Neural Two-Stage Stochastic Optimization for Solving Unit Commitment Problem
Pith reviewed 2026-05-19 05:23 UTC · model grok-4.3
The pith
A deep neural network approximates recourse costs in two-stage stochastic unit commitment so the first-stage problem can be solved directly as a mixed-integer linear program.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The method trains a deep neural network to map first-stage commitment decisions together with uncertainty features directly to the optimal recourse cost of the second-stage problem; once trained, this network is encoded as a set of mixed-integer linear constraints and inserted into the first-stage unit-commitment formulation, while a separate scenario-embedding network reduces an arbitrary collection of uncertainty realizations to a compact feature vector that keeps the overall model size independent of the scenario count.
What carries the argument
Deep neural network that maps commitment decisions and uncertainty features to recourse costs, encoded as MILP constraints and combined with a scenario-embedding network for dimensionality reduction.
If this is right
- The final optimization model stays the same size no matter how many uncertainty scenarios are considered.
- Operational constraints such as ramping limits and transmission capacities remain explicitly enforced inside the first-stage MILP.
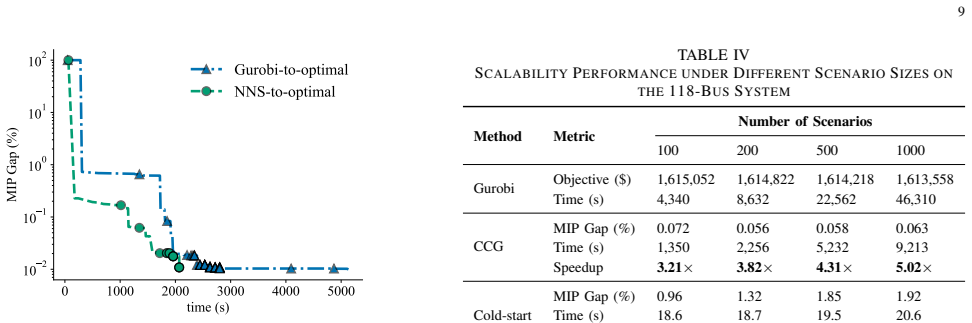
- Computation time scales far better than scenario-based decomposition or full MILP formulations on the IEEE 5-, 30-, and 118-bus systems.
- The same trained network can be reused across different numbers of scenarios without retraining.
Where Pith is reading between the lines
- The same embedding technique could be tried on other two-stage stochastic programs that have expensive recourse subproblems.
- If the network approximation error can be bounded, the method might give provable guarantees on solution quality rather than only empirical gaps.
- Real-time market clearing with hundreds of renewable scenarios becomes feasible if the network training is performed offline.
Load-bearing premise
The trained network must predict recourse costs accurately enough on new scenarios that the resulting first-stage solution stays close to optimal and satisfies all operational limits.
What would settle it
Run the trained model on a new set of scenarios or a larger test system and measure whether the obtained first-stage solution violates any operational constraint or produces a total expected cost more than 1 percent above the true optimum.
Figures


read the original abstract
This paper proposes a neural stochastic optimization method for efficiently solving the two-stage stochastic unit commitment (2S-SUC) problem under high-dimensional uncertainty scenarios. The proposed method approximates the second-stage recourse problem using a deep neural network trained to map commitment decisions and uncertainty features to recourse costs. The trained network is subsequently embedded into the first-stage UC problem as a mixed-integer linear program (MILP), allowing for explicit enforcement of operational constraints while preserving the key uncertainty characteristics. A scenario-embedding network is employed to enable dimensionality reduction and feature aggregation across arbitrary scenario sets, serving as a data-driven scenario reduction mechanism. Numerical experiments on IEEE 5-bus, 30-bus, and 118-bus systems demonstrate that the proposed neural two-stage stochastic optimization method achieves solutions with an optimality gap of less than 1%, while enabling orders-of-magnitude speedup compared to conventional MILP solvers and decomposition-based methods. Moreover, the model's size remains constant regardless of the number of scenarios, offering significant scalability for large-scale stochastic unit commitment problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a neural two-stage stochastic optimization method for the two-stage stochastic unit commitment (2S-SUC) problem. A deep neural network approximates the second-stage recourse costs from commitment decisions and uncertainty features; this network is encoded as MILP constraints and embedded in the first-stage problem. A scenario-embedding network performs data-driven dimensionality reduction across arbitrary scenario sets. Experiments on IEEE 5-, 30-, and 118-bus systems report optimality gaps below 1 % and orders-of-magnitude speedups relative to MILP solvers and decomposition methods, with model size independent of scenario count.
