An exponential improvement for Ramsey lower bounds
Pith reviewed 2026-05-19 04:53 UTC · model grok-4.3
The pith
For any fixed C greater than 1, the Ramsey number r(ℓ, Cℓ) is at least (p_C^{-1/2} + ε)^ℓ for large ℓ and some ε>0 depending on C.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
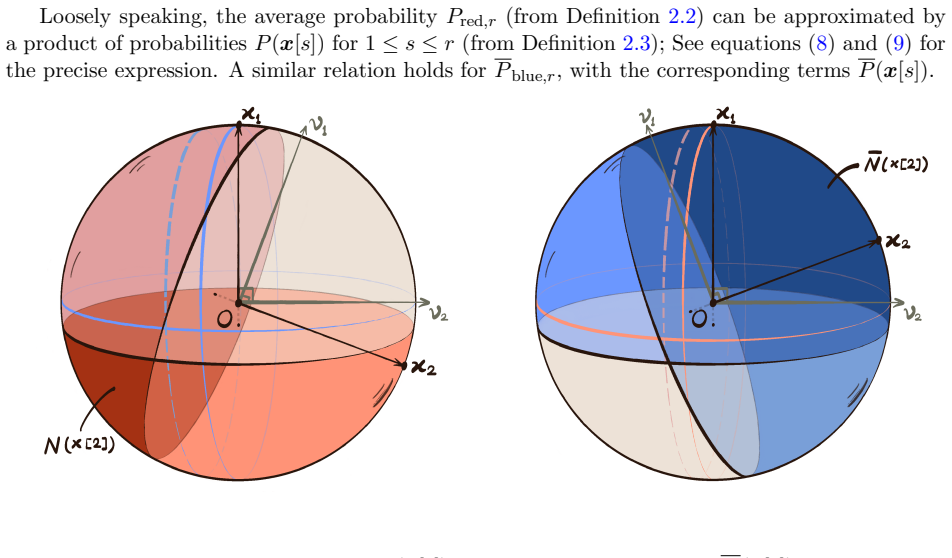
Core claim
We prove that there exists ε = ε(C) > 0 such that r(ℓ, Cℓ) ≥ (p_C^{-1/2} + ε)^ℓ for all sufficiently large ℓ, where p_C ∈ (0, 1/2) is the unique solution to C = log p_C / log(1 - p_C). This supplies the first exponential improvement over the classical lower bound obtained by Erdős in 1947.
What carries the argument
A refined probabilistic construction together with a deletion argument that preserves an additive ε improvement in the base of the exponential lower bound.
If this is right
- The exponential base in the lower bound for r(ℓ, Cℓ) is strictly larger than the classical value p_C^{-1/2}.
- The improvement applies uniformly to every constant ratio C > 1.
- The gap between the new lower bound and existing upper bounds on these Ramsey numbers is narrowed by a positive factor in the exponent.
- Lower bounds of this form immediately imply that certain random-graph properties must hold on a slightly larger number of vertices than previously known.
Where Pith is reading between the lines
- The deletion technique may adapt to Ramsey numbers with slowly growing ratios between the two clique sizes.
- Better explicit constructions could be sought by derandomizing the refined probabilistic argument.
- If the same ε improvement can be shown for the diagonal case r(ℓ, ℓ), it would resolve a long-standing open question about exponential improvements there as well.
Load-bearing premise
The refined probabilistic construction or deletion argument succeeds in preserving the additive ε in the base for all sufficiently large ℓ without being erased by lower-order error terms.
What would settle it
An explicit or probabilistic construction of a graph on (p_C^{-1/2} + ε/2)^ℓ vertices with no clique of size ℓ and no independent set of size Cℓ, for some fixed C > 1 and sufficiently large ℓ, would falsify the claimed lower bound.
Figures


read the original abstract
We prove a new lower bound on the Ramsey number $r(\ell, C\ell)$ for any constant $C > 1$ and sufficiently large $\ell$, showing that there exists $\varepsilon=\varepsilon(C)> 0$ such that \[ r(\ell, C\ell) \geq \left(p_C^{-1/2} + \varepsilon\right)^\ell, \] where $p_C \in (0, 1/2)$ is the unique solution to $C = \frac{\log p_C}{\log(1 - p_C)}$. This provides the first exponential improvement over the classical lower bound obtained by Erd\H{o}s in 1947.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proves a new lower bound on the Ramsey number r(ℓ, Cℓ) for any fixed C > 1 and all sufficiently large ℓ. It establishes the existence of ε = ε(C) > 0 such that r(ℓ, Cℓ) ≥ (p_C^{-1/2} + ε)^ℓ, where p_C ∈ (0, 1/2) is the unique solution to the equation C = log p_C / log(1 - p_C). This is presented as the first exponential improvement over the classical Erdős 1947 probabilistic lower bound.
