CardioBench: Do Echocardiography Foundation Models Generalize Beyond the Lab?
Pith reviewed 2026-05-21 21:37 UTC · model grok-4.3
The pith
CardioBench shows general-purpose encoders transfer well to echocardiography but struggle with fine-grained view and pathology tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CardioBench unifies eight publicly available echocardiography datasets into a standardized suite of four regression and five classification tasks spanning functional, structural, diagnostic, and view recognition endpoints. Under consistent zero-shot, probing, and alignment protocols, general-purpose encoders transfer well and often close the gap with probing, yet they struggle significantly with fine-grained distinctions like view classification and subtle pathology recognition. Models capturing temporal cardiac dynamics perform best on functional tasks, while retrieval-based approaches generalize more consistently across datasets.
What carries the argument
CardioBench, the unified benchmark of eight public datasets with fixed preprocessing, splits, and evaluation protocols for zero-shot, probing, and alignment testing.
If this is right
- General-purpose encoders become practical starting points for many echocardiography tasks once probed.
- Temporal modeling should be prioritized for functional assessment endpoints.
- Retrieval mechanisms provide a reliable route to consistent performance across varied datasets.
- Future architectural choices for medical imaging models can be guided by the need to handle fine-grained distinctions.
- Releasing the benchmark pipelines enables direct, reproducible comparisons that replace reliance on private data.
Where Pith is reading between the lines
- The pattern suggests that broad pretraining on non-medical video data can supply useful priors even for noisy medical acquisitions.
- Similar standardization efforts could expose generalization limits in other ultrasound or dynamic imaging domains.
- The benchmark could serve as a testbed for probing whether scale alone or specific inductive biases drive the observed task differences.
- Extending the suite with more pathology subtypes would clarify whether current struggles stem from data scarcity or architectural limits.
Load-bearing premise
Standardizing eight diverse public datasets with consistent preprocessing, splits, and evaluation protocols creates a fair, unbiased representation of real-world generalization challenges without introducing harmonization artifacts or losing dataset-specific characteristics.
What would settle it
A new foundation model trained only on private echocardiography data that substantially outperforms every model tested on CardioBench when evaluated under the exact same preprocessing, splits, and protocols would falsify the reported generalization patterns.
Figures










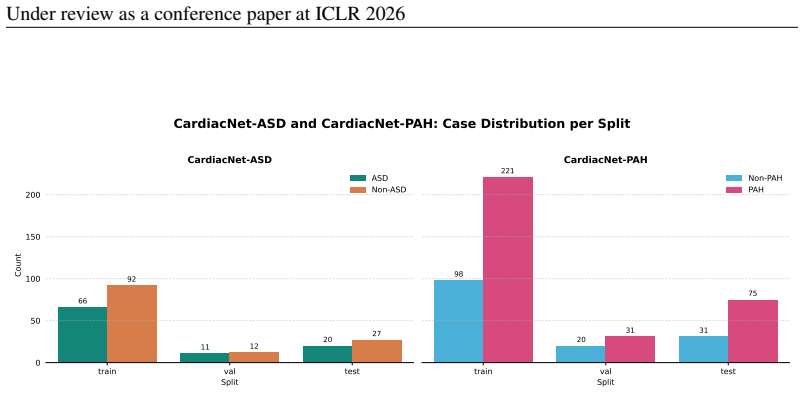

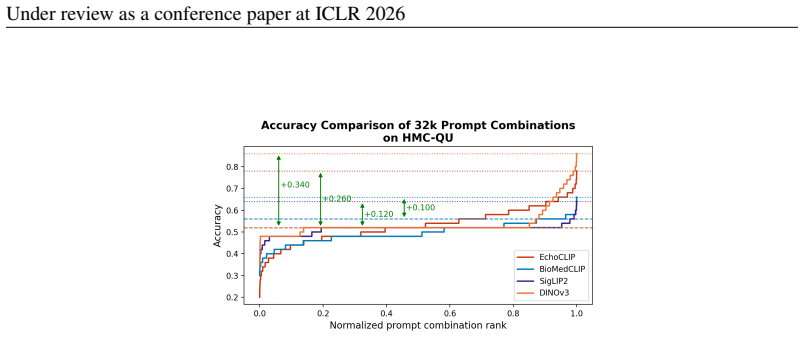




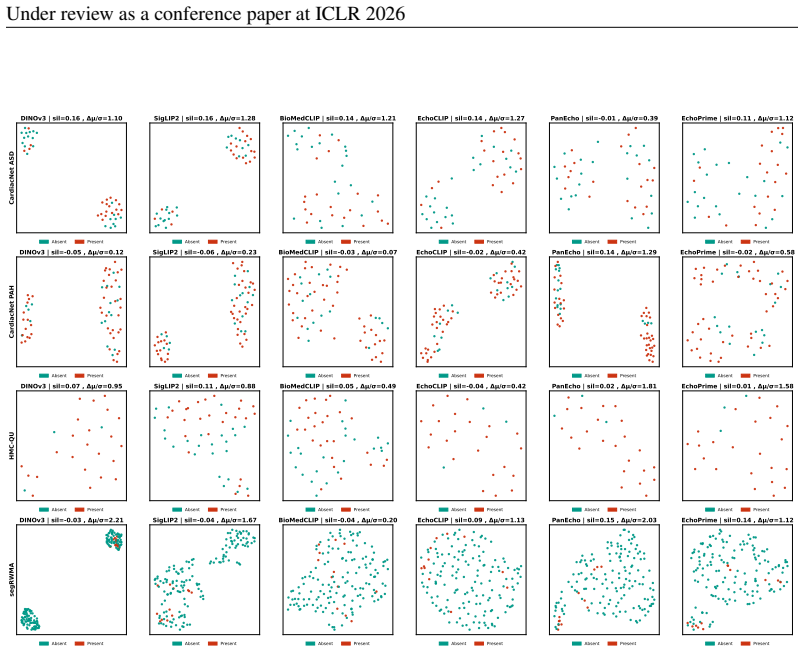



read the original abstract
Foundation models are reshaping medical imaging, yet their application in echocardiography remains limited, hindered by a heavy reliance on private datasets that prevent reproducible comparison. Echocardiography poses unique challenges, including noisy acquisitions, high frame redundancy, and limited diverse public datasets. To address this, we introduce CardioBench, a comprehensive benchmark for echocardiography foundation models. Specifically, CardioBench unifies eight publicly available datasets into a standardized suite spanning four regression and five classification tasks, covering functional, structural, diagnostic, and view recognition endpoints. Leveraging this framework, we evaluate several leading foundation models, including cardiac-specific, biomedical, and general-purpose encoders, under consistent zero-shot, probing, and alignment protocols. Our analysis reveals that while general-purpose encoders transfer well and often close the gap with probing, they struggle significantly with fine-grained distinctions like view classification and subtle pathology recognition. Results indicate that