Tree Training: Accelerating Agentic LLMs Training via Shared Prefix Reuse
Pith reviewed 2026-05-18 02:00 UTC · model grok-4.3
The pith
Averaging the loss over all branches in a tree trajectory is algebraically identical to a per-token weighted loss where each token's weight equals the fraction of branches passing through it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
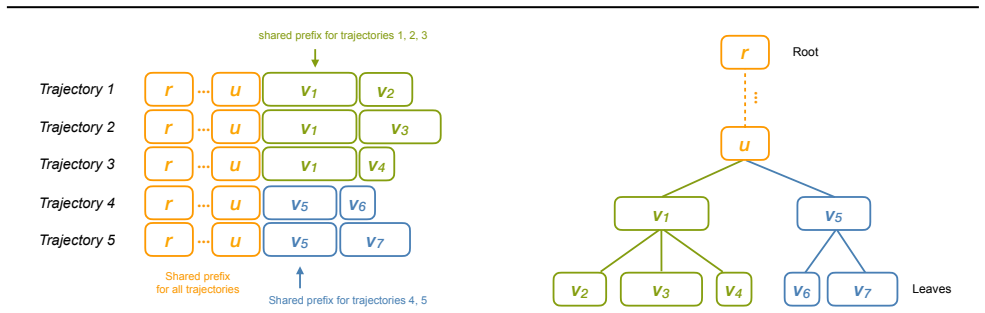
Averaging the loss over all branches independently is algebraically identical to a per-token weighted loss, where each token's weight equals the fraction of branches passing through it. The problem therefore reduces to computing the log-probability of every token in the prefix tree exactly once, with no repeated computation across shared prefixes: DFS serialization of the tree visits every token exactly once, and full-attention and SSM layers are adapted to ensure the resulting log-probabilities match independent per-branch calculation exactly. Redundancy-Free Tree Partitioning handles memory-constrained settings with zero redundant computation and peak memory bounded by a single root-to-toe
What carries the argument
DFS serialization of the tree, which visits every token exactly once, with adaptations to full-attention and SSM layers to match independent per-branch log-probabilities, plus Redundancy-Free Tree Partitioning that bounds peak memory to one root-to-leaf path.
Load-bearing premise
Adapting full-attention and SSM layers to the DFS-serialized tree must produce log-probabilities that exactly match independent per-branch calculation, and Redundancy-Free Tree Partitioning must incur zero redundant computation while bounding peak memory to a single root-to-leaf path.
What would settle it
Run both standard per-branch training and the proposed tree method on the same small trajectory tree and verify that the total loss and per-token gradients match exactly; any numerical difference would falsify the claimed algebraic identity.
Figures







read the original abstract
Agentic large language model (LLM) training often involves multi-turn interaction trajectories that branch into multiple execution paths due to concurrent tool use, think-mode, sub-agent, context management and other runtime designs. As a result, the tokens produced by a single task naturally form a tree-structured token trajectory with shared prefixes, rather than a linear sequence. Existing training pipelines linearize such trajectories and treat each branch independently, leading to substantial redundant computation in both forward and backward passes. We derive that averaging the loss over all branches independently is algebraically identical to a per-token weighted loss, where each token's weight equals the fraction of branches passing through it. The problem therefore reduces to computing the log-probability of every token in the prefix tree exactly once, with no repeated computation across shared prefixes: we propose DFS serialization of the tree, which visits every token exactly once, and adapt full-attention and SSM layers to ensure the resulting log-probabilities match independent per-branch calculation exactly. In practice, a single trajectory tree can be too large to fit in GPU memory; we therefore propose Redundancy-Free Tree Partitioning, which handles memory-constrained settings with zero redundant computation and peak memory bounded by a single root-to-leaf path. Together, these contributions form Tree Training, an efficient framework for training LLMs on tree-structured trajectories, achieving up to 6.2x end-to-end training speedup on dense and MoE models for both supervised fine-tuning and reinforcement learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that averaging the loss over all branches of a tree-structured token trajectory is algebraically identical to a per-token weighted loss (with each token weighted by the fraction of branches passing through it). It proposes DFS serialization of the tree together with adaptations to full-attention masks and SSM state handling so that log-probabilities are computed exactly once and match independent per-branch calculations. A Redundancy-Free Tree Partitioning scheme is introduced to handle large trees under memory constraints with zero redundant computation and peak memory bounded by a single root-to-leaf path. The resulting Tree Training framework is reported to deliver up to 6.2x end-to-end speedup for supervised fine-tuning and reinforcement learning on both dense and MoE models.
Significance. If the layer adaptations are shown to produce exactly matching log-probabilities and the partitioning incurs no hidden redundancy, the work offers a practical and theoretically grounded route to eliminate redundant forward/backward computation on branched trajectories that arise naturally in agentic LLM training. The algebraic identity is a clean, parameter-free derivation that directly reduces the problem to single-pass tree traversal; this is a genuine strength. The extension to both dense and MoE architectures and to both SFT and RL settings broadens potential impact.
major comments (2)
- [DFS Serialization and Layer Adaptations] DFS Serialization and Layer Adaptations section: the assertion that modified full-attention masks and SSM state save/restore produce log-probabilities that exactly equal those from independent per-branch forward passes is load-bearing for the claimed equivalence. No explicit proof, edge-case verification (e.g., multi-branch trees with shared prefixes of varying depth), or small-scale numerical comparison against a baseline of separate branch computations is provided; any cross-branch leakage in the attention mask or incorrect recurrent-state reset would invalidate the weighted-loss reduction.
