AV-Master: Dual-Path Comprehensive Perception Makes Better Audio-Visual Question Answering
Pith reviewed 2026-05-18 05:23 UTC · model grok-4.3
The pith
AV-Master uses dynamic adaptive sampling and modality preferences to better answer questions about complex audio-visual scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
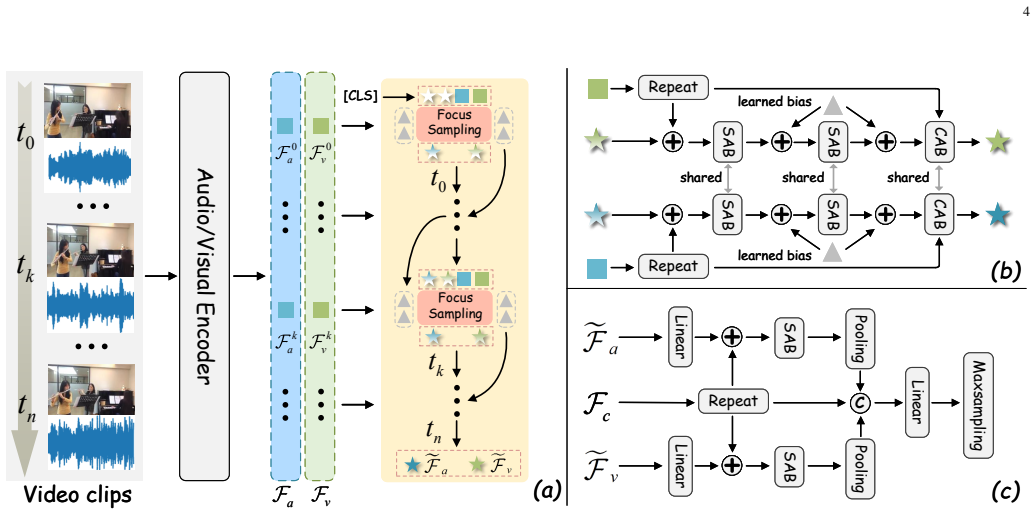
The central claim is that modeling both temporal and modality dimensions dynamically allows AV-Master to extract key information from redundant audio-visual scenes more effectively than prior approaches. The temporal path uses dynamic adaptive focus sampling to progressively select relevant segments. The modality path uses a preference-aware strategy to activate critical features selectively. These are tied together by a dual-path contrastive loss that promotes question-specific cross-modal collaboration. This results in better performance on four large-scale benchmarks, particularly for complex reasoning questions.
What carries the argument
Dual-path framework consisting of dynamic adaptive focus sampling for temporal selection and preference-aware strategy for modality contribution modeling, reinforced by dual-path contrastive loss.
If this is right
- Traditional fixed sampling methods are replaced by progressive focus on question-relevant segments to reduce redundancy.
- Independent modeling of modality contributions enables selective feature activation for better accuracy.
- The dual-path contrastive loss ensures consistency and complementarity in cross-modal representations.
- Overall reasoning capability improves especially on complex questions about audio-visual scenes.
- Outperformance is demonstrated across four large-scale benchmarks.
Where Pith is reading between the lines
- This sampling and preference approach might generalize to other multimodal tasks that involve noisy or redundant inputs.
- Efficient implementation of the focus mechanism could support deployment in resource-constrained environments.
- Combining this perception module with larger reasoning models could further enhance performance on open-ended questions.
Load-bearing premise
The dynamic adaptive focus sampling and preference-aware modality strategy can be trained to reliably identify and prioritize question-relevant information without introducing selection biases or requiring dataset-specific tuning.
What would settle it
Running AV-Master on a new audio-visual benchmark with high redundancy and complex reasoning questions and finding no significant improvement over existing methods would falsify the central claim.
