GRAPHIA: Harnessing Social Graph Data to Enhance LLM-Based Social Simulation
Pith reviewed 2026-05-18 03:44 UTC · model grok-4.3
The pith
Social graphs serve as high-quality supervision for training LLMs to simulate realistic social networks via reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
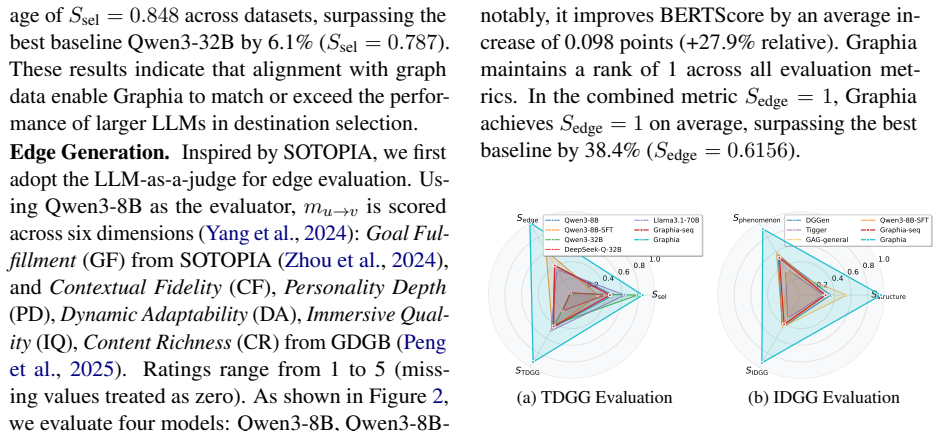
Graphia is a framework that harnesses social graph data as supervision signals for LLM post-training through reinforcement learning. Using GNN-based structural rewards, it trains agents for destination selection and edge generation, followed by graph generation pipelines. On three real-world networks, it improves micro-level metrics including destination selection score by 6.1%, edge classification by 12%, and edge content BERTScore by 27.9%, while achieving 35.98% higher structural similarity and 28.71% better replication of social phenomena at the macro level.
What carries the argument
GNN-based structural rewards applied in reinforcement learning to post-train LLMs for predicting social interactions and generating edges.
If this is right
- Agents learn to select interaction partners more accurately based on structural signals.
- Generated interactions better match real content patterns as measured by BERTScore.
- Simulated networks exhibit stronger alignment with observed structural similarities and social phenomena.
- Graph data proves effective as a supervision source for closing gaps in LLM social simulations.
Where Pith is reading between the lines
- Applying similar graph supervision could enhance LLM performance in other structured generation tasks beyond social networks.
- Researchers might use these improved simulations to model the effects of changes in network structure on behavior.
- Combining graph-based rewards with human feedback could further refine the alignment process.
Load-bearing premise
That rewards derived from graph neural networks on real social graphs provide an unbiased and sufficient signal to align LLM-generated behaviors with actual social dynamics.
What would settle it
Observing no significant improvement or a decrease in the reported alignment metrics when Graphia is applied to additional real-world social networks beyond the three tested would falsify the central effectiveness claim.
