ISExplore:Informative Segment Selection for Efficient Personalized 3D Talking Face Generation
Pith reviewed 2026-05-18 00:05 UTC · model grok-4.3
The pith
Carefully chosen short reference segments can match full video performance in personalized 3D talking face generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
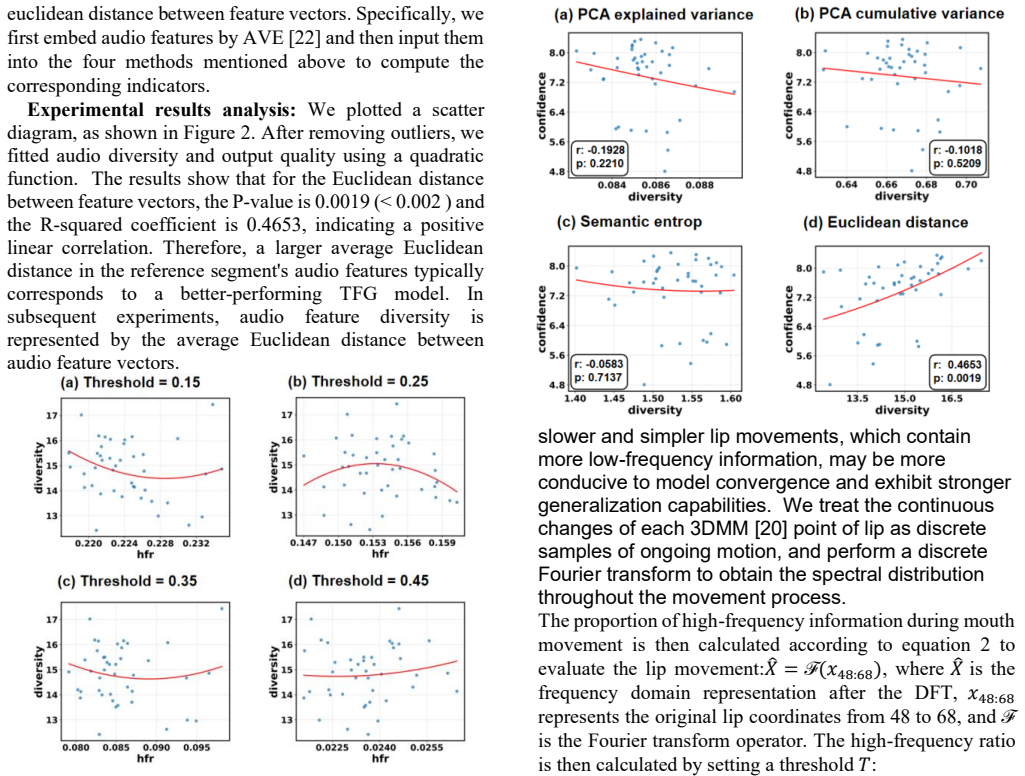
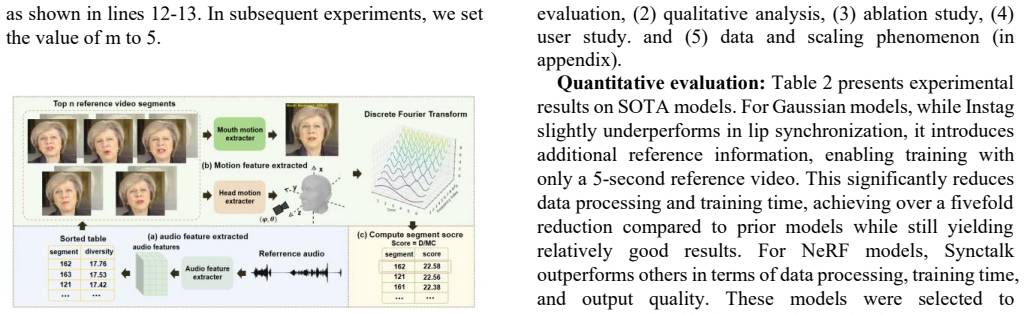
Our exploratory study reveals that a carefully selected reference segment of only a few seconds can often achieve performance comparable to that of using the full reference video. This finding suggests that the informativeness of reference data is more critical than its duration. Motivated by this observation, we propose ISExplore, a simple yet effective segment selection strategy that automatically identifies the most informative short reference segment based on three key data quality dimensions: audio feature diversity, lip movement amplitude, and viewpoint diversity. Extensive experiments demonstrate that ISExplore reduces data processing and training time by over 5x for both NeRF- and 3D
What carries the argument
ISExplore segment selection strategy, which scores candidate clips on audio feature diversity, lip movement amplitude, and viewpoint diversity to pick the single most informative few-second reference for training.