Significance. If the central performance claims are substantiated by exact out-of-sample verification, the approach would offer a scalable, constant-complexity surrogate for large-scale stochastic unit commitment that preserves operational constraints while achieving near-optimal first-stage decisions. This could materially advance real-time stochastic scheduling under high-dimensional uncertainty.
major comments (2)
- [Numerical Experiments] Numerical Experiments section: the reported optimality gaps below 1 % are obtained by solving the first-stage problem with the embedded neural surrogate; the manuscript does not state whether the true expected cost of the resulting commitment schedule was recomputed by solving the exact second-stage recourse problems on held-out scenarios. Without this verification, the gap figures may reflect surrogate objective values rather than true optimality gaps, directly undermining the central performance claim.
- [Method] Method section (neural recourse approximation and MILP embedding): no explicit approximation-error bounds, worst-case analysis of the ReLU/MILP encoding, or empirical feasibility checks on unseen scenario sets are provided. The central claim that the embedded network yields operationally feasible and near-optimal first-stage decisions therefore rests on unverified assumptions about surrogate accuracy.
minor comments (1)
- [Abstract] Abstract: the statement that 'the model's size remains constant regardless of the number of scenarios' should clarify whether this refers to the number of neural-network parameters or to the size of the resulting MILP.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment below, clarifying our experimental verification procedures and indicating where revisions will be made to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Numerical Experiments] Numerical Experiments section: the reported optimality gaps below 1 % are obtained by solving the first-stage problem with the embedded neural surrogate; the manuscript does not state whether the true expected cost of the resulting commitment schedule was recomputed by solving the exact second-stage recourse problems on held-out scenarios. Without this verification, the gap figures may reflect surrogate objective values rather than true optimality gaps, directly undermining the central performance claim.
Authors: We agree that explicit out-of-sample verification using exact second-stage solutions is necessary to substantiate the optimality gap claims. In our experiments, after obtaining first-stage commitment decisions from the MILP with the embedded neural surrogate, we recomputed the true expected recourse cost by solving the exact second-stage problems on held-out scenarios that were not used during training or validation. The reported gaps below 1% are with respect to these true costs. We will revise the Numerical Experiments section to explicitly describe this verification procedure, including details on the held-out scenario sets and how the true optimality gaps were calculated. revision: yes
-
Referee: [Method] Method section (neural recourse approximation and MILP embedding): no explicit approximation-error bounds, worst-case analysis of the ReLU/MILP encoding, or empirical feasibility checks on unseen scenario sets are provided. The central claim that the embedded network yields operationally feasible and near-optimal first-stage decisions therefore rests on unverified assumptions about surrogate accuracy.
Authors: We acknowledge that the manuscript does not include theoretical approximation-error bounds or a worst-case analysis of the ReLU/MILP encoding. Such bounds are difficult to obtain for general neural approximations of recourse functions and are outside the scope of this primarily empirical study. However, we provide extensive numerical validation on multiple IEEE test systems using unseen scenarios. To strengthen the manuscript, we will add a dedicated subsection reporting empirical feasibility checks on unseen scenario sets, including the percentage of feasible first-stage solutions obtained and any observed constraint violations. Operational feasibility of first-stage decisions is enforced directly by the MILP formulation of the unit commitment constraints. revision: partial
- Derivation of explicit approximation-error bounds or worst-case analysis for the neural recourse approximation and its ReLU/MILP encoding.
