Leveraging AV1 motion vectors for Fast and Dense Feature Matching
Pith reviewed 2026-05-18 06:28 UTC · model grok-4.3
pith:Q4PUN72C Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{Q4PUN72C}
Prints a linked pith:Q4PUN72C badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
AV1 motion vectors filtered by cosine consistency produce dense sub-pixel correspondences that match SIFT performance at far lower CPU cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
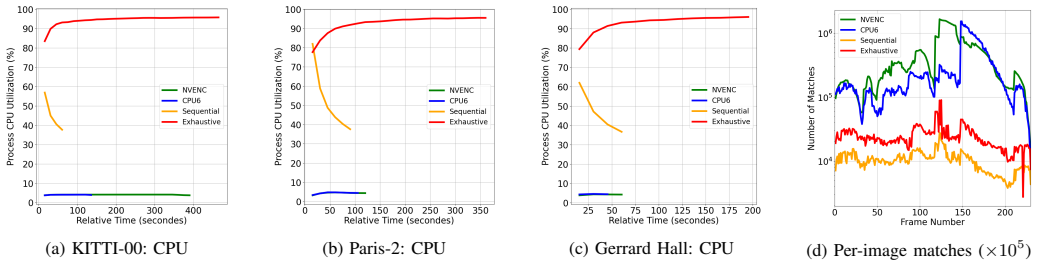
By taking the motion vectors computed during AV1 encoding and retaining only those that satisfy a cosine-consistency test, the method directly produces dense sub-pixel correspondences and short tracks. On short videos this compressed-domain front end runs at speeds comparable to sequential SIFT matching while using far less CPU, delivers denser point sets, and maintains competitive pairwise geometry. In a small SfM demonstration on a 117-frame clip the matches register all images and reconstruct 0.46-0.62 million points at 0.51-0.53 pixel reprojection error, with bundle-adjustment time scaling with match density.
What carries the argument
Cosine-consistency filtering of AV1 motion vectors to select reliable dense sub-pixel correspondences and short tracks.
If this is right
- On short videos the method achieves comparable run-time performance to sequential SIFT while consuming substantially less CPU.
- The matches are denser than those from SIFT yet maintain competitive pairwise geometric accuracy.
- In a small SfM pipeline the matches register every frame and reconstruct 0.46-0.62 million points at 0.51-0.53 px reprojection error.
- Bundle-adjustment runtime increases in proportion to the higher match density produced by the method.
Where Pith is reading between the lines
- The same compressed-domain vectors could be used for real-time tracking on battery-powered or embedded devices that already decode AV1.
- Extending the approach to long sequences would probably need drift-correction steps that preserve the original CPU advantage.
- Embedding this front end inside existing SfM or SLAM systems could shorten the overall preprocessing stage for video-based 3D reconstruction.
Load-bearing premise
Cosine-consistency filtering on AV1 motion vectors alone is enough to produce geometrically reliable correspondences without systematic bias that would require extra outlier-rejection stages.
What would settle it
Running the identical 117-frame SfM reconstruction with standard SIFT matches and measuring whether the AV1-based version produces higher reprojection error or fails to register any images.
Figures


read the original abstract
We repurpose AV1 motion vectors to produce dense sub-pixel correspondences and short tracks filtered by cosine consistency. On short videos, this compressed-domain front end runs comparably to sequential SIFT while using far less CPU, and yields denser matches with competitive pairwise geometry. As a small SfM demo on a 117-frame clip, MV matches register all images and reconstruct 0.46-0.62M points at 0.51-0.53,px reprojection error; BA time grows with match density. These results show compressed-domain correspondences are a practical, resource-efficient front end with clear paths to scaling in full pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes repurposing motion vectors produced by the AV1 video encoder to generate dense sub-pixel correspondences and short tracks for structure-from-motion. These are filtered by a cosine-consistency check. The authors claim that on short videos the approach runs at speeds comparable to sequential SIFT while consuming far less CPU, produces denser matches, and delivers competitive pairwise geometry. A small SfM demonstration on a 117-frame clip is reported to register every image and reconstruct 0.46–0.62 M points at 0.51–0.53 px reprojection error, with bundle-adjustment time scaling with match density.
Significance. If the central claims are substantiated, the work would supply a practical, low-CPU front-end for video-based SfM pipelines by exploiting already-computed compressed-domain data. The reported match density and reprojection error on the 117-frame example are encouraging for dense reconstruction tasks. The method’s reliance on an external encoder output rather than learned or fitted parameters is a methodological strength that aids reproducibility.
major comments (2)
- [Abstract] Abstract: the concrete performance figures (match density, reprojection error, registration success) are given for a 117-frame demo, yet no description is supplied of how the AV1 motion vectors are extracted from the bitstream, how the cosine-consistency filter is formulated or thresholded, or whether any post-hoc selection or outlier rejection was applied. Without these details the reported CPU advantage and geometric reliability cannot be independently verified.
- [Abstract] Abstract and method description: AV1 motion vectors are the output of block-based rate-distortion optimization and are quantized to integer or half-pixel grids. The paper asserts that cosine-consistency filtering alone yields “geometrically reliable correspondences” and “competitive pairwise geometry.” If residual directional bias or block-boundary artifacts remain, an additional robust estimator would be required; such a step would directly contradict the claimed CPU savings relative to SIFT.
minor comments (1)
- [Abstract] Abstract: the string “0.51-0.53,px” contains a typographical error; it should read “0.51-0.53 px”.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the positive assessment of the work's significance for video-based SfM pipelines. We address each major comment below, indicating where revisions have been made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the concrete performance figures (match density, reprojection error, registration success) are given for a 117-frame demo, yet no description is supplied of how the AV1 motion vectors are extracted from the bitstream, how the cosine-consistency filter is formulated or thresholded, or whether any post-hoc selection or outlier rejection was applied. Without these details the reported CPU advantage and geometric reliability cannot be independently verified.
