Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention
Pith reviewed 2026-05-18 09:58 UTC · model grok-4.3
The pith
Low-precision Flash Attention training fails because similar low-rank attention representations combine with biased rounding errors to create a self-reinforcing cycle that corrupts weight updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
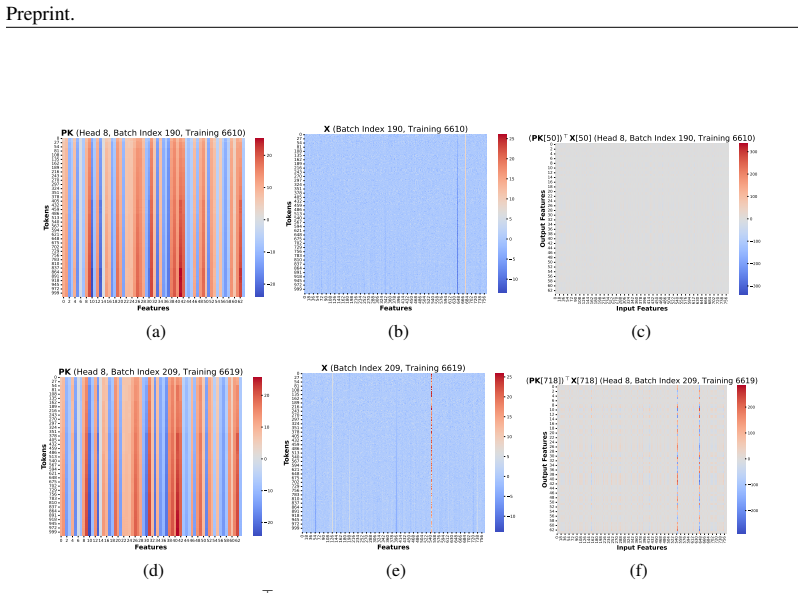
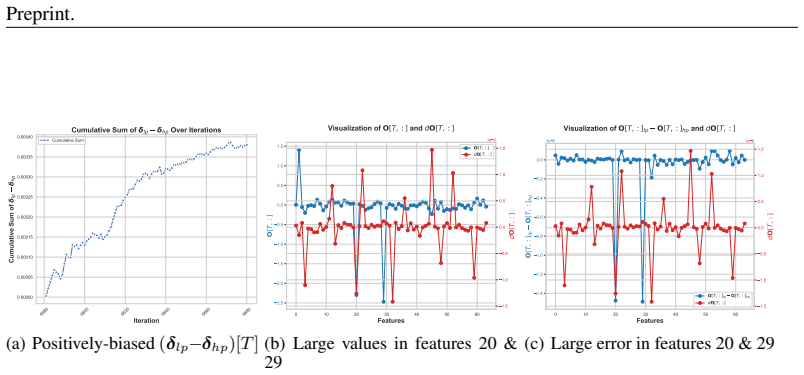
The failure is not a random artifact but caused by two intertwined phenomena: the emergence of similar low-rank representations within the attention mechanism and the compounding effect of biased rounding errors inherent in low-precision arithmetic. These factors create a vicious cycle of error accumulation that corrupts weight updates, ultimately derailing the training dynamics.
What carries the argument
The vicious cycle formed when similar low-rank attention representations meet biased rounding errors in low-precision arithmetic, which then amplifies errors in subsequent weight updates.
If this is right
- A minimal modification to Flash Attention that mitigates rounding bias is sufficient to stabilize low-precision training.
- The same low-rank similarity and rounding bias mechanism explains why instabilities appear specifically with Flash Attention rather than with standard attention.
- Correcting the rounding bias breaks the error-accumulation loop and prevents corruption of weight updates.
- The identified cycle accounts for the catastrophic loss spikes seen in prior low-precision Flash Attention runs.
Where Pith is reading between the lines
- The same bias-accumulation pattern may appear in other fused attention kernels or low-precision linear layers once representations become correlated.
- Hardware vendors could prioritize unbiased rounding modes in low-precision matrix units to reduce the need for software patches.
- Monitoring the rank diversity of attention heads during training could serve as an early warning signal for impending instability.
Load-bearing premise
The observed low-rank similarity and biased rounding errors are the primary and sufficient drivers of the instability rather than symptoms of other unexamined factors in training dynamics or hardware.
What would settle it
Training a transformer with the authors' proposed minimal modification to Flash Attention in the same low-precision setting and checking whether the loss explosion disappears while keeping all other factors fixed.
