Deepfake Detection that Generalizes Across Benchmarks
Pith reviewed 2026-05-18 23:43 UTC · model grok-4.3
The pith
A minimal update to a pre-trained vision model delivers state-of-the-art cross-dataset generalization for deepfake detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
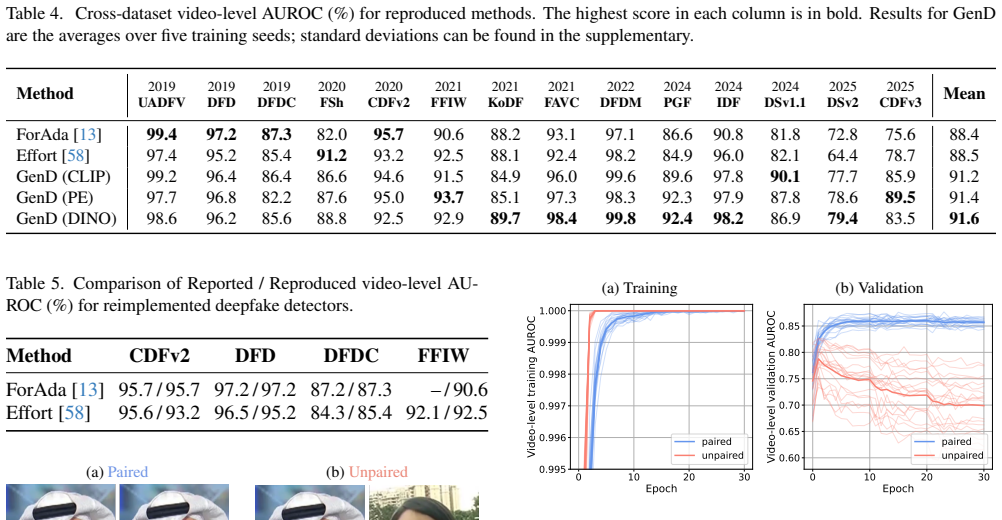
The GenD method updates only the Layer Normalization parameters of a foundational pre-trained vision encoder, representing 0.03 percent of the total parameters, and enforces a hyperspherical feature manifold by combining L2 normalization with metric learning. When evaluated across 14 benchmark datasets spanning 2019 to 2025, the resulting detector records higher average cross-dataset AUROC than more complex recent methods. The analysis further establishes that training on paired real and fake images drawn from the same source video is required to limit shortcut learning and that detection difficulty on academic benchmarks has not increased in a strictly monotonic fashion over time.
What carries the argument
GenD, the parameter-efficient adaptation of a pre-trained vision encoder that updates only its Layer Normalization parameters and projects features onto a hyperspherical manifold via L2 normalization and metric learning.
Load-bearing premise
That performance on the chosen 14 academic benchmarks from 2019 to 2025 serves as a reliable indicator of how the detector will behave against entirely new real-world manipulation techniques absent from all evaluation sets.
What would settle it
Evaluate the trained detector on a fresh dataset that uses a deepfake generation method completely outside the 14 benchmarks and check whether its average cross-dataset AUROC remains higher than that of competing approaches.
Figures



read the original abstract
The generalization of deepfake detectors to unseen manipulation techniques remains a challenge for practical deployment. Although many approaches adapt foundation models by introducing significant architectural complexity, this work demonstrates that robust generalization is achievable through a parameter-efficient adaptation of one of the foundational pre-trained vision encoders. The proposed method, GenD, fine-tunes only the Layer Normalization parameters (0.03% of the total) and enhances generalization by enforcing a hyperspherical feature manifold using L2 normalization and metric learning on it. We conducted an extensive evaluation on 14 benchmark datasets spanning from 2019 to 2025. The proposed method achieves state-of-the-art performance, outperforming more complex, recent approaches in average cross-dataset AUROC. Our analysis yields two primary findings for the field: 1) training on paired real-fake data from the same source video is essential for mitigating shortcut learning and improving generalization, and 2) detection difficulty on academic datasets has not strictly increased over time, with models trained on older, diverse datasets showing strong generalization capabilities. This work delivers a computationally efficient and reproducible method, proving that state-of-the-art generalization is attainable by making targeted, minimal changes to a pre-trained foundational image encoder model. The code is at: https://github.com/yermandy/GenD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GenD, a parameter-efficient method for deepfake detection. It adapts a pre-trained vision encoder by fine-tuning only the Layer Normalization parameters (0.03% of total parameters) while applying L2 normalization and metric learning to enforce a hyperspherical feature manifold. The method is evaluated on 14 benchmark datasets spanning 2019–2025 and claims state-of-the-art average cross-dataset AUROC, outperforming more complex recent approaches. Two key findings are reported: paired real-fake training data from the same source video is essential to mitigate shortcut learning, and detection difficulty on academic datasets has not strictly increased over time, with older diverse datasets generalizing well. Public code is provided.
