Adversarial Concept Distillation for One-Step Diffusion Personalization
Pith reviewed 2026-05-18 04:46 UTC · model grok-4.3
The pith
Adversarial distillation from multi-step teachers enables reliable personalization of one-step diffusion models for the first time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that one-step diffusion models can be personalized reliably by combining teacher-student consistency losses with adversarial losses that align generated images to real distributions. A multi-step teacher guides the student on content and structure while the adversarial component corrects for distribution shift introduced by the single-step approximation. The resulting student preserves generation speed and, through a subsequent collaborative stage, supplies useful signals that improve the teacher.
What carries the argument
The OPAD joint-training loop in which a one-step student receives both consistency losses from a multi-step teacher and adversarial losses against real images, plus a mutual-improvement stage that feeds student outputs back to the teacher.
If this is right
- Personalized images become available at single-step inference speed without the quality collapse seen in earlier attempts.
- The efficiency advantage of one-step models is retained while personalization quality approaches that of slower multi-step baselines.
- A closed feedback loop between student and teacher yields iterative gains in both models.
- Adversarial alignment proves sufficient to compensate for the information loss that occurs when reducing denoising steps from many to one.
Where Pith is reading between the lines
- The same adversarial-distillation pattern may transfer to other single-step generative architectures such as consistency models or distilled flows.
- Real-time on-device personalization applications become practical once single-step inference is paired with this training recipe.
- The collaborative stage suggests a general route for using fast student models to accelerate improvement of their slower teachers.
Load-bearing premise
Adversarial losses can be balanced so they close the distribution gap between one-step outputs and real images without creating new artifacts or training instability.
What would settle it
A side-by-side evaluation on standard personalization benchmarks in which OPAD produces the same severe artifacts or mode-collapse cases reported for prior one-step methods would falsify the reliability claim.
Figures








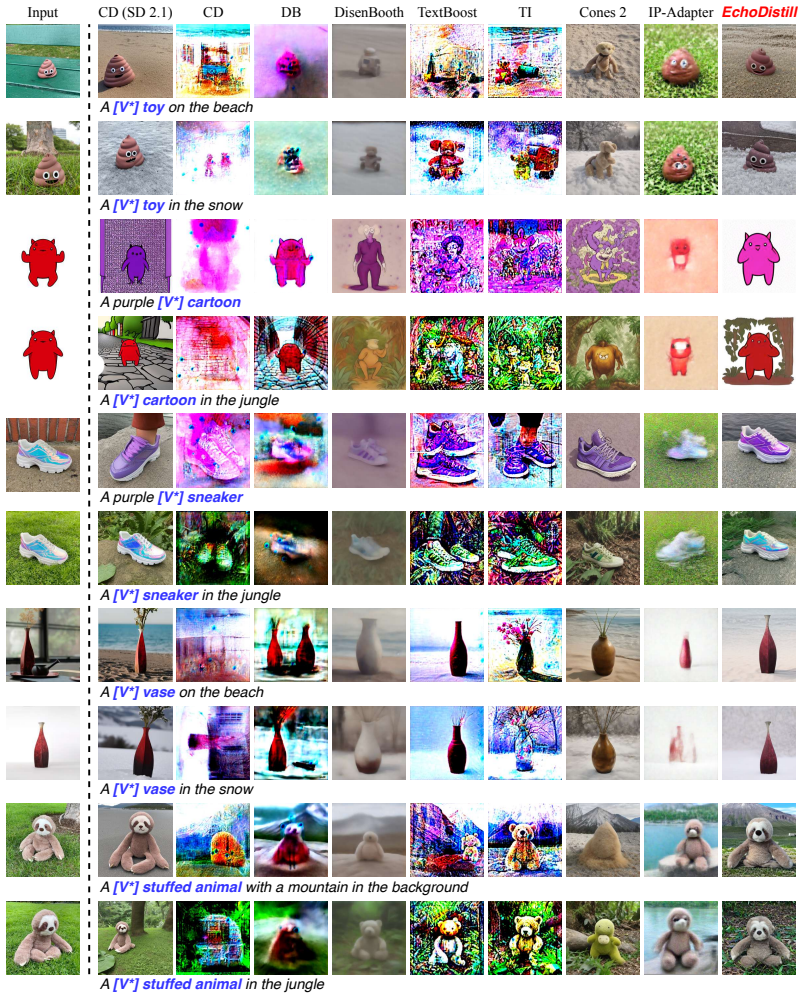



read the original abstract
Recent progress in accelerating text-to-image diffusion models enables high-fidelity synthesis within a single denoising step. However, customizing the fast one-step models remains challenging, as existing methods consistently fail to produce acceptable results, underscoring the need for new methodologies to personalize one-step models. Therefore, we propose One-step Personalized Adversarial Distillation (OPAD), a framework that combines teacher-student distillation with adversarial supervision. A multi-step diffusion model serves as the teacher, while a one-step student model is jointly trained with it. The student learns from alignment losses that preserve consistency with the teacher and from adversarial losses that align its output with real image distributions. Beyond one-step personalization, we further observe that the student's efficient generation and adversarially enriched representations provide valuable feedback to improve the teacher model, forming a collaborative learning stage. Extensive experiments demonstrate that OPAD is the first approach to deliver reliable, high-quality personalization for one-step diffusion models; in contrast, prior methods largely fail and produce severe failure cases, while OPAD preserves single-step efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes One-step Personalized Adversarial Distillation (OPAD), a framework that combines teacher-student distillation with adversarial supervision for personalizing one-step text-to-image diffusion models. A multi-step teacher guides a one-step student via alignment (consistency) losses and adversarial losses that align student outputs with real-image distributions; a subsequent collaborative stage lets the student provide feedback to improve the teacher. The central claim is that OPAD is the first method to achieve reliable high-quality personalization in the one-step regime, where prior approaches produce severe failures, while preserving single-step efficiency.
