Back to the Future: The Role of Past and Future Context Predictability in Incremental Language Production
Pith reviewed 2026-05-18 00:14 UTC · model grok-4.3
The pith
A new measure of information shared between a word and its future context, given past context, best predicts substitution errors and phonetic reduction in speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
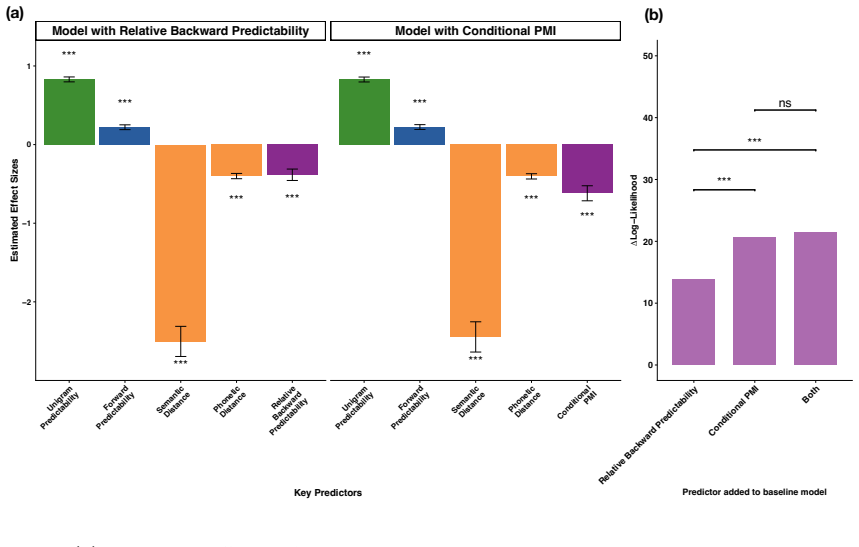
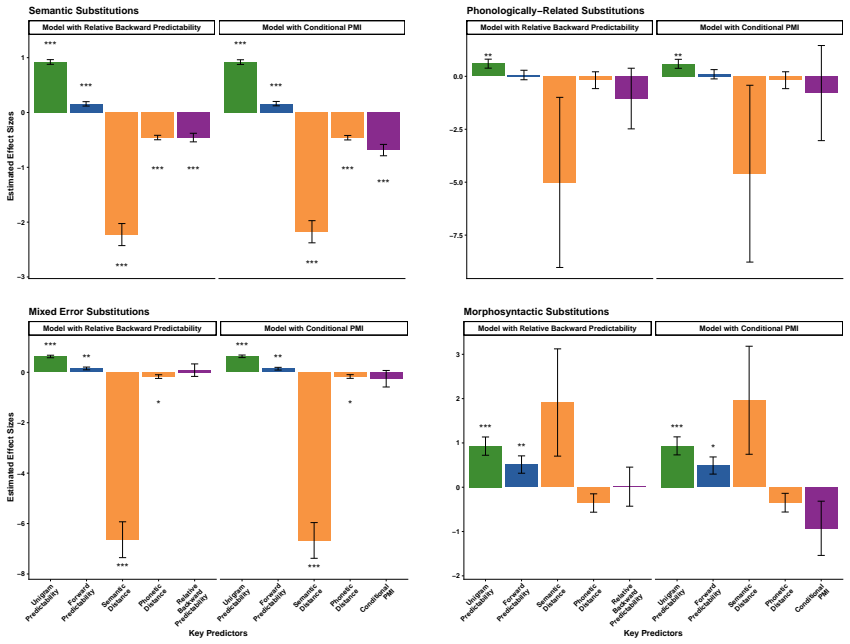
The central claim is that past-conditioned predictability increases the likelihood of a word appearing as a substitution error while future-conditioned predictability reduces it. Within a generative framework modeling lexical, contextual, and communicative influences on word choice, the authors' proposed measure of shared information between a word and future context under past constraints subsumes backward predictability and serves as the strongest contextual predictor of error identity. Error-type analysis further reveals graded trade-offs in how speakers prioritize form, meaning, and context information during lexical planning.
