TRANSPORTER: Transferring Visual Semantics from VLM Manifolds
Pith reviewed 2026-05-17 05:56 UTC · model grok-4.3
The pith
TRANSPORTER learns an optimal transport map from VLM embedding spaces to text-to-video generators so that logit scores steer the creation of videos showing the visual rules behind model predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
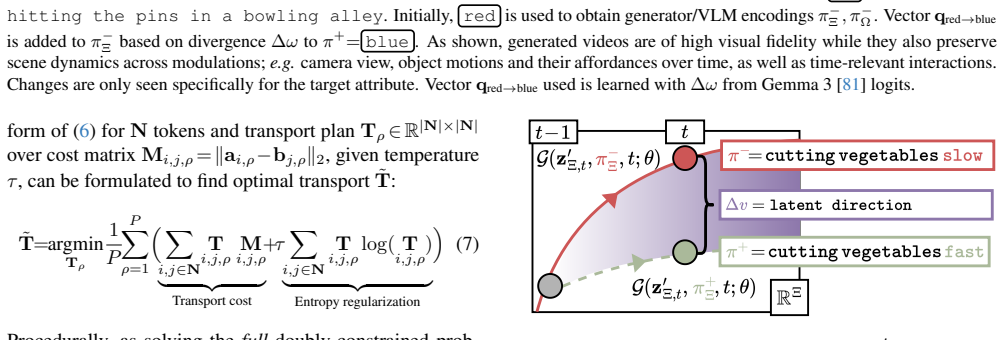
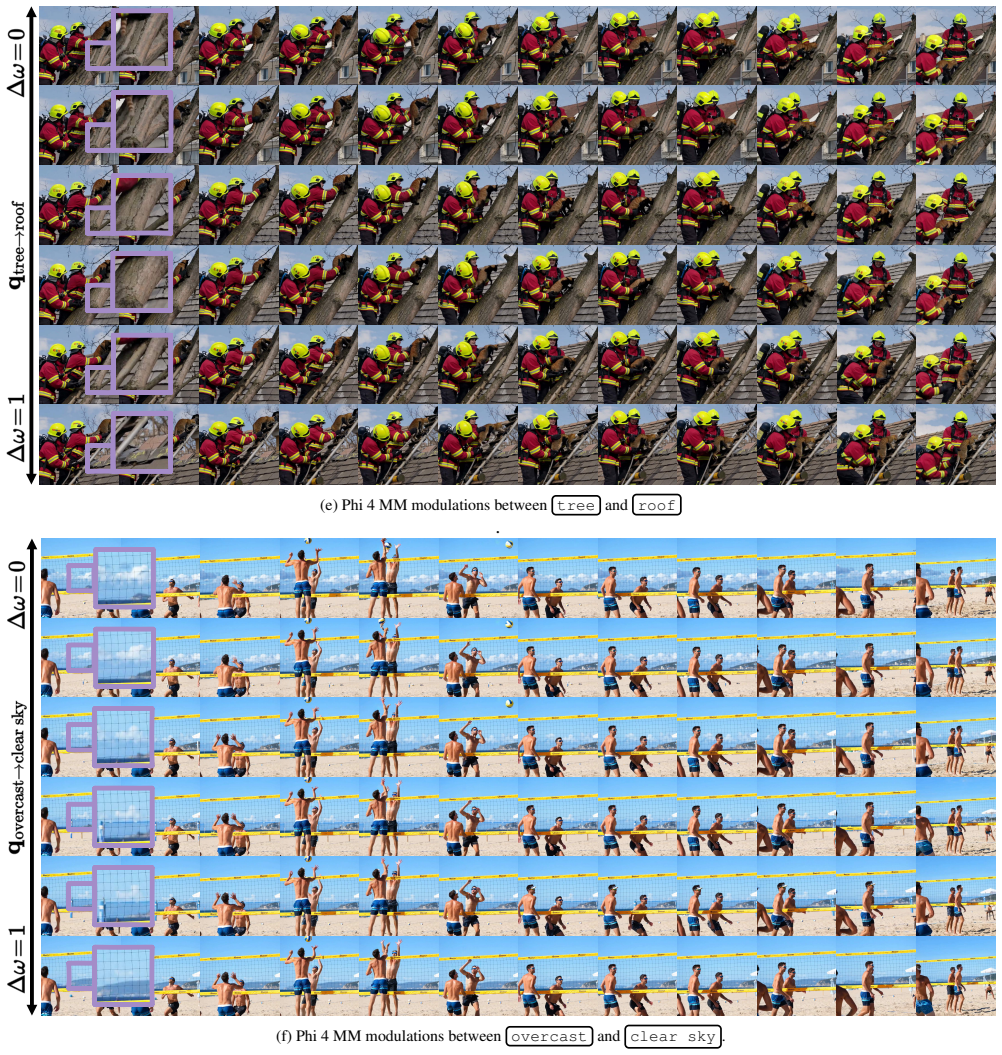
Given a VLM and a text-to-video model, TRANSPORTER learns an optimal transport coupling between the VLM's high-semantic embedding space and the conditioning space of the generative model; logit scores then define embedding directions that drive conditional video synthesis, producing videos whose content reflects caption variations over object attributes, action adverbs, and scene context.
