BEDTime: A Unified Benchmark for Automatically Describing Time Series
Pith reviewed 2026-05-18 18:52 UTC · model grok-4.3
The pith
A benchmark reveals that vision-language models describe structural features of time series better than dedicated time-series models or language-only approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Successful models for time-series and language should first master recognizing structural properties, differentiating between series, and generating accurate textual descriptions of univariate time series. The BEDTime benchmark, which reformats five datasets across text, image, and time-series modalities, demonstrates that dedicated time-series language models fall short on these tasks despite their design, vision-language models perform more strongly, language-only methods perform worst, and all approaches remain fragile under robustness perturbations.
What carries the argument
The BEDTime benchmark, which evaluates three core tasks (recognition, differentiation, and generation of descriptions) on five reformatted univariate time-series datasets presented in three modalities.
If this is right
- Prior claims of strong performance on complex time-series reasoning and cross-modal question answering rest on untested foundational skills.
- Vision-language models offer a stronger starting point than time-series-specific architectures for descriptive tasks.
- Language-only models require additional mechanisms to capture structural time-series features effectively.
- Robustness to noise, scale shifts, and other real-world variations must be improved before any approach can support reliable applications.
- Future model development should include explicit evaluation on recognition, differentiation, and generation before scaling to harder tasks.
Where Pith is reading between the lines
- The benchmark could be extended to multivariate series to test whether the same ordering of model families holds when interactions between channels matter.
- If vision-language models continue to lead, training pipelines that convert time series into images may become a default route for descriptive and reasoning capabilities.
- The fragility finding suggests that current training objectives for time-series language models do not sufficiently penalize sensitivity to small distributional changes.
- A practical next step would be to measure whether models that pass BEDTime also improve on downstream tasks such as anomaly explanation or forecasting justification.
Load-bearing premise
That the three tasks of recognizing, differentiating, and generating descriptions of univariate time series are the foundational skills any model claiming advanced time-series reasoning must have mastered first.
What would settle it
A dedicated time-series language model that scores above 80 percent accuracy on all three tasks across the five datasets while maintaining performance under the paper's robustness perturbations would falsify the claim that such models fall short.
Figures




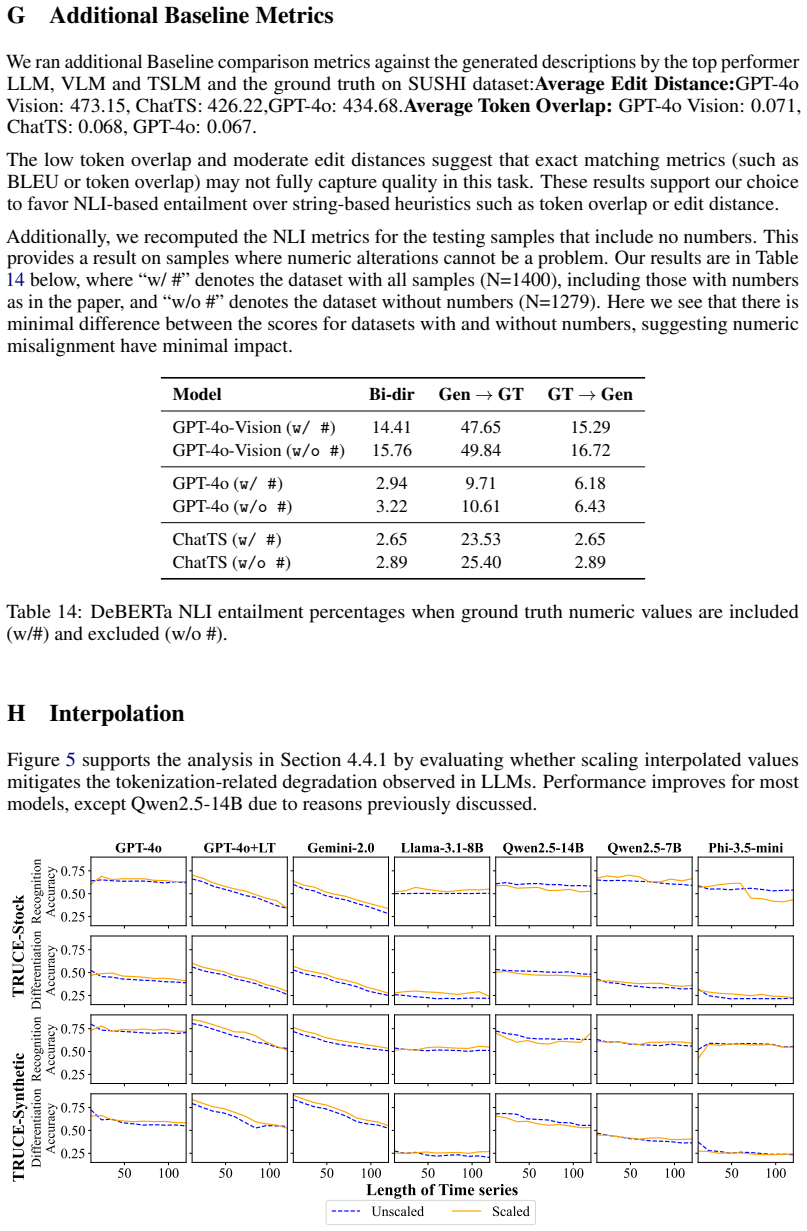
read the original abstract