Figures





read the original abstract
Large language models (LLMs) have shown promise in simulating human-like social behaviors. Social graphs provide high-quality supervision signals that encode both local interactions and global network structure, yet they remain underutilized for LLM training. To address this gap, we propose Graphia, the first general LLM-based social graph simulation framework that leverages graph data as supervision for LLM post-training via reinforcement learning. With GNN-based structural rewards, Graphia trains specialized agents to predict whom to interact with (destination selection) and how to interact (edge generation), followed by designed graph generation pipelines. We evaluate Graphia under two settings: Transductive Dynamic Graph Generation (TDGG), a micro-level task with our proposed node-wise interaction alignment metrics; and Inductive Dynamic Graph Generation (IDGG), a macro-level task with our proposed metrics for aligning emergent network properties. On three real-world networks, Graphia improves micro-level alignment by 6.1% in the composite destination selection score, 12% in edge classification accuracy, and 27.9% in edge content BERTScore over the strongest baseline. For macro-level alignment, it achieves 35.98% higher structural similarity and 28.71% better replication of social phenomena such as power laws and echo chambers. Our results show that social graphs can serve as high-quality supervision signals for LLM post-training, closing the gap between agent behaviors and network dynamics for LLM-based simulation. Code is available at https://github.com/Ji-Cather/Graphia.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Graphia, the first general LLM-based social graph simulation framework that uses GNN-derived structural rewards from real-world social graphs as supervision signals for LLM post-training via reinforcement learning. Specialized agents are trained to handle destination selection and edge generation, followed by graph generation pipelines. Evaluation occurs under Transductive Dynamic Graph Generation (TDGG) with proposed micro-level node-wise interaction alignment metrics and Inductive Dynamic Graph Generation (IDGG) with macro-level metrics for emergent network properties. On three real-world networks, Graphia reports concrete gains over the strongest baseline: 6.1% in composite destination selection score, 12% in edge classification accuracy, and 27.9% in edge content BERTScore for micro-level alignment; 35.98% higher structural similarity and 28.71% better replication of phenomena such as power laws and echo chambers for macro-level alignment. Code is released publicly.
Significance. If the reported alignment gains hold after addressing potential overlaps between reward signals and evaluation, the work would meaningfully advance LLM-based social simulation by showing how graph-structured supervision can improve both local agent behaviors and global network dynamics. The public code release supports reproducibility, a clear strength for this line of research.
major comments (3)
- [IDGG evaluation section] IDGG evaluation section: the headline macro-level results (35.98% structural similarity gain and 28.71% better replication of power laws/echo chambers) rest on metrics that directly measure degree distributions, clustering, and community structure—the same properties that GNN structural rewards are known to encode. The manuscript must demonstrate that the reward model supplies independent supervision rather than simply teaching the LLM to reproduce the GNN's inductive biases on the identical networks used as ground truth.
- [Experimental results and setup] Experimental results and setup: the abstract and results report specific percentage improvements (6.1%, 12%, 27.9%, etc.) without accompanying statistical significance tests, standard deviations across runs, or explicit details on data splits and baseline hyper-parameters. These omissions make it difficult to judge whether the micro-level gains are robust or could be sensitive to post-hoc choices.
- [GNN reward formulation] GNN reward formulation: the precise definition of the structural rewards (how node/edge features are extracted and aggregated) is not shown to be separable from the IDGG structural-similarity and social-phenomena metrics; without this separation the central claim that graph data provides 'high-quality supervision' for genuine alignment remains at risk of circularity.
minor comments (2)
- [Abstract] The three real-world networks used for experiments are not named in the abstract; adding their identities would improve immediate context for readers.
- [Notation and presentation] Ensure all acronyms (TDGG, IDGG, BERTScore) are defined on first use and used consistently in figure captions and tables.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and have revised the manuscript to improve clarity, add missing statistical details, and better articulate the distinction between reward signals and evaluation metrics.
read point-by-point responses
-
Referee: [IDGG evaluation section] the headline macro-level results (35.98% structural similarity gain and 28.71% better replication of power laws/echo chambers) rest on metrics that directly measure degree distributions, clustering, and community structure—the same properties that GNN structural rewards are known to encode. The manuscript must demonstrate that the reward model supplies independent supervision rather than simply teaching the LLM to reproduce the GNN's inductive biases on the identical networks used as ground truth.
Authors: We appreciate the referee highlighting the risk of circularity between GNN rewards and IDGG metrics. In the revised manuscript we have added Section 4.4, which explicitly contrasts the local nature of the rewards (GNN-based prediction of node degrees and edge existence probabilities computed on 2-hop neighborhoods during RL training) with the global emergent metrics used in IDGG (e.g., KS statistic on degree distributions, modularity for communities, and power-law exponent fitting). We further report an additional inductive experiment on a completely held-out network whose structure was never seen by the reward GNN, showing that performance gains persist. These additions demonstrate that the supervision guides dynamic agent behavior rather than directly reproducing GNN inductive biases on the evaluation graphs. revision: yes
-
Referee: [Experimental results and setup] the abstract and results report specific percentage improvements (6.1%, 12%, 27.9%, etc.) without accompanying statistical significance tests, standard deviations across runs, or explicit details on data splits and baseline hyper-parameters. These omissions make it difficult to judge whether the micro-level gains are robust or could be sensitive to post-hoc choices.
