Rethinking 1-bit Optimization Leveraging Pre-trained Large Language Models
Pith reviewed 2026-05-21 23:40 UTC · model grok-4.3
The pith
Pre-trained large language models can be adapted into high-performance 1-bit versions using progressive training instead of training from scratch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
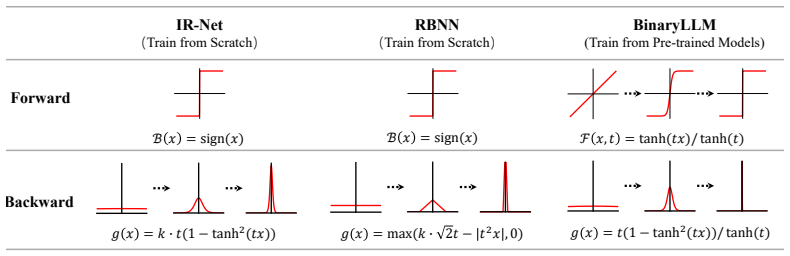
We identify that the large gap between full precision and 1-bit representations makes naive adaptation difficult. In this paper, we introduce a consistent progressive training for both forward and backward, smoothly converting the full-precision weights into the binarized ones. Additionally, we incorporate binary-aware initialization and dual-scaling compensation to reduce the difficulty of progressive training and improve the performance. Experimental results on LLMs of various sizes demonstrate that our method outperforms existing approaches. Our results show that high-performance 1-bit LLMs can be achieved using pre-trained models, eliminating the need for expensive training from scratch.
What carries the argument
Consistent progressive training applied to both forward and backward passes, together with binary-aware initialization and dual-scaling compensation, that gradually converts full-precision weights to binary form.
If this is right
- High-performance 1-bit LLMs become reachable directly from pre-trained checkpoints.
- Training costs drop because full from-scratch binarized training is no longer required.
- Accuracy degradation typical in 1-bit quantization is reduced across models of different sizes.
- Storage and compute savings are realized while retaining competitive task performance.
- Existing pre-trained assets can be reused for efficient quantized deployment.
Where Pith is reading between the lines
- The same gradual-adaptation idea could be tested on other low-bit or mixed-precision schemes beyond strict 1-bit.
- Practitioners might combine this conversion step with existing fine-tuning pipelines to produce task-specific 1-bit models more quickly.
- If the progressive schedule proves robust, it may encourage re-examination of other large representation-gap problems in model compression.
- Deployment on edge hardware could become more routine once pre-trained models are routinely turned into 1-bit versions.
Load-bearing premise
The large gap between full-precision and 1-bit representations can be bridged smoothly by consistent progressive training in forward and backward passes without irrecoverable accuracy loss.
What would settle it
If side-by-side tests on standard LLM benchmarks show that the resulting 1-bit models still lose substantial accuracy relative to full-precision versions or to from-scratch 1-bit baselines, the claim of successful smooth conversion would not hold.
Figures






read the original abstract
1-bit LLM quantization offers significant advantages in reducing storage and computational costs. However, existing methods typically train 1-bit LLMs from scratch, failing to fully leverage pre-trained models. This results in high training costs and notable accuracy degradation. We identify that the large gap between full precision and 1-bit representations makes naive adaptation difficult. In this paper, we introduce a consistent progressive training for both forward and backward, smoothly converting the full-precision weights into the binarized ones. Additionally, we incorporate binary-aware initialization and dual-scaling compensation to reduce the difficulty of progressive training and improve the performance. Experimental results on LLMs of various sizes demonstrate that our method outperforms existing approaches. Our results show that high-performance 1-bit LLMs can be achieved using pre-trained models, eliminating the need for expensive training from scratch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing 1-bit LLM quantization methods require training from scratch and suffer from accuracy degradation due to the large gap between full-precision and binarized representations. It proposes consistent progressive training applied to both forward and backward passes, combined with binary-aware initialization and dual-scaling compensation, to smoothly convert pre-trained full-precision weights into 1-bit models. Experiments on LLMs of various sizes are reported to show outperformance over prior approaches, supporting the conclusion that high-performance 1-bit LLMs can be obtained from pre-trained checkpoints without expensive from-scratch training.
