Code Semantic Zooming
Pith reviewed 2026-05-18 08:40 UTC · model grok-4.3
The pith
CodeZoom uses layered pseudocode to give developers more control over LLM-generated code than natural language prompts allow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Code Semantic Zooming (CodeZoom) is a novel approach based on pseudocode that allows developers to iteratively explore, understand, and refine code across multiple layers of semantic abstraction. In a within-subjects user study (n=26), our method matches a state-of-the-art coding agent, Claude Code, on usability while producing a large effect on code comprehension: over 90% of participants reported feeling more in control of design decisions when using CodeZoom compared to using Claude Code.
What carries the argument
Code Semantic Zooming (CodeZoom): a pseudocode interface for iterative exploration and refinement across multiple semantic abstraction layers in LLM-assisted coding.
If this is right
- Developers can adjust and verify code at chosen abstraction levels instead of relying on a single prompt.
- Code comprehension and sense of design ownership increase while usability remains comparable to current agents.
- Iterative refinement across layers supports building complex systems without full manual rewriting.
Where Pith is reading between the lines
- The layering idea could transfer to other generative AI tasks to give users similar steering ability.
- Integration into mainstream IDEs might change how teams review and accept AI contributions at scale.
- Repeated use could help less experienced programmers learn design patterns through guided abstraction changes.
Load-bearing premise
The within-subjects study with 26 participants isolates the specific effect of the CodeZoom interface from order effects, individual differences, and task variations.
What would settle it
A follow-up study using a between-subjects design or larger sample that finds no difference in perceived control or comprehension between CodeZoom and Claude Code would undermine the reported advantage.
Figures




read the original abstract
Recent advances in Large Language Models (LLMs) have introduced a new paradigm for software development, where source code is generated from natural language prompts. While this paradigm significantly boosts development productivity, building complex, real-world software systems remains challenging because natural language offers limited control over the code generation process. Inspired by the historical evolution of programming languages toward higher levels of abstraction, we advocate for a high-level abstraction language that gives developers greater control over LLM-assisted code writing. To this end, we propose Code Semantic Zooming (CodeZoom), a novel approach based on pseudocode that allows developers to iteratively explore, understand, and refine code across multiple layers of semantic abstraction. In a within-subjects user study (n=26), our method matches a state-of-the-art coding agent, Claude Code, on usability while producing a large effect on code comprehension: over 90% of participants reported feeling more in control of design decisions when using CodeZoom compared to using Claude Code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Code Semantic Zooming (CodeZoom), a multi-layer pseudocode abstraction technique intended to give developers iterative control over LLM-generated code by allowing exploration and refinement across semantic levels. It evaluates the approach via a within-subjects user study (n=26) that compares CodeZoom against the Claude Code agent, claiming equivalent usability but a large positive effect on code comprehension and control, with over 90% of participants reporting greater control over design decisions when using CodeZoom.
Significance. If the user-study results prove robust after addressing methodological gaps, the work would offer a concrete, historically grounded mechanism for increasing developer agency in LLM-assisted coding without usability penalties. This could influence interface design for future coding agents by demonstrating the value of explicit abstraction layers.
major comments (3)
- [User Study] User Study section: the headline result (>90% of participants reporting greater control) is presented without any description of task counterbalancing, order randomization, or statistical test (e.g., exact p-value or effect size) for the binary control item. In a within-subjects design these omissions leave open the possibility that learning, fatigue, or task-order effects fully explain the difference, so the causal attribution to the CodeZoom interface is not yet demonstrated.
- [User Study] User Study section: only subjective Likert-style or binary self-report measures are described; no objective comprehension or performance metrics (code-recall accuracy, successful modification rate, or time-to-correctness) are reported. This weakens the claim of a “large effect on code comprehension.”
