Perceive, Verify and Understand Long Video: Multi-Granular Perception and Active Verification via Interactive Agents
Pith reviewed 2026-05-18 12:36 UTC · model grok-4.3
The pith
CogniGPT uses an interactive loop of perception and verification agents to identify reliable clues in long videos with few frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that long videos pose challenges due to temporal complexity and sparse task-relevant information, and that existing LLM-based methods are limited by task-agnostic fixed-granularity perception and vision-language hallucinations; CogniGPT overcomes this via an interactive loop in which the Multi-Granular Perception Agent adaptively determines optimal perception granularity and strategy based on the evolving context without predetermined heuristics, while the Active Verification Agent actively mines multi-perspective visual evidence to cross-verify key observations and eliminate hallucinations, thereby efficiently identifying a minimal set of reliable task-related clues.
What carries the argument
The interactive loop between the Multi-Granular Perception Agent, which selects perception granularity and strategy adaptively, and the Active Verification Agent, which mines multi-perspective evidence for cross-verification.
If this is right
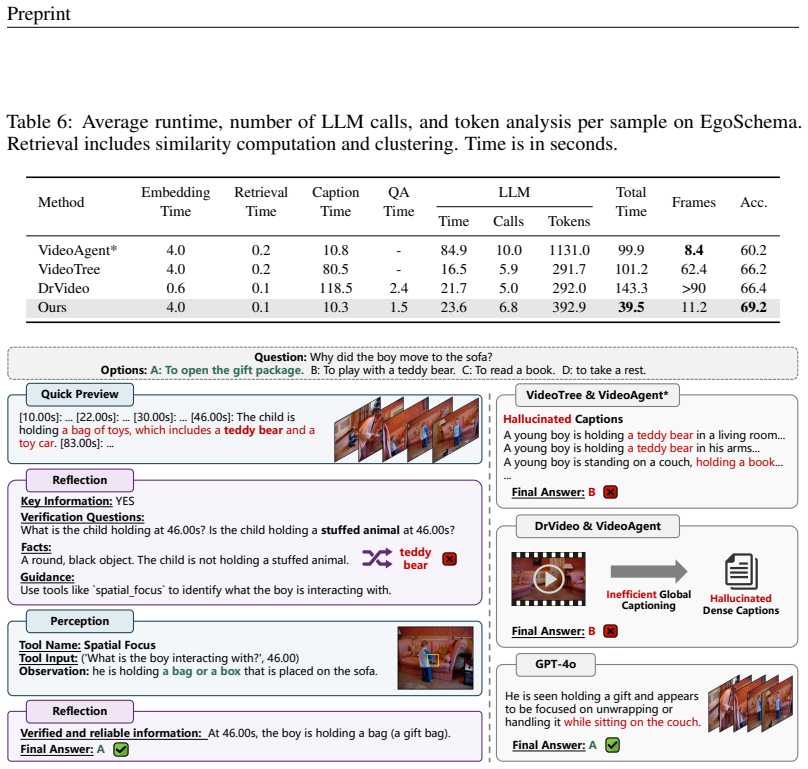
- Surpasses existing training-free methods on EgoSchema while using only 11.2 frames.
- Achieves performance comparable to Gemini 1.5-Pro on EgoSchema.
- Demonstrates improved accuracy and efficiency on Video-MME, NExT-QA, and MovieChat.
- Reduces dependence on fixed-granularity pipelines and associated hallucinations in long video tasks.
Where Pith is reading between the lines
- The same agent loop could be tested on other sparse-data tasks such as long audio or document question answering.
- Scaling the method to videos many times longer than current benchmarks would test whether the minimal-clue selection continues to hold.
- Combining the agents with additional verification sources might further lower error rates in real-world video applications.
Load-bearing premise
The perception agent can correctly pick the right level of video detail from context alone and the verification agent can consistently find evidence that removes mistakes without introducing new ones.
What would settle it
Replacing the adaptive perception and active verification steps with fixed uniform frame sampling and no cross-checking on the EgoSchema benchmark and measuring whether accuracy drops to match or fall below other training-free methods at similar frame counts.
