Why Johnny Can't Use Agents: Industry Aspirations vs. User Realities with AI Agents
Pith reviewed 2026-05-18 16:52 UTC · model grok-4.3
The pith
Commercial AI agents fall short in practice because their capabilities do not match user mental models and they lack skills for effective collaboration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
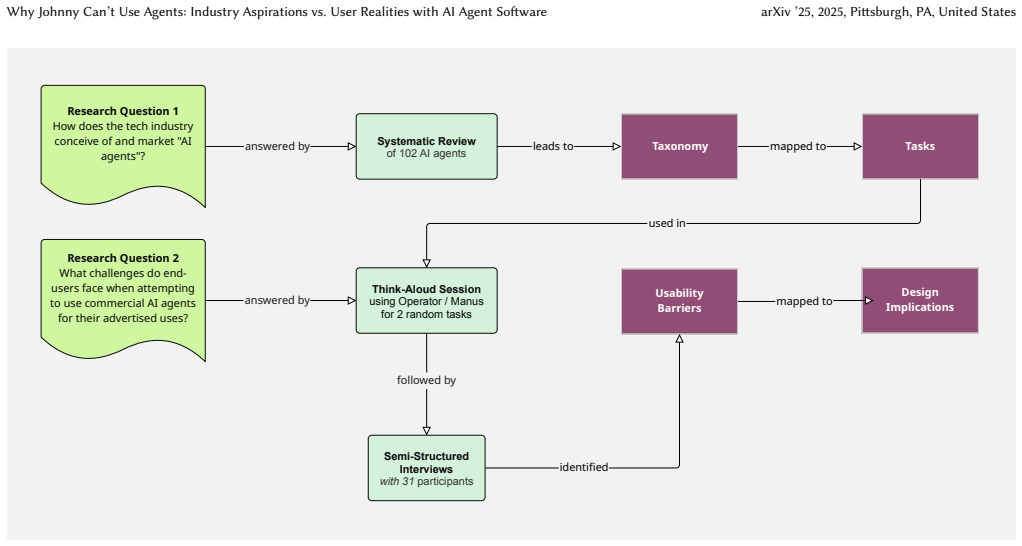
After mapping marketed capabilities across 102 agents into orchestration, creation, and insight categories, testing on two tools found that users generally liked the agents but encountered significant usability problems. These included agent actions that conflicted with users' mental models of how the tools should operate and a lack of meta-cognitive abilities required for productive human-agent teamwork.
What carries the argument
The gap between three umbrella categories of marketed AI agent uses and the concrete difficulties users encountered when performing representative tasks in each category during usability assessments.
If this is right
- Designers need to make agent behavior more predictable so it matches how users already think about task delegation.
- Agents require built-in ways to reflect on their progress and communicate uncertainties during ongoing work.
- Marketed promises for agents in orchestration, creation, and insight should be tempered until these collaboration gaps close.
- Everyday adoption of agents for professional or personal tasks will remain limited until the observed usability barriers are addressed.
Where Pith is reading between the lines
- The same mental-model and meta-cognition shortfalls may appear in other human-AI systems beyond the two tools studied.
- Future agent releases could be evaluated against explicit checklists for mental-model alignment before launch.
- If these issues persist, organizations may need to invest in user training or hybrid human oversight rather than full agent autonomy.
Load-bearing premise
The chosen tasks and the two tested agents accurately stand in for the full range of marketed capabilities and for typical end-user experiences across commercial AI agents.
What would settle it
A follow-up study with more participants, a wider set of agents, and success rates above 80 percent on similar marketed tasks without the reported mental-model or collaboration problems would undermine the central claim.
Figures









read the original abstract
There is growing imprecision about what "AI agents" are, what they can do, and how effectively they can be used by their intended users. We pose two key research questions: (i) How does the tech industry conceive and market "AI agents"? (ii) What challenges do end-users face when attempting to use commercial AI agents for their advertised uses? We first performed a systematic review of marketed use cases for 102 commercial AI agents, finding that they fall into three umbrella categories: orchestration, creation, and insight. We then evaluated whether end-users could realize these marketed capabilities in practice: we conducted a usability assessment where N = 31 participants attempted representative tasks for each of these categories on two popular commercial AI agent tools: Operator and Manus. We found that users were generally impressed with these agents but faced significant usability challenges ranging from agent capabilities that were misaligned with user mental models to agents lacking the meta-cognitive abilities necessary for effective collaboration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic review of 102 commercial AI agents and classifies their marketed use cases into three umbrella categories (orchestration, creation, and insight). It then reports a usability study in which N=31 participants attempted representative tasks from these categories on two commercial tools (Operator and Manus), concluding that users are generally impressed but encounter significant challenges including misalignment between agent capabilities and user mental models as well as insufficient meta-cognitive abilities for effective collaboration.