- [§3] §3 (System Description): the multi-layer pseudocode abstraction is introduced as the key innovation, yet the manuscript contains no ablation that isolates the contribution of the zooming layers versus the baseline pseudocode representation itself.
minor comments (2)
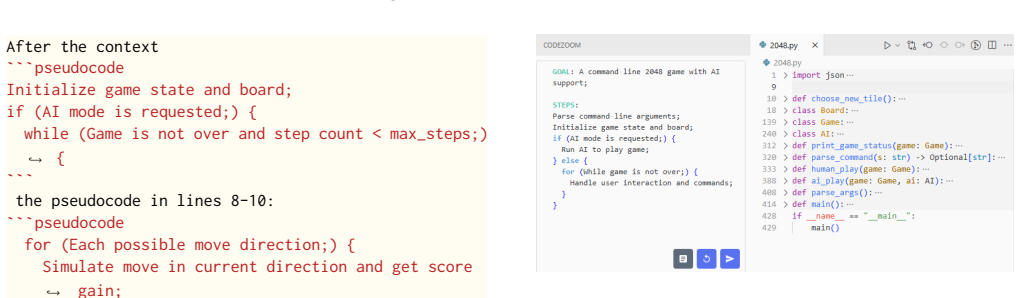
- [Figures] Figure captions for the semantic-zooming examples could be expanded to explicitly label each abstraction layer and the refinement operations performed between them.
- [Related Work] The related-work section would benefit from citing recent empirical studies on LLM coding-agent usability (e.g., those evaluating Copilot or Cursor) to strengthen the positioning of the Claude Code baseline.
Simulated Author's Rebuttal
Thank you for the referee's thoughtful and constructive feedback. We address each major comment below, clarifying our study design where details were omitted and outlining planned revisions to improve methodological transparency and strengthen the evaluation.
read point-by-point responses
-
Referee: [User Study] User Study section: the headline result (>90% of participants reporting greater control) is presented without any description of task counterbalancing, order randomization, or statistical test (e.g., exact p-value or effect size) for the binary control item. In a within-subjects design these omissions leave open the possibility that learning, fatigue, or task-order effects fully explain the difference, so the causal attribution to the CodeZoom interface is not yet demonstrated.
Authors: We agree that explicit reporting of these controls is necessary to support causal claims in a within-subjects design. The study procedure incorporated counterbalancing of task order across conditions and randomization of presentation order to mitigate learning and fatigue effects. We will revise the User Study section to describe these procedures in detail and will report the statistical analysis for the binary control item (including exact p-value and effect size, using an appropriate paired test such as McNemar's test). revision: yes
-
Referee: [User Study] User Study section: only subjective Likert-style or binary self-report measures are described; no objective comprehension or performance metrics (code-recall accuracy, successful modification rate, or time-to-correctness) are reported. This weakens the claim of a “large effect on code comprehension.”
Authors: We recognize that objective metrics would provide additional support for the comprehension claims. While the primary focus was on perceived control and comprehension (standard in HCI evaluations of developer agency), we also recorded task completion times and rates of successful code modifications. In the revision we will report these objective performance measures, including any relevant effect sizes, and integrate them with the subjective results to give a fuller picture of the observed differences. revision: yes
-
Referee: [§3] §3 (System Description): the multi-layer pseudocode abstraction is introduced as the key innovation, yet the manuscript contains no ablation that isolates the contribution of the zooming layers versus the baseline pseudocode representation itself.
Authors: We thank the referee for highlighting the value of isolating the multi-layer zooming component. Our evaluation was designed to compare the full CodeZoom system against a state-of-the-art LLM coding agent (Claude Code) rather than against a single-layer pseudocode baseline. Adding an ablation condition would have required a substantially larger sample and additional experimental arms. We will expand the limitations and future-work sections to explicitly discuss this design decision and outline a planned follow-up study that isolates the contribution of the semantic zooming layers. revision: partial
Circularity Check
No circularity in empirical user study
full rationale
The paper reports results from a within-subjects user study (n=26) comparing CodeZoom to Claude Code on usability and code comprehension metrics. No equations, mathematical derivations, fitted parameters, or predictions are present that could reduce to inputs by construction. Claims rest on participant self-reports and direct comparisons rather than any self-definitional, self-citation load-bearing, or ansatz-smuggling patterns. The study is self-contained as an external empirical evaluation with no internal derivation chain to inspect for circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Within-subjects user studies with n=26 can reliably detect differences in usability and perceived control between interfaces.