What carries the argument
The central object is the proposed information-theoretic measure that quantifies the information shared between a word and its future context under the constraints imposed by the past context.
If this is right
- Past-conditioned predictability increases the likelihood that a word surfaces as a substitution error.
- Future-conditioned predictability decreases the likelihood that a word surfaces as a substitution error.
- The proposed measure explains additional variance in phonetic reduction beyond what backward predictability alone accounts for.
- Speakers exhibit graded trade-offs among form, meaning, and context information when selecting words during incremental planning.
Where Pith is reading between the lines
- The results imply that production models should explicitly represent conditional future predictability to capture human-like error patterns and reduction.
- This approach could extend to predicting other planning phenomena such as pauses or self-repairs in longer utterances.
- Testing the measure in written production or across languages would clarify whether the past-future tradeoff is specific to spoken incremental planning.
Load-bearing premise
The generative framework accurately captures the separate influences of lexical, contextual, and communicative factors on word choice without circularity in how error likelihood is modeled.
What would settle it
A new corpus of naturalistic speech errors in which the proposed measure no longer outperforms backward predictability when predicting error identity after controlling for other factors would falsify the central claim.
Figures








read the original abstract
Contextual predictability shapes how we choose and encode words in production. The effects of a word's predictability given preceding or past context are generally well-understood in both production and comprehension, but studies of naturalistic production have also revealed a poorly-understood yet robust backward predictability effect of a word given only its future context, which may be linked to future planning. Across two studies of naturalistic speech, we revisit backward predictability using improved operationalizations, introducing a conceptually motivated information-theoretic measure that quantifies the information shared between a word and future context under the constraints imposed by the past context. Study 1 shows that this measure produces effects qualitatively similar to backward predictability while explaining unique variance in phonetic reduction. Study 2 examines substitution errors within a generative framework that models lexical, contextual, and communicative influences on word choice to predict the identity of the word that surfaces as an error. Within this framework, we find that past-conditioned predictability increases error likelihood, whereas future-conditioned predictability reduces it. Further, our proposed measure emerges as the strongest contextual predictor of error identity, subsuming backward predictability. Analysis of error types further reveals graded trade offs in how speakers prioritize form-, meaning-, and context-based information during lexical planning. Together, these findings illuminate how past and future context shape word choice and encoding, linking contextual predictability to mechanisms of incremental planning in sentence production.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents two studies on naturalistic speech examining how past and future context predictability influence word choice and encoding in language production. It proposes a new information-theoretic measure of the information shared between a word and its future context under past context constraints. Study 1 shows this measure has effects on phonetic reduction similar to backward predictability but explains unique variance. Study 2 employs a generative framework modeling lexical, contextual, and communicative factors to predict substitution error identities, finding that the proposed measure is the strongest contextual predictor, subsuming backward predictability, and identifying graded trade-offs in prioritizing form, meaning, and context information.
Significance. If the results hold, this work significantly advances the field by providing a conceptually motivated measure that better captures the interplay between past and future contexts in incremental planning. It strengthens the link between predictability effects and production mechanisms, with potential to inform computational models of language production and comprehension. The use of naturalistic data and error analysis adds ecological validity.
major comments (1)
- Study 2: The generative framework is described as modeling lexical, contextual, and communicative influences on word choice to predict error identity. To establish that the proposed measure is the strongest predictor without circularity, the manuscript should clarify whether the contextual influences in the base generative model are estimated independently of the information-theoretic measures being compared (past-conditioned predictability, future-conditioned predictability, and the proposed shared-information measure). If the base model already incorporates similar quantities, the ranking of predictors would not constitute an independent test of the measure's superiority.
minor comments (2)
- Abstract: The abstract reports qualitative similarity, unique variance explained, and strongest predictor status but omits specific statistical details, data exclusion rules, or full model specifications, which limits immediate verifiability of the central claims.