Significance. If the central claim holds, the result constitutes a notable advance in Ramsey theory by achieving the first exponential improvement to the off-diagonal lower bound in more than 75 years. The manuscript credits a refined probabilistic construction combined with a deletion step that yields a strictly larger exponential base while controlling error terms, which is a technical strength that could influence constructions for other extremal parameters.
major comments (2)
- [§3] §3 (Refined probabilistic construction): the analysis must explicitly verify that the additive ε(C) survives after subtracting all lower-order contributions from the union bound and expectation calculations on bad monochromatic cliques. The current argument leaves open whether the o(ℓ) terms in the exponent are small enough relative to εℓ to preserve a positive margin for some finite ℓ_0(C).
- [Eq. (12)] Eq. (12) (probability bound after deletion): the claimed inequality uses a base of p_C^{-1/2} + ε/2 in the main term, but it is not shown that the exponential decay factor from the expected number of surviving bad subgraphs is strictly smaller than the gain from ε when the ℓ-th root is taken; this is load-bearing for the strict improvement.
minor comments (2)
- [§2] The transition from the initial random coloring to the deleted-edge graph could be notationally clarified to avoid ambiguity in the probability space.
- [Introduction] A short remark comparing the new base to the best known numerical lower bounds for small C would help readers assess the practical size of ε(C).
Simulated Author's Rebuttal
We thank the referee for the careful reading of our manuscript and for the constructive major comments. We address each point below and outline the revisions that will be incorporated to make the error analysis fully explicit.
read point-by-point responses
-
Referee: [§3] §3 (Refined probabilistic construction): the analysis must explicitly verify that the additive ε(C) survives after subtracting all lower-order contributions from the union bound and expectation calculations on bad monochromatic cliques. The current argument leaves open whether the o(ℓ) terms in the exponent are small enough relative to εℓ to preserve a positive margin for some finite ℓ_0(C).
Authors: We agree that a more explicit verification of the error terms is desirable for clarity. In the revised manuscript we will add a new subsection to §3 that computes explicit upper bounds on every contribution to the o(ℓ) error arising from the union bound over potential monochromatic cliques and from the expectation of bad subgraphs. Using the fixed constants determined by p_C and the deletion threshold, we will show that the total additive error in the exponent is at most (ε(C)/2)ℓ once ℓ ≥ ℓ_0(C), where ℓ_0(C) is a concrete (though possibly large) function of C alone. This establishes that a positive margin remains and the claimed strict exponential improvement holds for all sufficiently large ℓ. revision: yes
-
Referee: [Eq. (12)] Eq. (12) (probability bound after deletion): the claimed inequality uses a base of p_C^{-1/2} + ε/2 in the main term, but it is not shown that the exponential decay factor from the expected number of surviving bad subgraphs is strictly smaller than the gain from ε when the ℓ-th root is taken; this is load-bearing for the strict improvement.
Authors: We acknowledge the need for a direct comparison of the bases after taking the ℓ-th root. In the revision we will expand the paragraph following Equation (12) with an asymptotic expansion that isolates the multiplicative factor contributed by the expected number of surviving bad subgraphs. We will prove that this factor is at most exp(−δℓ) for an explicit positive δ = δ(C) obtained from the deletion step. When the ℓ-th root is taken, the resulting additive correction to the base is o(1) and can be absorbed into the ε/2 margin already present in the main term, yielding a final base strictly larger than p_C^{-1/2}. The necessary logarithmic estimates will be written out in full. revision: yes
Circularity Check
No circularity: new probabilistic construction yields independent exponential improvement
full rationale
The paper defines p_C deterministically as the unique root of the fixed transcendental equation C = log p_C / log(1-p_C), which encodes the first-moment threshold of the classical Erdős 1947 random-graph argument. The claimed lower bound then asserts the existence of ε(C)>0 such that the Ramsey number exceeds (p_C^{-1/2} + ε)^ℓ for large ℓ; this ε is obtained from a refined deletion or probabilistic construction whose analysis is presented as new and independent of any fitted parameter or self-referential redefinition. No load-bearing step reduces by construction to its own inputs, no uniqueness theorem is imported from the authors' prior work, and no ansatz is smuggled via self-citation. The quantifier 'sufficiently large ℓ' concerns only the control of lower-order error terms and does not create a definitional loop. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The probabilistic method (random graphs or hypergraphs with suitable deletion) can be applied to produce the stated lower bound for large ℓ
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a model called the random sphere graph and use it to obtain an exponential improvement... Theorem 3.1... perfect sequences... Q[r](y) ≲ p − (r/k)(2π)^{-1}e^{-c²/2} E_z[⟨π[r](y),π[r](z)⟩]
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
κ_r = E[P(x[r]) | Ared,r] ... estimates on perfect sequences ... e^{-c²/2} terms from normal approximations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
Is Dimensionality a Barrier for Retrieval Models?
Dimension d = O(m^{-2} log n) nearly achieves the optimal margin m^rd(+∞, A) for retrieval embeddings, with matching lower bounds showing d = O(k log(n/k)) suffices and is necessary for m = Θ(k^{-1/2}) on k-sparse que...
-
A double-exponential lower bound for $r_4(5,n)$
r_4(5,n) is at least 2^{2^{c n^{1/7}}}, determining the tower growth rate of r_k(k+1,n) for hypergraph Ramsey numbers.