Figures



read the original abstract
Audio-Visual Question Answering (AVQA) requires models to effectively utilize both visual and auditory modalities to answer complex and diverse questions about audio-visual scenes. However, existing methods lack sufficient flexibility and dynamic adaptability in temporal sampling and modality preference awareness, making it difficult to focus on key information based on the question. This limits their reasoning capability in complex scenarios. To address these challenges, we propose a novel framework named AV-Master. It enhances the model's ability to extract key information from complex audio-visual scenes with substantial redundant content by dynamically modeling both temporal and modality dimensions. In the temporal dimension, we introduce a dynamic adaptive focus sampling mechanism that progressively focuses on audio-visual segments most relevant to the question, effectively mitigating redundancy and segment fragmentation in traditional sampling methods. In the modality dimension, we propose a preference-aware strategy that models each modality's contribution independently, enabling selective activation of critical features. Furthermore, we introduce a dual-path contrastive loss to reinforce consistency and complementarity across temporal and modality dimensions, guiding the model to learn question-specific cross-modal collaborative representations. Experiments on four large-scale benchmarks show that AV-Master significantly outperforms existing methods, especially in complex reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AV-Master, a framework for Audio-Visual Question Answering that introduces dynamic adaptive focus sampling to progressively select question-relevant audio-visual segments, a preference-aware modality strategy that models each modality's contribution independently, and a dual-path contrastive loss to enforce consistency and complementarity. Experiments on four large-scale benchmarks are reported to show significant outperformance over prior methods, especially on complex reasoning tasks.
Significance. If the reported gains hold under rigorous validation, the dual-path design could meaningfully advance AVQA by addressing temporal redundancy and modality imbalance in a question-adaptive manner, offering a more flexible alternative to fixed sampling strategies. The emphasis on end-to-end training of the focus policy is a potential strength if accompanied by controls for bias.
major comments (1)
- The central claim that AV-Master yields genuine cross-modal reasoning improvements (rather than artifacts of training-question correlation) depends on the dynamic adaptive focus sampling not collapsing to narrow temporal windows. No section demonstrates stability of the learned policy under shifts in question phrasing, scene complexity, or cross-dataset transfer (e.g., via adversarial rephrasing or held-out distributions), as required to rule out selection bias.
minor comments (2)
- The abstract states performance improvements but provides no quantitative results, error bars, or ablation details; these should be summarized with key numbers and dataset names for immediate clarity.
- Notation for the dual-path contrastive loss and the preference-aware weighting should be defined explicitly with equations in the method section to avoid ambiguity in how modality contributions are computed independently.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on the stability of the dynamic adaptive focus sampling below.
read point-by-point responses
-
Referee: The central claim that AV-Master yields genuine cross-modal reasoning improvements (rather than artifacts of training-question correlation) depends on the dynamic adaptive focus sampling not collapsing to narrow temporal windows. No section demonstrates stability of the learned policy under shifts in question phrasing, scene complexity, or cross-dataset transfer (e.g., via adversarial rephrasing or held-out distributions), as required to rule out selection bias.
Authors: We appreciate the referee highlighting the need to verify that our dynamic adaptive focus sampling does not collapse to narrow temporal windows, which is essential for claiming genuine improvements in cross-modal reasoning. In the manuscript, we present qualitative visualizations of the sampled segments for various questions, showing that the policy selects multiple relevant segments rather than fixed narrow windows, and quantitative ablations demonstrate that removing the adaptive sampling degrades performance on complex tasks. Additionally, the dual-path contrastive loss is designed to promote both consistency and complementarity, discouraging trivial solutions. Nevertheless, we acknowledge that explicit evaluations under adversarial question rephrasing, shifts in scene complexity, or cross-dataset policy transfer are not included. We will incorporate such robustness analyses, including tests on paraphrased questions and held-out distributions, in the revised manuscript to strengthen this aspect. revision: yes
Circularity Check
No significant circularity; new architectural components trained end-to-end on external benchmarks
full rationale
The paper introduces AV-Master as a novel framework with explicitly new mechanisms: dynamic adaptive focus sampling for temporal focus, a preference-aware modality strategy, and a dual-path contrastive loss. These are presented as architectural innovations to mitigate redundancy and improve cross-modal reasoning, trained jointly on four large-scale external benchmarks. Reported gains are empirical performance improvements rather than quantities derived by construction from fitted parameters or prior self-citations. No equations or steps reduce the central claims to tautological inputs; the derivation chain relies on proposed components and standard training, remaining self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dynamic adaptive focus sampling mechanism that progressively focuses on audio-visual segments... dual-path contrastive loss
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on four large-scale benchmarks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Retrieving to Recover: Towards Incomplete Audio-Visual Question Answering via Semantic-consistent Purification
R²ScP recovers missing audio-visual data in question answering by retrieving semantically consistent examples and purifying noise, outperforming generative imputation in incomplete scenarios.