What carries the argument
Optimal transport coupling between VLM high-semantic embedding spaces and the latent conditioning space of a text-to-video generative model, with logit scores supplying the transport directions.
If this is right
- Altering a single attribute in the input caption produces a corresponding visual change in the generated video that can be inspected to understand which visual cues the VLM used.
- The same coupling can be applied across multiple VLMs to compare how different models encode the same scene elements.
- Logit-driven video generation supplies a new form of interpretability that operates at the level of full visual sequences rather than attention maps or feature visualizations.
- The method is model-independent once the transport map is learned, allowing reuse with any VLM whose embeddings can be extracted.
Where Pith is reading between the lines
- If the transport map generalizes across different T2V backbones, it could become a standard post-hoc inspection tool for any caption-conditioned vision model.
- The generated videos could serve as training data for further alignment between generative models and the semantic distinctions learned by VLMs.
- Extending the coupling to video-to-video translation might allow direct editing of real footage to match VLM decision boundaries.
Load-bearing premise
The learned optimal transport coupling will faithfully capture and transfer the underlying rules that produce the VLM's logit predictions.
What would settle it
Generate videos for a fixed set of caption variants that produce known logit shifts in the VLM; if the visual differences in the videos do not align with the magnitude or direction of those logit shifts under controlled human or automated evaluation, the transport map has failed to transfer the decision rules.
Figures


















read the original abstract
How do video understanding models acquire their answers? Although current Vision Language Models (VLMs) reason over complex scenes with diverse objects, action performances, and scene dynamics, understanding and controlling their internal processes remains an open challenge. Motivated by recent advancements in text-to-video (T2V) generative models, this paper introduces a logits-to-video (L2V) task alongside a model-independent approach, TRANSPORTER, to generate videos that capture the underlying rules behind VLMs' predictions. Given the high-visual-fidelity produced by T2V models, TRANSPORTER learns an optimal transport coupling to VLM's high-semantic embedding spaces. In turn, logit scores define embedding directions for conditional video generation. TRANSPORTER generates videos that reflect caption changes over diverse object attributes, action adverbs, and scene context. Quantitative and qualitative evaluations across VLMs demonstrate that L2V can provide a fidelity-rich, novel direction for model interpretability that has not been previously explored.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TRANSPORTER for a logits-to-video (L2V) task. It learns an optimal transport coupling between high-semantic embedding spaces of VLMs and text-to-video (T2V) generative models; logit scores then define directions for conditional video generation. The resulting videos are claimed to reflect caption changes over object attributes, action adverbs, and scene context, with quantitative and qualitative evaluations across VLMs supporting a novel interpretability direction.
Significance. If the transport mapping holds, the work offers a high-fidelity generative route to VLM interpretability that has not been previously explored, leveraging T2V priors to visualize internal prediction rules. This could meaningfully advance understanding of how VLMs reason over complex video scenes.
major comments (2)
- [§3] §3 (Optimal Transport Coupling): The central claim requires that the OT plan, when conditioned on logit scores, produces videos whose changes faithfully reflect the specific rules or features driving VLM logit predictions. However, OT minimizes a global Wasserstein cost between manifolds and does not enforce local alignment with the VLM's decision boundary or attribution; if manifold curvature differs or the T2V prior injects unrelated factors, the generated videos may be plausible yet misaligned with the VLM's actual reasoning. A concrete verification (e.g., controlled ablation on known decision features) is needed.