Significance. If the experimental claims hold, the work addresses a practically important gap: one-step diffusion models offer substantial inference speedups but have resisted personalization. The collaborative feedback loop between student and teacher is a distinctive element that could generalize beyond this setting. The approach builds on established distillation and adversarial techniques but applies them in a new one-step context with an efficiency-preserving feedback mechanism.
major comments (2)
- [Abstract] Abstract and experimental claims: the assertion that 'prior methods largely fail and produce severe failure cases' while OPAD succeeds is load-bearing for the central contribution, yet the provided description supplies no quantitative metrics (FID, CLIP similarity, user-study scores, or ablation tables) or failure-case analysis to support the magnitude of improvement or to isolate the adversarial component's contribution.
- [Method (adversarial and collaborative stages)] Adversarial alignment mechanism: the claim that adversarial losses reliably align the one-step student's output distribution to real images without artifacts or instability rests on the joint training with consistency losses, but the one-step setting lacks the iterative refinement that normally stabilizes such training; concrete details on loss weighting, training dynamics, or safeguards against mode collapse (e.g., in the loss formulation or optimization procedure) are required to substantiate the weakest assumption.
minor comments (2)
- [Training details] Clarify how the balancing weights between alignment and adversarial losses are chosen or scheduled, as they appear among the free parameters.
- [Experiments] Add explicit ablation isolating the collaborative feedback stage to demonstrate its contribution to teacher improvement without compromising student efficiency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental claims: the assertion that 'prior methods largely fail and produce severe failure cases' while OPAD succeeds is load-bearing for the central contribution, yet the provided description supplies no quantitative metrics (FID, CLIP similarity, user-study scores, or ablation tables) or failure-case analysis to support the magnitude of improvement or to isolate the adversarial component's contribution.
Authors: We thank the referee for highlighting this. The full manuscript includes comprehensive quantitative evaluations with FID, CLIP similarity, user-study scores, ablation tables, and failure-case visualizations that support the claims and isolate the adversarial component's contribution. To strengthen the abstract, we will revise it to incorporate key metrics and explicitly reference the relevant experimental sections and figures. revision: yes
-
Referee: [Method (adversarial and collaborative stages)] Adversarial alignment mechanism: the claim that adversarial losses reliably align the one-step student's output distribution to real images without artifacts or instability rests on the joint training with consistency losses, but the one-step setting lacks the iterative refinement that normally stabilizes such training; concrete details on loss weighting, training dynamics, or safeguards against mode collapse (e.g., in the loss formulation or optimization procedure) are required to substantiate the weakest assumption.
