Soft Head Selection for Injecting ICL-Derived Task Embeddings
Pith reviewed 2026-05-19 02:37 UTC · model grok-4.3
The pith
Gradient-based head selection lets ICL task embeddings outperform few-shot ICL and PEFT
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SITE identifies task-relevant attention heads by computing gradients with respect to task embeddings derived from few-shot in-context learning prompts and then injects the embeddings preferentially into the selected heads to adapt the model to downstream tasks.
What carries the argument
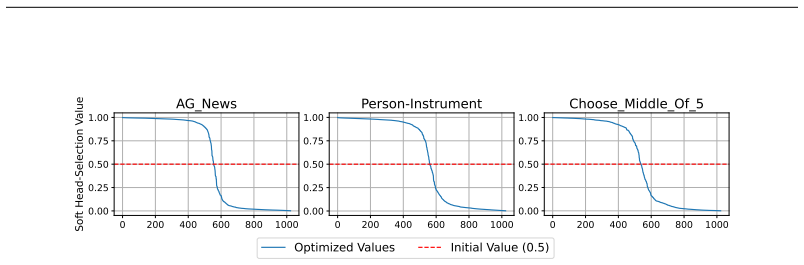
Gradient-based soft head selection that identifies task-relevant attention heads for targeted injection of ICL-derived task embeddings
If this is right
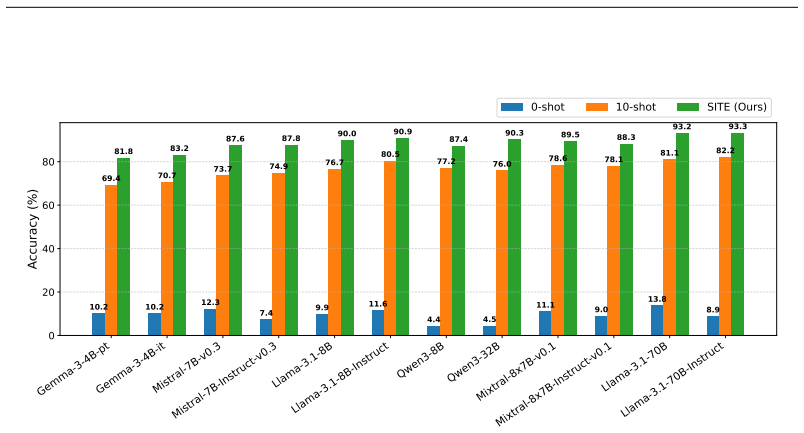
- SITE outperforms prior embedding-based adaptation methods and few-shot ICL across open-ended generation, reasoning, and natural language understanding tasks.
- The method requires substantially fewer trainable parameters than PEFT while delivering higher performance.
- Results hold across twelve LLMs sized from 4B to 70B parameters.
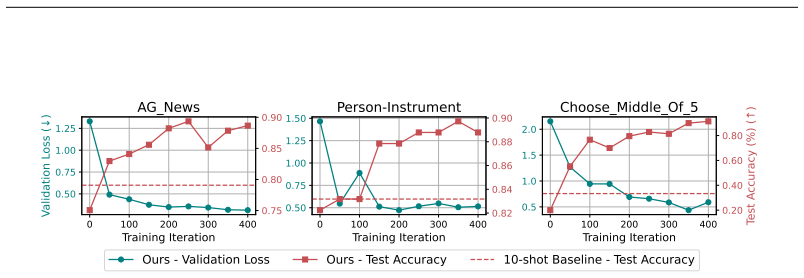
- Intra-task and inter-task activation patching shows strong task dependence in attention head functionality.
Where Pith is reading between the lines
- Similar gradient signals could be used to focus other adaptation techniques on the most relevant model components.
- Strong task dependence in heads implies attention mechanisms may implement identifiable modular computations that could transfer across related tasks.
- The approach might extend to zero-shot or dynamic selection settings to further lower adaptation costs.
Load-bearing premise
Gradients from few-shot ICL prompts can reliably identify task-relevant attention heads for embedding injection without selection bias or task-specific overfitting.
What would settle it
If randomly selected heads produce the same performance gains as gradient-selected heads when the same task embeddings are injected, the value of the selection step would be falsified.