Significance. If the empirical results hold, the work is significant for showing that robust cross-dataset generalization in deepfake detection is achievable via minimal, targeted adaptation of foundational encoders rather than architectural complexity. The 0.03% parameter count and public code are clear strengths that support reproducibility and practical utility. The two findings on paired training and non-increasing dataset difficulty offer concrete, actionable insights for the field.
major comments (1)
- [§4] §4 (Experimental evaluation): The manuscript claims state-of-the-art average cross-dataset AUROC but provides insufficient detail on the precise train/test splits across the 14 datasets and on whether baseline methods were re-implemented under identical conditions or taken from reported numbers. These details are load-bearing for independent verification of the SOTA claim and the two primary findings.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly name the base pre-trained vision encoder (e.g., which ViT or ResNet variant) to aid immediate reproducibility.
- [Tables/Figures] Figure captions and table headers would benefit from clearer indication of whether results are averaged over multiple runs or single runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address the single major comment below and will incorporate additional experimental details to strengthen reproducibility.
read point-by-point responses
-
Referee: [§4] §4 (Experimental evaluation): The manuscript claims state-of-the-art average cross-dataset AUROC but provides insufficient detail on the precise train/test splits across the 14 datasets and on whether baseline methods were re-implemented under identical conditions or taken from reported numbers. These details are load-bearing for independent verification of the SOTA claim and the two primary findings.
Authors: We agree that greater specificity on data partitioning and baseline implementation is essential for verification. In the revised manuscript we will add a dedicated subsection (and accompanying table) that enumerates, for each of the 14 datasets, the exact source videos or clips used for training versus testing, the number of real and fake frames in each split, and the temporal or identity-based partitioning strategy employed to avoid leakage. We will also explicitly state that all reported baseline results were obtained by re-implementing the competing methods ourselves under identical training protocols, data splits, optimizer settings, and evaluation metrics; any minor hyper-parameter deviations required by the original papers will be noted. The public code repository already contains the precise split-generation scripts and configuration files that reproduce these experiments, and we will add a README section that maps each table entry to the corresponding code path. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper's core contribution is an empirical method (GenD) that fine-tunes only LayerNorm parameters plus L2 normalization and metric learning, evaluated via comparative AUROC on 14 independent external benchmark datasets (2019-2025). The SOTA performance claim and two primary findings (importance of paired real-fake training; non-increasing difficulty over time) are direct experimental observations on held-out data, not quantities fitted within the training loop or reduced by construction to the method's inputs. No mathematical derivations, equations, uniqueness theorems, or ansatzes are invoked that collapse to self-definition or self-citation chains. The evaluation protocol is reproducible with public code and relies on external benchmarks rather than internal self-referential metrics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained vision foundation models yield transferable features for deepfake detection tasks
- domain assumption Enforcing a hyperspherical manifold via L2 normalization and metric learning improves generalization to unseen manipulations
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L2-normalized classification token … uniformity and alignment losses … Luniform = log E[exp(−2∥zx−zy∥²)] … Lalign = E[∥zx−zy∥²]
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fine-tunes only the Layer Normalization parameters (0.03% of the total)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Energy-Based Constraint Networks: Learning Structural Coherence Across Modalities
Energy-based constraint networks learn structural coherence from contrastive pairs using frozen encoders, achieving 93.4% accuracy on text corruptions and 0.959 AUC on deepfake detection with composable branches that ...
-
Aletheia: Physics-Conditioned Localized Artifact Attention (PhyLAA-X) for End-to-End Generalizable and Robust Deepfake Video Detection
PhyLAA-X embeds physics-derived feature volumes into localized artifact attention for improved cross-generator generalization and adversarial robustness in deepfake detection.
-
Fractal Characterization of Low-Correlation Signals in AI-Generated Image Detection
Fractal characterization of low-correlation signals distinguishes AI-generated images from real ones with claimed robustness and superior performance.
