SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Pith reviewed 2026-05-17 20:18 UTC · model grok-4.3
The pith
Unifying recommendation serving into a single GPU model replaces separate CPU indexing services and enables more complex architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
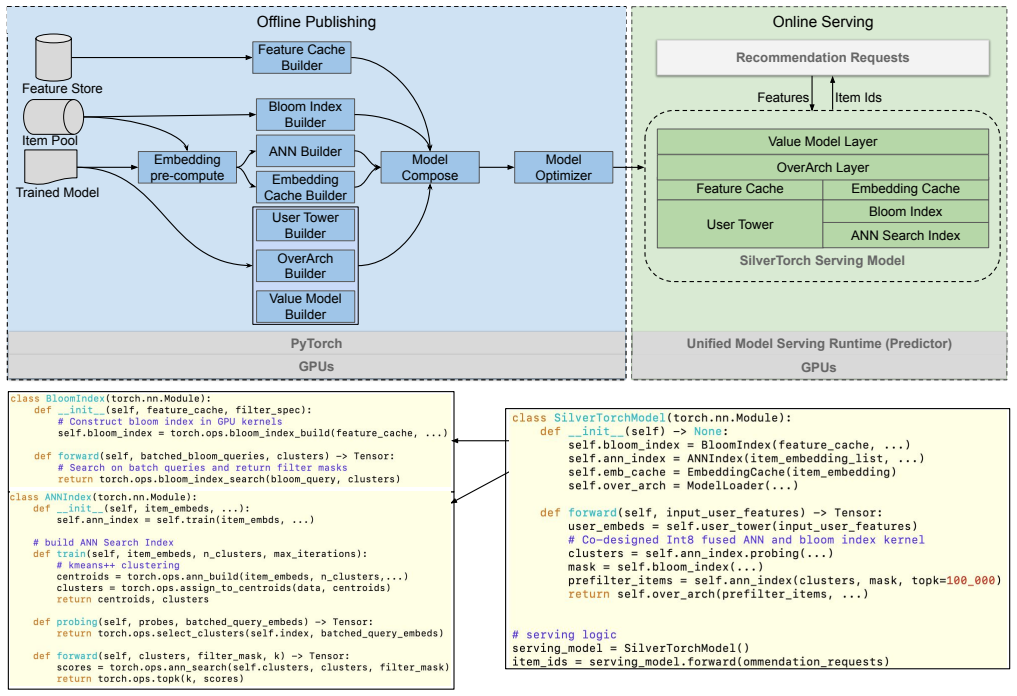
SilverTorch brings all components of deep learning recommendation model serving into one unified model by replacing standalone indexing and filtering services with model layers. It proposes a model-based GPU Bloom index for feature filtering and a fused Int8 ANN kernel for nearest neighbor search. Through co-design of the ANN search and feature filtering, it reduces GPU memory usage and eliminates computation. This enables an OverArch scoring layer and multi-task retrieval with a Value Model to aggregate scores, improving retrieval accuracy and supporting more complex models.
What carries the argument
The model-based GPU Bloom index paired with the fused Int8 ANN kernel, which together move filtering and search inside the model to cut memory and compute overhead.
If this is right
- Throughput reaches up to 23.7 times higher than prior approaches.
- Cost efficiency improves by 13.35 times relative to CPU-based serving.
- More complex models that use learned similarities and multi-task retrieval become feasible while accuracy rises.
- The design supports online serving of hundreds of models for varied applications.
Where Pith is reading between the lines
- The same unification pattern could be tested on other large-scale similarity tasks outside recommendation, such as content retrieval in media platforms.
- Developers might explore adding further model components like learned filters without rebuilding separate infrastructure layers.
- Production teams could measure end-to-end latency gains when the same GPU resources handle both retrieval and scoring in one pass.
Load-bearing premise
The integrated Bloom index and ANN kernel preserve or improve retrieval accuracy on diverse real-world queries without introducing systematic misses or biases.
What would settle it
Running the system on a production dataset with query patterns different from the evaluated ones and measuring whether recall or ranking quality drops below the level achieved by separate CPU indexing services.