Authors: We agree that additional concrete details will improve clarity. In the revised manuscript we will expand the method section to specify the exact loss weighting coefficients, describe the observed training dynamics and convergence behavior, and detail safeguards including the stabilizing role of consistency losses, spectral normalization on the discriminator, gradient penalty terms, and alternating optimization to mitigate mode collapse. These elements are already implemented in our training procedure and contribute to the observed stability. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes OPAD as a framework that combines established teacher-student distillation with adversarial supervision for one-step model personalization. The abstract describes alignment losses preserving consistency with a multi-step teacher and adversarial losses aligning student outputs to real image distributions, plus a collaborative feedback stage. No equations, derivations, or self-referential definitions are shown that would reduce the claimed results or performance to inputs by construction. The central claims rest on empirical experiments rather than tautological reductions or load-bearing self-citations, rendering the method self-contained against external benchmarks in distillation and adversarial training.
Axiom & Free-Parameter Ledger
free parameters (1)
- balancing weights between alignment and adversarial losses
axioms (1)
- domain assumption A multi-step diffusion model can serve as an effective teacher whose outputs provide useful supervision for a one-step student.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Panos Achlioptas, Alexandros Benetatos, Iordanis Fostiropoulos, and Dimitris Skourtis. Stellar: systematic evaluation of human-centric personalized text-to-image methods.arXiv preprint arXiv:2312.06116, 2023
-
[3]
An image is worth multiple words: Multi-attribute inversion for constrained text-to-image synthesis
Aishwarya Agarwal, Srikrishna Karanam, Tripti Shukla, and Balaji Vasan Srinivasan. An image is worth multiple words: Multi-attribute inversion for constrained text-to-image synthesis. International Conference on Machine Learning, 2024
work page 2024
-
[4]
Yuval Alaluf, Elad Richardson, Gal Metzer, and Daniel Cohen-Or. A neural space-time representation for text-to-image personalization.ACM Transactions on Graphics (TOG), 42(6):1–10, 2023
work page 2023
-
[5]
Moab Arar, Rinon Gal, Yuval Atzmon, Gal Chechik, Daniel Cohen-Or, Ariel Shamir, and Amit H. Bermano. Domain-agnostic tuning-encoder for fast personalization of text-to-image models. InSIGGRAPH Asia 2023 Conference Papers, pages 1–10, 2023
work page 2023
-
[6]
Kandinsky 3.0 technical report.arXiv preprint arXiv:2312.03511, 2023
Vladimir Arkhipkin, Andrei Filatov, Viacheslav Vasilev, Anastasia Maltseva, Said Azizov, Igor Pavlov, Julia Agafonova, Andrey Kuznetsov, and Denis Dimitrov. Kandinsky 3.0 technical report.arXiv preprint arXiv:2312.03511, 2023. 10
-
[7]
Break-a- scene: Extracting multiple concepts from a single image.SIGGRAPH Asia 2023, 2023
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen-Or, and Dani Lischinski. Break-a- scene: Extracting multiple concepts from a single image.SIGGRAPH Asia 2023, 2023
work page 2023
-
[8]
Colorpeel: Color prompt learning with diffusion models via color and shape disentanglement
Muhammad Atif Butt, Kai Wang, Javier Vazquez-Corral, and Joost van de Weijer. Colorpeel: Color prompt learning with diffusion models via color and shape disentanglement. InEuropean Conference on Computer Vision, 2024
work page 2024
-
[9]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[10]
Efficient geometry- aware 3d generative adversarial networks
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry- aware 3d generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16123–16133, 2022
work page 2022
-
[11]
Xverse: Consistent multi-subject control of identity and semantic attributes via dit modulation
Bowen Chen, Mengyi Zhao, Haomiao Sun, Li Chen, Xu Wang, Kang Du, and Xinglong Wu. Xverse: Consistent multi-subject control of identity and semantic attributes via dit modulation. arXiv preprint arXiv:2506.21416, 2025
-
[12]
Hong Chen, Yipeng Zhang, Simin Wu, Xin Wang, Xuguang Duan, Yuwei Zhou, and Wenwu Zhu. Disenbooth: Identity-preserving disentangled tuning for subject-driven text-to-image generation.International Conference on Learning Representations, 2024
work page 2024
-
[13]
Subject-driven text-to-image generation via apprenticeship learning
Wenhu Chen, Hexiang Hu, Yandong Li, Nataniel Rui, Xuhui Jia, Ming-Wei Chang, and William W Cohen. Subject-driven text-to-image generation via apprenticeship learning. Advances in Neural Information Processing Systems, 2023
