MCAT: Scaling Many-to-Many Speech-to-Text Translation with MLLMs to 70 Languages
Pith reviewed 2026-05-17 03:10 UTC · model grok-4.3
The pith
MCAT scales MLLM speech translation to mutual support among 70 languages while compressing audio to 30 tokens for faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
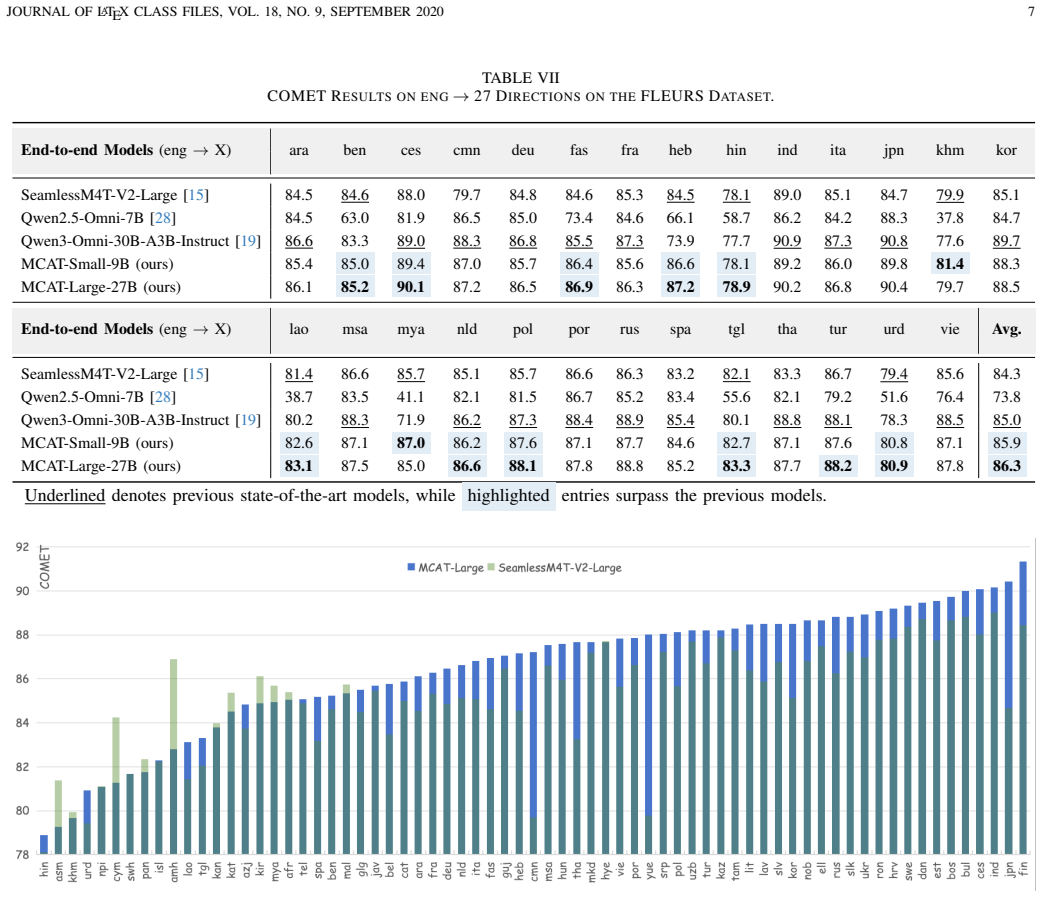
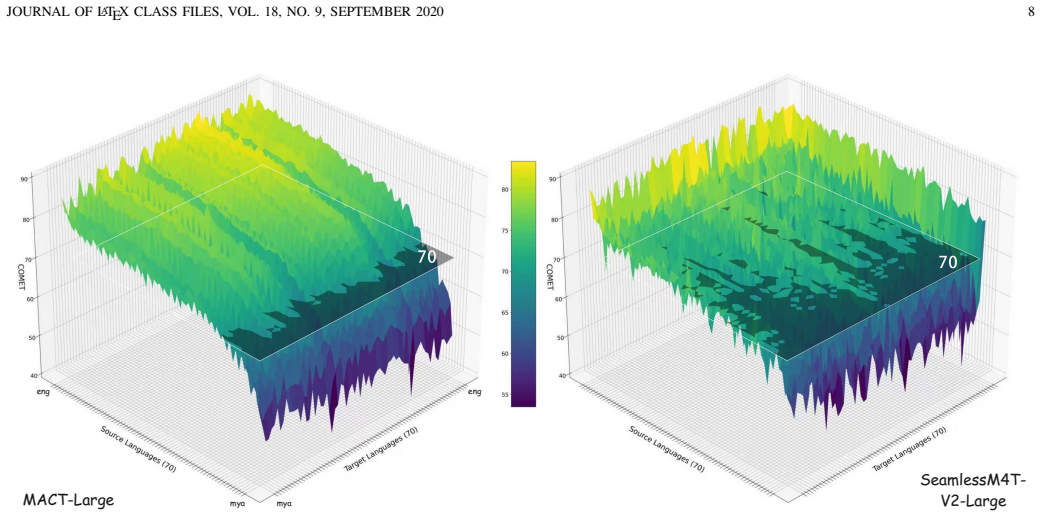
Curriculum learning combined with data balancing extends MLLM many-to-many speech-to-text translation to 70 languages, and an optimized adapter reduces speech sequences to 30 tokens, yielding results that surpass state-of-the-art end-to-end models on FLEURS in 70x69 directions while raising inference efficiency.