Reference graph
Works this paper leans on
-
[1]
Protecting world leaders against 8 deep fakes
Shruti Agarwal, Hany Farid, Yuming Gu, Mingming He, Koki Nagano, and Hao Li. Protecting world leaders against 8 deep fakes. InCVPR Workshops, 2019. 2
work page 2019
-
[2]
Proactive image manipulation detection
Vishal Asnani, Xi Yin, Tal Hassner, Sijia Liu, and Xiaoming Liu. Proactive image manipulation detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15386–15395, 2022. 2
work page 2022
-
[3]
MALP: manipulation localization using a proactive scheme
Vishal Asnani, Xi Yin, Tal Hassner, and Xiaoming Liu. MALP: manipulation localization using a proactive scheme. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12343–12352, 2023. 2
work page 2023
-
[4]
Realistic and efficient face swapping: A unified approach with diffusion models
Sanoojan Baliah, Qinliang Lin, Shengcai Liao, Xiaodan Liang, and Muhammad Haris Khan. Realistic and efficient face swapping: A unified approach with diffusion models. In 2025 IEEE/CVF Winter Conference on Applications of Com- puter Vision (WACV), pages 1062–1071. IEEE, 2025. 1
work page 2025
-
[5]
Sarah Barrington, Matyas Bohacek, and Hany Farid. Deep- speak dataset v1.0.arXiv preprint arXiv:2408.05366, 2024. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Per- turb, attend, detect and localize (PADL): Robust proactive image defense.IEEE Access, 2025
Filippo Bartolucci, Iacopo Masi, and Giuseppe Lisanti. Per- turb, attend, detect and localize (PADL): Robust proactive image defense.IEEE Access, 2025. 2
work page 2025
-
[7]
Bit- Fit: Simple parameter-efficient fine-tuning for transformer- based masked language-models
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. Bit- Fit: Simple parameter-efficient fine-tuning for transformer- based masked language-models. InProceedings of the 60th Annual Meeting of the Association for Computational Lin- guistics (Volume 2: Short Papers), pages 1–9, Dublin, Ire- land, 2022. Association for Computational Linguistics. 5
work page 2022
-
[8]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the net- work.arXiv preprint arXiv:2504.13181, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Stella Bounareli, Christos Tzelepis, Vasileios Argyriou, Ioannis Patras, and Georgios Tzimiropoulos. One-shot neu- ral face reenactment via finding directions in GAN’s latent space.International Journal of Computer Vision, 132(8): 3324–3354, 2024. 1
work page 2024
-
[10]
Sergi D Bray, Shane D Johnson, and Bennett Kleinberg. Testing human ability to detect ‘deepfake’ images of human faces.Journal of Cybersecurity, 9(1):tyad011, 2023. 1
work page 2023
-
[11]
Jikang Cheng, Zhiyuan Yan, Ying Zhang, Yuhao Luo, Zhongyuan Wang, and Chen Li. Can we leave deepfake data behind in training deepfake detector? InThe Thirty-eighth Annual Conference on Neural Information Processing Sys- tems, 2024. 5
work page 2024
-
[12]
Exploiting style latent flows for generalizing deepfake video detection
Jongwook Choi, Taehoon Kim, Yonghyun Jeong, Seungryul Baek, and Jongwon Choi. Exploiting style latent flows for generalizing deepfake video detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1133–1143, 2024. 5
work page 2024
-
[13]
Forensics adapter: Adapting CLIP for generaliz- able face forgery detection
Xinjie Cui, Yuezun Li, Ao Luo, Jiaran Zhou, and Junyu Dong. Forensics adapter: Adapting CLIP for generaliz- able face forgery detection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19207– 19217, 2025. 2, 4, 5, 6, 8
work page 2025
-
[14]
Google DeepMind. Veo 3, 2025.https://deepmind. google/models/veo/. 2
work page 2025
-
[15]
Retinaface: Single-shot multi- level face localisation in the wild
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kot- sia, and Stefanos Zafeiriou. Retinaface: Single-shot multi- level face localisation in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5203–5212, 2020. 3
work page 2020
-
[16]
The DeepFake Detection Challenge (DFDC) Dataset
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The deepfake detection challenge (DFDC) dataset.arXiv preprint arXiv:2006.07397, 2020. 4
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[17]
Deepfakes De- tection Dataset by Google & Jigsaw.https : / / research