- [§5] §5 (Quantitative Evaluation): The abstract states that evaluations 'demonstrate' the L2V approach, yet no specific metrics, baselines, statistical tests, or effect sizes are referenced in the description of results. Without these, it is impossible to assess whether the transport mapping outperforms simpler alternatives or supports the fidelity-rich interpretability claim.
minor comments (2)
- [§3] Notation for the embedding spaces, cost function, and conditioning on logits should be introduced with a single consistent diagram early in the method section to aid readability.
- [Abstract] The abstract claims results 'across VLMs' but does not name the specific models or datasets used; this detail belongs in the abstract or a dedicated table.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We address each major comment point by point below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Optimal Transport Coupling): The central claim requires that the OT plan, when conditioned on logit scores, produces videos whose changes faithfully reflect the specific rules or features driving VLM logit predictions. However, OT minimizes a global Wasserstein cost between manifolds and does not enforce local alignment with the VLM's decision boundary or attribution; if manifold curvature differs or the T2V prior injects unrelated factors, the generated videos may be plausible yet misaligned with the VLM's actual reasoning. A concrete verification (e.g., controlled ablation on known decision features) is needed.
Authors: We agree that the global nature of optimal transport does not inherently guarantee local alignment with VLM decision boundaries, and that manifold differences or T2V priors could introduce misalignments. Our current evidence relies on qualitative demonstrations where logit-driven shifts produce videos reflecting targeted attribute, action, and scene changes across VLMs. To provide the requested concrete verification, we will add a controlled ablation study in the revised manuscript: we will intervene on known VLM decision features (e.g., by altering specific object attributes in input frames) and measure the fidelity of corresponding changes in the generated videos under the OT coupling. revision: yes
-
Referee: [§5] §5 (Quantitative Evaluation): The abstract states that evaluations 'demonstrate' the L2V approach, yet no specific metrics, baselines, statistical tests, or effect sizes are referenced in the description of results. Without these, it is impossible to assess whether the transport mapping outperforms simpler alternatives or supports the fidelity-rich interpretability claim.
Authors: We acknowledge that the results description would benefit from greater explicitness on quantitative aspects. While the manuscript includes quantitative evaluations across VLMs in §5, we will revise this section to explicitly detail the metrics (e.g., semantic consistency and generation fidelity measures), baselines compared, statistical tests applied, and effect sizes observed. This will allow readers to better evaluate the transport mapping's performance relative to alternatives. revision: yes
Circularity Check
No circularity: method uses external OT and T2V without self-referential reduction
full rationale
The derivation introduces TRANSPORTER as an optimal transport coupling between VLM embeddings and T2V generative latents, with logit scores used to define directions for conditional generation. No equations, fitted parameters, or self-citations in the abstract reduce the generated videos or interpretability claims to inputs defined by the same data or prior author work. The L2V task and evaluations rely on external models and standard OT, remaining self-contained and falsifiable against independent benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TRANSPORTER learns an optimal transport coupling to VLM’s high-semantic embedding spaces... ρ-OT uses {p_Ω1,ρ} and {p_Ω2,ρ} sets of P learnable projection vectors... min_γρ ∫ M dγρ − τ ∫ γρ log(γρ)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