Figures

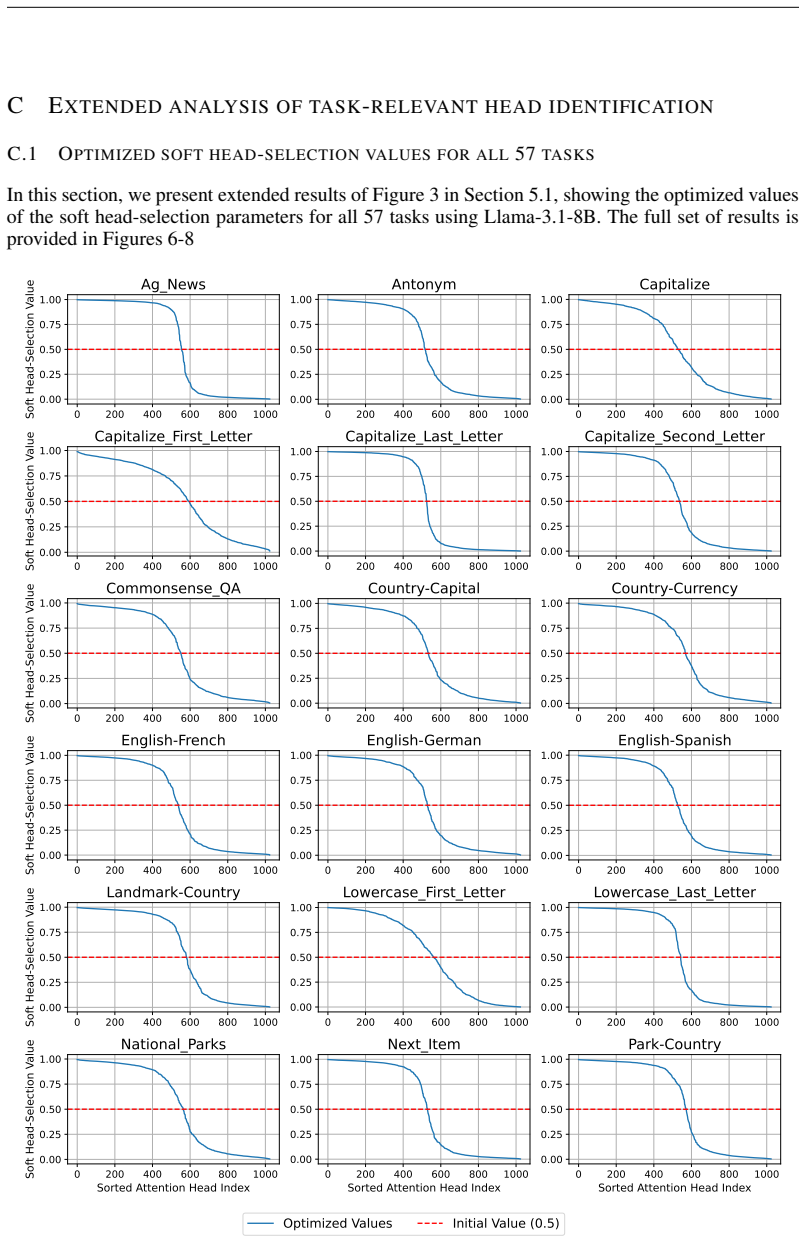

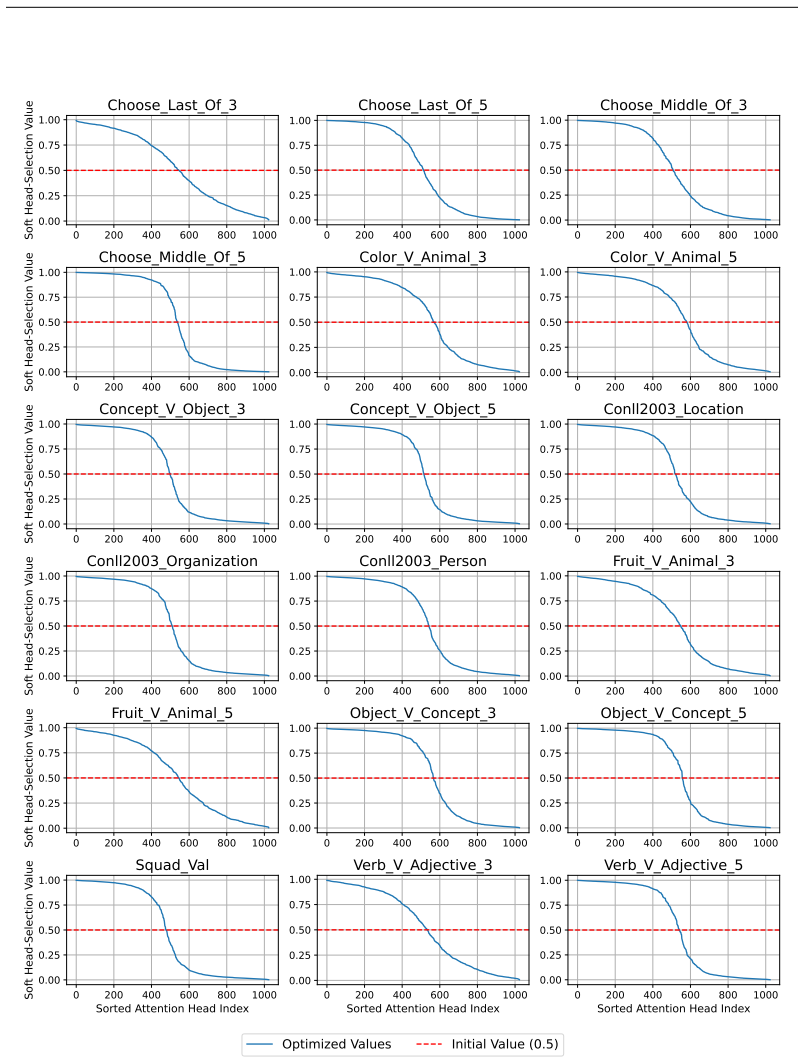









read the original abstract
Large language models (LLMs) are commonly adapted to downstream tasks using parameter-efficient fine-tuning (PEFT) or in-context learning (ICL). Recently, ICL-driven embedding-based adaptation has been proposed as a distinct task adaptation paradigm. It derives task-specific embeddings from intermediate activations using few-shot prompts and injects them during inference. Despite its conceptual appeal, this approach has not demonstrated consistent performance gains over PEFT or ICL, and its empirical advantages have been limited in practice. We propose Soft head-selection for ICL-derived Task Embeddings (SITE), a gradient-based method that identifies task-relevant attention heads to enable effective task embedding injection. Across various types of open-ended generation, reasoning, and natural language understanding tasks, SITE significantly outperforms prior embedding-based adaptation methods and few-shot ICL, while using substantially fewer trainable parameters than PEFT. Experiments on 12 LLMs ranging from 4B to 70B parameters demonstrate the generality of our approach, and intra-task and inter-task activation patching analyses further provide new mechanistic insights by revealing strong task dependence in attention head functionality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Soft head-selection for ICL-derived Task Embeddings (SITE), a gradient-based method to identify and softly select task-relevant attention heads for injecting embeddings derived from few-shot ICL prompts. It claims consistent outperformance over prior embedding-based adaptation methods and few-shot ICL across open-ended