Reference graph
Works this paper leans on
-
[1]
J. Zhang, P. Tang, Y . Tan, and H. Wang, “Mgtr-miss: More ground truth retrieving based multimodal interaction and semantic supervision for video description,”Neural Networks, p. 107817, 2025
work page 2025
-
[2]
P. Tang, J. Zhang, H. Wang, Y . Tan, and Y . Yi, “Srvc-la: Sparse regularization of visual context and latent attention based model for video description,”Neurocomputing, vol. 630, p. 129639, 2025
work page 2025
-
[3]
Svc 2025: the first multimodal deception detection challenge,
X. Lin, X. Guo, T. Wang, Y . Ma, J. Huang, J. Zhang, J. Cao, and Z. Yu, “Svc 2025: the first multimodal deception detection challenge,”arXiv preprint arXiv:2508.04129, 2025
-
[4]
Progressive spatio-temporal perception for audio-visual question answering,
G. Li, W. Hou, and D. Hu, “Progressive spatio-temporal perception for audio-visual question answering,” inProceedings of the 31st ACM international conference on multimedia, pp. 7808–7816, 2023
work page 2023
-
[5]
Boosting audio visual question answering via key semantic-aware cues,
G. Li, H. Du, and D. Hu, “Boosting audio visual question answering via key semantic-aware cues,” inProceedings of the 32nd ACM Inter- national Conference on Multimedia, pp. 5997–6005, 2024
work page 2024
-
[6]
Question-aware gaussian experts for audio-visual question answering,
H. Kim, I. Jung, D. Suh, Y . Zhang, S. Lee, and S. Hong, “Question-aware gaussian experts for audio-visual question answering,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 13681– 13690, 2025
work page 2025
-
[7]
Learning to answer questions in dynamic audio-visual scenarios,
G. Li, Y . Wei, Y . Tian, C. Xu, J.-R. Wen, and D. Hu, “Learning to answer questions in dynamic audio-visual scenarios,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19108–19118, 2022
work page 2022
-
[8]
Audio-visual adaptive fusion network for question answering based on contrastive learning,
X. Zhao, Y . Wang, and P. Jin, “Audio-visual adaptive fusion network for question answering based on contrastive learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, pp. 10483–10491, 2025
work page 2025
-
[9]
M. Risoud, J.-N. Hanson, F. Gauvrit, C. Renard, P.-E. Lemesre, N.-X. Bonne, and C. Vincent, “Sound source localization,”European annals of otorhinolaryngology, head and neck diseases, vol. 135, no. 4, pp. 259– 264, 2018
work page 2018
-
[10]
Music gesture for visual sound separation,
C. Gan, D. Huang, H. Zhao, J. B. Tenenbaum, and A. Torralba, “Music gesture for visual sound separation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10478– 10487, 2020
work page 2020
-
[11]
Visualvoice: Audio-visual speech separation with cross-modal consistency,
R. Gao and K. Grauman, “Visualvoice: Audio-visual speech separation with cross-modal consistency,” in2021 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pp. 15490–15500, IEEE, 2021
work page 2021
-
[12]
Listen to look: Action recognition by previewing audio,
R. Gao, T.-H. Oh, K. Grauman, and L. Torresani, “Listen to look: Action recognition by previewing audio,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10457– 10467, 2020
work page 2020
-
[13]
Multimodal fusion for audio-image and video action recognition,
M. B. Shaikh, D. Chai, S. M. S. Islam, and N. Akhtar, “Multimodal fusion for audio-image and video action recognition,”Neural Computing and Applications, vol. 36, no. 10, pp. 5499–5513, 2024
work page 2024
-
[14]
Audio-visual event localization in unconstrained videos,
Y . Tian, J. Shi, B. Li, Z. Duan, and C. Xu, “Audio-visual event localization in unconstrained videos,” inProceedings of the European conference on computer vision (ECCV), pp. 247–263, 2018
work page 2018
-
[15]
Cross-modal attention network for temporal inconsistent audio-visual event localization,
H. Xuan, Z. Zhang, S. Chen, J. Yang, and Y . Yan, “Cross-modal attention network for temporal inconsistent audio-visual event localization,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 279–286, 2020
work page 2020
-
[16]