Nicholas Dufour, Andrew Gully, Per Karlsson, Alexey Victor V orbyov, Thomas Leung, Jeremiah Childs, and Christoph Bregler. Deepfakes De- tection Dataset by Google & Jigsaw.https : / / research . google / blog / contributing - data - to - deepfake - detection - research/,
-
[18]
Xinghe Fu, Zhiyuan Yan, Taiping Yao, Shen Chen, and Xi Li. Exploring unbiased deepfake detection via token-level shuffling and mixing.arXiv preprint arXiv:2501.04376,
-
[19]
The expressive power of tuning only the normal- ization layers.arXiv preprint arXiv:2302.07937, 2023
Angeliki Giannou, Shashank Rajput, and Dimitris Papail- iopoulos. The expressive power of tuning only the normal- ization layers.arXiv preprint arXiv:2302.07937, 2023. 2
-
[20]
Lips don’t lie: A generalisable and robust approach to face forgery detection
Alexandros Haliassos, Konstantinos V ougioukas, Stavros Petridis, and Maja Pantic. Lips don’t lie: A generalisable and robust approach to face forgery detection. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5039–5049, 2021. 2, 4, 5
work page 2021
-
[21]
Leveraging real talking faces via self- supervision for robust forgery detection
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis, and Maja Pantic. Leveraging real talking faces via self- supervision for robust forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14950–14962, 2022. 5
work page 2022
-
[22]
Yue-Hua Han, Tai-Ming Huang, Kai-Lung Hua, and Jun- Cheng Chen. Towards more general video-based deepfake detection through facial component guided adaptation for foundation model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22995–23005,
-
[23]
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey.Transactions on Machine Learning Research, 2024. 5
work page 2024
-
[24]
Ammarah Hashmi, Sahibzada Adil Shahzad, Chia-Wen Lin, Yu Tsao, and Hsin-Min Wang. Unmasking illusions: Under- standing human perception of audiovisual deepfakes.arXiv preprint arXiv:2405.04097, 2024. 1
-
[25]
Polyglotfake: A novel multilingual and multimodal deepfake dataset
Yang Hou, Haitao Fu, Chunkai Chen, Zida Li, Haoyu Zhang, and Jianjun Zhao. Polyglotfake: A novel multilingual and multimodal deepfake dataset. InInternational Conference on Pattern Recognition, pages 180–193. Springer, 2024. 4
work page 2024
-
[26]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations, 2022. 5
work page 2022
-
[27]
Model attribution of face- swap deepfake videos
Shan Jia, Xin Li, and Siwei Lyu. Model attribution of face- swap deepfake videos. In2022 IEEE International Confer- 9 ence on Image Processing (ICIP), pages 2356–2360. IEEE,
-
[28]
FakeA VCeleb: A novel audio-video multimodal deepfake dataset.arXiv preprint arXiv:2108.05080,
Hasam Khalid, Shahroz Tariq, Minha Kim, and Simon S Woo. FakeA VCeleb: A novel audio-video multimodal deep- fake dataset.arXiv preprint arXiv:2108.05080, 2021. 4
-
[29]
Clipping the deception: Adapting vision-language models for univer- sal deepfake detection
Sohail Ahmed Khan and Duc-Tien Dang-Nguyen. Clipping the deception: Adapting vision-language models for univer- sal deepfake detection. InProceedings of the 2024 Inter- national Conference on Multimedia Retrieval, pages 1006– 1015, 2024. 2
work page 2024
-
[30]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Kodf: A large-scale korean deep- fake detection dataset
Patrick Kwon, Jaeseong You, Gyuhyeon Nam, Sungwoo Park, and Gyeongsu Chae. Kodf: A large-scale korean deep- fake detection dataset. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 10744– 10753, 2021. 4
work page 2021
-
[32]
Advancing high fidelity identity swapping for forgery detection
Lingzhi Li, Jianmin Bao, Hao Yang, Dong Chen, and Fang Wen. Advancing high fidelity identity swapping for forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5074–5083,
-
[33]
Vision-language model fine-tuning via simple parameter-efficient modification
Ming Li, Jike Zhong, Chenxin Li, Liuzhuozheng Li, Nie Lin, and Masashi Sugiyama. Vision-language model fine-tuning via simple parameter-efficient modification. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14394–14410, Miami, Florida, USA, 2024. Association for Computational Linguistics. 5
work page 2024
-
[34]
Celeb-df: A large-scale challenging dataset for deep- fake forensics