Figures





read the original abstract
Long videos, characterized by temporal complexity and sparse task-relevant information, pose significant reasoning challenges for AI systems. Although existing Large Language Model (LLM)-based approaches have advanced long video understanding, they remain bottlenecked by task-agnostic, fixed-granularity perception pipelines and suffer from vision-language hallucinations. Inspired by human adaptive perception and active verification, we propose CogniGPT, a framework leveraging an interactive loop between a Multi-Granular Perception Agent (MPA) and an Active Verification Agent (AVA). Specifically, instead of predetermined heuristics, MPA adaptively determines the optimal perception granularity and strategy based on the evolving context, while AVA actively mines multi-perspective visual evidence to cross-verify key observations and eliminate hallucinations. This interaction allows CogniGPT to efficiently identify a minimal set of reliable task-related clues. Extensive experiments on EgoSchema, Video-MME, NExT-QA, and MovieChat demonstrate its superiority in accuracy and efficiency. Notably, on EgoSchema, it surpasses existing training-free methods using only 11.2 frames and achieves performance comparable to Gemini 1.5-Pro.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CogniGPT, an interactive agent-based framework for long-video understanding. It consists of a Multi-Granular Perception Agent (MPA) that adaptively selects perception granularity and strategy from evolving context without predetermined heuristics, paired with an Active Verification Agent (AVA) that mines multi-perspective evidence to cross-verify observations and reduce hallucinations. The interaction is claimed to identify a minimal set of reliable task-related clues. Experiments on EgoSchema, Video-MME, NExT-QA, and MovieChat are reported to demonstrate superiority in accuracy and efficiency; notably, on EgoSchema the method surpasses existing training-free baselines using only 11.2 frames while achieving performance comparable to Gemini 1.5-Pro.
Significance. If the adaptive, heuristic-free perception loop and verification mechanism hold up under scrutiny, the work could meaningfully advance efficient long-video reasoning by reducing reliance on fixed-granularity pipelines and mitigating hallucinations, offering a scalable human-inspired alternative for LLM-based video systems.
major comments (2)
- [Abstract] Abstract: The central efficiency claim (surpassing training-free methods on EgoSchema with only 11.2 frames) rests on the assertion that MPA 'adaptively determines the optimal perception granularity and strategy based on the evolving context' rather than 'predetermined heuristics.' The manuscript must demonstrate in the agent implementation (likely §3 or the prompt appendix) that no implicit granularity ladders, decision rules, or fixed sampling strategies are encoded in the system prompt or in-context examples; otherwise the reported frame reduction may be attributable to standard prompting rather than the interactive loop.
- [Experiments] Experiments section: The abstract states benchmark superiority and efficiency gains, yet provides no details on baselines, ablations isolating MPA versus AVA, error analysis, or statistical tests. Without these, it is impossible to confirm that the performance delta is load-bearingly due to the proposed interaction rather than implementation choices or dataset-specific factors.
minor comments (1)
- [Abstract] Abstract: The acronyms MPA and AVA are introduced without a brief parenthetical expansion on first use, which reduces immediate readability for readers scanning the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have carefully considered each major comment and revised the manuscript to strengthen the presentation of our method and experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central efficiency claim (surpassing training-free methods on EgoSchema with only 11.2 frames) rests on the assertion that MPA 'adaptively determines the optimal perception granularity and strategy based on the evolving context' rather than 'predetermined heuristics.' The manuscript must demonstrate in the agent implementation (likely §3 or the prompt appendix) that no implicit granularity ladders, decision rules, or fixed sampling strategies are encoded in the system prompt or in-context examples; otherwise the reported frame reduction may be attributable to standard prompting rather than the interactive loop.
