Personality Pairing Improves Human-AI Collaboration
Pith reviewed 2026-05-17 20:07 UTC · model grok-4.3
The pith
Specific personality pairings can improve human-AI collaboration performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
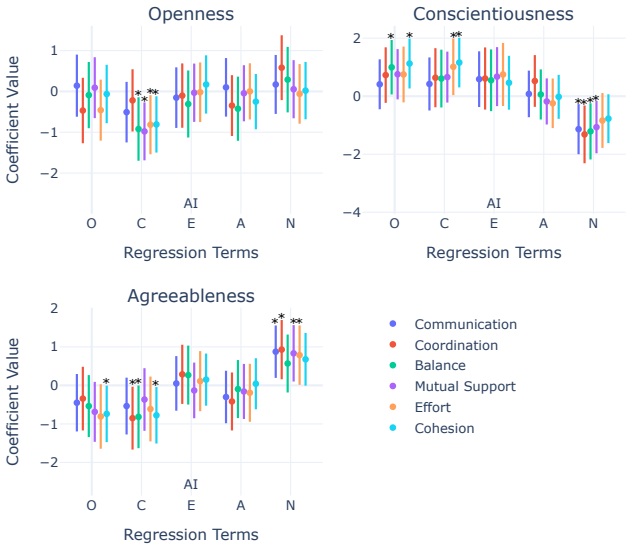
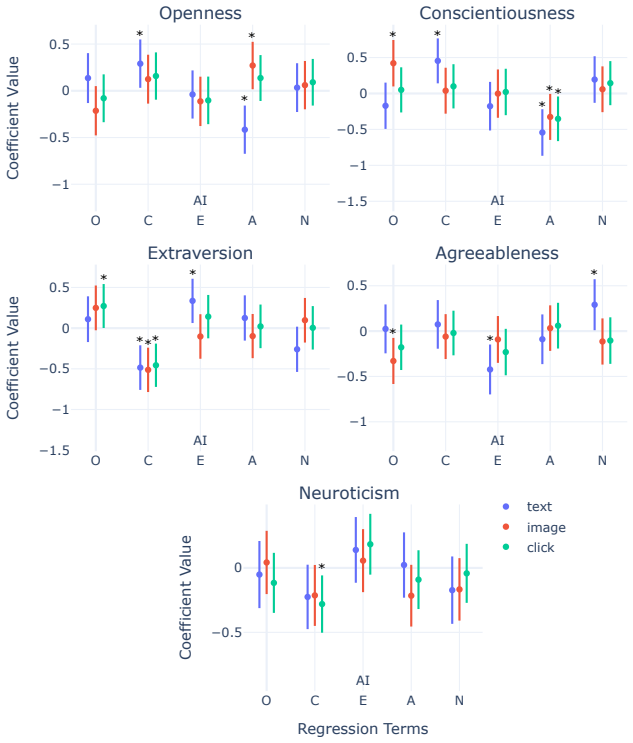
In a preregistered randomized experiment, 1,258 participants paired with AI agents prompted for varying Big Five personality traits produced 7,266 ads whose quality was shaped by both the human's and the AI's traits. Specific pairings directly affected outcomes, with extraverted humans paired with conscientious AI yielding the lowest quality, and neurotic humans paired with neurotic AI achieving higher click-through rates in a field experiment with nearly 5 million impressions, even after controlling for ad quality. These results provide the first large-scale causal experimental evidence that specific personality pairings can improve human-AI collaboration.
What carries the argument
Randomized pairing of human Big Five personality traits with AI agents prompted to exhibit targeted levels of the same traits, with outcomes measured by independent ad quality ratings and real-world performance metrics.
If this is right
- Human personalities and AI personalities each shape ad quality and teamwork on their own.
- Certain human-AI personality combinations produce measurable shifts in output quality.
- Ad quality generated under different pairings influences real-world metrics such as click-through rates.
- Some pairings improve performance metrics beyond the effect of quality alone.
- These patterns support further work on personalizing AI agents to individual users.
Where Pith is reading between the lines
- The same pairing logic could be tested in non-advertising tasks such as writing or data analysis.
- AI interfaces might eventually detect a user's personality traits automatically to select a suitable agent profile.
- Workplace teams that use AI assistants could see gains if agents are assigned according to employee traits.
- Longer-term studies could check whether the effects persist across repeated collaborations.
Load-bearing premise
Humans perceived and responded to the AI agents' prompted personality traits as intended, and ad quality ratings accurately captured collaboration effectiveness.