work page 2023
-
[14]
Re-imagen: Retrieval- augmented text-to-image generator
Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W Cohen. Re-imagen: Retrieval- augmented text-to-image generator. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[15]
Jiwoo Chung, Sangeek Hyun, Hyunjun Kim, Eunseo Koh, MinKyu Lee, and Jae-Pil Heo. Fine-tuning visual autoregressive models for subject-driven generation.Proceedings of the International Conference on Computer Vision, 2025
work page 2025
-
[16]
Idadapter: Learning mixed features for tuning-free personalization of text-to-image models
Siying Cui, Jia Guo, Xiang An, Jiankang Deng, Yongle Zhao, Xinyu Wei, and Ziyong Feng. Idadapter: Learning mixed features for tuning-free personalization of text-to-image models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 950–959, 2024
work page 2024
-
[17]
Trung Dao, Thuan Hoang Nguyen, Thanh Le, Duc Vu, Khoi Nguyen, Cuong Pham, and Anh Tran. Swiftbrush v2: Make your one-step diffusion model better than its teacher.European Conference on Computer Vision, 2024
work page 2024
-
[18]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Freecustom: Tuning-free customized image generation for multi-concept composition
Ganggui Ding, Canyu Zhao, Wen Wang, Zhen Yang, Zide Liu, Hao Chen, and Chunhua Shen. Freecustom: Tuning-free customized image generation for multi-concept composition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9089–9098, 2024
work page 2024
-
[20]
Ziyi Dong, Pengxu Wei, and Liang Lin. Dreamartist: Towards controllable one-shot text-to- image generation via contrastive prompt-tuning.arXiv preprint arXiv:2211.11337, 2022
-
[21]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion.International Conference on Learning Representations, 2023
work page 2023
-
[22]
Rinon Gal, Moab Arar, Yuval Atzmon, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. Designing an encoder for fast personalization of text-to-image models.arXiv preprint arXiv:2302.12228, 2023. 11
-
[23]
Lcm-lookahead for encoder-based text-to-image personalization
Rinon Gal, Or Lichter, Elad Richardson, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. Lcm-lookahead for encoder-based text-to-image personalization. In European Conference on Computer Vision, pages 322–340. Springer, 2024
work page 2024
-
[24]
Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Ephrat, Tomer Michaeli, Inbar Mosseri, and Tali Dekel. Tokenverse: Versatile multi-concept personalization in token modulation space.Proceedings of the International Conference on Computer Vision, 2025
work page 2025
-
[25]
Yuchao Gu, Xintao Wang, Jay Zhangjie Wu, Yujun Shi, Yunpeng Chen, Zihan Fan, Wuyou Xiao, Rui Zhao, Shuning Chang, Weijia Wu, et al. Mix-of-show: Decentralized low-rank adap- tation for multi-concept customization of diffusion models.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[26]
Zinan Guo, Yanze Wu, Chen Zhuowei, Peng Zhang, Qian He, et al. Pulid: Pure and lightning id customization via contrastive alignment.Advances in neural information processing systems, 37:36777–36804, 2024
work page 2024
-
[27]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[28]
Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, and Feng Yang. Svdiff: Compact parameter space for diffusion fine-tuning.Proceedings of the International Conference on Computer Vision, 2023
work page 2023
-
[29]
Multiscale sliced wasserstein distances as perceptual color difference measures
Jiaqi He, Zhihua Wang, Leon Wang, Tsein-I Liu, Yuming Fang, Qilin Sun, and Kede Ma. Multiscale sliced wasserstein distances as perceptual color difference measures. InEuropean Conference on Computer Vision, pages 425–442. Springer, 2024
work page 2024
-
[30]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.International Conference on Learning Representations, 2023
work page 2023
-
[31]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
work page 2020
-
[32]
Classdiffusion: More aligned personalization tuning with explicit class guidance
Jiannan Huang, Jun Hao Liew, Hanshu Yan, Yuyang Yin, Yao Zhao, Humphrey Shi, and Yunchao Wei. Classdiffusion: More aligned personalization tuning with explicit class guidance. International Conference on Learning Representations, 2025
work page 2025
- [33]
-
[34]
Qihan Huang, Siming Fu, Jinlong Liu, Hao Jiang, Yipeng Yu, and Jie Song. Resolving multi-condition confusion for finetuning-free personalized image generation.Proceedings of the Conference on Artificial Intelligence, 2025
work page 2025
-
[35]