invented entities (1)
-
CodeZoom multi-layer pseudocode abstraction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Uzzal Kumar Acharjee, Minhazul Arefin, Kazi Mojammel Hossen, Mo- hammed Nasir Uddin, Md. Ashraf Uddin, and Linta Islam. Sequence-to-sequence learning-based conversion of pseudo-code to source code using neural translation approach.IEEE Access, 10:26730–26742, 2022
work page 2022
-
[2]
Ontology- based automatic code generation from pseudocode
Raed Al-Msie’deen, Mohammad Alshraideh, and Hatem Alsharafat. Ontology- based automatic code generation from pseudocode. InInternational Conference on Interactive Mobile Communication, Technologies and Learning (IMCL), pages 729–738. Springer, 2020
work page 2020
-
[3]
Pseudocode generation from source code using the bart model.Mathematics, 10(21):3967, 2022
Anas Alokla, Walaa Gad, Waleed Nazih, Mustafa Aref, and Abdel-badeeh Salem. Pseudocode generation from source code using the bart model.Mathematics, 10(21):3967, 2022
work page 2022
-
[4]
Retrieval-based transformer pseudocode generation.Mathematics, 10(4):604, 2022
Anas Alokla, Walaa Gad, Waleed Nazih, Mustafa Aref, and Abdel-Badeeh Salem. Retrieval-based transformer pseudocode generation.Mathematics, 10(4):604, 2022
work page 2022
-
[5]
Mohammadmehdi Ataei, Hyunmin Cheong, Daniele Grandi, Ye Wang, Nigel Morris, and Alexander Tessier. Elicitron: A large language model agent-based simulation framework for design requirements elicitation.J. Comput. Inf. Sci. Eng., 25(1), 2025
work page 2025
-
[6]
John W. Backus. The history of fortran i, ii, and III. InHistory of Programming Languages, from the ACM SIGPLAN History of Programming Languages Conference, June 1-3, 1978, Los Angeles, California, USA, pages 25–74, 1978
work page 1978
-
[7]
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D C, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, Balasubramanyan Ashok, and Shashank Shet. Codeplan: Repository-level coding using llms and planning.Proceedings of the ACM on Software Engineering, 1(FSE):675–698, 2024
work page 2024
-
[8]
Shraddha Barke, Michael B. James, and Nadia Polikarpova. Grounded copilot: How programmers interact with code-generating models.Proc. ACM Program. Lang., 7:85–111, 2023
work page 2023
-
[9]
Raymond P. L. Buse and Westley Weimer. Automatic documentation inference for exceptions. InProceedings of the ACM/SIGSOFT International Symposium Code Semantic Zooming Conference’17, July 2017, Washington, DC, USA on Software Testing and Analysis, ISSTA 2008, Seattle, W A, USA, July 20-24, 2008, pages 273–282, 2008
work page 2017
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Ole-Johan Dahl, Edsger Wybe Dijkstra, and Charles Antony Richard Hoare. Structured programming. Academic Press Ltd., 1972
work page 1972
-
[12]
C. J. Date.A Guide to the SQL Standard, Second Edition. 1989
work page 1989
-
[13]
An empirical compari- son of dependency network evolution in seven software packaging ecosystems
Alexandre Decan, Tom Mens, and Philippe Grosjean. An empirical compari- son of dependency network evolution in seven software packaging ecosystems. Empirical Software Engineering, 24(1):381–416, 2019
work page 2019
- [14]
-
[15]
Walaa Gad, Anas Alokla, Waleed Nazih, Mustafa Aref, and Abdel-badeeh Salem. Dlbt: Deep learning-based transformer to generate pseudo-code from source code.Computers, Materials & Continua, 70(2), 2022
work page 2022
-
[16]
BugScope: Learn to Find Bugs Like Human
Jinyao Guo, Chengpeng Wang, Dominic Deluca, Jinjie Liu, Zhuo Zhang, and Xiangyu Zhang. Bugscope: Learn to find bugs like human.CoRR, abs/2507.15671, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Multi-paradigm declarative languages
Michael Hanus. Multi-paradigm declarative languages. InLogic Programming, 23rd International Conference, ICLP 2007, Porto, Portugal, September 8-13, 2007, Proceedings, volume 4670, pages 45–75, 2007
work page 2007
-
[18]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dong Huang, Qingwen Bu, Jie M. Zhang, Michael Luck, and Heming Cui. Agent- coder: Multi-agent-based code generation with iterative testing and optimisation. CoRR, abs/2312.13010, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
work page 2024
-
[20]
Alan C. Kay. The early history of smalltalk. InHistory of Programming Languages Conference (HOPL-II), Preprints, Cambridge, Massachusetts, USA, April 20-23, 1993, pages 69–95, 1993
work page 1993
-
[21]
Majeed Kazemitabaar, Runlong Ye, Xiaoning Wang, Austin Zachary Henley, Paul Denny, Michelle Craig, and Tovi Grossman. Codeaid: Evaluating a classroom deployment of an llm-based programming assistant that balances student and educator needs. InProceedings of the CHI Conference on Human Factors in Com- puting Systems, CHI 2024, Honolulu, HI, USA, May 11-16,...