Figures









read the original abstract
Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing approaches rely on dedicated ANN indexing and filtering services on CPUs, suffering from non-negligible costs and missing co-design opportunities. Such inefficiency makes them difficult to support complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we present SilverTorch, a model-based serving system that brings all components into one unified model. It unifies model serving by replacing standalone indexing and filtering services with model layers. We propose a model-based GPU Bloom index for feature filtering and a fused Int8 ANN kernel for nearest neighbor search. Through co-design of the ANN search and feature filtering, we reduce GPU memory usage and eliminate computation. Benefiting from this design, we scale up retrieval by introducing an OverArch scoring layer and a multi-task retrieval with a Value Model to aggregate scores. These advancements improve the retrieval accuracy and enable future studies for serving more complex models. Our evaluation on industry-scale datasets show that SilverTorch achieves up to 23.7\times higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch solution is 13.35\times more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch is deployed at scale, serving hundreds of models online and supporting recommendation for diverse applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. SilverTorch is a unified model-based serving system for deep learning recommendation models (DLRM) that integrates indexing, filtering, and scoring into GPU model layers. It replaces standalone CPU-based ANN and filtering services with a model-based GPU Bloom index for feature filtering and a fused Int8 ANN kernel for nearest-neighbor search. The design includes an OverArch scoring layer and multi-task retrieval via a Value Model to support complex architectures such as learned similarities. On industry-scale datasets the system reports up to 23.7× higher throughput than state-of-the-art approaches, 13.35× better cost efficiency than CPU baselines, and accuracy gains, with production deployment serving hundreds of models.
Significance. If the throughput, cost, and accuracy claims are substantiated with complete experimental detail, the work has substantial practical significance for large-scale recommendation infrastructure. Unifying indexing/filtering into model layers removes separate services and enables more expressive retrieval models on GPUs, which could lower operational costs while improving quality. The reported deployment at scale and the focus on co-design of quantization, Bloom filtering, and ANN kernels constitute concrete engineering contributions that address real production bottlenecks.
major comments (3)
- [Evaluation] Evaluation section: the central throughput claim of up to 23.7× improvement is presented without named baselines, hardware configurations, batch sizes, or error bars. Because the speedup is the primary empirical support for the unified model-based approach, the absence of these details prevents assessment of whether the gains are attributable to the Bloom index + fused Int8 kernel co-design or to other factors.
- [Model Architecture / Evaluation] Model description and evaluation: the claim that the model-based GPU Bloom index together with the fused Int8 ANN kernel preserves or improves retrieval accuracy without systematic misses is load-bearing for the accuracy-improvement argument, yet no recall@K, bias, or query-distribution analysis is reported. This directly affects the weakest assumption identified in the review.
- [§4] §4 (or equivalent): ablation studies isolating the contributions of the OverArch scoring layer and the Value Model for multi-task retrieval are missing. Without them it is impossible to determine whether the reported accuracy gains stem from these new components or from the underlying ANN and filtering changes.
minor comments (2)
- [Abstract] Abstract: the industry-scale datasets used for the reported numbers should be named (even if only by size or domain) to allow readers to gauge representativeness.
- [System Design] A diagram or pseudocode equation showing how the Bloom index and Int8 ANN kernel are fused inside the model forward pass would clarify the claimed elimination of computation and memory reduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment point by point below and will revise the paper to incorporate additional details and analyses where appropriate.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central throughput claim of up to 23.7× improvement is presented without named baselines, hardware configurations, batch sizes, or error bars. Because the speedup is the primary empirical support for the unified model-based approach, the absence of these details prevents assessment of whether the gains are attributable to the Bloom index + fused Int8 kernel co-design or to other factors.