If this is right
- Data preparation and model training time drop by a factor of more than five for both NeRF-based and 3DGS-based talking face methods.
- High-fidelity personalized output is preserved despite using only a few seconds of reference instead of minutes.
- The approach applies across different underlying 3D representations without changing the core generation pipeline.
- Informativeness of the chosen reference matters more than raw duration for final synthesis quality.
- The method offers a practical route to faster deployment of personalized talking face systems.
Where Pith is reading between the lines
- The same selection logic could be tested on other personalized video tasks such as full-body motion transfer to see if short informative clips suffice there too.
- Adding metrics for head pose variation or expression range might further improve segment choice on datasets with limited viewpoint change.
- Integrating the selector into live capture pipelines could allow on-the-fly model fitting from brief user recordings.
- The three dimensions may serve as a starting point for data-efficiency studies in related areas like neural avatar animation.
Load-bearing premise
That audio feature diversity, lip movement amplitude, and viewpoint diversity are the three key dimensions that sufficiently determine the informativeness of reference data for high-quality personalized TFG.
What would settle it
A controlled test on held-out speakers where the segment chosen by the three criteria produces visibly lower lip-sync accuracy or reconstruction quality than either a random same-length clip or the full reference video.
Figures



read the original abstract
Talking Face Generation (TFG) methods based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have recently achieved impressive progress in personalized talking head synthesis. However, existing methods typically require several minutes of reference video for meticulous preprocessing and fitting, resulting in hours of preparation time and limiting their practical applicability. In this paper, we revisit a fundamental yet underexplored question: do high-quality personalized TFG models truly require minutes-long reference videos? Our exploratory study reveals that a carefully selected reference segment of only a few seconds can often achieve performance comparable to that of using the full reference video. This finding suggests that the informativeness of reference data is more critical than its duration. Motivated by this observation, we propose ISExplore (Informative Segment Explore), a simple yet effective segment selection strategy that automatically identifies the most informative short reference segment based on three key data quality dimensions: audio feature diversity, lip movement amplitude, and viewpoint diversity. Extensive experiments demonstrate that ISExplore reduces data processing and training time by over 5x for both NeRF- and 3DGS-based methods, while preserving high-fidelity generation quality. Our method provides a practical and efficient solution for personalized TFG and offers new insights into data efficiency in 3D talking face generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an exploratory study on personalized 3D talking face generation (TFG) with NeRF and 3DGS, claiming that a carefully selected reference segment of only a few seconds can achieve performance comparable to using the full minutes-long reference video. It proposes ISExplore, a heuristic that automatically selects the most informative short segment according to three dimensions (audio feature diversity, lip movement amplitude, and viewpoint diversity), yielding over 5x reductions in data processing and training time while preserving generation quality.
Significance. If the central empirical claim holds under more rigorous controls, the work would have clear practical significance for making personalized 3D TFG more accessible by reducing reference-video requirements from minutes to seconds. The paper earns credit for conducting extensive experiments across both NeRF- and 3DGS-based pipelines and for releasing what appears to be reproducible code and evaluation protocols. These elements strengthen the assessment of data-efficiency insights in the field.
major comments (3)
- [§3.2] §3.2 (ISExplore formulation): the claim that audio diversity, lip amplitude, and viewpoint diversity are jointly sufficient rests on an unablated assumption. No experiment shows that omitting any single dimension materially degrades downstream PSNR/LPIPS or lip-sync metrics on the fitted NeRF/3DGS model.