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-df: A large-scale challenging dataset for deep- fake forensics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3207– 3216, 2020. 4
work page 2020
-
[35]
Celeb-df++: A large-scale chal- lenging video deepfake benchmark for generalizable forensics,
Yuezun Li, Delong Zhu, Xinjie Cui, and Siwei Lyu. Celeb-df++: A large-scale challenging video deepfake benchmark for generalizable forensics.arXiv preprint arXiv:2507.18015, 2025. 3, 4
-
[36]
Forgery-aware adaptive transformer for generalizable synthetic image detection
Huan Liu, Zichang Tan, Chuangchuang Tan, Yunchao Wei, Jingdong Wang, and Yao Zhao. Forgery-aware adaptive transformer for generalizable synthetic image detection. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 10770–10780, 2024. 2
work page 2024
-
[37]
Weifeng Liu, Tianyi She, Jiawei Liu, Boheng Li, Dongyu Yao, and Run Wang. Lips are lying: Spotting the temporal inconsistency between audio and visual in lip-syncing deep- fakes.Advances in Neural Information Processing Systems, 37:91131–91155, 2024. 2, 4
work page 2024
-
[38]
Dat Nguyen, Nesryne Mejri, Inder Pal Singh, Polina Kuleshova, Marcella Astrid, Anis Kacem, Enjie Ghorbel, and Djamila Aouada. Laa-net: Localized artifact attention network for quality-agnostic and generalizable deepfake de- tection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17395– 17405, 2024. 5
work page 2024
-
[39]
Ex- ploring self-supervised vision transformers for deepfake de- tection: A comparative analysis
Huy H Nguyen, Junichi Yamagishi, and Isao Echizen. Ex- ploring self-supervised vision transformers for deepfake de- tection: A comparative analysis. InProceedings of the IEEE International Joint Conference on Biometrics (IJCB), pages 1–10, 2024. 2
work page 2024
-
[40]
Towards uni- versal fake image detectors that generalize across genera- tive models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards uni- versal fake image detectors that generalize across genera- tive models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24480– 24489, 2023. 1, 2, 4
work page 2023
-
[41]
Ziqiao Peng, Jiwen Liu, Haoxian Zhang, Xiaoqiang Liu, Songlin Tang, Pengfei Wan, Di Zhang, Hongyan Liu, and Jun He. Omnisync: Towards universal lip synchronization via diffusion transformers.arXiv preprint arXiv:2505.21448,
-
[42]
Wang Qi, Yu-Ping Ruan, Yuan Zuo, and Taihao Li. Parameter-efficient tuning on layer normalization for pre- trained language models.arXiv preprint arXiv:2211.08682,
-
[43]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning, pages 8748–8763. PmLR, 2021. 1, 2
work page 2021
-
[44]
Faceforen- sics++: Learning to detect manipulated facial images
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Chris- tian Riess, Justus Thies, and Matthias Nießner. Faceforen- sics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1–11, 2019. 3, 4
work page 2019
-
[45]
Detecting deep- fakes with self-blended images
Kaede Shiohara and Toshihiko Yamasaki. Detecting deep- fakes with self-blended images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18720–18729, 2022. 2, 5
work page 2022
-
[46]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Cyclical learning rates for training neural networks
Leslie N Smith. Cyclical learning rates for training neural networks. InProceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), pages 464–472. IEEE, 2017. 3
work page 2017
-
[48]
Synthesia, 2024.https://www.synthesia.io. 2
work page 2024
-
[49]
In- triguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. In- triguing properties of neural networks. InProceedings of the International Conference on Learning Representations (ICLR), 2014. 7
work page 2014
-
[50]
Real appearance mod- eling for more general deepfake detection
Jiahe Tian, Cai Yu, Xi Wang, Peng Chen, Zihao Xiao, Jiao Dai, Jizhong Han, and Yesheng Chai. Real appearance mod- eling for more general deepfake detection. InEuropean Con- ference on Computer Vision, pages 402–419. Springer, 2024. 5
work page 2024
-
[51]
Layernorm: A key component in parameter-efficient fine-tuning.arXiv preprint arXiv:2403.20284, 2024
Taha ValizadehAslani and Hualou Liang. Layernorm: A key component in parameter-efficient fine-tuning.arXiv preprint arXiv:2403.20284, 2024. 2
-
[52]
Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InInternational conference on machine learning, pages 9929–9939. PMLR, 2020. 2, 5 10