logit difference Δω computed using Hellinger distance... concept bank Q = {q_o : o ∈ O}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harri- son, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv:2412.08905, 2024. 1, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkin- son, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, et al. Phi-4-mini technical report: Compact yet pow- erful multimodal language models via mixture-of-loras. arXiv:2503.01743, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Getting vit in shape: Scaling laws for compute-optimal model design.NeurIPS, 2023
Ibrahim M Alabdulmohsin, Xiaohua Zhai, Alexander Kolesnikov, and Lucas Beyer. Getting vit in shape: Scaling laws for compute-optimal model design.NeurIPS, 2023. 1
work page 2023
-
[4]
Building nor- malizing flows with stochastic interpolants.ICLR, 2023
Michael S Albergo and Eric Vanden-Eijnden. Building nor- malizing flows with stochastic interpolants.ICLR, 2023. 2
work page 2023
-
[5]
Re- fusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Re- fusal in language models is mediated by a single direction. NeurIPS, 2024. 1
work page 2024
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wen- bin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv:2502.13923, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Network dissection: Quantifying inter- pretability of deep visual representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying inter- pretability of deep visual representations. InCVPR, 2017. 2
work page 2017
-
[8]
Continuous, subject-specific attribute control in t2i models by identifying semantic directions
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Melvin Sevi, Vincent Tao Hu, and Björn Om- mer. Continuous, subject-specific attribute control in t2i models by identifying semantic directions. InCVPR, 2025. 2, 4, 6
work page 2025
-
[9]
Legrad: An explain- ability method for vision transformers via feature formation sensitivity
Walid Bousselham, Angie Boggust, Sofian Chaybouti, Hendrik Strobelt, and Hilde Kuehne. Legrad: An explain- ability method for vision transformers via feature formation sensitivity. InICCV, 2025. 2
work page 2025
-
[10]
Labeling neural representations with inverse recognition
Kirill Bykov, Laura Kopf, Shinichi Nakajima, Marius Kloft, and Marina Höhne. Labeling neural representations with inverse recognition. InNeurIPS, 2023. 2
work page 2023
-
[11]
Unsupervised learn- ing of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learn- ing of visual features by contrasting cluster assignments. NeurIPS, 2020. 3
work page 2020
-
[12]
Grad-CAM++: General- ized gradient-based visual explanations for deep convolu- tional networks
Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad-CAM++: General- ized gradient-based visual explanations for deep convolu- tional networks. InWACV, 2018. 2
work page 2018
-
[13]
Generic attention- model explainability for interpreting bi-modal and encoder- decoder transformers
Hila Chefer, Shir Gur, and Lior Wolf. Generic attention- model explainability for interpreting bi-modal and encoder- decoder transformers. InICCV, 2021. 2
work page 2021
-
[14]
Plot: Prompt learning with optimal transport for vision-language models.ICLR, 2023
Guangyi Chen, Weiran Yao, Xiangchen Song, Xinyue Li, Yongming Rao, and Kun Zhang. Plot: Prompt learning with optimal transport for vision-language models.ICLR, 2023. 2
work page 2023
-
[15]
Interpreting and controlling vision foundation models via text explanations.arXiv:2310.10591, 2023
Haozhe Chen, Junfeng Yang, Carl V ondrick, and Chengzhi Mao. Interpreting and controlling vision foundation models via text explanations.arXiv:2310.10591, 2023. 2
-
[16]
Selfie: self-interpretation of large language model embeddings
Haozhe Chen, Carl V ondrick, and Chengzhi Mao. Selfie: self-interpretation of large language model embeddings. In ICML, 2024. 1
work page 2024
-
[17]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodal- ity, long context, and next generation agentic capabilities. arXiv:2507.06261, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Fluxspace: Disentangled semantic editing in rectified flow models
Yusuf Dalva, Kavana Venkatesh, and Pinar Yanardag. Fluxspace: Disentangled semantic editing in rectified flow models. InCVPR, 2025. 3
work page 2025
-
[19]
Im- plicit inversion turns clip into a decoder.arXiv:2505.23161,
Antonio D’Orazio, Maria Rosaria Briglia, Donato Crisos- tomi, Dario Loi, Emanuele Rodolà, and Iacopo Masi. Im- plicit inversion turns clip into a decoder.arXiv:2505.23161,