Recent works propose complex multi-modal models that handle both time series and language, ultimately claiming high performance on complex tasks like time series reasoning and cross-modal question answering. However, they skip foundational evaluations that such complex models should have mastered. So we ask a simple question: \textit{How well can recent models describe structural properties of time series?} To answer this, we propose that successful models should be able to \textit{recognize}, \textit{differentiate}, and \textit{generate} descriptions of univariate time series. We then create \textbf{\benchmark}, a benchmark to assess these novel tasks, that comprises \textbf{five datasets} reformatted across \textbf{three modalities}. In evaluating \textbf{17 state-of-the-art models}, we find that (1) surprisingly, dedicated time series-language models fall short, despite being designed for similar tasks, (2) vision language models are quite capable, (3) language only methods perform worst, despite many lauding their potential, and (4) all approaches are clearly fragile to a range of real world robustness tests, indicating directions for future work. Together, our findings critique prior works' claims and provide avenues for advancing multi-modal time series modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BEDTime, a benchmark for assessing models' ability to recognize, differentiate, and generate descriptions of univariate time series. It reformats five existing datasets into three modalities and evaluates 17 state-of-the-art models (including dedicated time series-language models, vision-language models, and language-only methods). The central findings are that time series-language models underperform despite their design, vision-language models are relatively capable, language-only approaches perform worst, and all models show fragility under robustness tests. The work uses these results to critique prior multi-modal models for skipping such foundational evaluations before claiming performance on complex tasks like time series reasoning and cross-modal QA.
Significance. If the benchmark construction and evaluations are robust, the work provides a useful standardized testbed for basic time series description skills that could help diagnose limitations in current multi-modal approaches. The empirical comparison across 17 models and the inclusion of real-world robustness tests add concrete evidence on performance gaps and fragility, which may usefully inform future model development even if the foundational premise requires further support.
major comments (2)
- [Introduction and §3] Introduction and §3 (Benchmark Tasks): The central critique of prior works rests on the claim that recognizing, differentiating, and generating descriptions of univariate time series are foundational prerequisite skills for any model asserting time series reasoning or cross-modal QA capabilities. This assumption is load-bearing but receives limited justification; the manuscript does not provide explicit argument, cognitive/ML references, or evidence showing why strong performance on these specific univariate reformatted tasks is necessary before complex reasoning can succeed. If complex models can achieve higher-level tasks without excelling here, the reported performance gaps would not necessarily invalidate prior claims.
- [§4] §4 (Dataset Reformatting and Modalities): The description of how the five datasets were reformatted across the three modalities lacks sufficient detail on preprocessing steps, preservation of structural properties, and controls for leakage or bias. This is load-bearing for the validity of the cross-model comparisons and the fragility findings, as reformatting choices directly affect what 'structural properties' are being tested.
minor comments (2)
- [§5] §5 (Evaluation Metrics): For the generation task, specify whether LLM-based metrics were used and how circularity was avoided (e.g., via human validation or fixed judges); this would strengthen interpretability of the reported gaps.