Significance. If the empirical findings hold after methodological clarification, the work offers a useful empirical contrast between industry marketing claims and observed user difficulties, which could inform agent design and evaluation practices. The broad review of 102 agents provides a reasonable foundation for identifying categories, but the strength of the central claim rests on the usability component.
major comments (3)
- [Usability assessment (methods)] The description of the usability assessment provides no information on participant recruitment, task operationalization for each category, data analysis methods, or bias controls. Without these details it is not possible to assess whether the reported challenges are reliably supported by the observations.
- [Task selection and category coverage] No explicit mapping is given between the most frequent marketed capabilities identified in the review of 102 agents and the specific representative tasks selected for Operator and Manus. This gap prevents the observed usability issues from being taken as evidence about the advertised capabilities across the three categories.
- [Generalization from the usability study] The study evaluates only two tools. The manuscript does not demonstrate that Operator and Manus are representative of the broader set of 102 agents or of commercial AI agents in general, which limits the scope of the claim about 'end-user realities with AI agents'.
minor comments (1)
- [Abstract] The abstract states that a 'systematic review' was performed but does not summarize the search strategy, inclusion criteria, or coding process used to arrive at the 102 agents and three categories.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below, indicating the revisions we plan to make to improve the clarity and rigor of our work.
read point-by-point responses
-
Referee: The description of the usability assessment provides no information on participant recruitment, task operationalization for each category, data analysis methods, or bias controls. Without these details it is not possible to assess whether the reported challenges are reliably supported by the observations.
Authors: We agree that the current description of the usability assessment lacks sufficient methodological detail. In the revised version of the manuscript, we will substantially expand this section to include comprehensive information on participant recruitment (including the recruitment platform, screening criteria, and sample demographics), the operationalization of tasks for each of the three categories with specific examples, the data analysis methods employed (including both quantitative measures and qualitative thematic analysis), and the steps taken to mitigate potential biases such as counterbalancing task order and ensuring inter-coder reliability. These additions will enable readers to better evaluate the robustness of our findings. revision: yes
-
Referee: No explicit mapping is given between the most frequent marketed capabilities identified in the review of 102 agents and the specific representative tasks selected for Operator and Manus. This gap prevents the observed usability issues from being taken as evidence about the advertised capabilities across the three categories.
Authors: We appreciate this observation and will address it by adding an explicit mapping in the revised manuscript. We will include a new table or detailed description that connects the most prevalent capabilities identified in our systematic review of 102 agents to the representative tasks used in the usability study for Operator and Manus. This will clarify how the selected tasks reflect the marketed use cases in the orchestration, creation, and insight categories, thereby strengthening the link between the review and the empirical evaluation. revision: yes
-
Referee: The study evaluates only two tools. The manuscript does not demonstrate that Operator and Manus are representative of the broader set of 102 agents or of commercial AI agents in general, which limits the scope of the claim about 'end-user realities with AI agents'.
Authors: We acknowledge the limitation inherent in evaluating only two specific tools. In the revised manuscript, we will more explicitly discuss this in the limitations and future work sections, qualifying our claims to reflect that the study provides insights from two prominent commercial agents rather than a comprehensive sample of all 102 reviewed agents. We selected Operator and Manus as they are widely recognized and actively marketed examples that span the identified categories, but we will avoid overgeneralizing and instead frame the findings as indicative of current challenges in the field. We believe this approach maintains the value of the contrast between industry aspirations and user realities while being transparent about scope. revision: partial
Circularity Check
No circularity: empirical review and usability study with independent observations
full rationale
The paper performs a systematic review of 102 commercial AI agents to derive three umbrella categories and then conducts a usability assessment with N=31 participants on two tools. No mathematical derivations, fitted parameters, predictions, or self-citations are used as load-bearing steps. All claims rest on direct participant data and observed behaviors rather than any reduction to inputs by construction, self-definition, or prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Established usability assessment methods from HCI literature are suitable for evaluating commercial AI agent tools.
