work page 2023
-
[16]
Less could be better: Parameter-efficient fine-tuning advances medical vision foundation models
Chenyu Lian, Hong-Yu Zhou, Yizhou Yu, and Liansheng Wang. Less could be better: Parameter-efficient fine-tuning advances medical vision foundation models. InMedical Imaging with Deep Learning, 2024. 3
work page 2024
-
[17]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Haotian Liu, Chunyuan Li, Yuhang Li, and Yong Jae Lee. Visual instruction tuning.arXiv preprint arXiv:2304.08485,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without super- vision.Transactions on Machine Learning Research, 2024. 5
work page 2024
-
[20]
Radia- log: Large vision-language models for x-ray reporting and dialog-driven assistance
Chantal Pellegrini, Ege ¨Ozsoy, Benjamin Busam, Benedikt Wiestler, Nassir Navab, and Matthias Keicher. Radia- log: Large vision-language models for x-ray reporting and dialog-driven assistance. InMedical Imaging with Deep Learning, 2025. 3
work page 2025
-
[21]
Fernando P ´erez-Garc´ıa, Harshita Sharma, Sam Bond-Taylor, Kenza Bouzid, Valentina Salvatelli, Maximilian Ilse, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Matthew P Lungren, et al. Exploring scalable medical image encoders beyond text supervision.Nature Machine Intelligence, pages 1–12, 2025. 3
work page 2025
-
[22]
Vu Minh Hieu Phan, Yutong Xie, Yuankai Qi, Lingqiao Liu, Liyang Liu, Bowen Zhang, Zhibin Liao, Qi Wu, Minh- Son To, and Johan W Verjans. Decomposing disease de- scriptions for enhanced pathology detection: A multi-aspect vision-language pre-training framework. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11492...
work page 2024
-
[23]
Ex- 10 ploring transfer learning in medical image segmentation us- ing vision-language models
Kanchan Poudel, Manish Dhakal, Prasiddha Bhandari, Ra- bin Adhikari, Safal Thapaliya, and Bishesh Khanal. Ex- 10 ploring transfer learning in medical image segmentation us- ing vision-language models. InMedical Imaging with Deep Learning, pages 1142–1165. PMLR, 2024. 1, 3
work page 2024
-
[24]
Medical image understanding with pretrained vision language mod- els: A comprehensive study
Ziyuan Qin, Huahui Yi, Qicheng Lao, and Kang Li. Medical image understanding with pretrained vision language mod- els: A comprehensive study. InThe Eleventh International Conference on Learning Representations. 1, 3
-
[25]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 2, 5, 6, 7
work page 2021
-
[26]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural in- formation processing systems, 35:25278–25294, 2022. 2
work page 2022
-
[27]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroen- sri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C ´ıan Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025. 2, 3, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Laleh Seyyed-Kalantari, Haoran Zhang, Matthew BA Mc- Dermott, Irene Y Chen, and Marzyeh Ghassemi. Under- diagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations.Na- ture medicine, 27(12):2176–2182, 2021. 5
work page 2021
-
[29]
Few-shot adaptation of medical vision-language models
Fereshteh Shakeri, Yunshi Huang, Julio Silva-Rodr ´ıguez, Houda Bahig, An Tang, Jose Dolz, and Ismail Ben Ayed. Few-shot adaptation of medical vision-language models. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 553–563. Springer,
-
[30]
George Shih, Carol C Wu, Safwan S Halabi, Marc D Kohli, Luciano M Prevedello, Tessa S Cook, Arjun Sharma, Judith K Amorosa, Veronica Arteaga, Maya Galperin- Aizenberg, et al. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possi- ble pneumonia.Radiology: Artificial Intelligence, 1(1): e180041, 2019. 5, 6, 8
work page 2019
-
[31]
Vision-language model selection and reuse for downstream adaptation
Hao-Zhe Tan, Zhi Zhou, Yu-feng Li, and Lan-Zhe Guo. Vision-language model selection and reuse for downstream adaptation. InForty-second International Conference on Machine Learning, 2025. 1
work page 2025
-
[32]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi `ere, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and tech- nology.arXiv preprint arXiv:2403.08295, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Ekin Tiu, Ellie Talius, Pujan Patel, Curtis P Langlotz, An- drew Y Ng, and Pranav Rajpurkar. Expert-level detection of pathologies from unannotated chest x-ray images via self- supervised learning.Nature biomedical engineering, 6(12): 1399–1406, 2022. 2, 3, 5, 7, 8
work page 2022
-
[34]
Fuying Wang, Yuyin Zhou, Shujun Wang, Varut Vardhanab- huti, and Lequan Yu. Multi-granularity cross-modal align- ment for generalized medical visual representation learn- ing.Advances in Neural Information Processing Systems, 35:33536–33549, 2022. 3
work page 2022
-
[35]
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mo- hammadhadi Bagheri, and Ronald M Summers. Chestx- ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2097–2106,
work page 2097