work page 2020
-
[53]
Altfreezing for more general video face forgery detection
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, and Houqiang Li. Altfreezing for more general video face forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4129–4138, 2023. 5
work page 2023
-
[54]
Identity-driven multimedia forgery detection via reference assistance
Junhao Xu, Jingjing Chen, Xue Song, Feng Han, Hai- jun Shan, and Yu-Gang Jiang. Identity-driven multimedia forgery detection via reference assistance. InProceedings of the 32nd ACM International Conference on Multimedia, pages 3887–3896, 2024. 4
work page 2024
-
[55]
Yuting Xu, Jian Liang, Lijun Sheng, and Xiao-Yu Zhang. Learning spatiotemporal inconsistency via thumbnail layout for face deepfake detection.International Journal of Com- puter Vision, 132(12):5663–5680, 2024. 5
work page 2024
-
[56]
Deepfakebench: A comprehensive benchmark of deepfake detection
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. Deepfakebench: A comprehensive benchmark of deepfake detection. InAdvances in Neural Information Processing Systems, pages 4534–4565. Curran Associates, Inc., 2023. 3
work page 2023
-
[57]
Transcending forgery specificity with latent space augmentation for generalizable deepfake detection
Zhiyuan Yan, Yuhao Luo, Siwei Lyu, Qingshan Liu, and Baoyuan Wu. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 8984–8994, 2024. 5
work page 2024
-
[58]
Orthogonal subspace decomposi- tion for generalizable AI-generated image detection
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke-Yue Zhang, Chengchun Liu, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. Orthogonal subspace decomposi- tion for generalizable AI-generated image detection. InPro- ceedings of the International Conference on Machine Learn- ing, 2025. 2, 4, 5, 6, 8
work page 2025
-
[59]
Zhiyuan Yan, Yandan Zhao, Shen Chen, Mingyi Guo, Xinghe Fu, Taiping Yao, Shouhong Ding, Yunsheng Wu, and Li Yuan. Generalizing deepfake video detection with plug- and-play: Video-level blending and spatiotemporal adapter tuning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12615–12625, 2025. 4, 5
work page 2025
-
[60]
Exposing deep fakes using inconsistent head poses
Xin Yang, Yuezun Li, and Siwei Lyu. Exposing deep fakes using inconsistent head poses. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8261–8265. IEEE, 2019. 4
work page 2019
-
[61]
Faceguard: Proactive deepfake detection.arXiv preprint arXiv:2109.05673, 2021
Yuankun Yang, Chenyue Liang, Hongyu He, Xiaoyu Cao, and Neil Zhenqiang Gong. Faceguard: Proactive deepfake detection.arXiv preprint arXiv:2109.05673, 2021. 2
-
[62]
Rui Zhai, Rongrong Ni, Yu Chen, Yang Yu, and Yao Zhao. Defending fake via warning: Universal proactive defense against face manipulation.IEEE Signal Processing Letters, 30:1072–1076, 2023. 2
work page 2023
-
[63]
Learning natural consistency represen- tation for face forgery video detection
Daichi Zhang, Zihao Xiao, Shikun Li, Fanzhao Lin, Jianmin Li, and Shiming Ge. Learning natural consistency represen- tation for face forgery video detection. InEuropean Con- ference on Computer Vision, pages 407–424. Springer, 2024. 5
work page 2024
-
[64]
Learning self-consistency for deepfake detection
Tianchen Zhao, Xiang Xu, Mingze Xu, Hui Ding, Yuanjun Xiong, and Wei Xia. Learning self-consistency for deepfake detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15023–15033, 2021. 5
work page 2021
-
[65]
Proactive image manipulation detection via deep semi-fragile watermark.Neurocomputing, 585:127593,
Yuan Zhao, Bo Liu, Tianqing Zhu, Ming Ding, Xin Yu, and Wanlei Zhou. Proactive image manipulation detection via deep semi-fragile watermark.Neurocomputing, 585:127593,
-
[66]
Exploring temporal coherence for more gen- eral video face forgery detection
Yinglin Zheng, Jianmin Bao, Dong Chen, Ming Zeng, and Fang Wen. Exploring temporal coherence for more gen- eral video face forgery detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 15044–15054, 2021. 4, 5
work page 2021
-
[67]
Tianfei Zhou, Wenguan Wang, Zhiyuan Liang, and Jian- bing Shen. Face forensics in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5778–5788, 2021. 3, 4 11
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.