Contrastive positive sample propaga- tion along the audio-visual event line,
J. Zhou, D. Guo, and M. Wang, “Contrastive positive sample propaga- tion along the audio-visual event line,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 6, pp. 7239–7257, 2022
work page 2022
-
[17]
Exploring heterogeneous clues for weakly- supervised audio-visual video parsing,
Y . Wu and Y . Yang, “Exploring heterogeneous clues for weakly- supervised audio-visual video parsing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1326– 1335, 2021
work page 2021
-
[18]
Modality-independent teachers meet weakly-supervised audio-visual event parser,
Y .-H. Lai, Y .-C. Chen, and F. Wang, “Modality-independent teachers meet weakly-supervised audio-visual event parser,”Advances in Neural Information Processing systems, vol. 36, pp. 73633–73651, 2023
work page 2023
-
[19]
Label- anticipated event disentanglement for audio-visual video parsing,
J. Zhou, D. Guo, Y . Mao, Y . Zhong, X. Chang, and M. Wang, “Label- anticipated event disentanglement for audio-visual video parsing,” in European Conference on Computer Vision, pp. 35–51, Springer, 2024
work page 2024
-
[20]
Learning to separate object sounds by watching unlabeled video,
R. Gao, R. Feris, and K. Grauman, “Learning to separate object sounds by watching unlabeled video,” inProceedings of the European conference on computer vision (ECCV), pp. 35–53, 2018. 13
work page 2018
-
[21]
Co-separating sounds of visual objects,
R. Gao and K. Grauman, “Co-separating sounds of visual objects,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3879–3888, 2019
work page 2019
-
[22]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, pp. 8748–8763, PmLR, 2021
work page 2021
-
[23]
Cnn architectures for large-scale audio classification,
S. Hershey, S. Chaudhuri, D. P. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold,et al., “Cnn architectures for large-scale audio classification,” in2017 ieee international conference on acoustics, speech and signal processing (icassp), pp. 131–135, IEEE, 2017
work page 2017
-
[24]
Look, listen, and answer: Overcoming biases for audio-visual question answering,
J. Ma, M. Hu, P. Wang, W. Sun, L. Song, H. Pei, J. Liu, and Y . Du, “Look, listen, and answer: Overcoming biases for audio-visual question answering,”arXiv preprint arXiv:2404.12020, 2024
-
[25]
Tackling data bias in music-avqa: Craft- ing a balanced dataset for unbiased question-answering,
X. Liu, Z. Dong, and P. Zhang, “Tackling data bias in music-avqa: Craft- ing a balanced dataset for unbiased question-answering,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 4478–4487, 2024
work page 2024
-
[26]
Avqa: A dataset for audio-visual question answering on videos,
P. Yang, X. Wang, X. Duan, H. Chen, R. Hou, C. Jin, and W. Zhu, “Avqa: A dataset for audio-visual question answering on videos,” in Proceedings of the 30th ACM international conference on multimedia, pp. 3480–3491, 2022
work page 2022
-
[27]
Vggsound: A large- scale audio-visual dataset,
H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “Vggsound: A large- scale audio-visual dataset,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 721–725, IEEE, 2020
work page 2020
-
[28]
Adam: A Method for Stochastic Optimization
D. P. Kingma, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[29]
Guiding audio-visual question answering with collective question reasoning,
B. Pei, Y . Huang, G. Chen, J. Xu, Y . Wang, L. Wang, T. Lu, Y . Qiao, and F. Wu, “Guiding audio-visual question answering with collective question reasoning,”International Journal of Computer Vision, pp. 1– 18, 2025
work page 2025
-
[30]
Shmamba: Structured hyperbolic state space model for audio-visual question answering,
Z. Yang, W. Li, and G. Cheng, “Shmamba: Structured hyperbolic state space model for audio-visual question answering,”IEEE Transactions on Audio, Speech and Language Processing, 2025
work page 2025
-
[31]
Patch- level sounding object tracking for audio-visual question answering,
