GenHSI: Controllable Generation of Human-Scene Interaction Videos
Pith reviewed 2026-05-19 07:22 UTC · model grok-4.3
The pith
A training-free pipeline generates long videos of humans interacting with scenes from a single image reference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
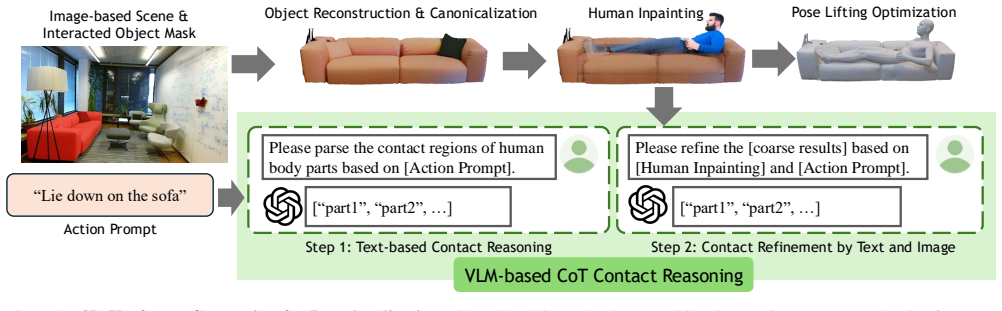
The authors claim that GenHSI is the first method to synthesize a long video sequence containing a chain of human-scene interaction actions without any training, using only image references of the scene and the character. The pipeline divides synthesis into script writing that turns complex prompts into atomic actions, pre-visualization that produces 3D keyframes by first generating 2D interactions through inpainting after view canonicalization and then lifting them to 3D via iterative optimization guided by contact cues and vision-language model reasoning, and finally animation that feeds those keyframes into a pre-trained video diffusion model to produce consistent motion with plausible 3D
What carries the argument
View canonicalization that lets pre-trained 2D inpainting models create interaction poses without multi-view fitting, followed by iterative optimization that uses contact cues and VLM reasoning to turn those poses into usable 3D keyframes.
If this is right
- Long chains of multiple human-scene interactions become feasible while preserving character identity and scene content from the input images.
- Plausible dynamics and scene affordances appear because the video diffusion model is conditioned on explicit 3D keyframes rather than text alone.
- Complex descriptions of chained actions are managed by first reducing them to a sequence of atomic steps during script writing.
- The entire process runs from single reference images without needing upfront 3D scene reconstructions or multiple camera views.
Where Pith is reading between the lines
- The same script-plus-keyframe-plus-animation structure could be tried for videos that involve several people or changing scene elements by extending the atomic action list and the keyframe stage.
- If the 2D-to-3D lifting step proves reliable, it may reduce the need for full multi-view capture when creating 3D-consistent animations in other settings.
- Applying the method to scenes whose affordances are less obvious, such as deformable objects or slippery floors, would test how far the contact and reasoning cues can stretch.
Load-bearing premise
The iterative optimization step guided by contact cues and vision-language model reasoning will reliably produce 3D poses from 2D inpaints that the video diffusion model can then animate into coherent and plausible long sequences.
What would settle it
Run the method on a sequence such as walking across a room, pulling out a chair, and sitting down, then inspect the output frames to see whether the person stays the same, feet and hands make correct contact with the floor and furniture, and no body parts pass through objects or float in air.