Authors: We agree that statistical rigor and experimental details are essential. The revised manuscript now includes standard deviations over five independent runs with different random seeds for all reported metrics. We have added paired t-test p-values (all improvements significant at p < 0.05) in Section 5 and Appendix B. Data splits are now explicitly stated (70/15/15 train/validation/test for TDGG; disjoint networks for IDGG), and we have included a table summarizing hyper-parameters for all baselines and our model, including learning rates, reward coefficients, and GNN architecture choices. revision: yes
-
Referee: [GNN reward formulation] the precise definition of the structural rewards (how node/edge features are extracted and aggregated) is not shown to be separable from the IDGG structural-similarity and social-phenomena metrics; without this separation the central claim that graph data provides 'high-quality supervision' for genuine alignment remains at risk of circularity.
Authors: We acknowledge the need for clearer separability. Section 3.2 has been expanded with the exact formulation: node rewards aggregate mean-pooled GNN embeddings over 2-hop neighborhoods to predict degree and centrality, while edge rewards use a link-prediction head. The revised text now explicitly contrasts these local, dense reward signals (used only to shape individual agent decisions during RL) with the global, post-hoc IDGG metrics (e.g., full-graph power-law fitting and echo-chamber detection). Although conceptual overlap exists because both concern graph structure, the training objective optimizes sequential interaction choices rather than directly matching the evaluation statistics; we have added a short discussion of this distinction in Section 4.4. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical method: GNN-based structural rewards are used within an RL post-training loop to align LLM agents on destination selection and edge generation, followed by graph generation pipelines. Evaluation occurs on held-out or separate real-world network instances using independent micro-level (destination selection, edge classification, BERTScore) and macro-level (structural similarity, power-law/echo-chamber replication) metrics. No equations or steps are shown that reduce a claimed prediction or result to a fitted parameter or self-citation by construction; the central claims rest on comparative performance against external baselines rather than internal redefinition. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Social graphs provide high-quality supervision signals that encode both local interactions and global network structure for LLM training.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosurereality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For macro-level alignment, it achieves 41.11% higher structural similarity and 32.98% better replication of emergent social phenomena (e.g., power laws, echo chambers)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Graphmaster: Au- tomated graph synthesis via LLM agents in data- limited environments. CoRR, abs/2504.00711. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur ...
-
[2]
The llama 3 herd of models. CoRR, abs/2407.21783. Chen Gao, Xiaochong Lan, Nian Li, Yuan Yuan, Jingtao Ding, Zhilun Zhou, Fengli Xu, and Yong Li
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
S$^3$: Social-network Simulation System with Large Language Model-Empowered Agents
S3: Social-network simulation sys- tem with large language model-empowered agents. CoRR, abs/2307.14984. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 oth- ers
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Llm-based multi-agent systems are scalable graph generative models. In Findings of the Association for Computational Linguistics, ACL 2025 Vienna, Austria, July 27, 2025, pages 1492–
work page 2025
-
[5]
Ex- ploring the potential of large language models as predictors in dynamic text-attributed graphs. CoRR, abs/2503.03258. Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu
-
[6]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Llms-as-judges: A comprehensive survey on llm- based evaluation methods. CoRR, abs/2412.05579. Yuhan Liu, Xiuying Chen, Xiaoqing Zhang, Xing Gao, Ji Zhang, and Rui Yan
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Unveiling the truth and facilitating change: Towards agent-based large-scale social movement simulation. In Findings of the Association for Computational Linguistics, ACL 2024 Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 4789–
work page 2024
-
[8]
GDGB: A benchmark for generative dynamic text-attributed graph learning. CoRR, abs/2507.03267. Jinghua Piao, Yuwei Yan, Jun Zhang, Nian Li, Junbo Yan, Xiaochong Lan, Zhihong Lu, Zhiheng Zheng, Jing Yi Wang, Di Zhou, Chen Gao, Fengli Xu, Fang Zhang, Ke Rong, Jun Su, and Yong Li
-
[9]
Agentsociety: Large-scale simulation of llm-driven generative agents advances understanding of human behaviors and society. CoRR, abs/2502.08691. Giulio Rossetti, Massimo Stella, Rémy Cazabet, Kather- ine Abramski, Erica Cau, Salvatore Citraro, An- drea Failla, Riccardo Improta, Virginia Morini, and Valentina Pansanella
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Y social: an llm-powered social media digital twin. CoRR, abs/2408.00818. Keigo Sakurai, Ren Togo, Takahiro Ogawa, and Miki Haseyama
-
[11]
LLM is knowledge graph rea- soner: Llm’s intuition-aware knowledge graph rea- soning for cold-start sequential recommendation. In Advances in Information Retrieval - 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6-10, 2025, Proceedings Part II, volume 15573 of Lecture Notes in Computer Science, pages 263–278. Zhihong Sh...
