SPEAR-1: Scaling Beyond Robot Demonstrations via 3D Understanding
Pith reviewed 2026-05-17 20:17 UTC · model grok-4.3
The pith
A robot foundation model matches leaders using 20 times fewer demonstrations by adding 3D perception from ordinary images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
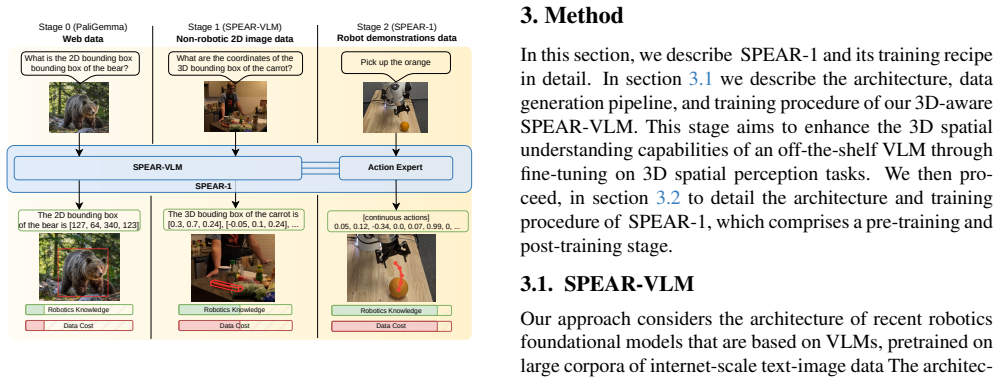
The paper presents SPEAR-1, a robotic foundation model that combines grounded 3D perception with language-instructed embodied control. It starts by training SPEAR-VLM on non-robotic images augmented with 3D annotations to infer object coordinates in 3D space. Then SPEAR-1 is trained on approximately 45 million frames from 24 Open X-Embodiment datasets, achieving performance that matches or surpasses state-of-the-art models while requiring 20 times fewer robot demonstrations.
What carries the argument
SPEAR-VLM, a 3D-aware vision-language model that infers object coordinates in 3D space from a single 2D image and serves as the foundation for the robot controller.
If this is right
- Embodied control becomes more reliable when the underlying perception includes explicit 3D spatial understanding.
- Scaling robot learning no longer requires proportional increases in expensive robot demonstration data.
- Models can leverage abundant public image datasets to bootstrap capabilities needed for physical tasks.
- Performance on language-instructed tasks improves across different environments and robot types.
Where Pith is reading between the lines
- Future work could test whether the same 3D enrichment helps in non-language tasks like pure visual navigation.
- Combining this with other data sources such as video might further reduce the need for robot trials.
- Deployment on real robots could reveal whether the 3D reasoning helps in dynamic or cluttered scenes specifically.
Load-bearing premise
3D spatial reasoning learned from annotated everyday images will transfer to make language-guided robot actions more reliable and general.
What would settle it
Running SPEAR-1 and a version without the 3D VLM component on the same set of new robot tasks and seeing if the 3D version shows no advantage in success rate or generalization.
Figures





read the original abstract
Robotic Foundation Models (RFMs) hold great promise as generalist, end-to-end systems for robot control. Yet their ability to generalize across new environments, tasks, and embodiments remains limited. We argue that a major bottleneck lies in their foundations: most RFMs are built by fine-tuning internet-pretrained Vision-Language Models (VLMs). However, these VLMs are trained on 2D image-language tasks and lack the 3D spatial reasoning inherently required for embodied control in the 3D world. Bridging this gap directly with large-scale robotic data is costly and difficult to scale. Instead, we propose to enrich easy-to-collect non-robotic image data with 3D annotations and enhance a pretrained VLM with 3D understanding capabilities. Following this strategy, we train SPEAR-VLM, a 3D-aware VLM that infers object coordinates in 3D space from a single 2D image. Building on SPEAR-VLM, we introduce our main contribution, $~\textbf{SPEAR-1}$: a robotic foundation model that integrates grounded 3D perception with language-instructed embodied control. Trained on $\sim$45M frames from 24 Open X-Embodiment datasets, SPEAR-1 outperforms or matches state-of-the-art models such as $\pi_0$-FAST and $\pi_{0.5}$, while it uses 20$\times$ fewer robot demonstrations. This carefully-engineered training strategy unlocks new VLM capabilities and as a consequence boosts the reliability of embodied control beyond what is achievable with only robotic data. We make our model weights and 3D-annotated datasets publicly available at https://spear.insait.ai.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPEAR-1, a robotic foundation model that first trains SPEAR-VLM on 3D-annotated non-robotic images to acquire spatial reasoning, then integrates this into a policy trained on approximately 45M frames from 24 Open X-Embodiment datasets. The central claim is that this yields performance matching or exceeding baselines such as π₀-FAST and π₀.₅ while requiring 20× fewer robot demonstrations, by addressing the 2D limitation of standard VLMs for embodied 3D control.