- [Experimental Evaluation] Experimental Evaluation section: the 6.2x end-to-end speedup figure is presented without sufficient controls. Details are missing on model sizes and types, dataset characteristics, exact baseline implementation (linearized independent branches), batching strategy, hardware, and whether the reported time includes partitioning overhead or only the core forward/backward passes.
minor comments (2)
- [Abstract] Abstract: the phrase 'up to 6.2x' should be qualified with the specific model, task, and memory regime in which it was measured.
- [Notation and Preliminaries] Notation: ensure that 'prefix tree', 'trajectory tree', and 'branch' are defined once and used consistently; the transition from per-branch loss to per-token weighting would benefit from an explicit equation linking the two formulations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential impact of our work on accelerating training for agentic LLMs. We address each of the major comments below and will update the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [DFS Serialization and Layer Adaptations] DFS Serialization and Layer Adaptations section: the assertion that modified full-attention masks and SSM state save/restore produce log-probabilities that exactly equal those from independent per-branch forward passes is load-bearing for the claimed equivalence. No explicit proof, edge-case verification (e.g., multi-branch trees with shared prefixes of varying depth), or small-scale numerical comparison against a baseline of separate branch computations is provided; any cross-branch leakage in the attention mask or incorrect recurrent-state reset would invalidate the weighted-loss reduction.
Authors: We appreciate this observation. The algebraic equivalence between averaging losses over branches and the per-token weighted loss is derived in Section 3.1 of the manuscript. To address the concern, we will include an explicit formal proof of the equivalence in the appendix of the revised manuscript. Additionally, we will add a small-scale numerical verification experiment comparing the log-probabilities from our DFS serialization with modified attention masks and SSM handling against independent per-branch computations on multi-branch trees with varying shared prefix depths. This will confirm the absence of cross-branch leakage and correct state resets. revision: yes
-
Referee: [Experimental Evaluation] Experimental Evaluation section: the 6.2x end-to-end speedup figure is presented without sufficient controls. Details are missing on model sizes and types, dataset characteristics, exact baseline implementation (linearized independent branches), batching strategy, hardware, and whether the reported time includes partitioning overhead or only the core forward/backward passes.
Authors: We agree that more experimental details are necessary for reproducibility and to substantiate the speedup claims. In the revised manuscript, we will expand the Experimental Evaluation section to include: specific model sizes and architectures (e.g., 7B dense and MoE models), dataset characteristics (number of trajectories, branching factors, etc.), a detailed description of the baseline implementation (linearized independent branches with standard attention), batching strategy used, hardware specifications (GPU types and counts), and clarification on timing measurements (confirming inclusion of partitioning overhead in end-to-end times). We will also report additional metrics such as memory usage and per-component timings. revision: yes
Circularity Check
No significant circularity; central equivalence is a direct algebraic identity
full rationale
The paper's key derivation states that averaging loss over independent branches is algebraically identical to a per-token weighted loss with weights as branch fractions through each token. This identity follows immediately from the definition of averaging and does not reduce to any fitted parameter, self-referential equation, or prior result by the same authors. The DFS serialization, attention/SSM adaptations, and Redundancy-Free Tree Partitioning are presented as new algorithmic mechanisms to realize the exact per-token log-probabilities without repetition; these steps are constructive proposals rather than re-expressions of inputs. No load-bearing claim relies on self-citation chains, uniqueness theorems imported from prior work, or ansatzes smuggled via citation. The derivation chain is self-contained against external benchmarks and introduces independent content.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption DFS serialization of the prefix tree visits every token exactly once while preserving the causal structure needed for exact log-probability computation.
- domain assumption Full-attention and SSM layers can be adapted to the serialized tree such that per-token log-probabilities remain identical to those computed on independent branches.
Reference graph
Works this paper leans on
-
[1]
Abdelaziz, I., Basu, K., Agarwal, M., Kumaravel, S., Stal- lone, M., Panda, R., Rizk, Y ., Bhargav, G. P. S., Crouse, M., Gunasekara, C., Ikbal, S., Joshi, S., Karanam, H., Kumar, V ., Munawar, A., Neelam, S., Raghu, D., Sharma, U., Soria, A. M., Sreedhar, D., Venkateswaran, P., Un- uvar, M., Cox, D. D., Roukos, S., Lastras, L. A., and Kapanipathi, P. Gra...