- [Results tables] Table 2 or equivalent results table: Ensure consistent categorization of the 17 models (TS-LM vs. VLM vs. language-only) with citations and hyperparameter details for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments identify important areas for clarification and strengthening. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Introduction and §3] Introduction and §3 (Benchmark Tasks): The central critique of prior works rests on the claim that recognizing, differentiating, and generating descriptions of univariate time series are foundational prerequisite skills for any model asserting time series reasoning or cross-modal QA capabilities. This assumption is load-bearing but receives limited justification; the manuscript does not provide explicit argument, cognitive/ML references, or evidence showing why strong performance on these specific univariate reformatted tasks is necessary before complex reasoning can succeed. If complex models can achieve higher-level tasks without excelling here, the reported performance gaps would not necessarily invalidate prior claims.
Authors: We appreciate the referee's observation that the foundational premise requires stronger support. Our view is that these tasks capture basic perceptual and descriptive competencies that logically precede higher-order reasoning, analogous to how low-level feature extraction supports complex inference in multimodal systems. In revision we will expand the Introduction and §3 with explicit argumentation, drawing on references from cognitive science regarding hierarchical skill development and from ML literature on the necessity of basic multimodal alignment before advanced reasoning. We will also note that even if not strictly prerequisite, poor performance on these tasks still diagnostically highlights limitations in current models' time-series understanding. revision: yes
-
Referee: [§4] §4 (Dataset Reformatting and Modalities): The description of how the five datasets were reformatted across the three modalities lacks sufficient detail on preprocessing steps, preservation of structural properties, and controls for leakage or bias. This is load-bearing for the validity of the cross-model comparisons and the fragility findings, as reformatting choices directly affect what 'structural properties' are being tested.
Authors: We agree that greater detail on reformatting is necessary to support the validity of the comparisons and robustness results. In the revised manuscript we will substantially expand §4 to document the full preprocessing pipelines for each dataset and modality. This will include explicit steps for preserving structural properties (e.g., trends, seasonality, anomalies), quantitative checks on property retention, and controls implemented to avoid leakage or systematic bias across reformattings. Where feasible we will add pseudocode or illustrative examples. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation
full rationale
This is a benchmark paper that defines three tasks (recognize, differentiate, generate descriptions of univariate time series), reformats five existing datasets into three modalities, and reports empirical performance of 17 models. No derivations, equations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided abstract or description. The central claims rest on direct model evaluations against the new benchmark rather than any reduction of results to the paper's own inputs by construction. The assumption that these tasks are foundational is stated explicitly but does not create circularity in the evaluation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The tasks of recognizing, differentiating, and generating descriptions of univariate time series are foundational skills that complex multi-modal models should have mastered before tackling time series reasoning and cross-modal question answering.
Forward citations
Cited by 1 Pith paper
-
LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
LLaTiSA is a vision-language model trained on a new 83k-sample hierarchical time series reasoning dataset that shows superior performance and out-of-distribution generalization on stratified TSR tasks.
Reference graph
Works this paper leans on
-
[1]
Chang Lu, Chandan K Reddy, Ping Wang, Dong Nie, and Yue Ning. Multi-label clinical time- series generation via conditional gan.IEEE Transactions on Knowledge and Data Engineering, 36(4):1728–1740, 2023
work page 2023
-
[2]
Kamila Romanowski, Michael R Law, Mohammad Ehsanul Karim, Jonathon R Campbell, Md Belal Hossain, Mark Gilbert, Victoria J Cook, and James C Johnston. Healthcare utilization after respiratory tuberculosis: a controlled interrupted time series analysis.Clinical Infectious Diseases, 77(6):883–891, 2023