generation, reasoning, and NLU tasks on 12 LLMs (4B–70B parameters), while using substantially fewer trainable parameters than PEFT. Intra-task and inter-task activation patching analyses are presented as evidence of strong task dependence in attention head functionality.
Significance. If the claims hold after addressing selection robustness, the work offers a parameter-efficient adaptation paradigm that bridges ICL and embedding injection with mechanistic interpretability. The scale of experiments across model sizes and task categories, plus the patching analyses, would constitute a solid empirical contribution to efficient LLM adaptation.
major comments (2)
- [§3.2] §3.2 (gradient-based head selection): The method computes head importance from gradients on a fixed few-shot ICL prompt set. Because ICL is known to be sensitive to example order, selection, and formatting, it is unclear whether the resulting soft mask captures task-general heads or prompt artifacts. This directly bears on the performance gains in §4 and the task-dependence conclusions from the patching experiments in §5; a stability analysis across multiple prompt configurations for selection is needed.
- [§4] §4 (experimental results): The headline claim of significant outperformance lacks reported statistical testing, exact baseline re-implementation details, and confirmation that head-selection hyperparameters were not tuned on the same data used for final evaluation. These omissions weaken the reliability of the comparisons to PEFT, ICL, and prior embedding methods.
minor comments (2)
- [Abstract] Abstract: Include a brief mention of the number of tasks, model sizes, and whether gains are statistically significant to give readers a clearer sense of scope.