Figures








read the original abstract
The pursuit of computational efficiency has driven the adoption of low-precision formats for training transformer models. However, this progress is often hindered by notorious training instabilities. This paper provides the first mechanistic explanation for a long-standing and unresolved failure case where training with flash attention in low-precision settings leads to catastrophic loss explosion. Our in-depth analysis reveals that the failure is not a random artifact but caused by two intertwined phenomena: the emergence of similar low-rank representations within the attention mechanism and the compounding effect of biased rounding errors inherent in low-precision arithmetic. We demonstrate how these factors create a vicious cycle of error accumulation that corrupts weight updates, ultimately derailing the training dynamics. To validate our findings, we introduce a minimal modification to the flash attention that mitigates the bias in rounding errors. This simple change stabilizes the training process, confirming our analysis and offering a practical solution to this persistent problem. Code is available at https://github.com/ucker/why-low-precision-training-fails.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide the first mechanistic explanation for catastrophic loss explosion when training transformers with Flash Attention in low-precision arithmetic. It attributes the failure to two intertwined phenomena: the emergence of similar low-rank representations within the attention mechanism and the compounding effect of biased rounding errors in low-precision operations. These factors are said to form a vicious cycle that corrupts weight updates. The authors introduce a minimal modification to Flash Attention that mitigates the rounding bias and report that this change stabilizes training.
Significance. If the causal analysis is substantiated, the work supplies a concrete mechanistic account of a known practical failure mode in efficient transformer training together with a simple, deployable fix. The public code release is a strength that enables direct verification and extension.
major comments (2)
- [§4.2] §4.2 and the associated stabilization experiment: the paper shows that the rounding-bias mitigation restores stable training, yet does not report an intervention that selectively disrupts low-rank similarity in the attention keys/queries while leaving the rounding bias intact (or the converse). Without such a disambiguation, the mutual-reinforcement claim remains correlational rather than demonstrably causal.
- [§3.1] §3.1, the low-rank representation analysis: the reported cosine similarities and singular-value spectra are consistent with collapse, but the manuscript does not quantify the downstream effect on gradient magnitude or provide a bound showing that this similarity is sufficient to drive the observed loss explosion independent of other low-precision matmul dynamics.
minor comments (2)
- [Figure 3] Figure 3: axis labels and color legends are insufficiently descriptive; readers cannot immediately distinguish the low-precision versus high-precision curves without consulting the caption.
- [§2.2] The notation for the online softmax accumulation in FlashAttention (around Eq. (2)) re-uses symbols that were previously defined for the full-precision case; a short clarifying sentence would prevent confusion.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive suggestions. The comments correctly identify opportunities to strengthen the causal interpretation of our results. We address each point below and have revised the manuscript with additional discussion and supporting analysis.
read point-by-point responses
-
Referee: [§4.2] §4.2 and the associated stabilization experiment: the paper shows that the rounding-bias mitigation restores stable training, yet does not report an intervention that selectively disrupts low-rank similarity in the attention keys/queries while leaving the rounding bias intact (or the converse). Without such a disambiguation, the mutual-reinforcement claim remains correlational rather than demonstrably causal.
Authors: We agree that an orthogonal intervention isolating low-rank similarity from rounding bias would provide stronger causal evidence. Designing such an experiment without inadvertently altering rounding behavior or other low-precision dynamics has proven difficult in our setup, as the collapse emerges from the joint training process. Nevertheless, the fact that mitigating rounding bias alone stabilizes training—while low-rank similarity is still observed—indicates that the bias is necessary for the observed explosion. In the revised manuscript we have expanded §4.2 to explicitly characterize the current evidence as supporting a mutual-reinforcement mechanism while acknowledging its correlational character and outlining possible future disambiguation approaches. revision: partial
-
Referee: [§3.1] §3.1, the low-rank representation analysis: the reported cosine similarities and singular-value spectra are consistent with collapse, but the manuscript does not quantify the downstream effect on gradient magnitude or provide a bound showing that this similarity is sufficient to drive the observed loss explosion independent of other low-precision matmul dynamics.