Significance. If the empirical results hold with proper controls, the work would be significant for reducing the training cost of 1-bit LLMs by reusing pre-trained models rather than starting from random initialization. This could lower barriers to deploying efficient quantized models. The approach is presented as an empirical training procedure rather than a parameter-free derivation or machine-checked proof.
major comments (2)
- [Abstract and method description] The central claim that consistent progressive training (forward and backward) plus binary-aware init and dual-scaling bridges the representation gap without irrecoverable loss is load-bearing, yet the manuscript provides no ablation studies or intermediate training dynamics that isolate the progressive schedule's contribution. Without these, performance gains could be attributable to the pre-trained starting point alone rather than the proposed techniques.
- [Abstract and experimental results] The abstract states outperformance on LLMs of various sizes, but the provided text contains no error bars, statistical significance tests, or full experimental details (e.g., training hyperparameters, dataset splits, or exact baselines). This undermines verification of the claim that the method eliminates the need for training from scratch.
minor comments (1)
- [Method] Notation for the dual-scaling compensation and binary-aware initialization should be defined more explicitly with equations to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We have carefully reviewed the major comments and provide detailed point-by-point responses below. We agree that certain aspects of the presentation can be strengthened and outline the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract and method description] The central claim that consistent progressive training (forward and backward) plus binary-aware init and dual-scaling bridges the representation gap without irrecoverable loss is load-bearing, yet the manuscript provides no ablation studies or intermediate training dynamics that isolate the progressive schedule's contribution. Without these, performance gains could be attributable to the pre-trained starting point alone rather than the proposed techniques.
Authors: We appreciate the referee's emphasis on the need for ablations to rigorously isolate the contribution of the consistent progressive training schedule. The manuscript presents the progressive training applied to both forward and backward passes, together with binary-aware initialization and dual-scaling compensation, as the key mechanisms for smoothly bridging the full-precision to 1-bit representation gap. While the current version focuses on the overall empirical outcomes, we acknowledge that dedicated ablation studies and intermediate training dynamics (such as loss or accuracy curves across training steps) are not explicitly included. In the revised manuscript, we will add these elements, including comparisons of the full proposed method against ablated variants that omit the progressive schedule, as well as plots illustrating training dynamics. This will help demonstrate that the performance improvements stem from the proposed techniques rather than the pre-trained initialization alone. revision: yes
-
Referee: [Abstract and experimental results] The abstract states outperformance on LLMs of various sizes, but the provided text contains no error bars, statistical significance tests, or full experimental details (e.g., training hyperparameters, dataset splits, or exact baselines). This undermines verification of the claim that the method eliminates the need for training from scratch.
Authors: We thank the referee for highlighting the importance of detailed experimental reporting to support the claims. The manuscript reports that our method outperforms existing approaches on LLMs of various sizes and concludes that high-performance 1-bit models can be obtained from pre-trained checkpoints without from-scratch training. However, we agree that the current text does not include error bars, statistical significance tests, or exhaustive details on training hyperparameters, dataset splits, and exact baseline configurations. In the revision, we will expand the experimental section to incorporate these: reporting means and standard deviations over multiple runs, including statistical significance tests where appropriate, and providing complete specifications of hyperparameters, dataset splits, and baseline implementations. These additions will improve the reproducibility and strengthen the evidence for our central claim. revision: yes
Circularity Check
No circularity: empirical training procedure validated on external benchmarks
full rationale
The paper presents an empirical method consisting of consistent progressive training in forward and backward passes, binary-aware initialization, and dual-scaling compensation to adapt pre-trained full-precision LLMs to 1-bit representations. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the method's own inputs or outputs. Performance claims rest on experimental results across LLMs of various sizes, which constitute external validation rather than internal tautologies or self-referential definitions. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The large gap between full-precision and 1-bit representations makes naive adaptation difficult and can be addressed by consistent progressive training.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a consistent progressive training for both forward and backward, smoothly converting the full-precision weights into the binarized ones... F(x, t) = tanh(tx)/tanh(t)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
binary-aware initialization... dual-scaling compensation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Smollm - blazingly fast and remarkably powerful, 2024
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Leandro von Werra, and Thomas Wolf. Smollm - blazingly fast and remarkably powerful, 2024. 12 1 3 5 7 9 11 13 15 chunk 0 5 10 15 20 25 30 35The value of t Uniform Progressive 1 0 1 1.5 1.0 0.5 0.0 0.5 1.0 1.5 PPL=36.9, Zero-shot Acc.=40.5 1 3 5 7 9 11 13 15 chunk 0 5 10 15 20 25 30 35The value of t Logarithm ...