models capturing temporal cardiac dynamics perform best on functional tasks, while retrieval-based approaches generalize more consistently across datasets. By releasing preprocessing, splits, and public evaluation pipelines, CardioBench establishes a reproducible reference point to guide the architectural design of future echocardiography and possibly other medical imaging foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CardioBench, a benchmark that unifies eight publicly available echocardiography datasets into a standardized suite of four regression and five classification tasks covering functional, structural, diagnostic, and view recognition endpoints. It evaluates leading foundation models (cardiac-specific, biomedical, and general-purpose encoders) under consistent zero-shot, probing, and alignment protocols. The central findings are that general-purpose encoders transfer well and often close the gap with probing but struggle with fine-grained distinctions such as view classification and subtle pathology recognition; models capturing temporal cardiac dynamics perform best on functional tasks; and retrieval-based approaches generalize more consistently across datasets. The work releases preprocessing, splits, and public evaluation pipelines to support reproducibility.
Significance. If the reported patterns hold, CardioBench provides a valuable public reference point for comparing echocardiography foundation models and addressing the field's reliance on private data. The explicit release of code, splits, and pipelines is a clear strength that promotes reproducibility and allows others to extend the benchmark. This can meaningfully guide architectural choices for future medical imaging foundation models by highlighting task-specific strengths in transfer and generalization.
major comments (2)
- [§3 (Benchmark Construction and Dataset Unification)] §3 (Benchmark Construction and Dataset Unification): The central claims about generalization, transfer performance, and task-specific model rankings rest on the assumption that standardizing eight heterogeneous datasets via shared preprocessing, splits, and protocols produces an unbiased testbed. No sensitivity analysis, ablation on preprocessing variants, or pre-/post-harmonization statistics (e.g., view distributions or noise profiles) are provided to rule out artifacts that could confound relative model performances or inflate apparent consistency of retrieval methods.
- [Results tables (e.g., Tables 2–4)] Results tables (e.g., Tables 2–4 reporting zero-shot/probing/alignment accuracies): Conclusions that temporal models 'perform best' on functional tasks and retrieval approaches 'generalize more consistently' require supporting statistical tests or error bars on the differences; without them, it is unclear whether observed gaps exceed variability across the eight datasets.
minor comments (2)
- [Abstract] Abstract: Adding one or two quantitative highlights (e.g., specific accuracy or correlation values for the top-performing models on key tasks) would better convey the magnitude of the reported effects.
- [Figure 1 or benchmark overview diagram] Figure 1 or benchmark overview diagram: Include brief examples of acquisition variability across the eight source datasets to illustrate the heterogeneity being standardized.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of benchmark robustness and statistical rigor that we will address to strengthen the presentation of CardioBench. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3 (Benchmark Construction and Dataset Unification)] The central claims about generalization, transfer performance, and task-specific model rankings rest on the assumption that standardizing eight heterogeneous datasets via shared preprocessing, splits, and protocols produces an unbiased testbed. No sensitivity analysis, ablation on preprocessing variants, or pre-/post-harmonization statistics (e.g., view distributions or noise profiles) are provided to rule out artifacts that could confound relative model performances or inflate apparent consistency of retrieval methods.