Authors: We accept that explicit quantification of the effect on gradients would strengthen the section. The revised manuscript now includes additional plots in §3.1 that track the relationship between rising key/query cosine similarity and the growth of attention gradient norms across training steps in the unstable low-precision runs. Deriving a tight theoretical bound that isolates representation similarity from the full suite of low-precision matrix-multiplication effects is technically involved and lies outside the scope of the present study; we have added a concise discussion of this limitation together with the empirical support provided by the stabilization experiment. revision: yes
Circularity Check
No significant circularity in the mechanistic analysis
full rationale
The paper presents an empirical mechanistic explanation for training instability in low-precision Flash Attention, identifying low-rank attention representations and biased rounding errors as intertwined causes of a vicious cycle. Validation comes from observing these phenomena and testing a minimal rounding-bias mitigation that stabilizes training. No load-bearing steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the central claim rests on direct observation and intervention rather than renaming or importing uniqueness from prior author work. The derivation is self-contained against external benchmarks of empirical reproduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the compounding effect of biased rounding errors inherent in low-precision arithmetic... vicious cycle of error accumulation that corrupts weight updates
-
IndisputableMonolith/Foundation/ArithmeticFromLogicembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Similar Low-rank Updates of Weight Cause Training Failure... low-rank representations R
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scalify: scale propagation for efficient low-precision llm training.arXiv preprint arXiv:2407.17353,
Paul Balanc ¸a, Sam Hosegood, Carlo Luschi, and Andrew Fitzgibbon. Scalify: scale propagation for efficient low-precision llm training.arXiv preprint arXiv:2407.17353,
-
[2]
u-µp: The unit- scaled maximal update parametrization.arXiv preprint arXiv:2407.17465,
Charlie Blake, Constantin Eichenberg, Josef Dean, Lukas Balles, Luke Y Prince, Bj ¨orn Deiseroth, Andres Felipe Cruz-Salinas, Carlo Luschi, Samuel Weinbach, and Douglas Orr. u-µp: The unit- scaled maximal update parametrization.arXiv preprint arXiv:2407.17465,
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[4]
Scaling fp8 training to trillion- token llms.arXiv preprint arXiv:2409.12517,
Maxim Fishman, Brian Chmiel, Ron Banner, and Daniel Soudry. Scaling fp8 training to trillion- token llms.arXiv preprint arXiv:2409.12517,
-
[5]
Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex
Accessed: 2025-09-07. Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex. Openwebtext corpus.http: //Skylion007.github.io/OpenWebTextCorpus,
work page 2025
-
[6]
10 Preprint. Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, et al. Is flash attention stable?arXiv preprint arXiv:2405.02803,
-
[7]
arXiv preprint arXiv:2505.01043
Zhiwei Hao, Jianyuan Guo, Li Shen, Yong Luo, Han Hu, Guoxia Wang, Dianhai Yu, Yonggang Wen, and Dacheng Tao. Low-precision training of large language models: Methods, challenges, and opportunities.arXiv preprint arXiv:2505.01043,
-
[8]
Query-key normalization for transformers
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normalization for transformers.arXiv preprint arXiv:2010.04245,
-
[9]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Train- ing compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Spam: Spike- aware adam with momentum reset for stable llm training.arXiv preprint arXiv:2501.06842,
Tianjin Huang, Ziquan Zhu, Gaojie Jin, Lu Liu, Zhangyang Wang, and Shiwei Liu. Spam: Spike- aware adam with momentum reset for stable llm training.arXiv preprint arXiv:2501.06842,
-
[11]
A Study of BFLOAT16 for Deep Learning Training
Dhiraj Kalamkar, Dheevatsa Mudigere, Naveen Mellempudi, Dipankar Das, Kunal Banerjee, Sasikanth Avancha, Dharma Teja V ooturi, Nataraj Jammalamadaka, Jianyu Huang, Hector Yuen, et al. A study of bfloat16 for deep learning training.arXiv preprint arXiv:1905.12322,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[12]
Kimi K2: Open Agentic Intelligence
Kimi-Team. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Mixed Precision Training With 8-bit Floating Point