Authors: We thank the referee for this important clarification request. In the revised manuscript we have added the complete system prompts for both the Multi-Granular Perception Agent and the Active Verification Agent to the appendix. These prompts contain only high-level instructions for the LLM to reason over the current task context and accumulated observations; they do not encode any fixed granularity ladders, decision rules, sampling schedules, or in-context examples that prescribe specific perception strategies. The choice of granularity and verification actions is left entirely to the model's contextual reasoning at each step. We believe this addition directly addresses the concern and shows that the reported efficiency stems from the adaptive interaction rather than implicit heuristics. revision: yes
-
Referee: [Experiments] Experiments section: The abstract states benchmark superiority and efficiency gains, yet provides no details on baselines, ablations isolating MPA versus AVA, error analysis, or statistical tests. Without these, it is impossible to confirm that the performance delta is load-bearingly due to the proposed interaction rather than implementation choices or dataset-specific factors.
Authors: We agree that the experimental section would benefit from greater transparency. In the revised version we have expanded the Experiments section with: (i) explicit descriptions and hyper-parameter settings for every baseline, (ii) new ablation tables that isolate the contributions of MPA alone, AVA alone, and the full MPA-AVA loop, (iii) a dedicated error-analysis subsection that categorizes failure cases and illustrates how the verification step reduces hallucinations, and (iv) statistical significance tests (paired t-tests with p-values) on the key performance deltas. These additions provide stronger evidence that the observed gains are attributable to the interactive framework. revision: yes
Circularity Check
No significant circularity; agent design claims remain independent of fitted inputs or self-citation chains
full rationale
The paper presents CogniGPT as an interactive MPA-AVA loop where MPA selects granularity from evolving context and AVA mines evidence. These are architectural choices inspired by human perception, described without equations, parameter fits, or derivations that reduce outputs to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked to force the framework. Empirical results on EgoSchema etc. are benchmark comparisons, not tautological predictions. The framework is self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can serve as reliable bases for perception and verification agents in video tasks
invented entities (2)
-
Multi-Granular Perception Agent (MPA)
no independent evidence
-
Active Verification Agent (AVA)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
interactive loop between Multi-Granular Perception Agent (MGPA) and Verification-Enhanced Reflection Agent (VERA) ... progressively explore minimal yet comprehensive information
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Psychology of learning and motivation
Alan Baddeley. Psychology of learning and motivation. (No Title), 8: 0 47, 1974
work page 1974
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Glance and focus: Memory prompting for multi-event video question answering
Ziyi Bai, Ruiping Wang, and Xilin Chen. Glance and focus: Memory prompting for multi-event video question answering. Advances in Neural Information Processing Systems, 36: 0 34247--34259, 2023
work page 2023
-
[4]
Control of goal-directed and stimulus-driven attention in the brain
Maurizio Corbetta and Gordon L Shulman. Control of goal-directed and stimulus-driven attention in the brain. Nature reviews neuroscience, 3 0 (3): 0 201--215, 2002
work page 2002
-
[5]
Neural mechanisms of selective visual attention
Robert Desimone, John Duncan, et al. Neural mechanisms of selective visual attention. Annual review of neuroscience, 18 0 (1): 0 193--222, 1995
work page 1995
-
[6]
Chain-of-Verification Reduces Hallucination in Large Language Models
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. Chain-of-verification reduces hallucination in large language models. arXiv preprint arXiv:2309.11495, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Videoagent: A memory-augmented multimodal agent for video understanding
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented multimodal agent for video understanding. In European Conference on Computer Vision, pp.\ 75--92. Springer, 2024
work page 2024
-
[8]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13504--13514, 2024
work page 2024
-
[10]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 14281--14290, 2024
work page 2024
-
[11]
Videograph: Recognizing minutes-long human activities in videos
Noureldien Hussein, Efstratios Gavves, and Arnold WM Smeulders. Videograph: Recognizing minutes-long human activities in videos. arXiv preprint arXiv:1905.05143, 2019
-
[12]
Long movie clip classification with state-space video models