Authors: We agree that additional validation of the standardization process would increase confidence in the benchmark. The unification follows established practices from prior multi-dataset medical imaging benchmarks, with all models evaluated under identical protocols to enable fair relative comparisons. To directly address the concern, we will add pre- and post-harmonization statistics (view distributions, intensity histograms, and basic noise summaries) to the revised §3. We will also include a limited sensitivity analysis on core preprocessing choices (e.g., resolution and normalization) showing that model rankings remain stable. A full combinatorial ablation of every preprocessing variant is beyond the current scope but can be noted as future work. revision: partial
-
Referee: [Results tables (e.g., Tables 2–4)] Conclusions that temporal models 'perform best' on functional tasks and retrieval approaches 'generalize more consistently' require supporting statistical tests or error bars on the differences; without them, it is unclear whether observed gaps exceed variability across the eight datasets.
Authors: We concur that statistical support is necessary to substantiate the claims. In the revised manuscript we will augment Tables 2–4 with error bars showing standard deviation across the eight datasets. We will additionally report results of paired statistical tests (Wilcoxon signed-rank test) comparing performance differences between model categories, specifically for the temporal-model advantage on functional tasks and the consistency of retrieval-based approaches. These additions will clarify whether the observed gaps are statistically meaningful relative to cross-dataset variability. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential predictions
full rationale
This paper introduces CardioBench as a standardized evaluation suite across eight public echocardiography datasets for zero-shot, probing, and alignment protocols on existing foundation models. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. Results derive directly from model evaluations on unified public data with released code and splits, satisfying the self-contained benchmark criterion. The central claims about model transfer, temporal dynamics, and retrieval generalization rest on these external evaluations rather than any reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CardioBench unifies eight publicly available datasets into a standardized suite spanning four regression and five classification tasks, covering functional, structural, diagnostic, and view recognition endpoints.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Multimodal foundation models for echocardiogram interpretation.arXiv preprint arXiv:2308.15670,
Matthew Christensen, Milos Vukadinovic, Neal Yuan, and David Ouyang. Multimodal foundation models for echocardiogram interpretation.arXiv preprint arXiv:2308.15670,
-
[2]
Gregory Holste, Evangelos K Oikonomou, M ´arton Tokodi, Attila Kov ´acs, Zhangyang Wang, and Rohan Khera. Panecho: Complete ai-enabled echocardiography interpretation with multi-task deep learning.medRxiv, pp. 2024–11,
work page 2024
- [3]
-
[4]
Scaling up visual and vision-language representation learning with noisy text supervision
10 Under review as a conference paper at ICLR 2026 Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pp. 4904–4916. PMLR,
work page 2026
-
[5]
Echofm: Foundation model for generalizable echocardiogram analysis.arXiv preprint arXiv:2410.23413,
Sekeun Kim, Pengfei Jin, Sifan Song, Cheng Chen, Yiwei Li, Hui Ren, Xiang Li, Tianming Liu, and Quanzheng Li. Echofm: Foundation model for generalizable echocardiogram analysis.arXiv preprint arXiv:2410.23413,
-
[6]
Oriane Sim´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Flava: A foundational language and vision alignment model
11 Under review as a conference paper at ICLR 2026 Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Mar- cus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 15638–15650,
work page 2026
-
[8]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdul- mohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Milos Vukadinovic, Xiu Tang, Neal Yuan, Paul Cheng, Debiao Li, Susan Cheng, Bryan He, and David Ouyang. Echoprime: A multi-video view-informed vision-language model for compre- hensive echocardiography interpretation.arXiv preprint arXiv:2410.09704,
-
[10]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Pre- ston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
12 Under review as a conference paper at ICLR 2026 A ABBREVIATIONS EFEjection Fraction IVSdInterventricular Septal Thickness in Diastole LVIDdLeft Ventricular Internal Diameter in Diastole LVPWdLeft Ventricular Posterior Wall Thickness in Diastole A2C, A3C, A4CApical 2-, 3-, and 4-Chamber Views PLAXParasternal Long-Axis View PSAXParasternal Short-Axis Vie...
work page 2026
-
[12]
SegRWMA.The SegRWMA dataset includes 198 patients with regional wall motion annotations, comprising 14 abnormal cases in the A4C view, 13 in the A3C view, and 12 in the A2C view, with the remaining patients considered normal. Segmentation masks are provided for the annotated frames, and we use the first annotated frame index for evaluation. In this study,...
work page 2023
-
[13]
HMC-QU.The HMC-QU dataset contains 332 videos of A4C and A2C views with STEMI labels. Using patient-level labels, we apply a stratified split to maintain the STEMI/non-STEMI ratio across subsets. The dataset is divided into approximately 70.8% for training, 14.2% for validation, and 15% for testing, ensuring that all videos from the same patient remain in...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.