-
[20]
An image is worth 16x16 words: Trans- formers for image recognition at scale.ICLR, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.ICLR, 2021. 5
work page 2021
-
[21]
Weakly supervised semantic segmentation by pixel-to-prototype contrast
Ye Du, Zehua Fu, Qingjie Liu, and Yunhong Wang. Weakly supervised semantic segmentation by pixel-to-prototype contrast. InCVPR, 2022. 2
work page 2022
-
[22]
Deep insights into convolutional net- works for video recognition.IJCV, 2020
Christoph Feichtenhofer, Axel Pinz, Richard P Wildes, and Andrew Zisserman. Deep insights into convolutional net- works for video recognition.IJCV, 2020. 2
work page 2020
-
[23]
Thomas Fel, Thibaut Boissin, Victor Boutin, Agustin Pi- card, Paul Novello, Julien Colin, Drew Linsley, Tom Rousseau, Rémi Cadène, Lore Goetschalckx, et al. Unlock- ing feature visualization for deep network with magnitude constrained optimization.NeurIPS, 2023. 2, 5, 6
work page 2023
-
[24]
A holistic approach to unifying automatic concept extraction and concept importance estimation
Thomas Fel, Victor Boutin, Louis Béthune, Rémi Cadène, Mazda Moayeri, Léo Andéol, Mathieu Chalvidal, and Thomas Serre. A holistic approach to unifying automatic concept extraction and concept importance estimation. In NeurIPS, 2023. 2
work page 2023
-
[25]
Craft: Concept recursive activation factor- ization for explainability
Thomas Fel, Agustin Picard, Louis Bethune, Thibaut Boissin, David Vigouroux, Julien Colin, Rémi Cadène, and Thomas Serre. Craft: Concept recursive activation factor- ization for explainability. InCVPR, 2023. 2
work page 2023
-
[26]
Interpretable explana- tions of black boxes by meaningful perturbation
Ruth C Fong and Andrea Vedaldi. Interpretable explana- tions of black boxes by meaningful perturbation. InICCV,
-
[27]
Stanislav Fort and Jonathan Whitaker. Direct ascent syn- thesis: Revealing hidden generative capabilities in discrim- inative models.arXiv:2502.07753, 2025. 2
-
[28]
Interpreting clip’s image representation via text-based de- composition
Yossi Gandelsman, Alexei A Efros, and Jacob Steinhardt. Interpreting clip’s image representation via text-based de- composition. InICLR, 2024. 2
work page 2024
-
[29]
Concept sliders: Lora adap- tors for precise control in diffusion models
Rohit Gandikota, Joanna Materzy ´nska, Tingrui Zhou, An- tonio Torralba, and David Bau. Concept sliders: Lora adap- tors for precise control in diffusion models. InECCV, 2024. 2
work page 2024
-
[30]
Image style transfer using convolutional neural networks
Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. InCVPR, 2016. 3
work page 2016
-
[31]
Plug-in inversion: Model-agnostic inversion for vision with data augmenta- tions
Amin Ghiasi, Hamid Kazemi, Steven Reich, Chen Zhu, Micah Goldblum, and Tom Goldstein. Plug-in inversion: Model-agnostic inversion for vision with data augmenta- tions. InICML, 2022. 2
work page 2022
-
[32]
Arcee’s mergekit: A toolkit for merging large language models
Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. Arcee’s mergekit: A toolkit for merging large language models. In EMNLP, 2024. 3
work page 2024
-
[33]
Boosting the visual interpretability of clip via adversarial fine-tuning
Shizhan Gong, LEI Haoyu, Qi Dou, and Farzan Farnia. Boosting the visual interpretability of clip via adversarial fine-tuning. InICLR, 2025. 2
work page 2025
-
[34]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In CVPR, 2022. 5
work page 2022
-
[35]
Uncovering unique concept vectors through latent space decomposition
Mara Graziani, Laura O’ Mahony, An-Phi Nguyen, Hen- ning Müller, and Vincent Andrearczyk. Uncovering unique concept vectors through latent space decomposition. TMLR, 2023. 2
work page 2023
-
[36]
Gradvit: Gradient inversion of vision transformers
Ali Hatamizadeh, Hongxu Yin, Holger R Roth, Wenqi Li, Jan Kautz, Daguang Xu, and Pavlo Molchanov. Gradvit: Gradient inversion of vision transformers. InCVPR, 2022. 2, 5, 6
work page 2022
-
[37]
Clip knows image aesthetics.FAI, 2022
Simon Hentschel, Konstantin Kobs, and Andreas Hotho. Clip knows image aesthetics.FAI, 2022. 6
work page 2022
-
[38]
Natu- ral language descriptions of deep visual features