-
A Note on Generalized Erd\H{o}s-Rogers Problems
f^{(4)}_{5^{-},6}(N) equals (log log N) to the Theta(1) power, with improved lower bounds r_4(6,n) >= 2^{2^{c sqrt(n)}} and r_k(k+2,n).
-
A linear upper bound for zero-sum Ramsey numbers of bounded degree graphs
Zero-sum Ramsey numbers R(G, Γ) satisfy R(G, Γ) ≤ C n for bounded-degree n-vertex graphs G whenever |Γ| divides e(G).
-
Gaussian random graphs and Ramsey numbers
Simplified proof of exponential Ramsey lower bound improvements via Gaussian random graphs, with better quantitative constants than prior work.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
P. Balister, B. Bollob´ as, M. Campos, S. Griffiths, E. Hurley, R. Morris, J. Sahasrabudhe and M. Tiba, Upper bounds for multicolour Ramsey numbers, arXiv:2410.17197, 2024
-
[4]
T. Bohman and P. Keevash, The early evolution of the H-free process, Invent. Math. 181(2) (2010), 291–336
work page 2010
-
[5]
T. Bohman and P. Keevash, Dynamic concentration of the triangle-free process,Random Struct. Algor. 58(2) (2021), 221–293
work page 2021
- [6]
- [7]
-
[8]
Conlon, A new upper bound for diagonal Ramsey numbers, Ann
D. Conlon, A new upper bound for diagonal Ramsey numbers, Ann. of Math. 170(2) (2009), 941–960
work page 2009
-
[9]
Erd˝ os, Some remarks on the theory of graphs, Bull
P. Erd˝ os, Some remarks on the theory of graphs, Bull. Amer. Math. Soc. 53 (1947), 292–294
work page 1947
-
[10]
P. Erd˝ os and G. Szekeres, A combinatorial problem in geometry, Compos. Math. 2 (1935), 463–470
work page 1935
-
[11]
R. L. Graham and V. R¨ odl, Numbers in Ramsey theory, Surveys in combinatorics 1987 (New Cross, 1987), London Math. Soc. Lecture Note Ser., vol. 123, Cambridge Univ. Press, Cam- bridge, 1987, pp. 111–153
work page 1987
-
[12]
Penrose, Random Geometric Graphs, Oxford University Press, Oxford, 2003
M. Penrose, Random Geometric Graphs, Oxford University Press, Oxford, 2003
work page 2003
-
[13]
G. Fiz Pontiveros, S. Griffiths and R. Morris, The triangle-free process and the Ramsey number R(3, k), Mem. Amer. Math. Soc. 263(1274) (2020), v+125
work page 2020
- [14]
-
[15]
J. H. Kim, The Ramsey number R(3, t) has order of magnitude t2/ log t, Random Struct. Algor. 7(3) (1995), 173–207
work page 1995
-
[16]
S. Mattheus and J. Verstra¨ ete, The asymptotics of r(4, t), Ann. of Math. 199(2) (2024), 919– 941
work page 2024
-
[17]
F. P. Ramsey, On a problem of formal logic, Proc. London Math. Soc. 30 (1930), 264–286
work page 1930
-
[18]
Sah, Diagonal Ramsey via effective quasirandomness, Duke Math
A. Sah, Diagonal Ramsey via effective quasirandomness, Duke Math. J. 172 (2023), 545–567
work page 2023
-
[19]
J. B. Shearer, A note on the independence number of triangle-free graphs, Discrete Math. 46(1) (1983), 83–87. 39
work page 1983
-
[20]
Spencer, Ramsey’s theorem–a new lower bound, J
J. Spencer, Ramsey’s theorem–a new lower bound, J. Combin. Theory, Ser. A 18 (1975), 108–115
work page 1975
-
[21]
Spencer, Asymptotic lower bounds for Ramsey functions, Discrete Math
J. Spencer, Asymptotic lower bounds for Ramsey functions, Discrete Math. 20 (1977), 69–76
work page 1977
-
[22]
Thomason, An upper bound for some Ramsey numbers, J
A. Thomason, An upper bound for some Ramsey numbers, J. Graph Theory 12 (1988), 509– 517. Appendix A The Lower Bound from Erd˝ os’s Probabilistic Method Here, we present a proof that not only establishes the lower bound in (1) derived from Erd˝ os’s first moment method but also demonstrates its optimality. Let C ≥ 1 be a fixed constant. For p ∈ (0, 1/2] a...
work page 1988
-
[23]
and B(n, p) = n Cℓ (1 − p)(Cℓ 2 ). Hence, if f(n, p) ≤ 0.99, there exists at least one such coloring with no monochromatic clique, implying r(ℓ, Cℓ) > n. It thus suffices to find the maximum value of n = n(p) such that f(n, p) = 0.99. Assume this maximum is achieved at p = pC,ℓ. Then, ∂f (n, pC,ℓ) ∂p = ℓ 2 pC,ℓ n ℓ p(ℓ 2) C,ℓ − Cℓ 2 1 − pC,ℓ n Cℓ (1 − pC,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.