Naveen Mellempudi, Sudarshan Srinivasan, Dipankar Das, and Bharat Kaul. Mixed precision train- ing with 8-bit floating point.arXiv preprint arXiv:1905.12334,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[15]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. Mixed precision training.arXiv preprint arXiv:1710.03740,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisen- thwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, et al. Fp8 formats for deep learning.arXiv preprint arXiv:2209.05433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Igor Molybog, Peter Albert, Moya Chen, Zachary DeVito, David Esiobu, Naman Goyal, Punit Singh Koura, Sharan Narang, Andrew Poulton, Ruan Silva, et al. A theory on adam instability in large- scale machine learning.arXiv preprint arXiv:2304.09871,
- [19]
-
[20]
Badreddine Noune, Philip Jones, Daniel Justus, Dominic Masters, and Carlo Luschi
Ac- cessed: 2025-09-07. Badreddine Noune, Philip Jones, Daniel Justus, Dominic Masters, and Carlo Luschi. 8-bit numerical formats for deep neural networks.arXiv preprint arXiv:2206.02915,
-
[21]
11 Preprint. Houwen Peng, Kan Wu, Yixuan Wei, Guoshuai Zhao, Yuxiang Yang, Ze Liu, Yifan Xiong, Ziyue Yang, Bolin Ni, Jingcheng Hu, et al. Fp8-lm: Training fp8 large language models.arXiv preprint arXiv:2310.18313,
-
[22]
Sergio P Perez, Yan Zhang, James Briggs, Charlie Blake, Josh Levy-Kramer, Paul Balanca, Carlo Luschi, Stephen Barlow, and Andrew William Fitzgibbon. Training and inference of large lan- guage models using 8-bit floating point.arXiv preprint arXiv:2309.17224,
-
[23]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free.arXiv preprint arXiv:2505.06708,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
URLhttps://arxiv.org/abs/2505.09388. Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Methods of improving llm training stability.arXiv preprint arXiv:2410.16682,
Oleg Rybakov, Mike Chrzanowski, Peter Dykas, Jinze Xue, and Ben Lanir. Methods of improving llm training stability.arXiv preprint arXiv:2410.16682,
-
[27]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Training llms with mxfp4.arXiv preprint arXiv:2502.20586,
Albert Tseng, Tao Yu, and Youngsuk Park. Training llms with mxfp4.arXiv preprint arXiv:2502.20586,
-
[29]
Optimizing large language model training using fp4 quantization.arXiv preprint arXiv:2501.17116,
Ruizhe Wang, Yeyun Gong, Xiao Liu, Guoshuai Zhao, Ziyue Yang, Baining Guo, Zhengjun Zha, and Peng Cheng. Optimizing large language model training using fp4 quantization.arXiv preprint arXiv:2501.17116,
work page internal anchor Pith review arXiv
-
[30]
Mitchell Wortsman, Tim Dettmers, Luke Zettlemoyer, Ari S
Accessed: 2025-09-07. Mitchell Wortsman, Tim Dettmers, Luke Zettlemoyer, Ari S. Morcos, Ali Farhadi, and Lud- wig Schmidt. Stable and low-precision training for large-scale vision-language models. In Thirty-seventh Conference on Neural Information Processing Systems,
work page 2025
-
[31]
Efficient Streaming Language Models with Attention Sinks
URLhttps: //openreview.net/forum?id=sqqASmpA2R. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer
Greg Yang, Edward J Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ry- der, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer.arXiv preprint arXiv:2203.03466,
-
[33]
A spectral condition for feature learning
12 Preprint. Greg Yang, James B Simon, and Jeremy Bernstein. A spectral condition for feature learning.arXiv preprint arXiv:2310.17813,
-
[34]
Jiecheng Zhou, Ding Tang, Rong Fu, Boni Hu, Haoran Xu, Yi Wang, Zhilin Pei, Zhongling Su, Liang Liu, Xingcheng Zhang, et al. Towards efficient pre-training: Exploring fp4 precision in large language models.arXiv preprint arXiv:2502.11458,
-
[35]
13 Preprint. A RELATEDWORK A.1 MIXED-PRECISIONBF16 TRAINING. Contemporary large language model (LLM) pretraining almost universally employs mixed-precision arithmetic. Early efforts by Micikevicius et al. (2017) demonstrated that FP16 training—using an FP32 master copy of weights and fixed loss scaling—could match FP32 accuracy for many models. However, t...
work page 2017
-
[36]
Seg en à st 're ich s ho hem S oh ne / Un ser m Kaiser Ferdinand !
is a robust choice, as it ensures the maximum value in the exponent remains sufficiently negative. Algorithm 1Stablized Flash Attention by Mitigating Biased Rounding Error: Forward Pass Require:MatricesQ,K,V∈R N×d , block sizesB c,B r,β >1. 1:DivideQintoT r = l N Br m blocksQ 1, . . . ,QTr of sizeB r ×deach, and divideK,Vin to Tc = l N Bc m blocksK 1, . ....
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.