Reference graph
Works this paper leans on
- [1]
-
[2]
2025. Cleo AI. https://web.meetcleo.com/. Accessed: 2025-09-11
work page 2025
- [3]
-
[4]
Expedia Trip Matching AI Agent
2025. Expedia Trip Matching AI Agent. https://www.marketingdive.com/news/ expedia-brings-generative-ai-trip-planning-tool-to-instagram/748233/. Ac- cessed: 2025-09-12
work page 2025
-
[5]
2025. Gamma Presentation Builder. https://gamma.app/. Accessed: 2025-09-12
work page 2025
- [6]
- [7]
-
[8]
https://lovable.dev/ Accessed: 2025-09-01
2025.Lovable. https://lovable.dev/ Accessed: 2025-09-01
work page 2025
- [9]
-
[10]
2025. Salesforce Agentforce. https://www.salesforce.com/agentforce/. Accessed: 2025-09-12
work page 2025
-
[11]
Eytan Adar. 2018. Bounced Checks at the UI/AI Intersection. InHuman-Computer Interaction Consortium Workshop (HCIC’18)
work page 2018
-
[12]
2024.Introducing Perplexity Deep Research
Perplexity AI. 2024.Introducing Perplexity Deep Research. https://www.perplexity. ai/hub/blog/introducing-perplexity-deep-research Accessed: 2025-09-02
work page 2024
-
[13]
AI Agents Directory. 2025. AI Agent Marketplace & Directory | Find Top AI Agents & AI Agent Solutions. https://aiagentsdirectory.com/ Accessed: 2025-09- 01
work page 2025
-
[14]
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N. Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz. 2019. Guidelines for Human- AI Interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk)(CHI ’19). Associa...
-
[15]
Gagan Bansal, Besmira Nushi, Ece Kamar, Walter S. Lasecki, Daniel S. Weld, and Eric Horvitz. 2019. Beyond Accuracy: The Role of Mental Models in Human-AI arXiv ’25, 2025, Pittsburgh, PA, United States Shome et al. Team Performance.Proceedings of the AAAI Conference on Human Computation and Crowdsourcing7, 1 (Oct. 2019), 2–11. doi:10.1609/hcomp.v7i1.5285
- [16]
-
[17]
Beam.ai. 2025. Budget Generation | AI Agents & Agentic Workflows. https: //beam.ai/workflows/budget-generation Accessed: 2025-09-12
work page 2025
-
[18]
Fabio Bellifemine, Agostino Poggi, and Giovanni Rimassa. 2000. Developing multi-agent systems with JADE. InInternational workshop on agent theories, architectures, and languages. Springer, 89–103
work page 2000
-
[19]
B. S. Bloom, M. B. Engelhart, E. J. Furst, W. H. Hill, and D. R. Krathwohl. 1956.Tax- onomy of educational objectives. The classification of educational goals. Handbook 1: Cognitive domain. Longmans Green, New York
work page 1956
-
[20]
John Brooke et al. 1996. SUS-A quick and dirty usability scale.Usability evaluation in industry189, 194 (1996), 4–7
work page 1996
-
[21]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[22]
Vannevar Bush et al. 1945. As We May Think.The Atlantic monthly176, 1 (1945), 101–108
work page 1945
-
[23]
Hongru Cai, Yongqi Li, Wenjie Wang, Fengbin Zhu, Xiaoyu Shen, Wenjie Li, and Tat-Seng Chua. 2025. Large Language Models Empowered Personalized Web Agents. InProceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machinery, New York, NY, USA, 198–215. doi:10.1145/3696410.3714842
-
[24]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning
work page 2024
-
[25]
Microsoft Corporation. 1996.Microsoft FrontPage. https://en.wikipedia.org/wiki/ Microsoft_FrontPage Web authoring software
work page 1996
-
[26]
Justin Cranshaw, Emad Elwany, Todd Newman, Rafal Kocielnik, Bowen Yu, Sandeep Soni, Jaime Teevan, and Andrés Monroy-Hernández. 2017. Calendar.help: Designing a Workflow-Based Scheduling Agent with Humans in the Loop. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems. ACM, Denver, CO, USA, 2382–2393. doi:10.1145/3025453.3025780
-
[27]
Halbert, David Kurlander, Henry Lieberman, David Maulsby, Brad A