Circularity Check
No circularity: empirical validation on standard test systems is independent of fitted surrogate
full rationale
The paper describes training a DNN to approximate recourse costs from commitment decisions and uncertainty features, embedding the trained network (plus scenario-embedding subnetwork) as MILP constraints in the first-stage UC problem, and then reporting numerical optimality gaps and runtimes on IEEE 5/30/118-bus instances against MILP solvers and decomposition methods. These performance numbers are obtained by solving the surrogate-augmented first-stage problem and comparing its objective and feasibility to reference solutions; they do not reduce by construction to the training data or to any self-citation chain. The method is a standard data-driven surrogate approach whose central claims rest on external benchmark comparisons rather than on any redefinition of inputs as outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network weights and biases
axioms (1)
- domain assumption A trained feed-forward network can be exactly or approximately encoded as a set of mixed-integer linear constraints
invented entities (1)
-
Scenario-embedding network
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Stochastic security-constrained unit commitment,
L. Wu, M. Shahidehpour, and T. Li, “Stochastic security-constrained unit commitment,” IEEE Trans. Power Syst. , vol. 22, no. 2, pp. 800– 811, 2007
work page 2007
-
[2]
Frauendorfer, Stochastic two-stage programming
K. Frauendorfer, Stochastic two-stage programming. Springer Science & Business Media, 2012, vol. 392
work page 2012
-
[3]
Network-constrained AC unit com- mitment under uncertainty: A Benders’ decomposition approach,
A. Nasri, S. J. Kazempour et al. , “Network-constrained AC unit com- mitment under uncertainty: A Benders’ decomposition approach,” IEEE Trans. Power Syst., vol. 31, no. 1, pp. 412–422, 2015
work page 2015
-
[4]
Solution sensitivity-based scenario reduction for stochastic unit commitment,
Y . Feng and S. M. Ryan, “Solution sensitivity-based scenario reduction for stochastic unit commitment,” Comput. Manag. Sci., vol. 13, pp. 29– 62, 2016
work page 2016
-
[5]
Stochastic optimization for unit commitment—A review,
Q. P. Zheng, J. Wang, and A. L. Liu, “Stochastic optimization for unit commitment—A review,” IEEE Trans. Power Syst. , vol. 30, no. 4, pp. 1913–1924, 2014
work page 1913
-
[6]
Q. Zhai, X. Li, X. Lei, and X. Guan, “Transmission constrained UC with wind power: An all-scenario-feasible MILP formulation with strong nonanticipativity,” IEEE Trans. Power Syst. , vol. 32, no. 3, pp. 1805– 1817, 2016
work page 2016
-
[7]
Y . Zhang, J. Wang, B. Zeng, and Z. Hu, “Chance-constrained two-stage unit commitment under uncertain load and wind power output using bilinear Benders decomposition,” IEEE Trans. Power Syst. , vol. 32, no. 5, pp. 3637–3647, 2017
work page 2017
-
[8]
J. Lee and K. Lee, “Column-and-constraint generation approach to partition-based risk-averse two-stage stochastic programs,” Ann. Oper. Res., pp. 1–31, 2025
work page 2025
-
[9]
Data-driven stochastic unit commitment for integrating wind generation,
C. Zhao and Y . Guan, “Data-driven stochastic unit commitment for integrating wind generation,” IEEE Trans. Power Syst. , vol. 31, no. 4, pp. 2587–2596, 2015
work page 2015
-
[10]
Scenario map based stochastic unit commitment,
E. Du, N. Zhang, C. Kang, and Q. Xia, “Scenario map based stochastic unit commitment,” IEEE Trans. Power Syst. , vol. 33, no. 5, pp. 4694– 4705, 2018
work page 2018
-
[11]
An efficient robust solution to the two- stage stochastic unit commitment problem,
I. Blanco and J. M. Morales, “An efficient robust solution to the two- stage stochastic unit commitment problem,” IEEE Trans. Power Syst. , vol. 32, no. 6, pp. 4477–4488, 2017
work page 2017
-
[12]
Stochastic distributionally robust unit commitment with deep scenario clustering,
J. Zhang, B. Wang, and J. Watada, “Stochastic distributionally robust unit commitment with deep scenario clustering,”Electr. Power Syst. Res., vol. 224, p. 109710, 2023
work page 2023
-
[13]
Comparison of scenario reduction techniques for the stochastic unit commitment,
Y . Dvorkin, Y . Wang, H. Pandzic, and D. Kirschen, “Comparison of scenario reduction techniques for the stochastic unit commitment,” in 2014 IEEE PES general meeting , pp. 1–5
work page 2014
-
[14]
O. Yurdakul, F. Qiu et al. , “A predictive prescription framework for stochastic unit commitment using boosting ensemble learning algo- rithms,” IEEE Trans. Power Syst., vol. 39, no. 4, pp. 5726–5740, 2023
work page 2023
-
[15]