work page 2024
-
[2]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023
work page 2023
-
[3]
Piqa: Reasoning about physical common- sense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical common- sense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
work page 2020
-
[4]
Db-llm: Accurate dual-binarization for efficient llms
Hong Chen, Chengtao Lv, Liang Ding, Haotong Qin, Xiabin Zhou, Yifu Ding, Xuebo Liu, Min Zhang, Jinyang Guo, Xianglong Liu, et al. Db-llm: Accurate dual-binarization for efficient llms. arXiv preprint arXiv:2402.11960, 2024
-
[5]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. ArXiv, abs/1905.10044, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv preprint arXiv:1602.02830, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Cbq: Cross-block quantization for large language models
Xin Ding, Xiaoyu Liu, Zhijun Tu, Yun Zhang, Wei Li, Jie Hu, Hanting Chen, Yehui Tang, Zhiwei Xiong, Baoqun Yin, et al. Cbq: Cross-block quantization for large language models. arXiv preprint arXiv:2312.07950, 2023
-
[10]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
EleutherAI. lm-evaluation-harness, 2021. Accessed: 2025-01-14
work page 2021
-
[12]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022. 13 Chunk 1 Chunk 2 Chunk 3 Chunk 4 Chunk 5 Chunk 6 Chunk 7 Chunk 8 Chunk 9 Chunk 10 Chunk 11 Chunk 12 Chunk 13 Chunk 14 Chunk 15 Chunk 16 Chunk 17 Chunk 18 Chunk 19 Chun...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Pt-bitnet: 1-bit large language model with post-training quantization.Available at SSRN 4987078
Yufei Guo, Zecheng Hao, Jiahang Shao, Jie Zhou, Xiaode Liu, Xin Tong, Yuhan Zhang, Yuanpei Chen, Weihang Peng, and Zhe Ma. Pt-bitnet: 1-bit large language model with post-training quantization.Available at SSRN 4987078
-
[14]
Billm: Pushing the limit of post-training quantization for llms
Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, and Xi- aojuan Qi. Billm: Pushing the limit of post-training quantization for llms. arXiv preprint arXiv:2402.04291, 2024
-
[15]
Loftq: Lora-fine-tuning-aware quantization for large language models
Yixiao Li, Yifan Yu, Chen Liang, Pengcheng He, Nikos Karampatziakis, Weizhu Chen, and Tuo Zhao. Loftq: Lora-fine-tuning-aware quantization for large language models. arXiv preprint arXiv:2310.08659, 2023
-
[16]
Arb-llm: Alternating refined binarizations for large language models
Zhiteng Li, Xianglong Yan, Tianao Zhang, Haotong Qin, Dong Xie, Jiang Tian, Linghe Kong, Yulun Zhang, Xiaokang Yang, et al. Arb-llm: Alternating refined binarizations for large language models. arXiv preprint arXiv:2410.03129, 2024
-
[17]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. Proceedings of Machine Learning and Systems, 6:87–100, 2024
work page 2024
-
[18]
Mingbao Lin, Rongrong Ji, Zihan Xu, Baochang Zhang, Yan Wang, Yongjian Wu, Feiyue Huang, and Chia-Wen Lin. Rotated binary neural network. Advances in neural information processing systems , 33:7474–7485, 2020
work page 2020
-
[19]
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. Llm-qat: Data-free quantization aware training for large language models. arXiv preprint arXiv:2305.17888, 2023. 14
-
[20]
Reactnet: Towards precise binary neural network with generalized activation functions
Zechun Liu, Zhiqiang Shen, Marios Savvides, and Kwang-Ting Cheng. Reactnet: Towards precise binary neural network with generalized activation functions. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, pages 143–159. Springer, 2020
work page 2020
-
[21]
Fbi-llm: Scaling up fully binarized llms from scratch via autoregressive distillation
Liqun Ma, Mingjie Sun, and Zhiqiang Shen. Fbi-llm: Scaling up fully binarized llms from scratch via autoregressive distillation. arXiv preprint arXiv:2407.07093, 2024
- [22]
-
[23]
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit llms: All large language models are in 1.58 bits. arXiv preprint arXiv:2402.17764, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
On the State of the Art of Evaluation in Neural Language Models
Gábor Melis, Chris Dyer, and Phil Blunsom. On the state of the art of evaluation in neural language models. arXiv preprint arXiv:1707.05589, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InConference on Empirical Methods in Natural Language Processing, 2018