- [§3] Notation in §3: Define the soft selection weights and their injection mechanism more explicitly to avoid ambiguity when reproducing the forward pass.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate additional analyses and clarifications that strengthen the reliability of our claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (gradient-based head selection): The method computes head importance from gradients on a fixed few-shot ICL prompt set. Because ICL is known to be sensitive to example order, selection, and formatting, it is unclear whether the resulting soft mask captures task-general heads or prompt artifacts. This directly bears on the performance gains in §4 and the task-dependence conclusions from the patching experiments in §5; a stability analysis across multiple prompt configurations for selection is needed.
Authors: We agree that ICL sensitivity to prompt variations is a valid concern that could affect whether the selected heads reflect task-general properties or prompt artifacts. To address this directly, we will perform a stability analysis by varying example order, selection, and formatting during head selection, then report the consistency of the resulting soft masks and downstream performance. These results and discussion will be added to §3.2, with explicit links to how they support the task-dependence findings from the patching experiments in §5. revision: yes
-
Referee: [§4] §4 (experimental results): The headline claim of significant outperformance lacks reported statistical testing, exact baseline re-implementation details, and confirmation that head-selection hyperparameters were not tuned on the same data used for final evaluation. These omissions weaken the reliability of the comparisons to PEFT, ICL, and prior embedding methods.
Authors: We acknowledge the need for greater statistical rigor and transparency. In the revision we will add statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests across seeds) for all headline comparisons. We will also expand §4 with precise re-implementation details for every baseline, including code references and hyperparameter choices. Finally, we will explicitly confirm and document that head-selection hyperparameters were tuned exclusively on a held-out validation split disjoint from all evaluation data. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper proposes SITE, a gradient-based soft head selection procedure for injecting ICL-derived task embeddings, and supports its claims through direct experiments on 12 LLMs (4B–70B) that compare against independent external baselines (PEFT, few-shot ICL, prior embedding methods). Performance metrics and the intra-/inter-task patching analyses are defined and measured outside the head-selection rule itself; no equation or result is shown to reduce to the selection mask by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the derivation. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention heads in transformer LLMs possess task-dependent functionality that can be identified via gradient signals from ICL prompts.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[2]
Word Translation Without Parallel Data
Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Herv ´e J ´egou. Word translation without parallel data. arXiv preprint arXiv:1710.04087,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, et al. A survey on in-context learning.arXiv preprint arXiv:2301.00234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Is in-context learning in large language models bayesian? a martingale perspective
Fabian Falck, Ziyu Wang, and Chris Holmes. Is in-context learning in large language models bayesian? a martingale perspective. arXiv preprint arXiv:2406.00793,
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
In-context learning creates task vectors
Roee Hendel, Mor Geva, and Amir Globerson. In-context learning creates task vectors. arXiv preprint arXiv:2310.15916,
-
[7]
Linearity of relation decoding in transformer language models
Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. Linearity of relation decoding in transformer language models. In The Twelfth International Conference on Learning Representations. Or Honovich, Uri Shaham, Samuel R Bowman, and Omer Levy. Instruction induction: From few examples to...
-
[8]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chap- lot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L´elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth´ee Lacroix, and William El Sayed. Mistral 7b. arXiv preprint arX...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DARTS: Differentiable Architecture Search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search. arXiv preprint arXiv:1806.09055,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work?arXiv preprint arXiv:2202.12837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Distinguishing Antonyms and Synonyms in a Pattern-based Neural Network