-
[36]
Medclip: Contrastive learning from unpaired medi- cal images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medi- cal images and text. InProceedings of the Conference on Empirical Methods in Natural Language Processing. Con- ference on Empirical Methods in Natural Language Process- ing, page 3876, 2022. 3
work page 2022
-
[37]
Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 21372–21383, 2023. 3
work page 2023
-
[38]
Yifan Wu, Hayden Gunraj, Chi-en Amy Tai, and Alexan- der Wong. Covidx cxr-4: An expanded multi-institutional open-source benchmark dataset for chest x-ray image- based computer-aided covid-19 diagnostics.arXiv preprint arXiv:2311.17677, 2023. 5, 6
-
[39]
Post-pre-training for modality alignment in vision-language foundation models
Shin’ya Yamaguchi, Dewei Feng, Sekitoshi Kanai, Kazuki Adachi, and Daiki Chijiwa. Post-pre-training for modality alignment in vision-language foundation models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 1
work page 2025
-
[40]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Mma: Multi-modal adapter for vision-language models
Lingxiao Yang, Ru-Yuan Zhang, Yanchen Wang, and Xiao- hua Xie. Mma: Multi-modal adapter for vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23826– 23837, 2024. 1, 2, 5, 6, 7
work page 2024
-
[42]
Visual- language prompt tuning with knowledge-guided context op- timization
Hantao Yao, Rui Zhang, and Changsheng Xu. Visual- language prompt tuning with knowledge-guided context op- timization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6757–6767,
-
[43]
Low-rank few-shot adaptation of vision-language models
Maxime Zanella and Ismail Ben Ayed. Low-rank few-shot adaptation of vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1593–1603, 2024. 2, 5, 6, 7
work page 2024
-
[44]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 1, 2, 5
work page 2023
-
[45]
Disease-informed adaptation of vision-language mod- els.IEEE Transactions on Medical Imaging, 2024
Jiajin Zhang, Ge Wang, Mannudeep K Kalra, and Pingkun Yan. Disease-informed adaptation of vision-language mod- els.IEEE Transactions on Medical Imaging, 2024. 3
work page 2024
-
[46]
Tip- 11 adapter: Training-free adaption of clip for few-shot classi- fication
Renrui Zhang, Wei Zhang, Rongyao Fang, Peng Gao, Kun- chang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. Tip- 11 adapter: Training-free adaption of clip for few-shot classi- fication. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceed- ings, Part XXXV, page 493–510. Springer-Verlag, 2022. 2
work page 2022
-
[47]
Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Weidi Xie, and Yanfeng Wang. Knowledge-enhanced visual-language pre- training on chest radiology images.Nature Communications, 14(1):4542, 2023. 3
work page 2023
-
[48]
Mediclip: Adapting clip for few-shot medical image anomaly detection
Ximiao Zhang, Min Xu, Dehui Qiu, Ruixin Yan, Ning Lang, and Xiuzhuang Zhou. Mediclip: Adapting clip for few-shot medical image anomaly detection. InInternational Confer- ence on Medical Image Computing and Computer-Assisted Intervention, pages 458–468. Springer, 2024. 1, 3
work page 2024
-
[49]
Yuhui Zhang, Shih-Cheng Huang, Zhengping Zhou, Matthew P Lungren, and Serena Yeung. Adapting pre- trained vision transformers from 2d to 3d through weight in- flation improves medical image segmentation. InMachine Learning for Health, pages 391–404. PMLR, 2022. 1, 3
work page 2022
-
[50]
Contrastive learning of medical visual representations from paired images and text
Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D Manning, and Curtis P Langlotz. Contrastive learning of medical visual representations from paired images and text. InMachine learning for healthcare conference, pages 2–25. PMLR, 2022. 3
work page 2022
-
[51]
Clip in medical imaging: A survey.Medical Image Analysis, page 103551, 2025
Zihao Zhao, Yuxiao Liu, Han Wu, Mei Wang, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Zhiming Cui, Qian Wang, et al. Clip in medical imaging: A survey.Medical Image Analysis, page 103551, 2025. 2
work page 2025
-
[52]
Conditional prompt learning for vision-language mod- els
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language mod- els. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 16816–16825,
-
[53]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
-
[54]
Yang Zhou, Tan Faith, Yanyu Xu, Sicong Leng, Xinxing Xu, Yong Liu, and Rick Siow Mong Goh. Benchx: A unified benchmark framework for medical vision-language pretrain- ing on chest x-rays.Advances in Neural Information Pro- cessing Systems, 37:6625–6647, 2024. 3
work page 2024
-
[55]
Prompt-aligned gradient for prompt tuning
Beier Zhu, Yulei Niu, Yucheng Han, Yue Wu, and Hanwang Zhang. Prompt-aligned gradient for prompt tuning. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 15659–15669, 2023. 1, 2, 5, 6, 7 12
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.