Allen Cypher, Daniel C. Halbert, David Kurlander, Henry Lieberman, David Maulsby, Brad A. Myers, and Alan Turransky (Eds.). 1993.Watch what I do: programming by demonstration. MIT Press, Cambridge, MA, USA
work page 1993
-
[28]
F. S. de Boer, K. V. Hindriks, W. van der Hoek, and J. J. Ch. Meyer. 2002. Agent Programming with Declarative Goals. arXiv:cs/0207008 [cs.AI] https://arxiv.org/ abs/cs/0207008
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[29]
Finale Doshi-Velez and Been Kim. 2017. Towards A Rigorous Science of Inter- pretable Machine Learning. arXiv:1702.08608 [stat.ML] https://arxiv.org/abs/ 1702.08608
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. 2024. WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? arXiv:2403.07718 [cs.LG] https://arxiv.org/abs/2403.07718
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Alpana Dubey, Kumar Abhinav, Sakshi Jain, Veenu Arora, and Asha Puttaveer- ana. 2020. HACO: A Framework for Developing Human-AI Teaming. In13th Innovations in Software Engineering Conference (ISEC 2020). ACM, Jabalpur, India, 1–9. doi:10.1145/3385032.3385044
-
[32]
Upol Ehsan, Philipp Wintersberger, Q Vera Liao, Elizabeth Anne Watkins, Carina Manger, Hal Daumé III, Andreas Riener, and Mark O Riedl. 2022. Human-Centered Explainable AI (HCXAI): beyond opening the black-box of AI. InCHI conference on human factors in computing systems extended abstracts. 1–7
work page 2022
-
[33]
Dylan Freedman. 2025. The Day ChatGPT Went Cold.The New York Times (2025). https://www.nytimes.com/2025/08/19/business/chatgpt-gpt-5-backlash- openai.html Accessed: 2025-09-04
work page 2025
-
[34]
Gould, John Conti, and Todd Hovanyecz
John D. Gould, John Conti, and Todd Hovanyecz. 1983. Composing letters with a simulated listening typewriter.Commun. ACM26, 4 (April 1983), 295–308. doi:10.1145/2163.358100
-
[35]
Ryan Hoover. 2013. Product Hunt. https://www.producthunt.com/. Accessed: 2025-09-01
work page 2013
- [36]
-
[37]
Xueyu Hu, Tao Xiong, Biao Yi, Zishu Wei, Ruixuan Xiao, Yurun Chen, Jiasheng Ye, Meiling Tao, Xiangxin Zhou, Ziyu Zhao, Yuhuai Li, Shengze Xu, Shenzhi Wang, Xinchen Xu, Shuofei Qiao, Zhaokai Wang, Kun Kuang, Tieyong Zeng, Liang Wang, Jiwei Li, Yuchen Eleanor Jiang, Wangchunshu Zhou, Guoyin Wang, Keting Yin, Zhou Zhao, Hongxia Yang, Fan Wu, Shengyu Zhang, a...
-
[38]
arXiv:2508.04482 [cs.AI] https://arxiv.org/abs/2508.04482
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use. arXiv:2508.04482 [cs.AI] https://arxiv.org/abs/2508.04482
-
[39]
Edwin L. Hutchins, James D. Hollan, and Donald A. Norman. 1985. Direct Manipulation Interfaces. InUser Centered System Design: New Perspectives on Human-Computer Interaction, Donald A. Norman and Stephen W. Draper (Eds.). Lawrence Erlbaum Associates, Hillsdale, NJ, 87–124
work page 1985
-
[40]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Siegel, Nitya Nadgir, and Arvind Narayanan
Sayash Kapoor, Benedikt Stroebl, Zachary S. Siegel, Nitya Nadgir, and Arvind Narayanan. 2024. AI Agents That Matter. arXiv:2407.01502 [cs.LG] https: //arxiv.org/abs/2407.01502
-
[42]
Garry Kasparov. 2010. The Chess Master and the Computer.The New York Review of Books(2010). https://www.nybooks.com/articles/2010/02/11/the-chess- master-and-the-computer/
work page 2010
-
[43]
Harmanpreet Kaur, Alex C. Williams, and Walter S. Lasecki. 2019. Building Shared Mental Models between Humans and AI for Effective Collaboration. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland). Association for Computing Machinery. doi:10.1145/3290605. 3300643
-
[44]
Pranav Khadpe, Ranjay Krishna, Li Fei-Fei, Jeffrey T. Hancock, and Michael S. Bernstein. 2020. Conceptual Metaphors Impact Perceptions of Human-AI Collab- oration.Proc. ACM Hum.-Comput. Interact.4, CSCW2, Article 163 (Oct. 2020), 26 pages. doi:10.1145/3415234