Z. Li, J. Zhou, J. Zhang, S. Tang, K. Li, and D. Guo, “Patch- level sounding object tracking for audio-visual question answering,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, pp. 5075–5083, 2025
work page 2025
-
[32]
T. Yang, Y . Nan, L. Dai, Z. Liang, Y . Tian, and X. Zhang, “Sasr- net: Source-aware semantic representation network for enhancing audio- visual question answering,” inFindings of the Association for Compu- tational Linguistics: EMNLP 2024, pp. 15894–15904, 2024
work page 2024
-
[33]
Object-aware adaptive- positivity learning for audio-visual question answering,
Z. Li, D. Guo, J. Zhou, J. Zhang, and M. Wang, “Object-aware adaptive- positivity learning for audio-visual question answering,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 3306– 3314, 2024
work page 2024
-
[34]
Answering diverse questions via text attached with key audio-visual clues,
Q. Ye, Z. Yu, and X. Liu, “Answering diverse questions via text attached with key audio-visual clues,”arXiv preprint arXiv:2403.06679, 2024
-
[35]
Question-aware global-local video understanding network for audio-visual question answering,
Z. Chen, L. Wang, P. Wang, and P. Gao, “Question-aware global-local video understanding network for audio-visual question answering,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 5, pp. 4109–4119, 2023
work page 2023
-
[36]
Vision trans- formers are parameter-efficient audio-visual learners,
Y .-B. Lin, Y .-L. Sung, J. Lei, M. Bansal, and G. Bertasius, “Vision trans- formers are parameter-efficient audio-visual learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2299–2309, 2023
work page 2023
-
[37]
Pano-avqa: Grounded audio-visual question answering on 360deg videos,
H. Yun, Y . Yu, W. Yang, K. Lee, and G. Kim, “Pano-avqa: Grounded audio-visual question answering on 360deg videos,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2031– 2041, 2021
work page 2031
-
[38]
Action- centric relation transformer network for video question answering,
J. Zhang, J. Shao, R. Cao, L. Gao, X. Xu, and H. T. Shen, “Action- centric relation transformer network for video question answering,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 1, pp. 63–74, 2020
work page 2020
-
[39]
Reasoning with heterogeneous graph alignment for video question answering,
P. Jiang and Y . Han, “Reasoning with heterogeneous graph alignment for video question answering,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, pp. 11109–11116, 2020
work page 2020
-
[40]
Hierarchical conditional relation networks for video question answering,
T. M. Le, V . Le, S. Venkatesh, and T. Tran, “Hierarchical conditional relation networks for video question answering,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9972–9981, 2020
work page 2020
-
[41]
Temporal reasoning via audio question answering,
H. M. Fayek and J. Johnson, “Temporal reasoning via audio question answering,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2283–2294, 2020
work page 2020
-
[42]
Learnable aggregating net with diversity learning for video question answering,
X. Li, L. Gao, X. Wang, W. Liu, X. Xu, H. T. Shen, and J. Song, “Learnable aggregating net with diversity learning for video question answering,” inProceedings of the 27th ACM international conference on multimedia, pp. 1166–1174, 2019
work page 2019
-
[43]
A simple baseline for audio- visual scene-aware dialog,
I. Schwartz, A. G. Schwing, and T. Hazan, “A simple baseline for audio- visual scene-aware dialog,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12548–12558, 2019
work page 2019
-
[44]
Heterogeneous memory enhanced multimodal attention model for video question answering,
C. Fan, X. Zhang, S. Zhang, W. Wang, C. Zhang, and H. Huang, “Heterogeneous memory enhanced multimodal attention model for video question answering,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1999–2007, 2019
work page 1999
-
[45]
Beyond rnns: Positional self-attention with co-attention for video question answering,
X. Li, J. Song, L. Gao, X. Liu, W. Huang, X. He, and C. Gan, “Beyond rnns: Positional self-attention with co-attention for video question answering,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, pp. 8658–8665, 2019