Authors: We agree that the abstract is too concise and omits key methodological details needed for verification. The extraction of motion vectors from the AV1 bitstream and the formulation/thresholding of the cosine-consistency filter are described in the Methods section of the manuscript, and no post-hoc outlier rejection beyond the filter itself was applied. In the revised manuscript we have expanded the abstract with a brief, high-level description of these steps to make the performance claims more self-contained and verifiable. revision: yes
-
Referee: [Abstract] Abstract and method description: AV1 motion vectors are the output of block-based rate-distortion optimization and are quantized to integer or half-pixel grids. The paper asserts that cosine-consistency filtering alone yields “geometrically reliable correspondences” and “competitive pairwise geometry.” If residual directional bias or block-boundary artifacts remain, an additional robust estimator would be required; such a step would directly contradict the claimed CPU savings relative to SIFT.
Authors: We acknowledge that AV1 motion vectors are quantized and arise from block-based optimization, which can introduce directional bias or boundary effects. Nevertheless, our experiments show that the cosine-consistency filter alone produces correspondences supporting low reprojection error and full image registration on the reported clip, without requiring an additional robust estimator. This preserves the claimed CPU advantage. We have added a short discussion paragraph in the revised Methods section that examines residual artifacts and explains why the filter suffices for the targeted short-video use case. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents a method that repurposes external AV1 motion vector outputs from a standard encoder, applies cosine-consistency filtering to generate dense correspondences and short tracks, and validates the output via standard SfM pipelines on a 117-frame clip. No equations, fitted parameters, or self-referential definitions are described that would make match counts, reprojection errors, or geometry claims reduce to the inputs by construction. The central claims rest on independent external data (AV1 encoder) and conventional filtering rather than self-citation chains or ansatz smuggling. Results such as 0.51-0.53 px error emerge from applying the front-end to video data, not from renaming or predicting quantities already embedded in the method definition. This is a self-contained engineering description against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient feature extraction, encoding, and classification for action recognition,
V . Kantorov and I. Laptev, “Efficient feature extraction, encoding, and classification for action recognition,” in2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 2593–2600
work page 2014
-
[2]
Mov-slam: Using motion vectors for real-time single-cpu visual slam,
R. N. Turner, N. K. Banerjee, and S. Banerjee, “Mov-slam: Using motion vectors for real-time single-cpu visual slam,” in2023 Seventh IEEE International Conference on Robotic Computing (IRC), 2023, pp. 51– 58
work page 2023
-
[3]
Adaptive multi-reference prediction using a symmetric framework,
Z. Liu, D. Mukherjee, W.-T. Lin, P. Wilkins, J. Han, and Y . Xu, “Adaptive multi-reference prediction using a symmetric framework,” Electronic Imaging, vol. 2017, no. 2, 2017
work page 2017
-
[4]
Tool description for av1 and libaom,
X. Zhao, S. Liu, A. Grange, and A. Norkin, “Tool description for av1 and libaom,”Alliance for Open Media, Codec Working Group, Document: CWG-B078o, 2021
work page 2021
-
[5]
J. Han, B. Li, D. Mukherjee, C.-H. Chiang, A. Grange, C. Chen, H. Su, S. Parker, S. Deng, U. Joshi, Y . Chen, Y . Wang, P. Wilkins, Y . Xu, and J. Bankoski, “A technical overview of av1,” 2021. [Online]. Available: https://arxiv.org/abs/2008.06091
-
[6]
Sampson, p.d.: Fitting conic sections to “very scattered
P. Sampson, “Sampson, p.d.: Fitting conic sections to “very scattered” data: An iterative refinement of the bookstein algorithm. comput. graphics image process. 18, 97-108,”Computer Graphics and Image Processing, vol. 18, pp. 97–108, 01 1982
work page 1982
-
[7]
Structure-from-motion revisited,
J. L. Sch ¨onberger and J.-M. Frahm, “Structure-from-motion revisited,” inConference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[8]
Are we ready for autonomous driving? the kitti vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” inConference on Computer Vision and Pattern Recognition (CVPR), 2012
work page 2012
-
[9]
Disk: Learning local features with policy gradient,
M. J. Tyszkiewicz, P. Fua, and E. Trulls, “Disk: Learning local features with policy gradient,” 2020. [Online]. Available: https://arxiv.org/abs/2006.13566
-
[10]
LightGlue: Local feature matching at light speed.arXiv preprint arXiv:2306.13643,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “Lightglue: Local feature matching at light speed,” 2023. [Online]. Available: https://arxiv.org/abs/2306.13643
-
[11]
SuperPoint: Self-Supervised Interest Point Detection and Description
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” 2018. [Online]. Available: https://arxiv.org/abs/1712.07629
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Superglue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superglue: Learning feature matching with graph neural networks,” 2020. [Online]. Available: https://arxiv.org/abs/1911.11763
- [13]
-
[14]
“Ffmpeg,” https://ffmpeg.org/
-
[15]
“3rd generation partnership project; technical specification group services and system aspects; 5g video codec characteristics,” https://www.3gpp.org/specifications-technologies/specifications-by- series
-
[16]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” Int. J. Comput. Vision, vol. 60, no. 2, p. 91–110, Nov. 2004. [Online]. Available: https://doi.org/10.1023/B:VISI.0000029664.99615.94
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.