Authors: We agree that these experimental details are necessary for full assessment and reproducibility. In the revised manuscript we will explicitly name the baselines (including the specific ANN libraries and CPU-based systems compared against), specify the hardware configurations (GPU models and counts), report the batch sizes used for each throughput measurement, and add error bars from repeated runs. These additions will clarify that the reported gains derive from the co-design of the model-based Bloom index and fused Int8 ANN kernel rather than other factors. revision: yes
-
Referee: [Model Architecture / Evaluation] Model description and evaluation: the claim that the model-based GPU Bloom index together with the fused Int8 ANN kernel preserves or improves retrieval accuracy without systematic misses is load-bearing for the accuracy-improvement argument, yet no recall@K, bias, or query-distribution analysis is reported. This directly affects the weakest assumption identified in the review.
Authors: We acknowledge that additional quantitative support for the accuracy claims would strengthen the argument. While the current manuscript reports accuracy improvements enabled by serving more complex models, we will add recall@K metrics, bias analysis, and query-distribution studies in the revision to demonstrate that the Bloom index and fused kernel preserve retrieval quality without introducing systematic misses. revision: yes
-
Referee: [§4] §4 (or equivalent): ablation studies isolating the contributions of the OverArch scoring layer and the Value Model for multi-task retrieval are missing. Without them it is impossible to determine whether the reported accuracy gains stem from these new components or from the underlying ANN and filtering changes.
Authors: We agree that isolating the contributions of the OverArch scoring layer and Value Model is important. In the revised version we will add ablation studies (in §4 or a new subsection) that separately measure the impact of these components on accuracy, holding the underlying ANN and filtering fixed, to clarify their role in the observed gains. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical systems paper whose central claims rest on measured throughput, cost-efficiency, and accuracy improvements from a GPU-based unified serving architecture. The abstract and description present engineering co-design choices (model-based GPU Bloom index, fused Int8 ANN kernel, OverArch scoring layer) validated through experiments on industry-scale datasets rather than any mathematical derivation chain, first-principles predictions, or fitted parameters that reduce to the paper's own inputs by construction. No self-definitional steps, load-bearing self-citations, or ansatz smuggling appear; the results are externally falsifiable via replication of the reported benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Bloom filter size and hash functions
- Int8 quantization parameters for ANN
axioms (1)
- domain assumption GPU hardware supplies sufficient memory bandwidth and compute to make the fused kernels faster than CPU services
invented entities (2)
-
model-based GPU Bloom index
no independent evidence
-
OverArch scoring layer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a model-based GPU Bloom index for feature filtering and a fused Int8 ANN kernel for nearest neighbor search. Through co-design of the ANN search and feature filtering, we reduce GPU memory usage and eliminate computation.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SilverTorch achieves up to 23.7× higher throughput ... 13.35× more cost-efficient than CPU-based solution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
14 {TensorFlow}: a system for {Large-Scale} machine learning
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. 14 {TensorFlow}: a system for {Large-Scale} machine learning. In12th USENIX symposium on operating systems design and implementation (OSDI 16), pages 265–283, 2016
work page 2016
-
[2]
Under- standing scaling laws for recommendation models
Newsha Ardalani, Carole-Jean Wu, Zeliang Chen, Bhargav Bhushanam, and Adnan Aziz. Understanding scaling laws for recommendation models.arXiv preprint arXiv:2208.08489, 2022
-
[3]
k-means++: The advantages of careful seeding
David Arthur and Sergei Vassilvitskii. k-means++: The advantages of careful seeding. Technical report, Stanford, 2006
work page 2006
-
[4]
Aws p4d.24xlarge instance cost