What would settle it
A replication experiment in which participants show no difference in perceived AI personality or in final ad quality and click rates across the same set of prompted trait levels.
Figures




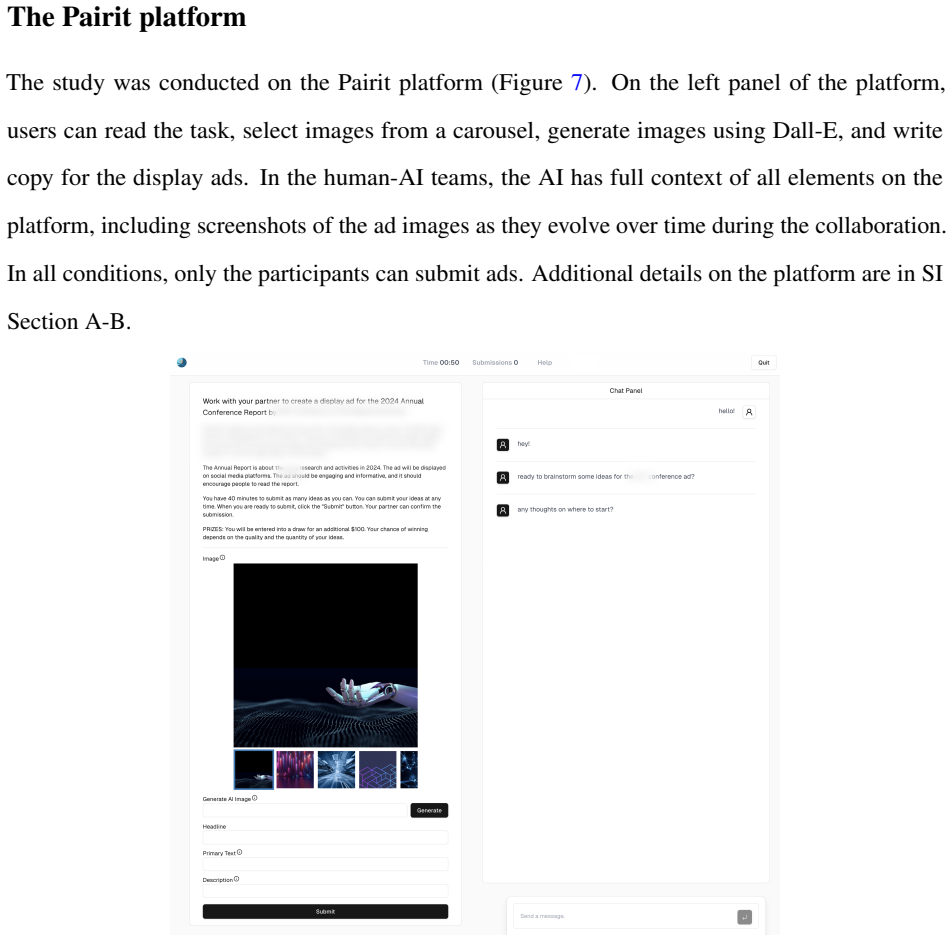
read the original abstract
Here we examine how AI agent "personalities" interact with human personalities to shape human-AI collaboration and performance. In a large-scale, preregistered randomized experiment, we paired 1,258 participants with AI agents prompted to exhibit varying levels of the Big Five personality traits. These human-AI teams produced 7,266 display ads for a real think tank, which we evaluated using 1,995 independent human raters and a field experiment on X that generated nearly 5 million impressions. We found that human and AI personalities individually shaped ad quality and teamwork. When examined together, human-AI personality pairings directly effected ad quality outcomes. For example, extraverted humans paired with conscientious AI produced the lowest-quality ads, followed by conscientious humans paired with agreeable AI and neurotic humans paired with conscientious AI. In the field experiment, ad quality significantly influenced ad performance, measured by click-through rates and cost-per-click, and neurotic humans paired with neurotic AI achieved higher click-through rates, even after controlling for ad quality. Together, these results provide the first large-scale causal experimental evidence that specific personality pairings can improve human-AI collaboration and motivate future research on the implications of AI personalization for performance and teamwork dynamics in human-AI teams.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that specific pairings of human and AI Big-Five personality traits causally affect collaboration outcomes. In a preregistered randomized experiment, 1,258 participants were paired with AI agents prompted to exhibit varying Big-Five traits; the resulting 7,266 ads were rated by 1,995 independent raters for quality and tested in a field experiment on X yielding nearly 5 million impressions. Key findings include lower ad quality for extraverted humans paired with conscientious AI and higher click-through rates for neurotic human-neurotic AI pairs even after controlling for ad quality.