work page 2019
-
[46]
Deep modular co- attention networks for visual question answering,
Z. Yu, J. Yu, Y . Cui, D. Tao, and Q. Tian, “Deep modular co- attention networks for visual question answering,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6281–6290, 2019
work page 2019
-
[47]
Hierarchical question-image co- attention for visual question answering,
J. Lu, J. Yang, D. Batra, and D. Parikh, “Hierarchical question-image co- attention for visual question answering,”Advances in neural information processing systems, vol. 29, 2016
work page 2016
-
[48]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Z. Cheng, S. Leng, H. Zhang, Y . Xin, X. Li, G. Chen, Y . Zhu, W. Zhang, Z. Luo, D. Zhao, and L. Bing, “Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms,”arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset,
S. Chen, H. Li, Q. Wang, Z. Zhao, M. Sun, X. Zhu, and J. Liu, “Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset,” Advances in Neural Information Processing Systems, vol. 36, pp. 72842– 72866, 2023
work page 2023
-
[50]
Valor: Vision-audio-language omni-perception pretraining model and dataset,
S. Chen, X. He, L. Guo, X. Zhu, W. Wang, J. Tang, and J. Liu, “Valor: Vision-audio-language omni-perception pretraining model and dataset,” arXiv preprint arXiv:2304.08345, 2023
-
[51]
Onellm: One framework to align all modalities with language,
J. Han, K. Gong, Y . Zhang, J. Wang, K. Zhang, D. Lin, Y . Qiao, P. Gao, and X. Yue, “Onellm: One framework to align all modalities with language,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26584–26595, 2024
work page 2024
-
[52]
Chatbridge: Bridging modalities with large language model as a language catalyst,
Z. Zhao, L. Guo, T. Yue, S. Chen, S. Shao, X. Zhu, Z. Yuan, and J. Liu, “Chatbridge: Bridging modalities with large language model as a language catalyst,”arXiv preprint arXiv:2305.16103, 2023
-
[53]
Q. Ye, Z. Yu, R. Shao, X. Xie, P. Torr, and X. Cao, “Cat: Enhancing multimodal large language model to answer questions in dynamic audio- visual scenarios,” inEuropean Conference on Computer Vision, pp. 146– 164, Springer, 2024
work page 2024
-
[54]
Cat+: investigating and enhancing audio-visual understanding in large language models,
Q. Ye, Z. Yu, R. Shao, Y . Cui, X. Kang, X. Liu, P. Torr, and X. Cao, “Cat+: investigating and enhancing audio-visual understanding in large language models,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[55]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
H. Zhang, X. Li, and L. Bing, “Video-llama: An instruction-tuned audio-visual language model for video understanding,”arXiv preprint arXiv:2306.02858, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Audio-visual llm for video understanding,
F. Shu, L. Zhang, H. Jiang, and C. Xie, “Audio-visual llm for video understanding,”arXiv preprint arXiv:2312.06720, 2023
-
[57]
Y . Tang, D. Shimada, J. Bi, and C. Xu, “Avicuna: Audio-visual llm with interleaver and context-boundary alignment for temporal referential dialogue,”arXiv preprint arXiv:2403.16276, vol. 2, 2024
-
[58]
Cad- contextual multi-modal alignment for dynamic avqa,
A. Nadeem, A. Hilton, R. Dawes, G. Thomas, and A. Mustafa, “Cad- contextual multi-modal alignment for dynamic avqa,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 7251–7263, 2024
work page 2024
-
[59]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
work page 2016
-
[60]
Internvideo2: Scaling foundation models for multimodal video understanding,
Y . Wang, K. Li, X. Li, J. Yu, Y . He, G. Chen, B. Pei, R. Zheng, Z. Wang, Y . Shi,et al., “Internvideo2: Scaling foundation models for multimodal video understanding,” inEuropean Conference on Computer Vision, pp. 396–416, Springer, 2024
work page 2024
-
[61]
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, IEEE, 2023
work page 2023
-
[62]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv,et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.