aws. Aws p4d.24xlarge instance cost. https://instances.vantage.sh/aws/ec2/p4d. 24xlarge?region=us-west-2, 2023
work page 2023
-
[5]
aws. Aws r6i.8xlarge instance cost. https://instances.vantage.sh/aws/ec2/r6i. 8xlarge?region=us-west-1, 2023
work page 2023
-
[6]
Aws x2idn.24xlarge instance cost
aws. Aws x2idn.24xlarge instance cost. https://instances.vantage.sh/aws/ec2/ x2idn.24xlarge?region=us-west-1, 2023
work page 2023
-
[7]
Itemsage: Learning product embeddings for shopping rec- ommendations at pinterest
Paul Baltescu, Haoyu Chen, Nikil Pancha, Andrew Zhai, Jure Leskovec, and Charles Rosenberg. Itemsage: Learning product embeddings for shopping rec- ommendations at pinterest. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2703–2711, 2022
work page 2022
-
[8]
Linr: Model based neural retrieval on gpus at linkedin
Fedor Borisyuk, Qingquan Song, Mingzhou Zhou, Ganesh Parameswaran, Madhu Arun, Siva Popuri, Tugrul Bingol, Zhuotao Pei, Kuang-Hsuan Lee, Lu Zheng, et al. Linr: Model based neural retrieval on gpus at linkedin. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 4366–4373, 2024
work page 2024
-
[9]
Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual web search engine.Computer networks and ISDN systems, 30(1-7):107–117, 1998
work page 1998
-
[10]
Scalability and efficiency chal- lenges in large-scale web search engines
B Barla Cambazoglu and Ricardo Baeza-Yates. Scalability and efficiency chal- lenges in large-scale web search engines. InProceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, pages 1223–1226, 2016
work page 2016
-
[11]
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. Spann: Highly-efficient billion-scale approximate nearest neighborhood search.Advances in Neural Information Processing Systems, 34:5199–5212, 2021
work page 2021
-
[12]
Deep neural networks for youtube recommendations
Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems, pages 191–198, 2016
work page 2016
-
[13]
Retrieval with learned similarities
Bailu Ding and Jiaqi Zhai. Retrieval with learned similarities. InProceedings of the ACM on Web Conference 2025, pages 1626–1637, 2025
work page 2025
-
[14]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. The faiss library. 2024
work page 2024
-
[15]
Compiling machine learning programs via high-level tracing
Roy Frostig, Matthew James Johnson, and Chris Leary. Compiling machine learning programs via high-level tracing. InSysML conference 2018, 2019
work page 2018
-
[16]
github. Faiss on the gpu limitations. https://github.com/facebookresearch/faiss/ wiki/Faiss-on-the-GPU#limitations, 2023
work page 2023
-
[17]
Bitfunnel: Revisiting signatures for search
Bob Goodwin, Michael Hopcroft, Dan Luu, Alex Clemmer, Mihaela Curmei, Sameh Elnikety, and Yuxiong He. Bitfunnel: Revisiting signatures for search. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 605–614, 2017
work page 2017
-
[18]
Embedding-based retrieval in facebook search
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. Embedding-based retrieval in facebook search. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2553–2561, 2020
work page 2020
-
[19]
Torchrec: a pytorch domain library for recommendation systems
Dmytro Ivchenko, Dennis Van Der Staay, Colin Taylor, Xing Liu, Will Feng, Rahul Kindi, Anirudh Sudarshan, and Shahin Sefati. Torchrec: a pytorch domain library for recommendation systems. InProceedings of the 16th ACM Conference on Recommender Systems, pages 482–483, 2022
work page 2022
-
[20]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. Diskann: Fast accurate billion-point nearest neighbor search on a single node.Advances in neural information processing Systems, 32, 2019
work page 2019
-
[21]
Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2019
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2019
work page 2019
-
[22]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[23]
Yu A Malkov and Dmitry A Yashunin. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transac- tions on pattern analysis and machine intelligence, 42(4):824–836, 2018
work page 2018
-
[24]
Milvus. Milvus gpu limitations. https://milvus.io/docs/gpu_index.md, 2023
work page 2023
-
[25]
Ray: A distributed framework for emerging {AI} applications
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, et al. Ray: A distributed framework for emerging {AI} applications. In13th USENIX symposium on operating systems design and implementation (OSDI 18), pages 561–577, 2018