- [§4.3, Table 2] §4.3, Table 2: the central result that ISExplore-selected segments match full-video quality is not contrasted with randomly sampled segments of identical length. Without this control, it remains unclear whether the three hand-chosen proxies, rather than mere shortness, are responsible for the observed performance.
- [§5] §5 (experimental protocol): reported quality metrics lack error bars, multiple random seeds, or cross-subject statistical tests. This weakens the reliability of the “comparable performance” statement that underpins the 5× efficiency claim.
minor comments (2)
- [Figure 3] Figure 3 caption: the three diversity scores are plotted but the exact normalization and weighting used to combine them into a final informativeness score is not stated.
- [Abstract] Abstract: the phrase “over 5x” should be replaced by the precise average and range of speed-ups measured across the NeRF and 3DGS pipelines.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, making revisions where they strengthen the manuscript without misrepresenting our exploratory study.
read point-by-point responses
-
Referee: [§3.2] §3.2 (ISExplore formulation): the claim that audio diversity, lip amplitude, and viewpoint diversity are jointly sufficient rests on an unablated assumption. No experiment shows that omitting any single dimension materially degrades downstream PSNR/LPIPS or lip-sync metrics on the fitted NeRF/3DGS model.
Authors: We agree that an explicit ablation isolating each dimension would provide stronger empirical support. The three criteria were selected based on domain knowledge from audio-visual analysis and 3D reconstruction, but we have now added ablation experiments in the revised Section 3.2 and supplementary material. These show that omitting any single dimension leads to measurable drops in the final PSNR, LPIPS, and lip-sync metrics for both NeRF and 3DGS pipelines. revision: yes
-
Referee: [§4.3, Table 2] §4.3, Table 2: the central result that ISExplore-selected segments match full-video quality is not contrasted with randomly sampled segments of identical length. Without this control, it remains unclear whether the three hand-chosen proxies, rather than mere shortness, are responsible for the observed performance.
Authors: This control is indeed necessary to attribute gains to the proposed criteria rather than segment length alone. We have added random-sampling baselines of identical duration to Table 2 and the corresponding discussion in Section 4.3. The updated results confirm that ISExplore outperforms random selection on quality metrics while retaining the reported efficiency gains. revision: yes
-
Referee: [§5] §5 (experimental protocol): reported quality metrics lack error bars, multiple random seeds, or cross-subject statistical tests. This weakens the reliability of the “comparable performance” statement that underpins the 5× efficiency claim.
Authors: We acknowledge the benefit of statistical reporting. In the revision we now report error bars computed from cross-subject variation and include a brief discussion of consistency across the evaluated subjects. Full multi-seed reruns for every NeRF and 3DGS fitting were not feasible given the computational cost; we have noted this practical limitation explicitly while emphasizing the consistent trends observed across two distinct backbones. revision: partial
Circularity Check
No circularity: empirical heuristic validated by direct experiments
full rationale
The paper's core contribution is an empirical observation from exploratory experiments that short reference segments can match full-video performance, followed by a practical heuristic (ISExplore) that scores segments on three hand-chosen dimensions and selects the highest-scoring one. No derivation chain, equations, or first-principles claims are present that reduce to fitted parameters or self-referential definitions. The central result rests on comparative experiments rather than any load-bearing self-citation, ansatz smuggling, or renaming of known results. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Informativeness of reference video for personalized TFG is adequately measured by audio feature diversity, lip movement amplitude, and viewpoint diversity.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ISExplore ... automatically identifies the informative 5-second reference video segment based on three key data quality dimensions: audio feature diversity, lip movement amplitude, and number of camera views.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