Figures







read the original abstract
Large-scale pre-trained video diffusion models have exhibited remarkable capabilities in diverse video generation. However, existing solutions face several challenges in generating long videos with rich human-scene interactions (HSI), including unrealistic dynamics and affordance, lack of subject identity preservation, and the need for expensive training. To this end, we propose GenHSI, a training-free method for controllable generation of long HSI videos with 3D awareness. Taking inspiration from movie animation, we subdivide the video synthesis into three stages: (1) script writing, (2) pre-visualization, and (3) animation. Given an image of a scene and a character with a user description, we use these three stages to generate long videos that preserve human identity and provide rich and plausible HSI. Script writing converts a complex text prompt involving a chain of HSI into simple atomic actions that are used in the pre-visualization stage to generate 3D keyframes. To synthesize plausible human interaction poses in 3D keyframes, we utilize pre-trained 2D inpainting diffusion models to generate plausible 2D human interactions based on view canonicalization, which eliminates the need for multi-view fitting in previous works. We then extend these interactions to 3D using robust iterative optimization, informed by contact cues and reasoning from VLMs. Prompted by these 3D keyframes, the pretrained video diffusion models can better generate consistent long videos with plausible dynamics and affordance in a 3D-aware manner. We are the first to synthesize a long video sequence with a chain of HSI actions without training based on the image references of the scene and character. Experiments demonstrate that our method can generate HSI videos that effectively preserve scene content and character identity with plausible human-scene interaction from a single image scene.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GenHSI, a training-free pipeline for controllable generation of long human-scene interaction (HSI) videos from a single scene image, character reference, and text description. It decomposes synthesis into three stages: script writing (decomposing complex HSI prompts into atomic actions), pre-visualization (generating 3D keyframes via 2D inpainting diffusion models after view canonicalization, followed by iterative 3D optimization using contact cues and VLM reasoning), and animation (conditioning pre-trained video diffusion models on the resulting keyframes). The central claim is that this produces long video sequences with chains of plausible HSI actions while preserving scene content and character identity, and that the method is the first to achieve this without training.
Significance. If the central claims hold, the work would be significant for enabling training-free, controllable synthesis of long-duration HSI videos by composing existing pre-trained models in a movie-animation-inspired pipeline. It targets open challenges in realistic dynamics, affordance, and identity preservation for applications in animation and simulation. The avoidance of multi-view fitting via view canonicalization and the integration of VLM reasoning for optimization represent potentially useful engineering contributions, though their impact depends on empirical validation.
major comments (2)
- [Experiments] Experiments section: the abstract and method description state that experiments demonstrate preservation of scene content and identity with plausible interactions, yet no quantitative metrics (e.g., FID, CLIP similarity, contact accuracy), ablation studies, or failure-case analysis are reported. This absence is load-bearing for the central claim of reliable long-sequence HSI generation.
- [Pre-visualization stage] Pre-visualization stage (method description): the iterative 3D optimization step that extends 2D inpainted poses (post-view-canonicalization) to keyframes using contact cues and VLM reasoning is asserted to be robust, but no convergence criteria, quantitative 3D-pose metrics (MPJPE, penetration rate), or analysis of local-minima escape on chained actions are supplied. This step is load-bearing for the claim that the frozen video diffusion model will produce consistent dynamics and affordance.
minor comments (2)
- [Related Work] The claim of being 'the first' to synthesize long chained HSI videos without training would benefit from a more explicit comparison table against prior training-free HSI or video-generation methods in the related-work section.
- [Method] Notation for 'view canonicalization' is introduced without a formal equation or diagram; a short definition or reference to the exact transformation would improve clarity.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We appreciate the positive assessment of the potential impact of GenHSI and the constructive criticism regarding empirical validation. We address each major comment in detail below, committing to revisions that enhance the manuscript's rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract and method description state that experiments demonstrate preservation of scene content and identity with plausible interactions, yet no quantitative metrics (e.g., FID, CLIP similarity, contact accuracy), ablation studies, or failure-case analysis are reported. This absence is load-bearing for the central claim of reliable long-sequence HSI generation.
Authors: We agree that quantitative evaluation is important for substantiating the claims of scene and identity preservation as well as plausible interactions. The current version of the manuscript relies on qualitative demonstrations through visual results. In the revision, we will introduce quantitative metrics including CLIP-based similarity scores for character identity preservation, contact accuracy measures for human-scene interactions, and FID scores for video quality where feasible. Additionally, we will conduct ablation studies on the script writing, pre-visualization, and animation stages, and include an analysis of failure cases. These additions will be presented in an expanded Experiments section. revision: yes
-
Referee: [Pre-visualization stage] Pre-visualization stage (method description): the iterative 3D optimization step that extends 2D inpainted poses (post-view-canonicalization) to keyframes using contact cues and VLM reasoning is asserted to be robust, but no convergence criteria, quantitative 3D-pose metrics (MPJPE, penetration rate), or analysis of local-minima escape on chained actions are supplied. This step is load-bearing for the claim that the frozen video diffusion model will produce consistent dynamics and affordance.