work page 2025
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. Chenxi Wang, Zongfang Liu, Dequan Yang, and Xiuy- ing Chen. 2025a. Decoding echo chambers: Llm- powered simulations revealing polarization in social networks. In Proceedings of the 31st International Conference on Computational Linguistics,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Qwen3 technical report. CoRR, abs/2505.09388. An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Hao- ran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, and 43 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Qwen2 technical report. Preprint, arXiv:2407.10671. Junchi Yao, Hongjie Zhang, Jie Ou, Dingyi Zuo, Zheng Yang, and Zhicheng Dong
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Sotopia-rl: Reward design for social intelligence. CoRR, abs/2508.03905. Jiasheng Zhang, Jialin Chen, Menglin Yang, Aosong Feng, Shuang Liang, Jie Shao, and Rex Ying. 2024a. DTGB: A comprehensive benchmark for dynamic text-attributed graphs. In Proceedings of the Annual Conference on Neural Information Processing Systems. Tianyi Zhang, Varsha Kishore, Fel...
-
[16]
In Proceedings of the 8-th International Conference on Learning Representations
Bertscore: Evalu- ating text generation with BERT. In Proceedings of the 8-th International Conference on Learning Representations. Xiaoqing Zhang, Xiuying Chen, Yuhan Liu, Jianzhou Wang, Zhenxing Hu, and Rui Yan. 2024b. A large- scale time-aware agents simulation for influencer selection in digital advertising campaigns. CoRR, abs/2411.01143. Xiaoqing Zh...
-
[17]
Sa- graph: A large-scale social graph dataset with com- prehensive context for influencer selection in market- ing. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua Italy, July 13-18, 2025, pages 3733–3742. Wenzhen Zheng and Xijin Tang
work page 2025
-
[18]
a user interested in fitness gear
B Details of Metric We provide detailed mathematical formulations and implementation specifics for the IDGG and TDGG social fidelity Scores introduced in Section 4.1. First, we define the dataset-wise normalization function for different metrics. To map all com- ponent metrics to [0,1] with a positive direction (higher is better), we apply min–max normali...
work page 2025
-
[19]
In the SFT stage, we per- form full-parameter fine-tuning
Table 5: Training Configuration for GraphMixer Parameter Type Configuration Model Architecture Number of GNN Layers 2 Dropout Rate 0.1 Sampling Strategy Number of Neighbors 20 Sampling Method Recent Training Parameters Batch Size 2048 Patience 5 Training Details.Our training pipeline consists of two stages: supervised fine-tuning (SFT) fol- lowed by task-...
work page 2048
-
[20]
We additionally include a supervised fine-tuned version of Qwen3-8B (denoted Qwen3-SFT) to an- alyze the effect of direct behavioral cloning without reinforcement learning. 2https://huggingface.co/Qwen/Qwen3-8B To study the impact of input data structure, we train Graphia-seq on the sequentialized dataset. The model follows the same architecture and train...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.