work page 2018
-
[27]
Fine-tuning llms to 1.58bit: extreme quantization made easy, 2024
Leandro von Werra Pedro Cuenca Omar Sanseviero Mohamed Mekkouri, Marc Sun and Thomas Wolf. Fine-tuning llms to 1.58bit: extreme quantization made easy, 2024
work page 2024
-
[28]
Xu Ouyang, Tao Ge, Thomas Hartvigsen, Zhisong Zhang, Haitao Mi, and Dong Yu. Low-bit quantization favors undertrained llms: Scaling laws for quantized llms with 100t training tokens. arXiv preprint arXiv:2411.17691, 2024
-
[29]
Forward and backward information retention for accurate binary neural networks
Haotong Qin, Ruihao Gong, Xianglong Liu, Mingzhu Shen, Ziran Wei, Fengwei Yu, and Jingkuan Song. Forward and backward information retention for accurate binary neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2250–2259, 2020
work page 2020
-
[30]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[31]
Xnor-net: Imagenet classifi- cation using binary convolutional neural networks
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classifi- cation using binary convolutional neural networks. In European conference on computer vision, pages 525–542. Springer, 2016
work page 2016
-
[32]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021
work page 2021
-
[33]
Pb-llm: Partially binarized large language models
Yuzhang Shang, Zhihang Yuan, Qiang Wu, and Zhen Dong. Pb-llm: Partially binarized large language models. arXiv preprint arXiv:2310.00034, 2023
-
[34]
Omniquant: Omnidirectionally calibrated quantization for large language models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models. arXiv preprint arXiv:2308.13137, 2023
-
[35]
A survey on transformer compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, and Dacheng Tao. A survey on transformer compression. arXiv preprint arXiv:2402.05964, 2024
-
[36]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Adabin: Improving binary neural networks with adaptive binary sets
Zhijun Tu, Xinghao Chen, Pengju Ren, and Yunhe Wang. Adabin: Improving binary neural networks with adaptive binary sets. In European conference on computer vision, pages 379–395. Springer, 2022
work page 2022
-
[38]
BitNet: Scaling 1-bit Transformers for Large Language Models
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. Bitnet: Scaling 1-bit transformers for large language models. arXiv preprint arXiv:2310.11453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Redpajama: an open dataset for training large language models
Maurice Weber, Daniel Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, et al. Redpajama: an open dataset for training large language models. arXiv preprint arXiv:2411.12372, 2024. 15
-
[40]
T-mac: Cpu renaissance via table lookup for low-bit llm deployment on edge, 2024
Jianyu Wei, Shijie Cao, Ting Cao, Lingxiao Ma, Lei Wang, Yanyong Zhang, and Mao Yang. T-mac: Cpu renaissance via table lookup for low-bit llm deployment on edge, 2024
work page 2024
-
[41]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, pages 38087–38099. PMLR, 2023
work page 2023
-
[42]
Onebit: Towards extremely low-bit large language models
Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, and Wanxiang Che. Onebit: Towards extremely low-bit large language models. arXiv preprint arXiv:2402.11295, 2024
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page 2025
-
[44]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Annual Meeting of the Association for Computational Linguistics, 2019
work page 2019
-
[45]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Be- ichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
An empirical study of qwen3 quantization
Xingyu Zheng, Yuye Li, Haoran Chu, Yue Feng, Xudong Ma, Jie Luo, Jinyang Guo, Haotong Qin, Michele Magno, and Xianglong Liu. An empirical study of qwen3 quantization. arXiv preprint arXiv:2505.02214, 2025
-
[48]
Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights
Aojun Zhou, Anbang Yao, Yiwen Guo, Lin Xu, and Yurong Chen. Incremental network quantization: Towards lossless cnns with low-precision weights. arXiv preprint arXiv:1702.03044, 2017. 16
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.