Authors: We acknowledge the need for more details and validation on the pre-visualization stage, particularly the iterative 3D optimization. In the revised manuscript, we will specify the convergence criteria used in the optimization process. We will also report quantitative 3D pose metrics such as Mean Per Joint Position Error (MPJPE) and penetration rates, evaluated against ground-truth poses where available or through proxy measures. Furthermore, we will provide analysis on how the method handles local minima in the context of chained actions, including examples and VLM reasoning steps. This will better support the claim regarding consistent dynamics in the subsequent animation stage. revision: yes
Circularity Check
No significant circularity; method composes external pre-trained models
full rationale
The paper describes a three-stage pipeline that chains existing pre-trained 2D inpainting diffusion models, VLM reasoning, iterative 3D optimization with contact cues, and a frozen video diffusion model. No equations, fitted parameters, or self-referential definitions appear in the abstract or claimed contributions. The central claim of training-free long HSI video synthesis rests on the composition of these external components rather than any derivation that reduces to its own inputs by construction. The optimization step is presented as a practical engineering choice informed by external cues, not as a mathematical result derived from the paper's own fitted quantities or prior self-citations that would create circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained 2D inpainting diffusion models can generate plausible 2D human interactions when conditioned on view-canonicalized inputs
- domain assumption VLM reasoning plus contact cues can guide iterative optimization to produce usable 3D human-scene interaction poses
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose GenHSI, a training-free method... subdividing the video synthesis into three stages: (1) script writing, (2) pre-visualization, and (3) animation... robust iterative optimization informed by contact cues
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
CoMoVi: Co-Generation of 3D Human Motions and Realistic Videos
CoMoVi co-generates 3D human motions and 2D videos synchronously in a single diffusion denoising loop using 3D-to-2D projection and dual-branch diffusion with 3D-2D cross attentions.
-
VHOI: Controllable Video Generation of Human-Object Interactions from Sparse Trajectories via Motion Densification
VHOI densifies sparse trajectories into color-encoded HOI mask sequences and conditions a fine-tuned video diffusion model on them to produce controllable human-object interaction videos, including full navigation sequences.
Reference graph
Works this paper leans on
-
[1]
Realistic vision inpainting. https://huggingface. co / Uminosachi / realisticVisionV51 _ v51VAE-inpainting. 5
-
[2]
Kling ai 1.6 elements. https : / / klingai . com / image-to-video/multi-id/ , . 2, 7
-
[3]
Kling ai 1.6 frames. https : / / klingai . com / image-to-video/frame-mode/ , . 2
-
[4]
Circle: Capture in rich contextual environments
Joao Pedro Ara ´ujo, Jiaman Li, Karthik Vetrivel, Rishi Agarwal, Jiajun Wu, Deepak Gopinath, Alexander William Clegg, and Karen Liu. Circle: Capture in rich contextual environments. In Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition , pages 21211–21221, 2023. 3
work page 2023
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Align your latents: High-resolution video syn- thesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video syn- thesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023. 2
work page 2023
-
[7]
Go-with-the-flow: Motion- controllable video diffusion models using real-time warped noise
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Mingming He, Li Ma, Yitong Deng, Lingx- iao Li, Mohsen Mousavi, et al. Go-with-the-flow: Motion- controllable video diffusion models using real-time warped noise. arXiv preprint arXiv:2501.08331, 2025. 3
-
[8]
Minghong Cai, Xiaodong Cun, Xiaoyu Li, Wenze Liu, Zhaoyang Zhang, Yong Zhang, Ying Shan, and Xiangyu Yue. Ditctrl: Exploring attention control in multi-modal diffusion transformer for tuning-free multi-prompt longer video generation. ArXiv, abs/2412.18597, 2024. 2
-
[9]