Xuhui Jia, Yang Zhao, Kelvin CK Chan, Yandong Li, Han Zhang, Boqing Gong, Tingbo Hou, Huisheng Wang, and Yu-Chuan Su. Taming encoder for zero fine-tuning image customization with text-to-image diffusion models.arXiv preprint arXiv:2304.02642, 2023
-
[36]
Liming Jiang, Qing Yan, Yumin Jia, Zichuan Liu, Hao Kang, and Xin Lu. Infiniteyou: Flexible photo recrafting while preserving your identity.Proceedings of the International Conference on Computer Vision, 2025
work page 2025
-
[37]
Omg: Occlusion-friendly personalized multi-concept generation in diffusion models
Zhe Kong, Yong Zhang, Tianyu Yang, Tao Wang, Kaihao Zhang, Bizhu Wu, Guanying Chen, Wei Liu, and Wenhan Luo. Omg: Occlusion-friendly personalized multi-concept generation in diffusion models. InEuropean Conference on Computer Vision, pages 253–270. Springer, 2024
work page 2024
-
[38]
Nupur Kumari, Xi Yin, Jun-Yan Zhu, Ishan Misra, and Samaneh Azadi. Generating multi- image synthetic data for text-to-image customization.arXiv preprint arXiv:2502.01720, 2025. 12
-
[39]
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi- concept customization of text-to-image diffusion.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[40]
Ensembling off-the-shelf models for gan training
Nupur Kumari, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Ensembling off-the-shelf models for gan training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10651–10662, 2022
work page 2022
-
[41]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[42]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models.International Conference on Machine Learning, 2023
work page 2023
-
[43]
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming-Ming Cheng, and Ying Shan. Photomaker: Customizing realistic human photos via stacked id embedding.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[44]
Ziqiang Li, Jun Li, Lizhi Xiong, Zhangjie Fu, and Zechao Li. A comprehensive survey on visual concept mining in text-to-image diffusion models.arXiv preprint arXiv:2503.13576, 2025
-
[45]
Enshu Liu, Xuefei Ning, Yu Wang, and Zinan Lin. Distilled decoding 1: One-step sampling of image auto-regressive models with flow matching.International Conference on Learning Representations, 2025
work page 2025
-
[46]
Cones: Concept neurons in diffusion models for customized generation
Zhiheng Liu, Ruili Feng, Kai Zhu, Yifei Zhang, Kecheng Zheng, Yu Liu, Deli Zhao, Jingren Zhou, and Yang Cao. Cones: Concept neurons in diffusion models for customized generation. International Conference on Machine Learning, 2023
work page 2023
-
[47]
Customizable image synthesis with multiple subjects
Zhiheng Liu, Yifei Zhang, Yujun Shen, Kecheng Zheng, Kai Zhu, Ruili Feng, Yu Liu, Deli Zhao, Jingren Zhou, and Yang Cao. Customizable image synthesis with multiple subjects. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[48]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787, 2022
work page 2022
-
[49]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Lcm-lora: A universal stable-diffusion acceleration module
Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu, Patrick von Platen, Apolinário Passos, Longbo Huang, Jian Li, and Hang Zhao. Lcm-lora: A universal stable-diffusion acceleration module. arXiv preprint arXiv:2311.05556, 2023
-
[51]
Jian Ma, Junhao Liang, Chen Chen, and Haonan Lu. Subject-diffusion: Open domain personalized text-to-image generation without test-time fine-tuning.Proceedings of the ACM SIGGRAPH Conference on Computer Graphics, 2024
work page 2024
-
[52]
Overview of intelligent video coding: from model-based to learning-based approaches
Siwei Ma, Junlong Gao, Ruofan Wang, Jianhui Chang, Qi Mao, Zhimeng Huang, and Chuan- min Jia. Overview of intelligent video coding: from model-based to learning-based approaches. Visual Intelligence, 1(1):15, 2023
work page 2023
-
[53]
Yiyang Ma, Huan Yang, Wenjing Wang, Jianlong Fu, and Jiaying Liu. Unified multi-modal latent diffusion for joint subject and text conditional image generation.arXiv preprint arXiv:2303.09319, 2023
-
[54]
Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models.Proceedings of the Conference on Artificial Intelligence, 2024
work page 2024
-
[55]
Dreamo: A unified framework for image customization.SIGGRAPH Asia, 2025
Chong Mou, Yanze Wu, Wenxu Wu, Zinan Guo, Pengze Zhang, Yufeng Cheng, Yiming Luo, Fei Ding, Shiwen Zhang, Xinghui Li, et al. Dreamo: A unified framework for image customization.SIGGRAPH Asia, 2025. 13
work page 2025
-
[56]
Thuan Hoang Nguyen and Anh Tran. Swiftbrush: One-step text-to-image diffusion model with variational score distillation.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[57]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Laba...