Evan Hernandez, Sarah Schwettmann, David Bau, Teona Bagashvili, Antonio Torralba, and Jacob Andreas. Natu- ral language descriptions of deep visual features. InICLR,
-
[39]
In- specting and editing knowledge representations in language models.COLM, 2024
Evan Hernandez, Belinda Z Li, and Jacob Andreas. In- specting and editing knowledge representations in language models.COLM, 2024. 1
work page 2024
-
[40]
Prompt-to-prompt im- age editing with cross attention control.ICLR, 2023
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.ICLR, 2023. 2
work page 2023
-
[41]
Clipscore: A reference-free eval- uation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free eval- uation metric for image captioning. InEMNLP, 2021. 6
work page 2021
-
[42]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 2022. 2
work page 2022
-
[43]
Tianze Hua, Tian Yun, and Ellie Pavlick. How do vision- language models process conflicting information across modalities?arXiv:2507.01790, 2025. 2
-
[44]
MIMIC: Multimodal Inversion for Model Interpretation and Conceptualization
Animesh Jain and Alexandros Stergiou. Mimic: Multi- modal inversion for model interpretation and conceptual- ization.arXiv:2508.07833, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Pyramidal flow matching for efficient video generative modeling.ICLR, 2025
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling.ICLR, 2025. 2
work page 2025
-
[46]
Auto-encoding vari- ational bayes.ICLR, 2014
Diederik P Kingma and Max Welling. Auto-encoding vari- ational bayes.ICLR, 2014. 3
work page 2014
-
[47]
The sinkhorn–knopp algorithm: conver- gence and applications.SIMAX, 2008
Philip A Knight. The sinkhorn–knopp algorithm: conver- gence and applications.SIMAX, 2008. 1
work page 2008
-
[48]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InICML, 2020. 2
work page 2020
-
[49]
Matthew Kowal, Richard P Wildes, and Konstantinos G Derpanis. Visual concept connectome (vcc): Open world concept discovery and their interlayer connections in deep models. InCVPR, 2024. 2
work page 2024
-
[50]
Interpretable generative models through post-hoc concept bottlenecks
Akshay Kulkarni, Ge Yan, Chung-En Sun, Tuomas Oikari- nen, and Tsui-Wei Weng. Interpretable generative models through post-hoc concept bottlenecks. InCVPR, 2025. 2
work page 2025
-
[51]
Beyond concept bottleneck models: How to make black boxes intervenable?NeurIPS, 2024
Sonia Laguna, Ri ˇcards Marcinkeviˇcs, Moritz Vandenhirtz, and Julia V ogt. Beyond concept bottleneck models: How to make black boxes intervenable?NeurIPS, 2024. 2
work page 2024
-
[52]
Clearclip: De- composing clip representations for dense vision-language inference
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. Clearclip: De- composing clip representations for dense vision-language inference. InECCV, 2024. 2
work page 2024
-
[53]
Demystifying neural style transfer
Yanghao Li, Naiyan Wang, Jiaying Liu, and Xiaodi Hou. Demystifying neural style transfer. InIJCAI, 2017. 3
work page 2017
-
[54]
Towards visually explaining video understand- ing networks with perturbation
Zhenqiang Li, Weimin Wang, Zuoyue Li, Yifei Huang, and Yoichi Sato. Towards visually explaining video understand- ing networks with perturbation. InWACV, 2021. 2
work page 2021
-
[55]
Flow matching for generative modeling.ICLR, 2023
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maxim- ilian Nickel, and Matt Le. Flow matching for generative modeling.ICLR, 2023. 2
work page 2023
-
[56]
Decoupled weight decay regularization.ICLR, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.ICLR, 2019. 5
work page 2019
-
[57]
Dou- bly right object recognition: A why prompt for visual ratio- nales
Chengzhi Mao, Revant Teotia, Amrutha Sundar, Sachit Menon, Junfeng Yang, Xin Wang, and Carl V ondrick. Dou- bly right object recognition: A why prompt for visual ratio- nales. InCVPR, 2023. 2
work page 2023
-
[58]
Visual classification via description from large language models
Sachit Menon and Carl V ondrick. Visual classification via description from large language models. InICLR, 2023. 2
work page 2023
-
[59]
Text-to-concept (and back) via cross-model align- ment
Mazda Moayeri, Keivan Rezaei, Maziar Sanjabi, and Soheil Feizi. Text-to-concept (and back) via cross-model align- ment. InICML, 2023. 2
work page 2023
-
[60]