Shengqu Cai, Duygu Ceylan, Matheus Gadelha, Chun- Hao Paul Huang, Tuanfeng Y . Wang, and Gordon Wet- zstein. Generative rendering: Controllable 4d-guided video generation with 2d diffusion models. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7611–7620, 2023. 2
work page 2024
-
[10]
Gen- erating human motion in 3d scenes from text descriptions
Zhi Cen, Huaijin Pi, Sida Peng, Zehong Shen, Minghui Yang, Shuai Zhu, Hujun Bao, and Xiaowei Zhou. Gen- erating human motion in 3d scenes from text descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1855–1866, 2024. 3
work page 2024
-
[11]
Videocrafter2: Overcoming data limitations for high- quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao-Liang Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high- quality video diffusion models. 2024 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 7310–7320, 2024. 2
work page 2024
-
[12]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James T. Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- α: Fast train- ing of diffusion transformer for photorealistic text-to-image synthesis. ArXiv, abs/2310.00426, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Foundhand: Large- scale domain-specific learning for controllable hand image generation
Kefan Chen, Chaerin Min, Linguang Zhang, Shreyas Ham- pali, Cem Keskin, and Srinath Sridhar. Foundhand: Large- scale domain-specific learning for controllable hand image generation. arXiv preprint arXiv:2412.02690, 2024. 2
-
[14]
Multi-subject open-set personalization in video generation
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Yuwei Fang, Kwot Sin Lee, Ivan Skorokhodov, Kfir Aberman, Jun-Yan Zhu, Ming-Hsuan Yang, and Sergey Tulyakov. Multi-subject open-set personalization in video generation. arXiv preprint arXiv:2501.06187, 2025. 2
-
[15]
Dreamcinema: Cinematic transfer with free camera and 3d character
Weiliang Chen, Fangfu Liu, Diankun Wu, Haowen Sun, Haixu Song, and Yueqi Duan. Dreamcinema: Cinematic transfer with free camera and 3d character. arXiv preprint arXiv:2408.12601, 2024. 2
-
[16]
Jiwoo Chung, Sangeek Hyun, and Jae-Pil Heo. Style in- jection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8795–8805, 2024. 2
work page 2024
-
[17]
Peishan Cong, Ziyi Wang, Zhiyang Dou, Yiming Ren, Wei Yin, Kai Cheng, Yujing Sun, Xiaoxiao Long, Xinge Zhu, and Yuexin Ma. Laserhuman: language-guided scene- aware human motion generation in free environment.arXiv preprint arXiv:2403.13307, 2024. 2, 3
-
[18]
Dragvideo: Interactive drag-style video editing
Yufan Deng, Ruida Wang, Yuhao Zhang, Yu-Wing Tai, and Chi-Keung Tang. Dragvideo: Interactive drag-style video editing. In European Conference on Computer Vi- sion, pages 183–199. Springer, 2024. 3
work page 2024
-
[19]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning,
-
[20]
Haoqiang Fan, Hao Su, and Leonidas J. Guibas. A point set generation network for 3d object reconstruction from a single image. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2463–2471, 2016. 6
work page 2017
-
[21]
Motioncharacter: Identity-preserving and motion controllable human video generation
Haopeng Fang, Di Qiu, Binjie Mao, Pengfei Yan, and He Tang. Motioncharacter: Identity-preserving and motion controllable human video generation. ArXiv, abs/2411.18281, 2024. 2
-
[22]
Dreamoving: A human 9 video generation framework based on diffusion models
Mengyang Feng, Jinlin Liu, Kai Yu, Yuan Yao, Zheng Hui, Xiefan Guo, Xianhui Lin, Haolan Xue, Chen Shi, Xiaowen Li, Aojie Li, Xiaoyang Kang, Biwen Lei, Miaomiao Cui, Peiran Ren, and Xuansong Xie. Dreamoving: A human 9 video generation framework based on diffusion models. ArXiv, abs/2312.05107, 2023. 2
-
[23]
Hu- mandit: Pose-guided diffusion transformer for long-form human motion video generation
Qijun Gan, Yi Ren, Chen Zhang, Zhenhui Ye, Pan Xie, Xi- ang Yin, Zehuan Yuan, Bingyue Peng, and Jianke Zhu. Hu- mandit: Pose-guided diffusion transformer for long-form human motion video generation. 2025. 2
work page 2025
-
[24]
Preserve your own cor- relation: A noise prior for video diffusion models
Songwei Ge, Seungjun Nah, Guilin Liu, Tyler Poon, An- drew Tao, Bryan Catanzaro, David Jacobs, Jia-Bin Huang, Ming-Yu Liu, and Yogesh Balaji. Preserve your own cor- relation: A noise prior for video diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22930–22941, 2023. 2
work page 2023
-
[25]