-
[45]
Sunnie S. Y. Kim, Q. Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. 2024. "I’m Not Sure, But... ": Examining the Im- pact of Large Language Models’ Uncertainty Expression on User Reliance and Trust. InProceedings of the 7th ACM Conference on Fairness, Accountability, and Transparency (FAccT 2024)
work page 2024
-
[46]
Andrew J. Ko, Brad A. Myers, and Htet Htet Aung. 2004. Six Learning Barriers in End-User Programming Systems. InProceedings of the 2004 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). 199–206. doi:10. 1109/VLHCC.2004.47
work page 2004
-
[47]
Hui Li, Jiasheng Zhang, and Kun Huang. 2025. Meta-Analyzing the Trust- Performance Link in Collaboration: Moderating Effects of Conceptual and Con- textual Factors.Public Performance & Management Review48, 1 (2025), 1–34. arXiv:https://doi.org/10.1080/15309576.2024.2405839 doi:10.1080/15309576.2024. 2405839
- [48]
-
[49]
J. C. R. Licklider. 1960. Man-Computer Symbiosis.IRE Transactions on Human Factors in ElectronicsHFE-1, 1 (1960), 4–11. doi:10.1109/THFE2.1960.4503259
-
[50]
Henry Lieberman. 1997. Autonomous Interface Agents. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’97). ACM, Atlanta, Georgia, USA, 67–74. doi:10.1145/258549.258592
-
[51]
Henry Lieberman and Ted Selker. 1999. Agents for the User Interface. InProceed- ings of the ACM Conference on Human Factors in Computing Systems (CHI). Media Laboratory, Massachusetts Institute of Technology. https://web.media.mit.edu/ ~lieber/Publications/Agents_for_UI.pdf
work page 1999
-
[52]
Deloitte Consulting LLP. 2025. AWS Marketplace: Care Finder Agent. https://aws. amazon.com/marketplace/pp/prodview-mau5avpo5xog6. https://aws.amazon. com/marketplace/pp/prodview-mau5avpo5xog6 Product listing for Care Finder Agent, an AI-powered healthcare navigation solution by Deloitte
work page 2025
-
[53]
Pattie Maes. 1994. Agents that reduce work and information overload.Commun. ACM37, 7 (July 1994), 30–40. doi:10.1145/176789.176792
-
[54]
Manus AI. 2025. Manus: General AI agent that bridges mind and action. https: //manus.im/?index=1. Accessed: 2025-09-02
work page 2025
-
[55]
David Maulsby, Saul Greenberg, and Richard Mander. 1993. Prototyping an intelligent agent through Wizard of Oz. InProceedings of the INTERACT’93 and CHI’93 Conference on Human Factors in Computing Systems. 277–284
work page 1993
-
[56]
Merritt, Kian Boon Tan, Christopher Ong, Aswin Thomas, Teong Leong Chuah, and Kevin McGee
Tim R. Merritt, Kian Boon Tan, Christopher Ong, Aswin Thomas, Teong Leong Chuah, and Kevin McGee. 2011. Are artificial team-mates scapegoats in com- puter games. InProceedings of the ACM 2011 Conference on Computer Supported Cooperative Work(Hangzhou, China)(CSCW ’11). Association for Computing Machinery, New York, NY, USA, 685–688. doi:10.1145/1958824.1958945
-
[57]
Tim Miller. 2019. Explanation in artificial intelligence: Insights from the social sciences.Artificial Intelligence267 (2019), 1–38. doi:10.1016/j.artint.2018.07.007
-
[58]
2023.Spotify Debuts a New AI DJ, Right in Your Pocket
Spotify Newsroom. 2023.Spotify Debuts a New AI DJ, Right in Your Pocket. https://newsroom.spotify.com/2023-02-22/spotify-debuts-a-new-ai-dj- right-in-your-pocket/ Accessed: 2025-09-12
work page 2023
-
[59]
Christopher Ong, Kevin McGee, and Teong Leong Chuah. 2012. Closing the human-AI team-mate gap: how changes to displayed information impact player behavior towards computer teammates. InProceedings of the 24th Australian Computer-Human Interaction Conference. 433–439
work page 2012
-
[60]
2025.Introducing ChatGPT agent: bridging research and action