work page 2024
-
[22]
Literate programming.The computer journal, 27(2):97–111, 1984
Donald Ervin Knuth. Literate programming.The computer journal, 27(2):97–111, 1984
work page 1984
-
[23]
Spoc: Search-based pseudocode to code
Sumith Kulal, Panupong Pasupat, Kartik Chandra, Mina Lee, Oded Padon, Alex Aiken, and Percy Liang. Spoc: Search-based pseudocode to code. InAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Informa- tion Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 11883–11894, 2019
work page 2019
-
[24]
R. Kumar et al. Machine learning for translating pseudocode to python: A comprehensive review. InInternational Conference on Intelligent Computing, Communication and Security (ICICCS), 2023
work page 2023
-
[25]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, Ju...
work page 2020
-
[26]
Large Language Model-Based Agents for Software Engineering: A Survey
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. Large language model-based agents for software engi- neering: A survey.CoRR, abs/2409.02977, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
John W. Lloyd. Practical advtanages of declarative programming. In1994 Joint Conference on Declarative Programming, GULP-PRODE’94 Peñiscola, Spain, Sep- tember 19-22, 1994, Volume 1, pages 18–30, 1994
work page 1994
-
[28]
Specgen: Automated generation of formal program specifications via large language models
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. Specgen: Automated generation of formal program specifications via large language models. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025, pages 16–28, 2025
work page 2025
-
[29]
Laura Moreno, Jairo Aponte, Giriprasad Sridhara, Andrian Marcus, Lori L. Pollock, and K. Vijay-Shanker. Automatic generation of natural language summaries for java classes. InIEEE 21st International Conference on Program Comprehension, ICPC 2013, San Francisco, CA, USA, 20-21 May, 2013, pages 23–32, 2013
work page 2013
-
[30]
Learning to generate pseudo-code from source code using statistical machine translation (T)
Yusuke Oda, Hiroyuki Fudaba, Graham Neubig, Hideaki Hata, Sakriani Sakti, Tomoki Toda, and Satoshi Nakamura. Learning to generate pseudo-code from source code using statistical machine translation (T). In Myra B. Cohen, Lars Grunske, and Michael Whalen, editors,30th IEEE/ACM International Conference on Automated Software Engineering, ASE 2015, Lincoln, NE...