Md Mohaiminul Islam and Gedas Bertasius. Long movie clip classification with state-space video models. In European Conference on Computer Vision, pp.\ 87--104. Springer, 2022
work page 2022
-
[13]
Identifying and mitigating vulnerabilities in llm-integrated applications
Fengqing Jiang. Identifying and mitigating vulnerabilities in llm-integrated applications. Master's thesis, University of Washington, 2024
work page 2024
-
[14]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13700--13710, 2024
work page 2024
- [15]
-
[16]
Semi-parametric video-grounded text generation
Sungdong Kim, Jin-Hwa Kim, Jiyoung Lee, and Minjoon Seo. Semi-parametric video-grounded text generation. arXiv preprint arXiv:2301.11507, 2023
-
[17]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024. URL https://llava-vl.github.io/blog/2024-01-30-llava-next/
work page 2024
-
[20]
Vista-llama: Reducing hallucination in video language models via equal distance to visual tokens
Fan Ma, Xiaojie Jin, Heng Wang, Yuchen Xian, Jiashi Feng, and Yi Yang. Vista-llama: Reducing hallucination in video language models via equal distance to visual tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13151--13160, 2024 a
work page 2024
-
[21]
Drvideo: Document retrieval based long video understanding
Ziyu Ma, Chenhui Gou, Hengcan Shi, Bin Sun, Shutao Li, Hamid Rezatofighi, and Jianfei Cai. Drvideo: Document retrieval based long video understanding. arXiv preprint arXiv:2406.12846, 2024 b
-
[22]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Egoschema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems, 36: 0 46212--46244, 2023
work page 2023
-
[24]
Query-dependent video representation for moment retrieval and highlight detection
WonJun Moon, Sangeek Hyun, SangUk Park, Dongchan Park, and Jae-Pil Heo. Query-dependent video representation for moment retrieval and highlight detection. In CVPR, pp.\ 23023--23033, 2023
work page 2023
-
[25]
S4nd: Modeling images and videos as multidimensional signals with state spaces
Eric Nguyen, Karan Goel, Albert Gu, Gordon Downs, Preey Shah, Tri Dao, Stephen Baccus, and Christopher R \'e . S4nd: Modeling images and videos as multidimensional signals with state spaces. Advances in neural information processing systems, 35: 0 2846--2861, 2022
work page 2022
-
[26]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 18221--18232, 2024
work page 2024
-
[27]
Eva-clip-18b: Scaling clip to 18 billion parameters
Quan Sun, Jinsheng Wang, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, and Xinlong Wang. Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252, 2024
-
[28]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Watersheds in digital spaces: an efficient algorithm based on immersion simulations
Luc Vincent and Pierre Soille. Watersheds in digital spaces: an efficient algorithm based on immersion simulations. IEEE Transactions on Pattern Analysis & Machine Intelligence, 13 0 (06): 0 583--598, 1991
work page 1991
-
[31]
Videoagent: Long-form video understanding with large language model as agent
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video understanding with large language model as agent. In European Conference on Computer Vision, pp.\ 58--76. Springer, 2024
work page 2024
-
[32]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xiangyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling. arXiv preprint arXiv:2501.12386, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Lifelongmemory: Leveraging llms for answering queries in long-form egocentric videos
Ying Wang, Yanlai Yang, and Mengye Ren. Lifelongmemory: Leveraging llms for answering queries in long-form egocentric videos. arXiv preprint arXiv:2312.05269, 2023
-
[34]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 3272--3283, 2025 b
work page 2025
-
[35]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 9777--9786, 2021
work page 2021
-
[36]
Zhe Xu, Kun Wei, Xu Yang, and Cheng Deng. Exploiting intrinsic multilateral logical rules for weakly supervised natural language video localization. In ACL, pp.\ 4511--4521, 2024
work page 2024
-
[37]
Zongxin Yang, Guikun Chen, Xiaodi Li, Wenguan Wang, and Yi Yang. Doraemongpt: Toward understanding dynamic scenes with large language models (exemplified as a video agent). arXiv preprint arXiv:2401.08392, 2024
-
[38]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[39]
A simple llm framework for long-range video question-answering
Ce Zhang, Taixi Lu, Md Mohaiminul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, and Gedas Bertasius. A simple llm framework for long-range video question-answering. arXiv preprint arXiv:2312.17235, 2023 a
-
[40]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023 b
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [41]
-
[42]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[43]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[44]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[45]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.