Significance. If the performance gains are shown to stem specifically from the 3D transfer rather than confounding factors, the approach would offer a scalable path to reduce reliance on expensive robot data for generalist policies, with potential impact on data-efficient robot learning.
major comments (2)
- [Experimental section] Experimental section (and associated tables/figures): the headline result that SPEAR-1 matches or exceeds π₀-FAST and π₀.₅ with 20× fewer demonstrations is not supported by a controlled ablation that holds robot data volume, architecture, and training recipe fixed while varying only the VLM backbone (SPEAR-VLM vs. a standard VLM). Without this isolation, the observed delta cannot be attributed to 3D spatial reasoning acquired from non-robotic annotations.
- [§3 and §4] §3 and §4: the integration of SPEAR-VLM into the robot policy is described at a high level, but no quantitative metrics, baseline details, ablation studies, or error analysis are referenced in the provided abstract or summary; the full experimental results must be examined to verify whether the data support the 20× data-efficiency claim.
minor comments (2)
- [Abstract] Abstract: the notation $~textbf{SPEAR-1}$ contains a stray tilde and inconsistent bolding; standardize to SPEAR-1 throughout.
- [Abstract] The link to model weights and datasets is provided, which is a positive for reproducibility; ensure the 3D-annotated datasets are clearly documented with annotation protocol and coverage statistics.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of experimental rigor. We respond to each major comment below and outline planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experimental section] Experimental section (and associated tables/figures): the headline result that SPEAR-1 matches or exceeds π₀-FAST and π₀.₅ with 20× fewer demonstrations is not supported by a controlled ablation that holds robot data volume, architecture, and training recipe fixed while varying only the VLM backbone (SPEAR-VLM vs. a standard VLM). Without this isolation, the observed delta cannot be attributed to 3D spatial reasoning acquired from non-robotic annotations.
Authors: We agree that isolating the VLM backbone while holding robot data volume, architecture, and training recipe fixed would strengthen attribution of gains to the 3D spatial reasoning. Our existing results compare against models trained on substantially larger robot datasets, supporting the overall data-efficiency claim. To directly address the concern, we will add a controlled ablation in the revised manuscript training an otherwise identical policy with a standard VLM backbone on the same ~45M frames. revision: yes
-
Referee: [§3 and §4] §3 and §4: the integration of SPEAR-VLM into the robot policy is described at a high level, but no quantitative metrics, baseline details, ablation studies, or error analysis are referenced in the provided abstract or summary; the full experimental results must be examined to verify whether the data support the 20× data-efficiency claim.
Authors: Sections 3 and 4 of the full manuscript contain the detailed integration architecture, quantitative success-rate metrics across tasks, baseline comparisons (including π₀-FAST and π₀.₅), ablation studies on the 3D components, and error analysis. The abstract summarizes the headline result; the 20× data-efficiency claim is supported by explicit data-volume comparisons in the experiments. We will add cross-references and a brief summary table in the revision to make these elements more immediately visible. revision: partial
Circularity Check
No circularity in the derivation chain
full rationale
The paper trains SPEAR-VLM on independently 3D-annotated non-robotic images to acquire spatial reasoning, then integrates the resulting backbone into SPEAR-1, which is trained on the public Open X-Embodiment robot datasets (~45 M frames). The headline performance claim (matching or exceeding π₀-FAST and π₀.₅ with 20× fewer demonstrations) is an empirical comparison against externally published baselines. No equation, training objective, or cited premise reduces the claimed 3D-transfer benefit or data-efficiency gain to a self-definition, a fitted parameter renamed as prediction, or a self-citation chain. The derivation therefore remains self-contained against external data and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3D coordinate annotations can be reliably generated and added to large-scale non-robotic image collections
invented entities (2)
-
SPEAR-VLM
no independent evidence
-
SPEAR-1
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We argue that a major bottleneck lies in their foundations: most RFMs are built by fine-tuning internet-pretrained Vision-Language Models (VLMs). However, these VLMs are trained on 2D image-language tasks and lack the 3D spatial reasoning inherently required for embodied control in the 3D world.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Flamingo: a Visual Language Model for Few-Shot Learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, An- toine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Se- bastian Borgeaud, Andy Brock, Aida Nematzadeh, Sa- hand Sharifzadeh, Mikolaj Binkow...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Roboarena: Distributed real- world evaluation of generalist robot policies
Pranav Atreya, Karl Pertsch, Tony Lee, Moo Jin Kim, Arhan Jain, Artur Kuramshin, Clemens Eppner, Cyrus Neary, Ed- ward Hu, Fabio Ramos, et al. Roboarena: Distributed real- world evaluation of generalist robot policies. InProceedings of the Conference on Robot Learning (CoRL 2025), 2025. 2, 16
work page 2025
-
[3]
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.arXiv preprint arXiv:2507.05331,
-
[4]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, Andr ´e Susano Pinto, Alexan- der Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, Thomas Unterthiner, Daniel Keysers, Skanda Koppula, Fangyu Liu, Adam Grycner, Alexey Gritsenko, Neil Houlsby, Manoj Kumar, Keran Rong, Julian Eisensch- los, Rishabh Kabra, Matthi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.pi 0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 3, 4, 8, 14, 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Kevin Black, Noah Brown, James Darpinian, Karan Dha- balia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Re...