work page 2018
-
[26]
Software-hardware co-design for fast and scalable training of deep learning recommendation models
Dheevatsa Mudigere, Yuchen Hao, Jianyu Huang, Zhihao Jia, Andrew Tulloch, Srinivas Sridharan, Xing Liu, Mustafa Ozdal, Jade Nie, Jongsoo Park, et al. Software-hardware co-design for fast and scalable training of deep learning recommendation models. InProceedings of the 49th Annual International Sympo- sium on Computer Architecture, pages 993–1011, 2022
work page 2022
-
[27]
Deep Learning Recommendation Model for Personalization and Recommendation Systems
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole- Jean Wu, Alisson G Azzolini, et al. Deep learning recommendation model for personalization and recommendation systems.arXiv preprint arXiv:1906.00091, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[28]
Merlin: a gpu accelerated recommendation framework
Even Oldridge, Julio Perez, Ben Frederickson, Nicolas Koumchatzky, Minseok Lee, Zehuan Wang, Lei Wu, Fan Yu, Rick Zamora, Onur Yilmaz, et al. Merlin: a gpu accelerated recommendation framework. InProceedings of IRS, 2020
work page 2020
-
[29]
Weston Pace, Chang She, Lei Xu, Will Jones, Albert Lockett, Jun Wang, and Raunak Shah. Lance: Efficient random access in columnar storage through adaptive structural encodings.arXiv preprint arXiv:2504.15247, 2025
-
[30]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A Paszke. Pytorch: An imperative style, high-performance deep learning library. arXiv preprint arXiv:1912.01703, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[31]
Manas hnsw realtime: Powering realtime embedding-based re- trieval
Pinterest. Manas hnsw realtime: Powering realtime embedding-based re- trieval. https://medium.com/pinterest-engineering/manas-hnsw-realtime- powering-realtime-embedding-based-retrieval-dc71dfd6afdd, 2023
work page 2023
-
[32]
Rapidsai. Rapidsai/raft: Raft contains fundamental widely-used algorithms and primitives for data science, graph and machine learning., 2022. URL https: //github.com/rapidsai/raft
work page 2022
-
[33]
Milvus: A purpose-built vector data management system
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. Milvus: A purpose-built vector data management system. InProceedings of the 2021 Inter- national Conference on Management of Data, pages 2614–2627, 2021
work page 2021
-
[34]
Billion-scale commodity embedding for e-commerce recommendation in alibaba
Jizhe Wang, Pipei Huang, Huan Zhao, Zhibo Zhang, Binqiang Zhao, and Dik Lun Lee. Billion-scale commodity embedding for e-commerce recommendation in alibaba. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 839–848, 2018
work page 2018
-
[35]
Sampling-bias-corrected neural modeling for large corpus item recommendations
Xinyang Yi, Ji Yang, Lichan Hong, Derek Zhiyuan Cheng, Lukasz Heldt, Aditee Kumthekar, Zhe Zhao, Li Wei, and Ed Chi. Sampling-bias-corrected neural modeling for large corpus item recommendations. InProceedings of the 13th ACM conference on recommender systems, pages 269–277, 2019
work page 2019
-
[36]
Learning a unified embedding for visual search at pinterest
Andrew Zhai, Hao-Yu Wu, Eric Tzeng, Dong Huk Park, and Charles Rosenberg. Learning a unified embedding for visual search at pinterest. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2412–2420, 2019
work page 2019
-
[37]
Revisiting neural retrieval on accelerators
Jiaqi Zhai, Zhaojie Gong, Yueming Wang, Xiao Sun, Zheng Yan, Fu Li, and Xing Liu. Revisiting neural retrieval on accelerators. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5520–5531, 2023
work page 2023
-
[38]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. Actions speak louder than words: Trillion- parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Wukong: Towards a scaling law for large-scale recommendation.arXiv preprint arXiv:2403.02545, 2024
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Daifeng Guo, Yanli Zhao, Shen Li, Yuchen Hao, Yantao Yao, et al. Wukong: Towards a scaling law for large-scale recommendation.arXiv preprint arXiv:2403.02545, 2024
-
[40]
Embedding in recommender systems: A survey.arXiv preprint arXiv:2310.18608, 2023
Xiangyu Zhao, Maolin Wang, Xinjian Zhao, Jiansheng Li, Shucheng Zhou, Dawei Yin, Qing Li, Jiliang Tang, and Ruocheng Guo. Embedding in recommender systems: A survey.arXiv preprint arXiv:2310.18608, 2023. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.