work page 2023
-
[3]
H Manisha Yapa, Hae-Young Kim, Kathy Petoumenos, Frank A Post, Awachana Jiamsakul, Jan-Walter De Neve, Frank Tanser, Collins Iwuji, Kathy Baisley, Maryam Shahmanesh, et al. Cd4+ t-cell count at antiretroviral therapy initiation in the “treat-all” era in rural south africa: an interrupted time series analysis.Clinical Infectious Diseases, 74(8):1350–1359, 2022
work page 2022
-
[4]
Nhung TH Trinh, Sophie de Visme, Jeremie F Cohen, Tim Bruckner, Nathalie Lelong, Pauline Adnot, Jean-Christophe Rozé, Béatrice Blondel, François Goffinet, Grégoire Rey, et al. Recent historic increase of infant mortality in france: A time-series analysis, 2001 to 2019.The Lancet Regional Health–Europe, 16, 2022
work page 2001
-
[5]
Torsten Rackoll, Konrad Neumann, Sven Passmann, Ulrike Grittner, Nadine Külzow, Julia Ladenbauer, and Agnes Flöel. Applying time series analyses on continuous accelerometry data—a clinical example in older adults with and without cognitive impairment.Plos one, 16(5):e0251544, 2021
work page 2021
-
[6]
Yong Hu, Kang Liu, Xiangzhou Zhang, Lijun Su, EWT Ngai, and Mei Liu. Application of evolutionary computation for rule discovery in stock algorithmic trading: A literature review. Applied Soft Computing, 36:534–551, 2020
work page 2020
-
[7]
Robert ´Slepaczuk and Maryna Zenkova. Robustness of support vector machines in algorithmic trading on cryptocurrency market.Central European Economic Journal, 5(52):186–205, 2018
work page 2018
-
[8]
A comparative study of bitcoin price prediction using deep learning.Mathematics, 7(10):898, 2019
Suhwan Ji, Jongmin Kim, and Hyeonseung Im. A comparative study of bitcoin price prediction using deep learning.Mathematics, 7(10):898, 2019
work page 2019
-
[9]
Omer Berat Sezer and Ahmet Murat Ozbayoglu. Algorithmic financial trading with deep convolutional neural networks: Time series to image conversion approach.Applied Soft Computing, 70:525–538, 2018
work page 2018
-
[10]
Stephan Schulmeister. Profitability of technical stock trading: Has it moved from daily to intraday data?Review of Financial Economics, 18(4):190–201, 2019
work page 2019
-
[11]
Jun Wang, Wenjie Du, Yiyuan Yang, Linglong Qian, Wei Cao, Keli Zhang, Wenjia Wang, Yuxuan Liang, and Qingsong Wen. Deep learning for multivariate time series imputation: A survey.arXiv preprint arXiv:2402.04059, 2024
-
[12]
Mingtian Tan, Mike Merrill, Vinayak Gupta, Tim Althoff, and Tom Hartvigsen. Are language models actually useful for time series forecasting?Advances in Neural Information Processing Systems, 37:60162–60191, 2024
work page 2024
- [13]
-
[14]
Xinlei Wang, Maike Feng, Jing Qiu, Jinjin Gu, and Junhua Zhao. From news to forecast: Integrating event analysis in llm-based time series forecasting with reflection.Advances in Neural Information Processing Systems, 37:58118–58153, 2024. 10
work page 2024
-
[15]
Language models still struggle to zero-shot reason about time series
Mike A Merrill, Mingtian Tan, Vinayak Gupta, Thomas Hartvigsen, and Tim Althoff. Language models still struggle to zero-shot reason about time series. InFindings of EMNLP, 2024
work page 2024
-
[16]
Winnie Chow, Lauren Gardiner, Haraldur T. Hallgrímsson, Maxwell A. Xu, and Shirley You Ren. Towards time series reasoning with llms, 2024
work page 2024
-
[17]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models.arXiv preprint arXiv:2310.01728, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Xinli Yu, Zheng Chen, Yuan Ling, Shujing Dong, Zongyi Liu, and Yanbin Lu. Temporal data meets llm–explainable financial time series forecasting.arXiv preprint arXiv:2306.11025, 2023
-
[19]
Chengsen Wang, Qi Qi, Jingyu Wang, Haifeng Sun, Zirui Zhuang, Jinming Wu, Lei Zhang, and Jianxin Liao. Chattime: A unified multimodal time series foundation model bridging numerical and textual data.AAAI Conference on Artificial Intelligence, 2025
work page 2025
-
[20]
Zhe Xie, Zeyan Li, Xiao He, Longlong Xu, Xidao Wen, Tieying Zhang, Jianjun Chen, Rui Shi, and Dan Pei. Chatts: Aligning time series with llms via synthetic data for enhanced understanding and reasoning.VLDB, 2025
work page 2025
-
[21]
Merrill, Zack Gottesman, Tim Althoff, David Evans, and Tom Hartvigsen
Mingtian Tan, Mike A. Merrill, Zack Gottesman, Tim Althoff, David Evans, and Tom Hartvigsen. Inferring events from time series using language models, 2025
work page 2025
-
[22]
Hao Xue and Flora D Salim. Promptcast: A new prompt-based learning paradigm for time series forecasting.IEEE Transactions on Knowledge and Data Engineering, 36(11):6851–6864, 2023
work page 2023
-
[23]
Timeseriesexam: A time series understanding exam, 2024