work page 2025
-
[7]
Spatialbot: Precise spatial understanding with vision lan- guage models,
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. arXiv preprint arXiv:2406.13642, 2024. 2
-
[8]
Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 14455–14465,
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Sombit Dey, Jan-Nico Zaech, Nikolay Nikolov, Luc Van Gool, and Danda Pani Paudel. Revla: Reverting vi- sual domain limitation of robotic foundation models.arXiv preprint arXiv:2409.15250, 2024. 3, 5
-
[11]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duck- worth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: An embodie...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Learning with 3d rotations, a hitch- hiker’s guide to SO(3)
Andreas Ren ´e Geist, Jonas Frey, Mikel Zhobro, Anna Lev- ina, and Georg Martius. Learning with 3d rotations, a hitch- hiker’s guide to SO(3). InForty-first International Confer- ence on Machine Learning, 2024. 5
work page 2024
-
[13]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
work page 2024
-
[14]
Rotation averaging.International journal of computer vision, 103(3):267–305, 2013
Richard Hartley, Jochen Trumpf, Yuchao Dai, and Hongdong Li. Rotation averaging.International journal of computer vision, 103(3):267–305, 2013. 5
work page 2013
-
[15]
Initializing new word embeddings for pretrained language models.https : / / www
John Hewitt. Initializing new word embeddings for pretrained language models.https : / / www . cs . columbia . edu /˜johnhew / vocab - expansion . html. 13
-
[16]
Huggingface transformers documen- tation.https : / / huggingface
HuggingFace. Huggingface transformers documen- tation.https : / / huggingface . co / docs / transformers/en/main_classes/model. 13
-
[17]
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic 9 vlms: Investigating the design space of visually-conditioned language models.arXiv preprint arXiv:2402.07865, 2024. 2, 3
-
[18]
Droid: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Bal- akrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Sys- tems, 2024. 6, 7, 8, 15, 16
work page 2024
-
[19]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 2, 3, 5, 7, 8, 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
MolmoAct: Action Reasoning Models that can Reason in Space
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision- language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024. 5, 6, 7, 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Flow matching for genera- tive modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maxim- ilian Nickel, and Matthew Le. Flow matching for genera- tive modeling. InThe Eleventh International Conference on Learning Representations, 2023. 4
work page 2023
-
[24]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez- Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code.arXiv preprint arXiv:2412.06264, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems, pages 34892–34916. Curran Associates, Inc., 2023. 3, 4
work page 2023
-
[26]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024. 2
work page 2024
-
[27]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024. 3
work page 2024
-
[28]
Rectified Flow: A Marginal Preserving Approach to Optimal Transport
Qiang Liu. Rectified flow: A marginal preserving approach to optimal transport.arXiv preprint arXiv:2209.14577, 2022. 4
work page internal anchor Pith review arXiv 2022
-
[29]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 12
work page 2021
-
[31]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and...