work page 2024
-
[2]
Association for Computational Linguistics. doi: 10.18653/v1/2024. emnlp-industry.85. URL https://aclanthology. org/2024.emnlp-industry.85/. Goru, R., Mehta, S., and Jain, P. One-pass to reason: To- ken duplication and block-sparse mask for efficient fine- tuning on multi-turn reasoning,
-
[3]
Hou, Z., Hu, Z., Li, Y ., Lu, R., Tang, J., and Dong, Y
URL https: //arxiv.org/abs/2504.18246. Hou, Z., Hu, Z., Li, Y ., Lu, R., Tang, J., and Dong, Y . Treerl: Llm reinforcement learning with on-policy tree search,
-
[4]
Ji, Y ., Ma, Z., Wang, Y ., Chen, G., Chu, X., and Wu, L
URL https://arxiv.org/abs/ 2506.11902. Ji, Y ., Ma, Z., Wang, Y ., Chen, G., Chu, X., and Wu, L. Tree search for llm agent reinforcement learning,
-
[5]
Tree search for llm agent reinforcement learning.arXiv preprint arXiv:2509.21240, 2025
URL https://arxiv.org/abs/2509.21240. Kim, S., Moon, S., Tabrizi, R., Lee, N., Mahoney, M. W., Keutzer, K., and Gholami, A. An llm compiler for parallel function calling,
-
[6]
URL https://arxiv.org/ abs/2312.04511. Li, Y ., Gu, Q., Wen, Z., Li, Z., Xing, T., Guo, S., Zheng, T., Zhou, X., Qu, X., Zhou, W., Zhang, Z., Shen, W., Liu, Q., Lin, C., Yang, J., Zhang, G., and Huang, W. Treepo: Bridging the gap of policy optimization and ef- ficacy and inference efficiency with heuristic tree-based modeling,
-
[7]
URL https://arxiv.org/abs/ 2508.17445. Liu, Z., Yue, T., Tang, Y ., Guo, L., Cai, J., Liu, Q., Chen, X., and Liu, J. Prefix grouper: Efficient grpo training through shared-prefix forward,
-
[8]
Prefix grouper: Efficient GRPO training through shared-prefix forward
URL https://arxiv. org/abs/2506.05433. Luo, X., Zhang, Y ., He, Z., Wang, Z., Zhao, S., Li, D., Qiu, L. K., and Yang, Y . Agent lightning: Train any ai agents with reinforcement learning,
-
[9]
Packer, C., Wooders, S., Lin, K., Fang, V ., Patil, S
URL https: //arxiv.org/abs/2508.03680. Packer, C., Wooders, S., Lin, K., Fang, V ., Patil, S. G., Stoica, I., and Gonzalez, J. E. Memgpt: Towards llms as operating systems,
-
[10]
MemGPT: Towards LLMs as Operating Systems
URL https://arxiv. org/abs/2310.08560. Pope, R., Douglas, S., Chowdhery, A., Devlin, J., Bradbury, J., Levskaya, A., Heek, J., Xiao, K., Agrawal, S., and Dean, J. Efficiently scaling transformer inference,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URLhttps://arxiv.org/abs/2211.05102. Qin, R., Li, Z., He, W., Zhang, M., Wu, Y ., Zheng, W., and Xu, X. Mooncake: A kvcache-centric disaggregated architecture for llm serving,
-
[12]
Mooncake: A kvcache-centric disaggregated architecture for llm serving, 2024
URL https:// arxiv.org/abs/2407.00079. Shah, J., Bikshandi, G., Zhang, Y ., Thakkar, V ., Ramani, P., and Dao, T. Flashattention-3: Fast and accurate attention with asynchrony and low-precision,
-
[13]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
URL https: //arxiv.org/abs/2407.08608. Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-lm: Training multi- billion parameter language models using model par- allelism,
work page internal anchor Pith review arXiv
-
[14]
URL https://arxiv.org/abs/ 1909.08053. Wang, F. and Hegde, S. Accelerating direct preference optimization with prefix sharing,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[15]
Wang, G., Zeng, J., Xiao, X., Wu, S., Yang, J., Zheng, L., Chen, Z., Bian, J., Yu, D., and Wang, H
URL https: //arxiv.org/abs/2410.20305. Wang, G., Zeng, J., Xiao, X., Wu, S., Yang, J., Zheng, L., Chen, Z., Bian, J., Yu, D., and Wang, H. Flashmask: Efficient and rich mask extension of flashattention,
-
[16]
Xu, W., Mei, K., Gao, H., Tan, J., Liang, Z., and Zhang, Y
URLhttps://arxiv.org/abs/2410.01359. Xu, W., Mei, K., Gao, H., Tan, J., Liang, Z., and Zhang, Y . A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
-
[17]
URL https: //arxiv.org/abs/2505.09388. Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y ., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Agentrl: Scaling agentic reinforcement learning with a multi-turn, multi-task framework, 2025
URLhttps://arxiv.org/abs/2510.04206. Zhong, W., Guo, L., Gao, Q., Ye, H., and Wang, Y . Memory- bank: Enhancing large language models with long-term memory,
-
[19]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
URL https://arxiv.org/abs/ 2305.10250. Zhou, Y ., Jiang, S., Tian, Y ., Weston, J., Levine, S., Sukhbaatar, S., and Li, X. Sweet-rl: Training multi-turn llm agents on collaborative reasoning tasks,
work page internal anchor Pith review Pith/arXiv arXiv
- [20]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.