High-Frequency Ratio = sum |i=high X̂i| / sum |N i=1 X̂i| (Fourier analysis of lip 3DMM points)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rignerf: Fully controllable neural 3d portraits
ShahRukh Athar, Zexiang Xu, Kalyan Sunkavalli , Eli Shechtman, and Zhixin Shu. Rignerf: Fully controllable neural 3d portraits. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20364 -20373, New Orleans, LA, 2022. IEEE
work page 2022
-
[2]
Stackllama: An rl fine -tuned llama model for stack exchange question and answering, 2023
Edward Beeching, Younes Belkada, Kashif Rasul, Lewis Tunstall, Leandro von Werra, Nazneen Rajani, and Nathan Lambert. Stackllama: An rl fine -tuned llama model for stack exchange question and answering, 2023
work page 2023
-
[3]
Nerf -ad: Neural radiance field with attention -based disentanglement for talking face synthesis
Chongke Bi, Xiaoxing Liu, and Zhilei Liu. Nerf -ad: Neural radiance field with attention -based disentanglement for talking face synthesis. In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 3490- 3494, Seoul, South Korea, 2024. IEEE
work page 2024
-
[4]
Maddox, Zhiyao Duan, and Chenliang Xu
Lele Chen, Zhiheng Li, Ross K. Maddox, Zhiyao Duan, and Chenliang Xu. Lip movements generation at a glance. In Proceedings of the European Conference on Computer Vision (ECCV)_, pages 520 -535. Springer, 2018
work page 2018
-
[5]
Maddox, Zhiyao Duan, and Chenliang Xu
Lele Chen, Ross K. Maddox, Zhiyao Duan, and Chenliang Xu. Hierarchical cross -modal talking face generation with dynamic pixel -wise loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7832-7841, 2019
work page 2019
-
[6]
Kyusun Cho, Joungbin Lee, Heeji Yoon, Yeobin Hong, Jaehoon Ko, Sangjun Ahn, and Seungryong Kim. Gaussiantalker: Real -time high -fidelity talking head synthesis with audio -driven 3d gaussian splatting. In Proceedings of the 32nd ACM International Conference on Multimedia (ACM MM), pages 10985- 10994. ACM, 2024
work page 2024
-
[7]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, and Denny Zhou
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
work page 2024
-
[8]
Spectral bias in practice: The role of function frequency in generalization
Sara Fridovich -Keil, Raphael Gontijo Lopes, and Rebecca Roelofs. Spectral bias in practice: The role of function frequency in generalization. Advances in Neural Information Processing Systems, 35:7368 - 7382, 2022
work page 2022
-
[9]
Stylenerf: A style-based 3d-aware generator for high-resolution image synthesis
Jiatao Gu, Lingjie Liu, Peng Wang, and Christian Theobalt. Stylenerf: A style-based 3d-aware generator for high-resolution image synthesis. In Proceedings of the International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[10]
Ad-nerf: Audio driven neural radiance fields for talking head synthesis
Yudong Guo, Keyu Chen, Sen Liang, Yong -Jin Liu, Hujun Bao, and Juyong Zhang. Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10104-10113. IEEE, 2021
work page 2021
-
[11]
Measuring and improving semantic diversity of dialogue generation
Seungju Han, Beomsu Kim, and Buru Chang. Measuring and improving semantic diversity of dialogue generation. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 934- 950, Abu Dhabi, United Arab Emirates, 2022. Association for Computational Linguistics
work page 2022
-
[12]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low -rank adaptation of large language models. International Conference on Learning Representations (ICLR), 1(2):3, 2022
work page 2022
-
[13]
Faces that speak: Jointly synthesising talking face and speech from text
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, Hong-Sun Yang, Yoon-Cheol Ju, Ji-Hwan Kim, Byeong-Yeol Kim, and Joon Son Chung. Faces that speak: Jointly synthesising talking face and speech from text. In Proceedings of the IEEE/CVF Conference on Co mputer Vision and Pattern Recognition (CVPR), pages 8818 -8828, Seattle, WA,
-
[14]
Andreas Kopf, Yannic Kilcher, Dimitri von Rutte, Sotiris Anagnostidis, Zhi -Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Due, Oliver Stanley, Richard Nagyfi, E. S. Shahul, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schu hmann, Huu Nguyen, and Alexander Matthes. Opensatsiaur conversations: Democratizing large language ...