X. Chen, Y . Liu, and L. Wu, “Towards improving unit commitment eco- nomics: An add-on tailor for renewable energy and reserve predictions,” IEEE Trans. Sustain. Energy , vol. 15, no. 4, pp. 2547–2566, 2024
work page 2024
-
[16]
J. Qin, R. Yang, and N. Yu, “Physics-informed graph neural networks for collaborative dynamic reconfiguration and voltage regulation in unbalanced distribution systems,” IEEE Trans. Ind. Appl., vol. 61, no. 2, pp. 2538–2548, 2025
work page 2025
-
[17]
Y . Zhu, G. Cui, A. Liu et al., “A reinforcement learning embedded sur- rogate Lagrangian relaxation method for fast solving unit commitment problems,” IEEE Trans. Power Syst. , 2025
work page 2025
-
[18]
Extended Benders decomposition for two-stage SCUC,
C. Liu, M. Shahidehpour, and L. Wu, “Extended Benders decomposition for two-stage SCUC,” IEEE Trans. Power Syst., vol. 25, no. 2, pp. 1192– 1194, 2010
work page 2010
-
[19]
A decomposition approach to the two-stage stochastic unit commitment problem,
Q. P. Zheng, J. Wang, P. M. Pardalos, and Y . Guan, “A decomposition approach to the two-stage stochastic unit commitment problem,” Ann. Oper. Res., vol. 210, pp. 387–410, 2013
work page 2013
-
[20]
Maximum resilience of artificial neural networks,
C.-H. Cheng, G. N ¨uhrenberg, and H. Ruess, “Maximum resilience of artificial neural networks,” in Automated Technology for Verification and Analysis: 15th International Symposium . Springer, 2017, pp. 251–268
work page 2017
-
[21]
Evaluating Robustness of Neural Networks with Mixed Integer Programming
V . Tjeng, K. Xiao, and R. Tedrake, “Evaluating robustness of neural networks with mixed integer programming,” arXiv preprint arXiv:1711.07356, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Deep neural networks and mixed integer linear optimization,
M. Fischetti and J. Jo, “Deep neural networks and mixed integer linear optimization,” Constraints, vol. 23, no. 3, pp. 296–309, 2018
work page 2018
-
[23]
ReLU networks as surrogate models in mixed-integer linear programs,
B. Grimstad and H. Andersson, “ReLU networks as surrogate models in mixed-integer linear programs,” Comput. Chem. Eng. , vol. 131, p. 106580, 2019
work page 2019
-
[24]
Strong mixed-integer programming formulations for trained neural networks,
R. Anderson, J. Huchette, W. Ma, C. Tjandraatmadja, and J. P. Vielma, “Strong mixed-integer programming formulations for trained neural networks,” Math. Program., vol. 183, no. 1, pp. 3–39, 2020
work page 2020
-
[25]
OMLT: Optimization & Machine Learning Toolkit,
F. Ceccon, J. Jalving, J. Haddad, A. Thebelt, C. Tsay, C. D. Laird, and R. Misener, “OMLT: Optimization & Machine Learning Toolkit,” J. Mach. Learn. Res. , vol. 23, no. 349, pp. 1–8, 2022
work page 2022
-
[26]
Formulating data-driven surrogate models for process optimization,
R. Misener and L. Biegler, “Formulating data-driven surrogate models for process optimization,” Comput. Chem. Eng. , vol. 179, p. 108411, 2023
work page 2023
-
[27]
J. Jalving, J. Ghouse et al. , “Beyond price taker: Conceptual design and optimization of integrated energy systems using machine learning market surrogates,” Appl. Energy, vol. 351, p. 121767, 2023
work page 2023
-
[28]
Optimal energy system scheduling using a constraint-aware reinforcement learning algorithm,
H. Shengren, P. P. Vergara et al. , “Optimal energy system scheduling using a constraint-aware reinforcement learning algorithm,”Int. J. Electr. Power Energy Syst., vol. 152, p. 109230, 2023
work page 2023
-
[29]
Neur2SP: Neural two-stage stochastic programming,
R. M. Patel, J. Dumouchelle, E. Khalil, and M. Bodur, “Neur2SP: Neural two-stage stochastic programming,” Adv. Neural Inf. Process. Syst., vol. 35, pp. 23 992–24 005, 2022
work page 2022
-
[30]
A comprehensive survey on design and application of autoencoder in deep learning,
P. Li, Y . Pei, and J. Li, “A comprehensive survey on design and application of autoencoder in deep learning,” Appl. Soft Comput. , vol. 138, p. 110176, 2023
work page 2023
-
[31]
R. D. Zimmerman, C. E. Murillo-S ´anchez et al., “MATPOWER: Steady- state operations, planning, and analysis tools for power systems research and education,”IEEE Trans. Power Syst., vol. 26, no. 1, pp. 12–19, 2010
work page 2010
-
[32]
Pyomo: modeling and solving mathematical programs in Python,
W. E. Hart, J.-P. Watson, and D. L. Woodruff, “Pyomo: modeling and solving mathematical programs in Python,” Math. Program. Comput. , vol. 3, pp. 219–260, 2011
work page 2011
-
[33]
Solving two-stage robust optimization problems using a column-and-constraint generation method,
B. Zeng and L. Zhao, “Solving two-stage robust optimization problems using a column-and-constraint generation method,” Oper. Res. Lett. , vol. 41, no. 5, pp. 457–461, 2013
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.