Diffusion as shader: 3d-aware video diffu- sion for versatile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as shader: 3d-aware video diffu- sion for versatile video generation control. arXiv preprint arXiv:2501.03847, 2025. 2
-
[26]
I2v-adapter: A general image-to-video adapter for diffusion models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, et al. I2v-adapter: A general image-to-video adapter for diffusion models. In ACM SIGGRAPH 2024 Conference Papers, pages 1–12, 2024. 2
work page 2024
-
[27]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Y . Qiao, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without spe- cific tuning. ArXiv, abs/2307.04725, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Vladimir Guzov, Aymen Mir, Torsten Sattler, and Gerard Pons-Moll. Human poseitioning system (hps): 3d human pose estimation and self-localization in large scenes from body-mounted sensors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 4318–4329, 2021. 3
work page 2021
-
[29]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Resolving 3d human pose ambiguities with 3d scene constraints
Mohamed Hassan, Vasileios Choutas, Dimitrios Tzionas, and Michael J Black. Resolving 3d human pose ambiguities with 3d scene constraints. In Proceedings of the IEEE/CVF international conference on computer vision , pages 2282– 2292, 2019. 2, 3
work page 2019
-
[31]
Cameractrl: En- abling camera control for text-to-video generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: En- abling camera control for text-to-video generation. In The Thirteenth International Conference on Learning Repre- sentations, 2025. 2
work page 2025
-
[32]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. Advances in neural informa- tion processing systems, 33:6840–6851, 2020. 2
work page 2020
-
[33]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models. Advances in Neural Information Processing Systems, 35:8633–8646, 2022. 2
work page 2022
-
[34]
Storyagent: Cus- tomized storytelling video generation via multi-agent col- laboration
Panwen Hu, Jin Jiang, Jianqi Chen, Mingfei Han, Shengcai Liao, Xiaojun Chang, and Xiaodan Liang. Storyagent: Cus- tomized storytelling video generation via multi-agent col- laboration. ArXiv, abs/2411.04925, 2024. 2
-
[35]
Move-in-2d: 2d-conditioned human motion generation
Hsin-Ping Huang, Yang Zhou, Jui-Hsien Wang, Difan Liu, Feng Liu, Ming-Hsuan Yang, and Zhan Xu. Move-in-2d: 2d-conditioned human motion generation. arXiv preprint arXiv:2412.13185, 2024. 3
-
[36]
Diffusion- based generation, optimization, and planning in 3d scenes
Siyuan Huang, Zan Wang, Puhao Li, Baoxiong Jia, Tengyu Liu, Yixin Zhu, Wei Liang, and Song-Chun Zhu. Diffusion- based generation, optimization, and planning in 3d scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16750–16761, 2023. 3, 4
work page 2023
-
[37]
Owl- 1: Omni world model for consistent long video generation
Yuanhui Huang, Wenzhao Zheng, Yuan Gao, Xin Tao, Pengfei Wan, Di Zhang, Jie Zhou, and Jiwen Lu. Owl- 1: Omni world model for consistent long video generation. ArXiv, abs/2412.09600, 2024. 2
-
[38]
VBench: Comprehensive benchmark suite for video generative mod- els
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative mod- els. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Reco...
work page 2024
-
[39]
Peekaboo: Interactive video generation via masked- diffusion
Yash Jain, Anshul Nasery, Vibhav Vineet, and Harkirat Behl. Peekaboo: Interactive video generation via masked- diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8079– 8088, 2024. 3
work page 2024
-
[40]
Scaling up dynamic human-scene interaction mod- eling
Nan Jiang, Zhiyuan Zhang, Hongjie Li, Xiaoxuan Ma, Zan Wang, Yixin Chen, Tengyu Liu, Yixin Zhu, and Siyuan Huang. Scaling up dynamic human-scene interaction mod- eling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 1737– 1747, 2024. 2, 3
work page 2024
-
[41]
Story-adapter: A training-free iterative framework for long story visual- ization
Jia ju Mao, Xiaoke Huang, Yunfei Xie, Yuanqi Chang, Mude Hui, Bingjie Xu, and Yuyin Zhou. Story-adapter: A training-free iterative framework for long story visual- ization. ArXiv, abs/2410.06244, 2024. 2
-
[42]
Zhanghan Ke, Chunyi Sun, Lei Zhu, Ke Xu, and Ryn- son W.H. Lau. Harmonizer: Learning to perform white-box image and video harmonization. In European Conference on Computer Vision (ECCV), 2022. 14