- Throughout: Notation for the proposed measure (past-conditioned mutual information) and related quantities should be defined more explicitly with equations early in the methods to aid reader comprehension of how it differs from standard backward predictability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and positive review of our manuscript. We address the major comment on Study 2 below.
read point-by-point responses
-
Referee: Study 2: The generative framework is described as modeling lexical, contextual, and communicative influences on word choice to predict error identity. To establish that the proposed measure is the strongest predictor without circularity, the manuscript should clarify whether the contextual influences in the base generative model are estimated independently of the information-theoretic measures being compared (past-conditioned predictability, future-conditioned predictability, and the proposed shared-information measure). If the base model already incorporates similar quantities, the ranking of predictors would not constitute an independent test of the measure's superiority.
Authors: We are grateful to the referee for pointing out the need for clarification on this matter to avoid any perception of circularity. In the generative framework of Study 2, the base model includes predictors for lexical factors (word frequency, length, and phonological properties), communicative factors (such as overall error rates and speaker-specific tendencies), and basic contextual influences captured through corpus-derived n-gram probabilities. These base contextual influences are estimated independently and do not incorporate the specific information-theoretic quantities under comparison, namely the past-conditioned predictability, future-conditioned predictability, or our proposed measure of shared information between the word and future context given the past. The latter measures are derived from more advanced language model-based estimates and are included as additional predictors in the model. We have revised the manuscript to explicitly describe this separation in the Methods section for Study 2, including details on how each component is computed, thereby confirming that the superior performance of the proposed measure represents an independent test. revision: yes
Circularity Check
No significant circularity; measures derived independently from information theory
full rationale
The paper defines its proposed shared-information measure directly from standard information-theoretic quantities on context distributions (past-conditioned mutual information between word and future context). Study 2's generative framework is presented as separately modeling lexical, contextual, and communicative influences on word choice to predict error identity, with the proposed measure then evaluated as a predictor within that framework. No equations or descriptions in the provided text reduce the target measure or its superiority to a fitted input, self-definition, or self-citation chain; the contextual components are not shown to embed the exact proposed quantity by construction. The derivation remains self-contained against external benchmarks of predictability and error modeling.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters in generative error model
axioms (1)
- standard math Information theory can quantify shared information between a word and future context under past constraints
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a principled alternative to backward predictability, based on the conditional PMI of the current word wt and the future context C>t given the past context C<t: conditional PMI(wt;C>t|C<t) = log p(wt|C>t,C<t) / p(wt|C<t)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Study 2 examines substitution errors within a generative framework that models lexical, contextual, and communicative influences on word choice
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Efficient Training of Language Models to Fill in the Middle
Anderson, J. R. (1991). The adaptive nature of human categorization.Psychological review, 98:409. Aylett, M. and Turk, A. (2004). The smooth signal redundancy hypothesis: A functional explanation for relationships between redundancy, prosodic prominence, and duration in spontaneous speech. Language and speech, 47:31–56. Balota, D. A., Boland, J. E., and S...
work page internal anchor Pith review arXiv 1991
-
[2]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
John Benjamins Publishing Company. Calhoun, S., Carletta, J., Brenier, J. M., Mayo, N., Jurafsky, D., Steedman, M., and Beaver, D. I. (2010). The nxt-format switchboard corpus: a rich resource for investigating the syntax, semantics, pragmatics and prosody of dialogue.Language Resources and Evaluation, 44:387–419. Christiansen, M. H. and Chater, N. (2016)...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Aprobabilisticmodeloflexicalandsyntacticaccessanddisambiguation.Cognitive Science, 20(2):137–194
Jurafsky, D.(1996). Aprobabilisticmodeloflexicalandsyntacticaccessanddisambiguation.Cognitive Science, 20(2):137–194. Jurafsky, D., Bell, A., Gregory, M., and Raymond, W. D. (2001). Probabilistic relations between words: Evidence from reduction in lexical production.Typological studies in language, 45:229–254. Kahneman, D. (1984). Changing views of attent...