Gromov-wasserstein autoencoders
Nao Nakagawa, Ren Togo, Takahiro Ogawa, and Miki Haseyama. Gromov-wasserstein autoencoders. InICLR,
-
[61]
Synthesizing the preferred inputs for neurons in neural networks via deep generator networks
Anh Nguyen, Alexey Dosovitskiy, Jason Yosinski, Thomas Brox, and Jeff Clune. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. NeurIPS, 2016. 2
work page 2016
-
[62]
Anh Nguyen, Jason Yosinski, and Jeff Clune. Multifaceted feature visualization: Uncovering the different types of fea- tures learned by each neuron in deep neural networks. In ICMLw, 2016. 2
work page 2016
-
[63]
Zoom in: An in- troduction to circuits.Distill, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An in- troduction to circuits.Distill, 2020. 2
work page 2020
-
[64]
Sparse autoencoders learn monosemantic features in vision-language models
Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. Sparse autoencoders learn monosemantic features in vision-language models. NeurIPS, 2025. 2
work page 2025
-
[65]
Future lens: Anticipating subsequent to- kens from a single hidden state.CoNNL, 2023
Koyena Pal, Jiuding Sun, Andrew Yuan, Byron C Wallace, and David Bau. Future lens: Anticipating subsequent to- kens from a single hidden state.CoNNL, 2023. 1
work page 2023
-
[66]
Normalizing flows for probabilistic modeling and infer- ence.JMLR, 2021
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and infer- ence.JMLR, 2021. 2
work page 2021
-
[67]
Precisecontrol: En- hancing text-to-image diffusion models with fine-grained attribute control
Rishubh Parihar, VS Sachidanand, Sabariswaran Mani, Te- jan Karmali, and R Venkatesh Babu. Precisecontrol: En- hancing text-to-image diffusion models with fine-grained attribute control. InECCV, 2024. 2
work page 2024
-
[68]
Rise: Random- ized input sampling for explanation of black-box models
Vitali Petsiuk, Abir Das, and Kate Saenko. Rise: Random- ized input sampling for explanation of black-box models. InBMVC, 2018. 2
work page 2018
-
[69]
A novel sliced fused gromov-wasserstein distance.arXiv:2508.02364, 2025
Moritz Piening and Robert Beinert. A novel sliced fused gromov-wasserstein distance.arXiv:2508.02364, 2025. 3
-
[70]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 2
work page 2021
-
[71]
Learning important features through propagating activation differences
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. InICML, 2017. 2
work page 2017
-
[72]
What does clip know about a red circle? visual prompt engineering for vlms
Aleksandar Shtedritski, Christian Rupprecht, and Andrea Vedaldi. What does clip know about a red circle? visual prompt engineering for vlms. InICCV, 2023. 2
work page 2023
-
[73]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps.arXiv:1312.6034,
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Vlg-cbm: Training concept bottleneck models with vision-language guidance.NeurIPS, 2024
Divyansh Srivastava, Ge Yan, and Lily Weng. Vlg-cbm: Training concept bottleneck models with vision-language guidance.NeurIPS, 2024. 2
work page 2024
-
[75]
Lavib: A large-scale video interpola- tion benchmark
Alexandros Stergiou. Lavib: A large-scale video interpola- tion benchmark. InNeurIPS, 2024. 5
work page 2024
-
[76]
Leaping into memories: Space-time deep feature synthesis
Alexandros Stergiou and Nikos Deligiannis. Leaping into memories: Space-time deep feature synthesis. InICCV,
-
[77]
About time: Ad- vances, challenges, and outlooks of action understanding
Alexandros Stergiou and Ronald Poppe. About time: Ad- vances, challenges, and outlooks of action understanding. IJCV, 2025. 1
work page 2025
-
[78]
Saliency tubes: Visual explanations for spatio- temporal convolutions
Alexandros Stergiou, Georgios Kapidis, Grigorios Kalli- atakis, Christos Chrysoulas, Remco Veltkamp, and Ronald Poppe. Saliency tubes: Visual explanations for spatio- temporal convolutions. InICIP, 2019. 2
work page 2019
-
[79]
Elaine Sui, Xiaohan Wang, and Serena Yeung-Levy. Just shift it: Test-time prototype shifting for zero-shot general- ization with vision-language models. InWACV, 2025. 2
work page 2025
-
[80]
Ax- iomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Ax- iomatic attribution for deep networks. InICML, 2017. 2
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.