OpenAI. 2025.Introducing ChatGPT agent: bridging research and action. https: //openai.com/index/introducing-chatgpt-agent/ Accessed: 2025-09-02. Why Johnny Can’t Use Agents: Industry Aspirations vs. User Realities with AI Agent Software arXiv ’25, 2025, Pittsburgh, PA, United States
work page 2025
-
[61]
OpenAI. 2025. Introducing Operator | OpenAI. https://openai.com/index/ introducing-operator/. Accessed: 2025-09-02
work page 2025
- [62]
-
[63]
Minjung Park, Jodi Forlizzi, and John Zimmerman. 2025. Exploring the Innovation Opportunities for Pre-trained Models. InProceedings of the 2025 ACM Designing Interactive Systems Conference (DIS ’25). 1973–2005. doi:10.1145/3715336.3735753
-
[64]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Dmitry Dodonov, Tung Nguyen, Jaeho Lee, Daron Anderson, Mikhail Doroshenko, Alun Cennyth Stokes, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al . 2024. Androidworld: A dynamic benchmarking environment for au- tonomous agents.arXiv preprint arXiv:2405.14573(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Matt Renner and Matt A.V. Chaban. 2025.601 real-world gen AI use cases from the world’s leading organizations. https://cloud.google.com/transform/101-real- world-generative-ai-use-cases-from-industry-leaders Published April 12, 2024; last updated April 9, 2025. Google Cloud
work page 2025
- [67]
-
[68]
Devansh Saxena, Ji-Youn Jung, Jodi Forlizzi, Kenneth Holstein, and John Zim- merman. 2025. AI Mismatches: Identifying Potential Algorithmic Harms Before AI Development. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–23. doi:10.1145/3706598.3714098
-
[69]
Ben Shneiderman. 1983. Direct manipulation: A step beyond programming languages.Computer16, 08 (1983), 57–69
work page 1983
-
[70]
On human-centered artificial intelligence
Ben Shneiderman. 2022.Human-centered AI. Oxford University Press
work page 2022
-
[71]
Ben Shneiderman and Pattie Maes. 1997. Direct manipulation vs. interface agents. Interactions4, 6 (Nov. 1997), 42–61. doi:10.1145/267505.267514
-
[72]
Yoav Shoham. 1993. Agent-oriented programming.Artificial Intelligence60, 1 (1993), 51–92. doi:10.1016/0004-3702(93)90034-9
-
[73]
Pradyumna Shome and Miuyin Marie Yong Wong. 2024. "Learning Too Much About Me": A User Study on the Security and Privacy of Generative AI Chatbots. InProceedings of the Twentieth Symposium on Usable Privacy and Security (SOUPS
work page 2024
-
[74]
USENIX Association, Philadelphia, PA, USA
— Poster Session. USENIX Association, Philadelphia, PA, USA. https: //www.usenix.org/conference/soups2024/presentation/shome-poster Poster
-
[75]
Neville A Stanton. 2006. Hierarchical task analysis: Developments, applications, and extensions.Applied ergonomics37, 1 (2006), 55–79
work page 2006
- [76]
-
[77]
Blase Ur, Melwyn Pak Yong Ho, Stephen Brawner, Jiyun Lee, Sarah Mennicken, Noah Picard, Diane Schulze, and Michael L Littman. 2016. Trigger-action pro- gramming in the wild: An analysis of 200,000 ifttt recipes. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems. 3227–3231
work page 2016
-
[78]
Hanna Wallach, Meera Desai, A Feder Cooper, Angelina Wang, Chad Atalla, Solon Barocas, Su Lin Blodgett, Alexandra Chouldechova, Emily Corvi, P Alex Dow, et al. 2025. Position: Evaluating generative ai systems is a social science measurement challenge.arXiv preprint arXiv:2502.00561(2025)
-
[79]
Alma Whitten and J Doug Tygar. 1999. Why Johnny Can’t Encrypt: A Usability Evaluation of PGP 5.0.. InUSENIX Security Symposium, Vol. 348. 169–184
work page 1999
-
[80]
Wikipedia contributors. 2025. Amazon Alexa. https://en.wikipedia.org/wiki/ Amazon_Alexa. Accessed: 2025-09-11
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.