Yifu Cai, Arjun Choudhry, Mononito Goswami, and Artur Dubrawski. Timeseriesexam: A time series understanding exam, 2024
work page 2024
-
[24]
Elizabeth Fons, Rachneet Kaur, Soham Palande, Zhen Zeng, Tucker Balch, Manuela Veloso, and Svitlana Vyetrenko. Evaluating large language models on time series feature understanding: A comprehensive taxonomy and benchmark.arXiv preprint arXiv:2404.16563, 2024
-
[25]
Time series language model for descriptive caption generation, 2025
Mohamed Trabelsi, Aidan Boyd, Jin Cao, and Huseyin Uzunalioglu. Time series language model for descriptive caption generation, 2025
work page 2025
-
[26]
Clasp: Learning concepts for time-series signals from natural language supervision, 2025
Aoi Ito, Kota Dohi, and Yohei Kawaguchi. Clasp: Learning concepts for time-series signals from natural language supervision, 2025
work page 2025
-
[27]
Can brain signals reveal inner alignment with human languages?, 2024
William Han, Jielin Qiu, Jiacheng Zhu, Mengdi Xu, Douglas Weber, Bo Li, and Ding Zhao. Can brain signals reveal inner alignment with human languages?, 2024
work page 2024
-
[28]
Carmen Martínez-Cruz, Antonio Rueda, Mihail Popescu, and James Keller. New linguistic description approach for time series and its application to bed restlessness monitoring for eldercare.IEEE Transactions on Fuzzy Systems, PP:1–1, 01 2021
work page 2021
-
[29]
Monwatch: A fuzzy application to monitor the user behavior using wearable trackers
José María Serrano Chica. Monwatch: A fuzzy application to monitor the user behavior using wearable trackers. In2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE). IEEE, 2020
work page 2020
-
[30]
A first approach to the generation of linguistic summaries from glucose sensors using gpt-4
Carmen Martínez-Cruz, Juan Gaitán-Guerrero, José Luis López Ruiz, Antonio Rueda, and Macarena Espinilla. A first approach to the generation of linguistic summaries from glucose sensors using gpt-4. InA First Approach to the Generation of Linguistic Summaries from Glucose Sensors Using GPT-4, pages 33–43, 11 2023
work page 2023
-
[31]
Law, Yvonne Freer, Jim Hunter, Robert H
Andrew S. Law, Yvonne Freer, Jim Hunter, Robert H. Logie, Neil McIntosh, and John Quinn. A comparison of graphical and textual presentations of time series data to support medical decision making in the neonatal intensive care unit.Journal of Clinical Monitoring and Computing, 19(3):183–194, June 2005
work page 2005
-
[32]
Contextual analysis of financial time series.Mathematics, 13(1):57, 2025
Nadezhda Yarushkina, Aleksey Filippov, and Anton Romanov. Contextual analysis of financial time series.Mathematics, 13(1):57, 2025. 11
work page 2025
-
[33]
Truth-conditional captioning of time series data
Harsh Jhamtani and Taylor Berg-Kirkpatrick. Truth-conditional captioning of time series data. InEMNLP, 2021
work page 2021
-
[34]
Yohei Kawaguchi, Kota Dohi, and Aoi Ito. SUSHI: A Dataset of Synthetic Unichannel Signals Based on Heuristic Implementation (Tiny), September 2024
work page 2024
-
[35]
Ecg-qa: A comprehensive question answering dataset combined with electrocardiogram, 2023
Jungwoo Oh, Gyubok Lee, Seongsu Bae, Joon myoung Kwon, and Edward Choi. Ecg-qa: A comprehensive question answering dataset combined with electrocardiogram, 2023
work page 2023
-
[36]
Tianwei Xing, Luis Garcia, Federico Cerutti, Lance M. Kaplan, Alun D. Preece, and Mani B. Srivastava. Deepsqa: Understanding sensor data via question answering. InIoTDI, pages 106–118. ACM, 2021
work page 2021
-
[37]
Pixiu: A large language model, instruction data and evaluation benchmark for finance, 2023
Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. Pixiu: A large language model, instruction data and evaluation benchmark for finance, 2023
work page 2023
-
[38]
Large language models are zero-shot time series forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. Large language models are zero-shot time series forecasters. InNeurIPS, 2023
work page 2023
-
[39]
Large language models for time series: A survey,
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, and Jingbo Shang. Large language models for time series: A survey.ArXiv, abs/2402.01801, 2024
-
[40]
Empowering time series analysis with large language models: A survey
Yushan Jiang, Zijie Pan, Xikun Zhang, Sahil Garg, Anderson Schneider, Yuriy Nevmyvaka, and Dongjin Song. Empowering time series analysis with large language models: A survey. In International Joint Conference on Artificial Intelligence, 2024
work page 2024
-
[41]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021
work page 2021
-
[42]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023
work page 2023
- [43]
-
[44]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Bern...