work page 2023
-
[58]
Xichen Pan, Li Dong, Shaohan Huang, Zhiliang Peng, Wenhu Chen, and Furu Wei. Kosmos- g: Generating images in context with multimodal large language models.International Conference on Learning Representations, 2024
work page 2024
-
[59]
Lianyu Pang, Jian Yin, Baoquan Zhao, Feize Wu, Fu Lee Wang, Qing Li, and Xudong Mao. Attndreambooth: Towards text-aligned personalized text-to-image generation.Advances in Neural Information Processing Systems, 37:39869–39900, 2024
work page 2024
-
[60]
NaHyeon Park, Kunhee Kim, and Hyunjung Shim. Textboost: Towards one-shot personaliza- tion of text-to-image models via fine-tuning text encoder.arXiv preprint arXiv:2409.08248, 2024
-
[61]
Maitreya Patel, Sangmin Jung, Chitta Baral, and Yezhou Yang. lambda-eclipse: Multi-concept personalized text-to-image diffusion models by leveraging clip latent space.arXiv preprint arXiv:2402.05195, 2024
-
[62]
Orthogonal adaptation for modular customization of diffusion models
Ryan Po, Guandao Yang, Kfir Aberman, and Gordon Wetzstein. Orthogonal adaptation for modular customization of diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7964–7973, 2024
work page 2024
-
[63]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. DreamFusion: Text-to-3D using 2D Diffusion.International Conference on Learning Representations, 2023
work page 2023
-
[64]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[65]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 06 2022
work page 2022
-
[66]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015
work page 2015
-
[67]
Ipadapter-instruct: Resolving ambiguity in image-based conditioning using instruct prompts, 2024
Ciara Rowles, Shimon Vainer, Dante De Nigris, Slava Elizarov, Konstantin Kutsy, and Simon Donné. Ipadapter-instruct: Resolving ambiguity in image-based conditioning using instruct prompts, 2024
work page 2024
-
[68]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aber- man. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22500–22510, 2023
work page 2023
-
[69]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Wei Wei, Tingbo Hou, Yael Pritch, Neal Wad- hwa, Michael Rubinstein, and Kfir Aberman. Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models.arXiv preprint arXiv:2307.06949, 2023
-
[70]
Align your flow: Scaling continuous-time flow map distillation
Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align your flow: Scaling continuous- time flow map distillation.arXiv preprint arXiv:2506.14603, 2025. 14
-
[71]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S Sara Mahdavi, Rapha Gontijo Lopes, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in Neural Information Processing Systems, 2022
work page 2022
-
[72]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. International Conference on Learning Representations, 2022
work page 2022
-
[73]
Adversarial diffusion distillation.European Conference on Computer Vision, 2024
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation.European Conference on Computer Vision, 2024
work page 2024
-
[74]
Ziplora: Any subject in any style by effectively merging loras.arXiv preprint arXiv:2311.13600, 2023
Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svetlana Lazebnik, Yuanzhen Li, and Varun Jampani. Ziplora: Any subject in any style by effectively merging loras.arXiv preprint arXiv:2311.13600, 2023
-
[75]
Jing Shi, Wei Xiong, Zhe Lin, and Hyun Joon Jung. Instantbooth: Personalized text-to-image generation without test-time finetuning.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[76]
Enis Simsar, Thomas Hofmann, Federico Tombari, and Pinar Yanardag. Loraclr: Contrastive adaptation for customization of diffusion models.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[77]
James Seale Smith, Yen-Chang Hsu, Lingyu Zhang, Ting Hua, Zsolt Kira, Yilin Shen, and Hongxia Jin. Continual diffusion: Continual customization of text-to-image diffusion with c-lora.arXiv preprint arXiv:2304.06027, 2023
-
[78]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021
work page 2021
-
[79]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning, pages 32211–32252. PMLR, 2023
work page 2023
-
[80]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.