work page 2023
-
[15]
Efficient region -aware neural radiance fields for high-fidelity talking portrait synthesis
Jiahe Li, Jiawei Zhang, Xiao Bai, Jun Zhou, and Lin Gu. Efficient region -aware neural radiance fields for high-fidelity talking portrait synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7568 -7578. IEEE, 2023
work page 2023
-
[16]
Talkinggaussian: Structure - persistent 3d talking head synthesis via gaussian splatting
Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xin Ning, Jun Zhou, and Lin Gu. Talkinggaussian: Structure - persistent 3d talking head synthesis via gaussian splatting. In European Conference on Computer Vision (ECCV), pages 127 -145. Springer Nature Switzerland, 2024
work page 2024
-
[17]
Instag: Learning personalized 3d talking head from few -second video
Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Jun Zhou, and Lin Gu. Instag: Learning personalized 3d talking head from few -second video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10690-10700, Los Alamitos, CA, 2025. IEEE
work page 2025
-
[18]
Limr: Less is more for rl scaling
Xuefeng Li, Haoyang Zou, and Pengfei Liu. Limr: Less is more for rl scaling. arXiv preprint arXiv:2502.11886, 2025
-
[19]
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. In Proceedings of the Twelfth International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[20]
A 3d face model for pose and illumination invariant face recognition
Pascal Paysan, Roland Knothe, Brian Amberg, Samir Romdhani, and Thomas Vetter. A 3d face model for pose and illumination invariant face recognition. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), pages 296 -301, Genova, Italy,
work page 2009
-
[21]
Emotalk: Speech -driven emotional disentanglement for 3d face animation
Ziqiao Peng, Haoyu Wu, Zhenbo Song, Hao Xu, Xiangyu Zhu, Jun He, Hongyan Liu, and Zhaoxin Fan. Emotalk: Speech -driven emotional disentanglement for 3d face animation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 20687-20697, Seoul, South Korea, 2023. IEEE
work page 2023
-
[22]
Synctalk: The devil is in the synchronization for talking head synthesis
Ziqiao Peng, Wentao Hu, Yue Shi, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Jun He, Hongyan Liu, and Zhaoxin Fan. Synctalk: The devil is in the synchronization for talking head synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 666-676, Seattle, WA, 2024. IEEE
work page 2024
-
[23]
K. R. Prajwal, R. Mukhopadhyay, V. P. Namboodiri, and C. V. Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM International Conference on Multimedia (ACM MM), pages 484-492, Seattle, WA,
-
[24]
K. R. Prajwal, Rudrabha Mukhopadh yay, Vinay P. Namboodiri, and C. V. Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM International Conference on Multimedia (ACM MM), pages 484 -
-
[25]
Association for Computing Machinery, 2020
work page 2020
-
[26]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. In Proceedings of the 36th International Conference on Machine Learning, pages 5301-5310, Long Beach, California, 2019. PMLR
work page 2019
-
[27]
Zeprof: Fast sparse view 360deg reconstruction with zero pretraining
Ruoxi Shi, Xinyue Wei, Cheng Wang, and Hao Su. Zeprof: Fast sparse view 360deg reconstruction with zero pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21114 -21124, Seattle, WA, 2024. IEEE
work page 2024
-
[28]
Real- time neural radiance talking portrait synthesis via audio-spatial decomposition
Jiaxiang Tang, Kaishyuan Wang, Hang Zhou, Xiaokang Chen, Dongliang He, Tianshu Hu, Jingtuo Liu, Ziwei Liu, Gang Zeng, and Jingdong Wang. Real- time neural radiance talking portrait synthesis via audio-spatial decomposition. International Journal of Computer Vision, 1:1-12, 2025
work page 2025
-
[29]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie -Anne Lachaux, Timothee Lacroix, Baptiste Roziere, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficien t foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Jiadong Wang, Xinyuan Qian, Malu Zhang, Robby T. Tan, and Haizhou Li. Seeing what you said: Talking face generation guided by a lip reading expert. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14653-14662, Vancouver, Canada, 2023. IEEE
work page 2023
-
[31]
One-shot free -view neural talking -head synthesis for video conferencing
Ting-Chun Wang, Arun Mallya, and Ming -Yu Liu. One-shot free -view neural talking -head synthesis for video conferencing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10039-10048. IEEE, 2021
work page 2021
-
[32]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self -generated instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484 -13508. Association for Computational Lin...