work page 2015
-
[31]
C3po: A lightweight copying mechanism for pseudocode- to-code translation
Authors of C3PO. C3po: A lightweight copying mechanism for pseudocode- to-code translation. InProceedings of the AACL-IJCNLP 2022 Student Research Workshop, 2022
work page 2022
-
[32]
Richard E. Pattis. Teaching EBNF first in CS 1. In Robert Beck and Don Goelman, editors,Proceedings of the 25th SIGCSE Technical Symposium on Computer Science Education, SIGCSE 1994, Phoenix, Arizona, USA, March 10-12, 1994, pages 300–303. ACM, 1994
work page 1994
-
[33]
Object oriented programming.ACM Sigplan Notices, 17(9):51–57, 1982
Tim Rentsch. Object oriented programming.ACM Sigplan Notices, 17(9):51–57, 1982
work page 1982
-
[34]
The c programming language.Bell Sys
Dennis M Ritchie, Stephen C Johnson, ME Lesk, BW Kernighan, et al. The c programming language.Bell Sys. Tech. J, 57(6):1991–2019, 1978
work page 1991
-
[35]
Geoffrey G. Roy. Designing and explaining programs with a literate pseudocode. ACM J. Educ. Resour. Comput., 6:1, 2006
work page 2006
-
[36]
Jean E. Sammet. The early history of COBOL.ACM SIGPLAN Notices, 13:121–161, 1978
work page 1978
-
[37]
Giriprasad Sridhara, Emily Hill, Divya Muppaneni, Lori L. Pollock, and K. Vijay- Shanker. Towards automatically generating summary comments for java methods. InASE 2010, 25th IEEE/ACM International Conference on Automated Software Engineering, Antwerp, Belgium, September 20-24, 2010, pages 43–52, 2010
work page 2010
-
[38]
Giriprasad Sridhara, Lori L. Pollock, and K. Vijay-Shanker. Automatically detect- ing and describing high level actions within methods. InProceedings of the 33rd International Conference on Software Engineering, ICSE 2011, Waikiki, Honolulu , HI, USA, May 21-28, 2011, pages 101–110, 2011
work page 2011
-
[39]
Bjarne Stroustrup. An overview of c++. InProceedings of the 1986 SIGPLAN workshop on Object-oriented programming, pages 7–18, 1986
work page 1986
-
[40]
Nimit Thaker and Abhilash Shukla. Python as multi paradigm programming language.International Journal of Computer Applications, 177(31):38–42, 2020
work page 2020
-
[41]
Website. Claude code. https://www.anthropic.com/claude-code, 2025. Accessed: 2025-09-08
work page 2025
-
[42]
Website. Codex. https://openai.com/codex/, 2025. Accessed: 2025-09-08
work page 2025
-
[43]
Website. Copilot. https://github.com/features/copilot, 2025. Accessed: 2025-09-08
work page 2025
-
[44]
Website. Cursor. https://cursor.com/, 2025. Accessed: 2025-09-08
work page 2025
-
[45]
Website. Gemini cli. https://cloud.google.com/gemini/docs/codeassist/gemini-cli,
-
[46]
Accessed: 2025-09-08
work page 2025
-
[47]
Website. Pseudocode guide for teachers. https://www.cambridgeinternational. org/Images/697401-2026-pseudocode-guide-for-teachers.pdf, 2025. Accessed: 2025-09-08
work page 2026
-
[48]
Website. Vibe coding. https://x.com/karpathy/status/1886192184808149383, 2025. Accessed: 2025-09-08
-
[49]
Fuzz4all: Universal fuzzing with large language models
Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, and Lingming Zhang. Fuzz4all: Universal fuzzing with large language models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024, pages 126:1–126:13, 2024
work page 2024
-
[50]
Kernelgpt: Enhanced kernel fuzzing via large language models
Chenyuan Yang, Zijie Zhao, and Lingming Zhang. Kernelgpt: Enhanced kernel fuzzing via large language models. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS 2025, Rotterdam, Netherlands, 30 March 2025 - 3 April 2025, pages 560–573, 2025
work page 2025
-
[51]
Fine-grained pseudo-code generation method via code feature extraction and transformer
Guang Yang, Yanlin Zhou, Xiang Chen, and Chi Yu. Fine-grained pseudo-code generation method via code feature extraction and transformer. In28th Asia- Pacific Software Engineering Conference, APSEC 2021, Taipei, Taiwan, December 6-9, 2021, pages 213–222, 2021
work page 2021
-
[52]
Master’s thesis, Sudan University of Science and Technology, 2014
Fatima Mohammed Rafie Younis.Automatic Pseudocode to Source Code. Master’s thesis, Sudan University of Science and Technology, 2014
work page 2014
-
[53]
Retrieval-based transformer for pseudocode generation.Mathe- matics, 10(4):604, 2021
Wei Zhang et al. Retrieval-based transformer for pseudocode generation.Mathe- matics, 10(4):604, 2021
work page 2021
-
[54]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2), 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.