work page 2022
-
[43]
3d gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkuehler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (TOG), 42:1 – 14, 2023. 6
work page 2023
-
[44]
David: Modeling dynamic affordance of 3d objects using pre- trained video diffusion models
Hyeonwoo Kim, Sangwon Beak, and Hanbyul Joo. David: Modeling dynamic affordance of 3d objects using pre- trained video diffusion models. ArXiv, abs/2501.08333,
-
[45]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023. 3, 5
work page 2023
-
[46]
Putting people in their place: Affordance-aware hu- man insertion into scenes
Sumith Kulal, Tim Brooks, Alex Aiken, Jiajun Wu, Jimei Yang, Jingwan Lu, Alexei A Efros, and Krishna Kumar Singh. Putting people in their place: Affordance-aware hu- man insertion into scenes. In Proceedings of the IEEE/CVF 10 Conference on Computer Vision and Pattern Recognition , pages 17089–17099, 2023. 3
work page 2023
-
[47]
Black Forest Labs. Flux. https://github.com/ black-forest-labs/flux . Accessed: 2024-09-24. 1
work page 2024
-
[48]
Ze- rohsi: Zero-shot 4d human-scene interaction by video gen- eration
Hongjie Li, Hong-Xing Yu, Jiaman Li, and Jiajun Wu. Ze- rohsi: Zero-shot 4d human-scene interaction by video gen- eration. ArXiv, abs/2412.18600, 2024. 2
-
[49]
Jiefeng Li, Chao Xu, Zhicun Chen, Siyuan Bian, Lixin Yang, and Cewu Lu. Hybrik: A hybrid analytical-neural inverse kinematics solution for 3d human pose and shape estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3383– 3393, 2021. 5
work page 2021
-
[50]
Hybrik-x: Hybrid analytical-neural inverse kinematics for whole-body mesh recovery
Jiefeng Li, Siyuan Bian, Chao Xu, Zhicun Chen, Lixin Yang, and Cewu Lu. Hybrik-x: Hybrid analytical-neural inverse kinematics for whole-body mesh recovery. arXiv preprint arXiv:2304.05690, 2023. 5
-
[51]
Genzi: Zero-shot 3d human-scene interaction generation
Lei Li and Angela Dai. Genzi: Zero-shot 3d human-scene interaction generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 20465–20474, 2024. 2, 3, 5, 7, 14
work page 2024
-
[52]
Animatable gaussians: Learning pose-dependent gaussian maps for high-fidelity human avatar modeling
Zhe Li, Zerong Zheng, Lizhen Wang, and Yebin Liu. Animatable gaussians: Learning pose-dependent gaussian maps for high-fidelity human avatar modeling. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2, 6
work page 2024
-
[53]
Intergen: Diffusion-based multi-human motion generation under complex interactions
Hanming Liang, Wenqian Zhang, Wenxu Li, Jingyi Yu, and Lan Xu. Intergen: Diffusion-based multi-human motion generation under complex interactions. Int. J. Comput. Vis., 132:3463–3483, 2023. 2
work page 2023
-
[54]
Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, Tanghui Jia, Junwu Zhang, Zhenyu Tang, Yatian Pang, Bin She, Cen Yan, Zhiheng Hu, Xiao wen Dong, Lin Chen, Zhang Pan, Xing Zhou, Shaoling Dong, Yonghong Tian, and Li Yuan. Open-sora plan: Open-source large video generation model. ArXiv, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, and Chao Liang. Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models. 2025. 2
work page 2025
-
[56]
Separate motion from appear- ance: Customizing motion via customizing text-to-video diffusion models
Huijie Liu, Jingyun Wang, Shuai Ma, Jie Hu, Xiaoming Wei, and Guoliang Kang. Separate motion from appear- ance: Customizing motion via customizing text-to-video diffusion models. arXiv preprint arXiv:2501.16714, 2025. 2
-
[57]
Phantom: Subject- consistent video generation via cross-modal alignment
Lijie Liu, Tianxiang Ma, Bingchuan Li, Zhuowei Chen, Ji- awei Liu, Qian He, and Xinglong Wu. Phantom: Subject- consistent video generation via cross-modal alignment
-
[58]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European Conference on Computer Vision , pages 38–55. Springer, 2024. 3
work page 2024
-
[59]
Matthew Loper, Naureen Mahmood, Javier Romero, Ger- ard Pons-Moll, and Michael J. Black. SMPL: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1–248:16, 2015. 2, 3
work page 2015
-
[60]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Ger- ard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2 , pages 851–866. 2023. 4
work page 2023
-
[61]
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, Changyi Wan, Ranchen Ming, Xiaoniu Song, Xing Chen, et al. Step-video-t2v technical report: The practice, challenges, and future of video foun- dation model. arXiv preprint arXiv:2502.10248, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[62]