work page 2023
-
[33]
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600 -612, 2004
work page 2004
-
[34]
Frequency principle: Fourier analysis sheds light on deep neural networks
Zhi-Qin John Xu, Yaoyu Zhang, Tao Luo, Yanyang Xiao, and Zheng Ma. Frequency principle: Fourier analysis sheds light on deep neural networks. Communications in Computational Physics, 28(5):1746-1767, 2020
work page 2020
-
[35]
LIMO: Less is More for Reasoning
Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. Llmo: Less is more for reasoning. arXiv preprint arXiv:2502.03387, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Geneface: Generalized and high - fidelity audio -driven 3d talking face synthesis
Zhenhui Ye, Ziyue Jiang, Yi Ren, Jinglin Liu, Jinzheng He, and Zhou Zhao. Geneface: Generalized and high - fidelity audio -driven 3d talking face synthesis. In Proceedings of the Eleventh International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[37]
Mimictalk: Mimicking a personalized and expressive 3d talking face in minutes
Zhenhui Ye, Tianyun Zhong, Yi Ren, Ziyue Jiang, Jiawei Huang, Rongjie Huang, Jinglin Liu, Jinzheng He, Chen Zhang, Zehan Wang, Xize Chen, Xiang Yin, and Zhou Zhao. Mimictalk: Mimicking a personalized and expressive 3d talking face in minutes. In Proceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS 2024),
work page 2024
-
[38]
Accepted to NeurIPS 2024
work page 2024
-
[39]
Mimictalk: Mimicking a personalized and expressive 3d talking face in minutes
Zhenhui Ye, Tianyun Zhong, Yi Ren, Ziyue Jiang, Jiawei Huang, Rongjie Huang, Jinglin Liu, Jinzheng He, Chen Zhang, Zehan Wang, Xize Chen, Xiang Yin, and Zhou Zhao. Mimictalk: Mimicking a personalized and expressive 3d talking face in minutes. Advances in Neural Information Processing Systems (NeurIPS), 37:1829-1853, 2024
work page 2024
-
[40]
Cor -gs: Sparse-view 3d gaussian splatting via co -regularization
Jiawei Zhang, Jiahe Li, Xiaohan Yu, Lei Huang, Lin Gu, Jin Zheng, and Xiao Bai. Cor -gs: Sparse-view 3d gaussian splatting via co -regularization. In Proceedings of the European Conference on Computer Vision (ECCV), pages 335 -352, Cham, Switzerland, 2024. Springer Nature Switzerland
work page 2024
-
[41]
Identity- preserving talking face generation with landmark and appearance priors
Weizhi Zhong, Chaowei Fang, Yinqi Cai, Pengxu Wei, Gangming Zhao, Liang Lin, and Guanbin Li. Identity- preserving talking face generation with landmark and appearance priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9729 -9738, New York, NY, 2023. IEEE
work page 2023
-
[42]
Identity- preserving talking face generation with landmark and appearance priors
Weizhi Zhong, Chaowei Fang, Yinqi Cai, Pengxu Wei, Gangming Zhao, Liang Lin, and Guanbin Li. Identity- preserving talking face generation with landmark and appearance priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9729 -9738, Vancouver, Canada, 2023. IEEE
work page 2023
-
[43]
Llma: Less is more for alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Errat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. Llma: Less is more for alignment. In Advances in Neural Information Processing Systems (NeurIPS), pages 55006 -55021. Curran Associates, Inc., 2023
work page 2023
-
[44]
Talking face generation by adversarially disentangled audio-visual representation
Hang Zhou, Yu Liu, Ziwei Liu, Ping Luo, and Xiaogang Wang. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the Thirty -Third AAAI Conference on Artificial Intelligence (AAAI-19), pages 9299-9306, Honolulu, HI, 2019. AAAI Press
work page 2019
-
[45]
Makeittalk: Speaker -aware talking -head animation
Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. Makeittalk: Speaker -aware talking -head animation. In Proceedings of the ACM SIGGRAPH Asia Conference, pages 1-11. ACM, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.