Significance. If the results hold, the work supplies the first large-scale causal evidence that personality pairings shape human-AI collaboration performance. Strengths include the preregistered randomized design, large N, multiple independent raters, and a real-world field experiment with external metrics (click-through rates, cost-per-click) that are independent of the personality prompts.
major comments (1)
- [Methods] Methods: No manipulation check is reported to verify that participants perceived or responded to the prompted AI personality traits as intended. Without such verification, the observed pairing effects (e.g., extraverted humans + conscientious AI yielding lowest-quality ads) cannot be confidently attributed to personality matching rather than prompt wording, model stochasticity, or task artifacts.
minor comments (2)
- [Results] Results: Report inter-rater reliability (e.g., Cronbach’s alpha or ICC) for the 1,995 ad-quality raters to support the claim that ratings validly capture collaboration effectiveness.
- [Results] Abstract and Results: Clarify the exact statistical controls used when reporting that neurotic pairings achieve higher click-through rates “even after controlling for ad quality.”
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the strengths of our preregistered design, large sample, and field experiment. We address the single major comment below and describe the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods: No manipulation check is reported to verify that participants perceived or responded to the prompted AI personality traits as intended. Without such verification, the observed pairing effects (e.g., extraverted humans + conscientious AI yielding lowest-quality ads) cannot be confidently attributed to personality matching rather than prompt wording, model stochasticity, or task artifacts.
Authors: We agree that confirming participants' perceptions of the AI traits would strengthen causal attribution to personality matching specifically. Our experiment randomizes assignment to AI prompt conditions that were constructed from validated Big-Five trait descriptions, and the primary outcomes (independent ad-quality ratings by 1,995 raters and field click-through rates from nearly 5 million impressions) are measured independently of any participant self-report. These downstream metrics therefore reflect the actual content generated under each prompt. In the revision we will (1) append the exact prompt templates for each personality condition, (2) add a post-hoc linguistic analysis of the 7,266 generated ads using established Big-Five dictionaries to document trait-consistent language, and (3) explicitly note the absence of a participant-level manipulation check as a limitation while emphasizing the objective, externally validated performance measures. Because the data have already been collected, we cannot add a new real-time manipulation check, but the planned additions will improve transparency and help isolate the contribution of the personality prompts. revision: partial
Circularity Check
Purely empirical randomized experiment with independent external metrics
full rationale
The paper describes a preregistered randomized experiment that pairs participants with AI agents prompted for Big-Five traits, then measures ad quality via independent human raters and field click-through rates on X. No equations, fitted parameters, or derivations are present. Central claims rest on measured outcomes that are statistically independent of the input prompts once randomization is applied. No self-citations are invoked as uniqueness theorems or load-bearing premises. The design is self-contained against external benchmarks (rater evaluations and live ad performance), satisfying the criteria for a non-circular empirical result.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Random assignment to personality conditions produces comparable groups except for the treatment.
- domain assumption Prompted Big Five traits in the AI are perceived by humans as intended.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
large-scale preregistered randomized experiment that paired 1,258 participants with AI agents prompted to exhibit varying levels of the Big Five personality traits... ad quality... field experiment on X
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1287/orsc.2022.1651. 24 Anthropic. Claude character. https://www.anthropic.com/research/claude-character,
-
[2]
Ac- cessed: 2025-08-29. M. R. Barrick, G. L. Stewart, M. J. Neubert, and M. K. Mount. Relating member ability and personality to work-team processes and team effectiveness.Journal of applied psychology, 83(3):377,
work page 2025
-
[3]
URL https://doi.org/10.1177/ 00222429241275886
doi: 10.1177/00222429241275886. URL https://doi.org/10.1177/ 00222429241275886. M. Braun, B. de Langhe, S. Puntoni, and E. M. Schwartz. Leveraging digital advertising platforms for consumer research.Journal of Consumer Research, 51(1):119–128, 05
-
[4]
ISSN 0093-5301. doi: 10.1093/jcr/ucad058. URLhttps://doi.org/10.1093/jcr/ucad058. T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, ...