Trailblazer: Trajectory control for diffusion-based video generation
Wan-Duo Kurt Ma, John P Lewis, and W Bastiaan Kleijn. Trailblazer: Trajectory control for diffusion-based video generation. In SIGGRAPH Asia 2024 Conference Papers , pages 1–11, 2024. 3
work page 2024
-
[63]
Cinemo: Consis- tent and controllable image animation with motion diffu- sion models
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Yuan- Fang Li, Cunjian Chen, and Yu Qiao. Cinemo: Consis- tent and controllable image animation with motion diffu- sion models. arXiv preprint arXiv:2407.15642, 2024. 2
-
[64]
Genheld: Generating and editing handheld objects
Chaerin Min and Srinath Sridhar. Genheld: Generating and editing handheld objects. arXiv preprint arXiv:2406.05059,
- [65]
-
[66]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervi- sion. arXiv preprint arXiv:2304.07193, 2023. 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Text2place: Affordance-aware text guided human placement
Rishubh Parihar, Harsh Gupta, Sachidanand VS, and R Venkatesh Babu. Text2place: Affordance-aware text guided human placement. In European Conference on Computer Vision, pages 57–77. Springer, 2024. 2, 3
work page 2024
-
[68]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019. 4
work page 2019
-
[69]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 10975–10985, 2019. 2, 3, 14
work page 2019
-
[70]
Hoi-diff: Text-driven syn- thesis of 3d human-object interactions using diffusion mod- els
Xiaogang Peng, Yiming Xie, Zizhao Wu, Varun Jampani, Deqing Sun, and Huaizu Jiang. Hoi-diff: Text-driven syn- thesis of 3d human-object interactions using diffusion mod- els. ArXiv, abs/2312.06553, 2023. 2
-
[71]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1
work page 2022
-
[72]
Dreambooth: Fine 11 tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine 11 tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500– 22510, 2023. 2
work page 2023
-
[73]
Magic insert: Style-aware drag-and-drop
Nataniel Ruiz, Yuanzhen Li, Neal Wadhwa, Yael Pritch, Michael Rubinstein, David E Jacobs, and Shlomi Fruchter. Magic insert: Style-aware drag-and-drop. arXiv preprint arXiv:2407.02489, 2024. 3
-
[74]
Geodiffuser: Geometry-based im- age editing with diffusion models
Rahul Sajnani, Jeroen Vanbaar, Jie Min, Kapil Katyal, and Srinath Sridhar. Geodiffuser: Geometry-based im- age editing with diffusion models. arXiv preprint arXiv:2404.14403, 2024. 2
-
[75]
Zhang, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, Jifeng Da, and Hong- sheng Li
Xiaoyu Shi, Zhaoyang Huang, Fu-Yun Wang, Weikang Bian, Dasong Li, Y . Zhang, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, Jifeng Da, and Hong- sheng Li. Motion-i2v: Consistent and controllable image- to-video generation with explicit motion modeling. ArXiv, abs/2401.15977, 2024. 2
-
[76]
Dragdiffusion: Harnessing diffusion models for interac- tive point-based image editing
Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Han- shu Yan, Wenqing Zhang, Vincent YF Tan, and Song Bai. Dragdiffusion: Harnessing diffusion models for interac- tive point-based image editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8839–8849, 2024. 2
work page 2024
-
[77]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[78]
Sound to visual scene gener- ation by audio-to-visual latent alignment
Kim Sung-Bin, Arda Senocak, Hyunwoo Ha, Andrew Owens, and Tae-Hyun Oh. Sound to visual scene gener- ation by audio-to-visual latent alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 6430–6440, 2023. 2
work page 2023
-
[79]
Add-it: Training-free object in- sertion in images with pretrained diffusion models
Yoad Tewel, Rinon Gal, Dvir Samuel, Yuval Atzmon, Lior Wolf, and Gal Chechik. Add-it: Training-free object in- sertion in images with pretrained diffusion models. arXiv preprint arXiv:2411.07232, 2024. 3
-
[80]
Hongjie Wang, Chih-Yao Ma, Yen-Cheng Liu, Ji Hou, Tao Xu, Jialiang Wang, Felix Juefei-Xu, Yaqiao Luo, Peizhao Zhang, Tingbo Hou, Peter Vajda, Niraj Kumar Jha, and Xiaoliang Dai. Lingen: Towards high-resolution minute- length text-to-video generation with linear computational complexity. ArXiv, abs/2412.09856, 2024. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.