Kim Anh Nguyen, Sabine Schulte im Walde, and Ngoc Thang Vu. Distinguishing antonyms and synonyms in a pattern-based neural network. arXiv preprint arXiv:1701.02962,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition
Erik F Sang and Fien De Meulder. Introduction to the conll-2003 shared task: Language- independent named entity recognition. arXiv preprint cs/0306050,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[16]
Aaditya K Singh, Ted Moskovitz, Felix Hill, Stephanie CY Chan, and Andrew M Saxe. What needs to go right for an induction head? a mechanistic study of in-context learning circuits and their formation. arXiv preprint arXiv:2404.07129,
-
[17]
Recursive deep models for semantic compositionality over a sentiment treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language pro- cessing, pp. 1631–1642,
work page 2013
-
[18]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge.arXiv preprint arXiv:1811.00937,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Function vectors in large language models
Eric Todd, Millicent L Li, Arnab Sen Sharma, Aaron Mueller, Byron C Wallace, and David Bau. Function vectors in large language models. arXiv preprint arXiv:2310.15213,
-
[21]
Retrieval head mechanisti- cally explains long-context factuality
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. Retrieval head mechanisti- cally explains long-context factuality. arXiv preprint arXiv:2404.15574,
-
[22]
An Explanation of In-context Learning as Implicit Bayesian Inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit bayesian inference. arXiv preprint arXiv:2111.02080,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Complementary explanations for effective in-context learning
Xi Ye, Srinivasan Iyer, Asli Celikyilmaz, Ves Stoyanov, Greg Durrett, and Ramakanth Pasunuru. Complementary explanations for effective in-context learning. arXiv preprint arXiv:2211.13892,
-
[25]
Xiaoqing Zhang, Ang Lv, Yuhan Liu, Flood Sung, Wei Liu, Jian Luan, Shuo Shang, Xiuying Chen, and Rui Yan. More is not always better? enhancing many-shot in-context learning with differen- tiated and reweighting objectives. arXiv preprint arXiv:2501.04070,
-
[26]
On the role of attention heads in large language model safety
Zhenhong Zhou, Haiyang Yu, Xinghua Zhang, Rongwu Xu, Fei Huang, Kun Wang, Yang Liu, Junfeng Fang, and Yongbin Li. On the role of attention heads in large language model safety. arXiv preprint arXiv:2410.13708,
-
[27]
Neural Architecture Search with Reinforcement Learning
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Kaijian Zou, Muhammad Khalifa, and Lu Wang. Retrieval or global context understanding? on many-shot in-context learning for long-context evaluation. arXiv preprint arXiv:2411.07130 ,
-
[29]
and MTV (Huang et al., 2024). For FV , we adopt the hy- perparameter settings specified for Llama-2-7B in the official repository and apply them to our experiments on Llama-3.1-8B, as both models share the same number of attention layers and atten- tion heads per layer. For MTV , we train the head-sampling distribution on the full training dataset for 100...
work page 2024
-
[30]
Input:Sammy wanted to go to where the people were
Task Name Task Description Input-Output Example CommonsenseQA Select the most plausible answer to a commonsense question from five given options. Input:Sammy wanted to go to where the people were. Where might he go? a: race track b: populated areas c: the desert d: apartment e: roadblock Output:b Country-Capital Generate the capital city of a given countr...
work page 2023
-
[31]
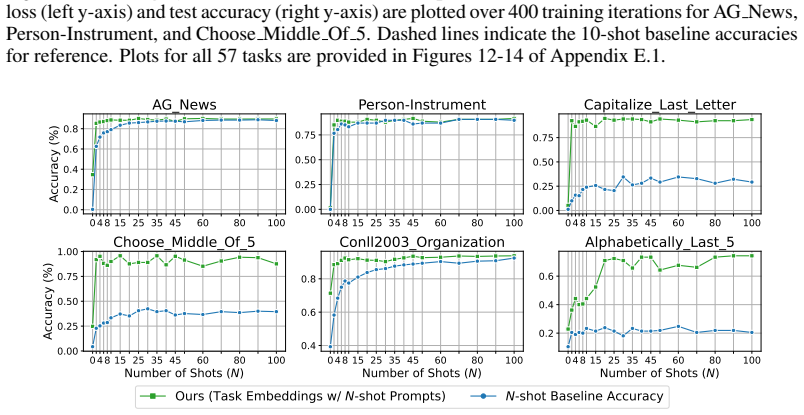
These results demonstrate the robustness of our method to variations in prompt format
Across all five templates, our method consistently achieves strong performance, with average accuracies ranging from 89.0% to 91.2%, significantly outperforming the 10-shot baseline (76.7%-77.8%). These results demonstrate the robustness of our method to variations in prompt format. Table 12: Prompt templates used in the ablation study. Each template show...
work page 2023
-
[32]
32 0 200 400 600 800 1000 0.00 0.25 0.50 0.75 1.00Soft Head-Selection Value Choose_Last_Of_3 0 200 400 600 800 1000 0.00 0.25 0.50 0.75 1.00 Choose_Last_Of_5 0 200 400 600 800 1000 0.00 0.25 0.50 0.75 1.00 Choose_Middle_Of_3 0 200 400 600 800 1000 0.00 0.25 0.50 0.75 1.00Soft Head-Selection Value Choose_Middle_Of_5 0 200 400 600 800 1000 0.00 0.25 0.50 0....
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.