work page 2024
-
[45]
Google. Gemini 2.0 flash. https://cloud.google.com/vertex-ai/docs/ generative-ai/models/gemini-2-flash, 2025. Accessed: May 15, 2025
work page 2025
-
[46]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page 2024
-
[47]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Qin Cai, Vishrav Chaudhary, Dong Chen, Dongdong Chen, Weizhu Chen, Yen-Chun Chen, Yi-Ling Chen, Hao Cheng, Parul Chopra, Xiyang Dai, Matt...
work page 2024
-
[48]
Qwen2.5-1m technical report, 2025
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, Junyang Lin, Kai Dang, Kexin Yang, Le Yu, Mei Li, Minmin Sun, Qin Zhu, Rui Men, Tao He, Weijia Xu, Wenbiao Yin, Wenyuan Yu, Xiafei Qiu, Xingzhang Ren, Xinlong Yang, Yong Li, Zhiying Xu, and Zipeng Zhang. Qwen2.5-1m technical re...
work page 2025
-
[49]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page 2025
-
[50]
A first approach to the generation of linguistic summaries from glucose sensors using gpt-4
Carmen Martínez-Cruz, Juan Gaitán-Guerrero, José Luis López Ruiz, Antonio Rueda, and Macarena Espinilla. A first approach to the generation of linguistic summaries from glucose sensors using gpt-4. InProceedings of the 15th International Conference on Ubiquitous Computing & Ambient Intelligence (UCAmI 2023), volume 842 ofLecture Notes in Networks and Syst...
work page 2023
-
[51]
tasksource: A large collection of NLP tasks with a structured dataset prepro- cessing framework
Damien Sileo. tasksource: A large collection of NLP tasks with a structured dataset prepro- cessing framework. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors,Proceedings of the 2024 Joint International Con- ference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING...
work page 2024
-
[52]
Chain-of-thought prompting elicits reasoning in large language models, 2023
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023
work page 2023
-
[53]
a value is neared by the flow through exponential decay
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. 15 Appendix A Dataset Description 1 3 5 7 9 11 Time Step 0 5 10 15 Value ID: AD_240 mostly lower than starting position it remains mostly flat in the middle. stays steady in the middle 1 3 5 7 9 11 ...
work page 2023
-
[54]
Review the annotation:{description}
-
[55]
Analyze the time series:{series}
-
[56]
Respond withTrueif the annotation accurately describes the time series
Determine if the annotation precisely matches the pattern depicted in the time series. Respond withTrueif the annotation accurately describes the time series. Respond withFalseif it does not. Avoid providing any additional comments or explanations. Task 2: Differentiation. Carefully analyze the given time series and choose the single best option that most...
-
[57]
Read all options before deciding
-
[58]
Only output the chosen option, highlighted as A, B, C, or D
-
[59]
Avoid adding extra text or explanations. 17 Time series:{series} Options: • A:{option_1} • B:{option_2} • C:{option_3} • D:{option_4} Task 3: Open Generation. You are tasked with generating a textual description of the visual properties of the provided time series. Please follow these instructions carefully:
-
[60]
Analyze the given time series data:{series}
-
[61]
Identify and describe the most prominent visual features or patterns observed in the time series. Consider characteristics such as trends, seasonality, anomalies, or significant changes. Your response should be a concise textual description of the most pronounced visual properties of the time series. Avoid including unnecessary details or unrelated commen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.