work page 1996
-
[4]
Momma, S., Slevc, L. R., and Phillips, C. (2016). The timing of verb selection in japanese sentence production.Journal of Experimental Psychology: Learning, Memory, and Cognition, 42:813. Momma, S., Slevc, L. R., and Phillips, C. (2018). Unaccusativity in sentence production.Linguistic Inquiry, 49:181–194. Mortensen, D. R., Littell, P., Bharadwaj, A., Goy...
work page 2016
-
[5]
Rapp, D. N. and Samuel, A. G. (2002). A reason to rhyme: phonological and semantic influences on lexical access.Journal of Experimental Psychology: Learning, Memory, and Cognition, 28:564. Reece, A., Cooney, G., Bull, P., Chung, C., Dawson, B., Fitzpatrick, C., Glazer, T., Knox, D., Liebscher, A., and Marin, S. (2023). The candor corpus: Insights from a l...
work page 2002
-
[6]
Roelofs, A. and Piai, V. (2011). Attention demands of spoken word planning: A review.Frontiers in psychology, 2:307. Ryskin, R., Futrell, R., Kiran, S., and Gibson, E. (2018). Comprehenders model the nature of noise in the environment.Cognition, 181:141–150. Schneider, W. and Shiffrin, R. M. (1977). Controlled and automatic human information processing: I...
work page 2011
-
[7]
Beyond this, the tokenizer vocabulary also included<eos>,<PRE>,<SUF>,<MID>, and<unk>tokens
Instead of using an off-the-shelf Byte-Pair Encoding (BPE) tokenizer (Rad- ford et al., 2019), which relies on subword tokenization based on token frequency, we opt to train a whitespace-based tokenizer on the CANDOR corpus; we choose this tokenization scheme for simplicity of estimating token or word probability and to keep the vocabulary size more tract...
work page 2019
-
[8]
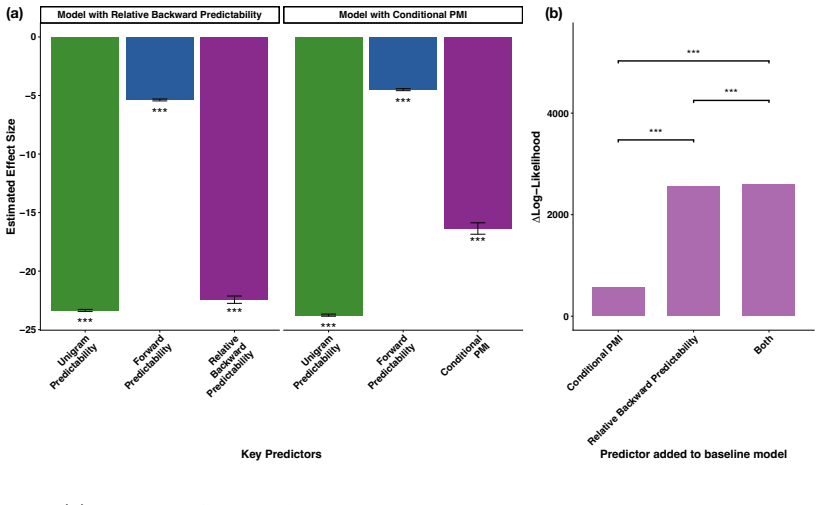
In study 1, the duration model with relative backward predictability had lower BIC than the model with conditional PMI, indicating a better fit to the data (∆BIC = -3890). Adding conditional PMI to the model with relative backward predictability further reduced the BIC compared to the model with only backward predictability; since this difference in BIC>1...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.