-
[5]
URLhttps://arxiv.org/abs/2507.21509. P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav. Mem0: Building production-ready ai agents with scalable long-term memory,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URLhttps://arxiv.org/abs/2504.19413. K. M. Collins, I. Sucholutsky, U. Bhatt, K. Chandra, L. Wong, M. Lee, C. E. Zhang, T. Zhi-Xuan, M. Ho, V . Mansinghka, et al. Building machines that learn and think with people.Nature Human Behaviour, 8 (10):1851–1863,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URLhttps://arxiv.org/abs/2503.17473. A. Fügener, J. Grahl, A. Gupta, and W. Ketter. Cognitive challenges in human–artificial intelligence collaboration: Investigating the path toward productive delegation.Information Systems Research, 33(2): 678–696,
work page internal anchor Pith review arXiv
-
[8]
doi: 10.1145/3581641. 3584052. M. Hoegl and H. G. Gemuenden. Teamwork quality and the success of innovative projects: A theoretical concept and empirical evidence.Organization Science, 12(4):435–449,
-
[9]
doi: 10.1287/orsc.12.4.435. 10635. A. Humlum and E. Vestergaard. The adoption of chatgpt. Working Paper 2024-50, University of Chicago, Becker Friedman Institute for Economics,
-
[10]
Available at SSRN: https://ssrn.com/abstract= 4807516. M. Jakesch, A. Bhat, D. Buschek, L. Zalmanson, and M. Naaman. Co-writing with opinionated language mod- els affects users’ views. InProceedings of the 2023 CHI Conference on Human Factors in Computing Sys- tems, CHI ’23, New York, NY , USA,
work page 2023
-
[11]
Association for Computing Machinery. ISBN 9781450394215. doi: 10.1145/3544548.3581196. URLhttps://doi.org/10.1145/3544548.3581196. G. Jiang, M. Xu, S.-C. Zhu, W. Han, C. Zhang, and Y . Zhu. Evaluating and inducing personality in pre-trained language models,
- [12]
-
[13]
URLhttps://doi.org/10.1145/3208975
doi: 10.1145/3208975. URLhttps://doi.org/10.1145/3208975. M. F. Jung, J. J. Lee, N. DePalma, S. O. Adalgeirsson, P. J. Hinds, and C. Breazeal. Engaging robots: easing complex human-robot teamwork using backchanneling. InProceedings of the 2013 Conference on Computer Supported Cooperative Work, CSCW ’13, page 1555–1566, New York, NY , USA,
-
[14]
Association for Computing Machinery. ISBN 9781450313315. doi: 10.1145/2441776.2441954. URL https://doi.org/10.1145/2441776.2441954. S. L. Kichuk and W. H. Wiesner. The big five personality factors and team performance: implications for selecting successful product design teams.Journal of Engineering and Technology management, 14(3-4): 195–221,
-
[15]
doi: 10.1126/science.adh2586. OpenAI. Customizing your ChatGPT personality. https://help.openai.com/en/articles/ 11899719-customizing-your-chatgpt-personality, 2025a. Accessed: 2025-08-29. OpenAI. Sycophancy in GPT-4o. https://openai.com/index/sycophancy-in-gpt-4o/ , 2025b. Ac- cessed: 2025-08-29. N. Otis, R. Clarke, S. Delecourt, D. Holtz, and R. Koning....
-
[16]
URLhttps://arxiv.org/abs/2503.06195. M. Sharma, M. Tong, T. Korbak, D. Duvenaud, A. Askell, S. R. Bowman, N. Cheng, E. Durmus, Z. Hatfield- Dodds, S. R. Johnston, S. Kravec, T. Maxwell, S. McCandlish, K. Ndousse, O. Rausch, N. Schiefer, D. Yan, M. Zhang, and E. Perez. Towards understanding sycophancy in language models,
-
[17]
URL https://arxiv.org/abs/2310.13548. S. M. Tully, C. Longoni, and G. Appel. Lower artificial intelligence literacy predicts greater ai receptivity. Journal of Marketing, 0:00222429251314491,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
doi: 10.1038/s41562-024-02024-1. Y . Wan, J. Wu, M. Abdulhai, L. Shani, and N. Jaques. Enhancing personalized multi-turn dialogue with curiosity reward,
- [19]
-
[20]
doi: 10.1287/mnsc.2021.00588. J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Lichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou. Chain-of- thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Cu...
-
[21]
URL https://proceedings.neurips.cc/paper_ files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf. E. Wiles, Z. T. Munyikwa, and J. J. Horton. Algorithmic writing assistance on jobseekers’ resumes increases hires. Working Paper 30886, National Bureau of Economic Research,
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.