work page 2024
-
[32]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Abhishek Padalkar, Acorn Pooley, Ajinkya Jain, Alex Bew- ley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anikait Singh, Anthony Brohan, et al. Open x- embodiment: Robotic learning datasets and rt-x models. arXiv preprint arXiv:2310.08864, 2023. 3, 6, 8, 15
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision- language-action models.arXiv preprint arXiv:2501.09747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Introducing gemini 2.0: our new ai model for the agentic era
Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu. Introducing gemini 2.0: our new ai model for the agentic era. https : / / blog . google / technology / google - deepmind / google - gemini - ai - update - december-2024/. 3
work page 2024
-
[35]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial represen- tations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025. 2, 3, 7, 12, 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 4, 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Grounded sam: Assembling open-world models for diverse visual tasks,
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks,
-
[38]
FLOWER: Democratizing generalist robot policies with efficient vision- language-action flow policies
Moritz Reuss, Hongyi Zhou, Marcel R ¨uhle, ¨Omer Erdinc ¸ Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. FLOWER: Democratizing generalist robot policies with efficient vision- language-action flow policies. In7th Robot Learning Work- shop: Towards Robots with Human-Level Abilities, 2025. 15, 16
work page 2025
-
[39]
Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 15768–15780, 2025. 2
work page 2025
-
[40]
Generalist robot ma- 10 nipulation beyond action labeled data
Alexander Spiridonov, Jan-Nico Zaech, Nikolay Nikolov, Luc Van Gool, and Danda Pani Paudel. Generalist robot ma- 10 nipulation beyond action labeled data. In9th Annual Con- ference on Robot Learning, 2025. 2, 15
work page 2025
-
[41]
PaliGemma 2: A Family of Versatile VLMs for Transfer
Andreas Steiner, Andr ´e Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey Grit- senko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, et al. Paligemma 2: A family of versatile vlms for transfer.arXiv preprint arXiv:2412.03555, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi `ere, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and tech- nology.arXiv preprint arXiv:2403.08295, 2024. 3, 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Ta- tiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Are- nas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Bridgedata v2: A dataset for robot learning at scale
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen- Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale. InProceedings of the Conference on Robot Learning (CoRL), 2023. 4, 6, 7, 8, 13, 14, 15
work page 2023
-
[46]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision.arXiv preprint arXiv:2410.19115, 2024. 2, 3, 4, 13
-
[48]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 3
work page 2024
-
[49]
Robotic control via em- bodied chain-of-thought reasoning
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via em- bodied chain-of-thought reasoning. In8th Annual Confer- ence on Robot Learning, 2024. 15
work page 2024
-
[50]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023. 3
work page 2023
-
[51]
Cot-vla: Visual chain-of-thought rea- soning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought rea- soning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025. 15, 16
work page 2025
-
[52]
Open3D: A Modern Library for 3D Data Processing
Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. Open3D: A modern library for 3D data processing.arXiv:1801.09847,
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Sanketi, Grecia Salazar, Michael S
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, Quan Vuong, Vincent Vanhoucke, Huong Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R. Sanketi, Grecia Salazar, Michael S. Ryoo, Krista Reymann, Kanishka Rao, Karl Pertsch, Igor Mordatch, Henryk Michalewski...
-
[54]
Appendix The appendix is organized as follows: • In Sec
3 11 A. Appendix The appendix is organized as follows: • In Sec. A.1 we provide more details on the VLM pre- training including VQA tasks, encoder fusion strategies, 3D tokenization and data annotation pipeline. • In Sec. A.2 we provide more details on the VLA training including data mixture, architecture, flow matching and design decision ablation result...
-
[55]
Concatenating the visual features predicted by both en- coders and projecting them via a linear layer to the LLM embedding space. In particular, for SigLIP we take only the tokens at the last layer of the vision encoder, while for MoGe we take the tokens at the last 4 layers of the encoder, following the approach used by MoGe architec- ture to decode the ...
-
[56]
Using MoGe’s predicted 3D point cloudPin the camera ego pose (in an affine-invariant space) and adding them to the SigLIP encoder features, similar to SpatialVLA [35]. In particular, MoGe’s 3D point cloud outputP∈R H×W×3 is embedded toP ′ ∈R h×w×d through a projectorψ(·), composed of normaliza- tion, convolution, sinusoidal embeddingγ(x) = (x,sin(2 0πx),c...
-
[57]
and an MLP. Finally, the featuresF ′ =F+P ′ are fed to PaliGemma’s SigLIP linear projector, where F∈R h×w×d denotes the features at the SigLIP encoder output. During our preliminary VLM evaluations we found the first strategy to demonstrate qualitatively better perfor- mance on bounding box prediction tasks. In particular, models trained with the second a...
work page 2048
-
[58]
and deploying on the WidowX robot in environments close to the training distribution. Bridge V2, however, is not very diverse in the number of environments, objects, 15 and camera viewpoints. As a result, we observe that models pre-trained on Bridge V2 only perform well on WidowX environments when the deployment scenario is similar to what is seen in the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.