What carries the argument
The MCAT framework, built on curriculum learning and data balancing for language scaling together with an optimized speech adapter that shortens speech token sequences to 30.
If this is right
- Surpasses existing end-to-end models across every 70x69 translation direction on FLEURS.
- Raises inference speed by shortening speech token sequences.
- Maintains performance gains on both 9B and 27B scale MLLMs.
- Enables mutual translation support among the full set of 70 languages.
Where Pith is reading between the lines
- The token-compression approach may transfer to other speech or audio multimodal tasks.
- Wider language coverage could support translation tools for previously underserved regions.
- Open release of the models invites direct testing on additional low-resource language pairs.
Load-bearing premise
Curriculum learning and data balancing can scale MLLM translation to 70 languages without quality loss, and the adapter's reduction to 30 tokens keeps all needed speech information intact.
What would settle it
Direct side-by-side FLEURS evaluation in which MCAT fails to beat prior end-to-end models on non-English-centric pairs or shows no inference speedup with the 30-token adapter.
Figures




read the original abstract
Multimodal Large Language Models (MLLMs) have achieved great success in Speech-to-Text Translation (S2TT) tasks. However, current research is constrained by two key challenges: language coverage and efficiency. Most of the popular S2TT datasets are substantially English-centric, which restricts the scaling-up of MLLMs' many-to-many translation capabilities. Moreover, the inference speed of MLLMs degrades dramatically when the speech is converted into long sequences (e.g., 750 tokens). To address these limitations, we propose a Multilingual Cost-effective Accelerated Speech-to-Text Translator (MCAT) framework, which includes two innovations. First, a language scaling method that leverages curriculum learning and a data balancing strategy is introduced to extend the language coverage supported by MLLMs to 70 languages and achieve mutual translation among these languages. Second, an optimized speech adapter module is designed to reduce the length of the speech sequence to only 30 tokens. Extensive experiments were conducted on MLLMs of different scales (9B and 27B). The experimental results demonstrate that MCAT not only surpasses state-of-the-art end-to-end models on the FLEURS dataset across 70x69 directions but also enhances inference efficiency. The code and models are released at https://github.com/yxduir/m2m-70.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MCAT framework to scale many-to-many speech-to-text translation (S2TT) with multimodal LLMs to 70 languages. It proposes two main innovations: (1) a language scaling approach using curriculum learning and data balancing to enable mutual translation among 70 languages, and (2) an optimized speech adapter that compresses input speech sequences to only 30 tokens. Experiments on 9B and 27B MLLMs report surpassing prior end-to-end SOTA models on the FLEURS benchmark across 70×69 directions while also improving inference efficiency; code and models are released.
Significance. If the empirical claims hold after verification, the work would be a meaningful contribution to multilingual S2TT by simultaneously tackling limited language coverage (beyond English-centric datasets) and the quadratic inference cost of long speech token sequences in MLLMs. Demonstrating scalable many-to-many performance with a 30-token adapter on both 9B and 27B models, together with public code release, would provide a practical baseline for future efficiency-focused multilingual speech translation research.
major comments (2)
- [§4.2] §4.2 (Optimized Speech Adapter): The central efficiency claim rests on the assertion that the adapter compresses speech to 30 tokens without systematic information loss. No ablation is reported that directly compares BLEU or other metrics for 30-token vs. longer sequences (e.g., 100+ tokens) on FLEURS low-resource language subsets; without this, it remains unclear whether the reported average gains mask quality degradation in specific directions.
- [§5] §5 (Experiments): The claim that MCAT surpasses SOTA end-to-end models across all 70×69 directions is load-bearing for the paper’s contribution, yet the manuscript provides only aggregate results without per-direction breakdowns, statistical significance tests, or detailed baseline hyper-parameter matching. This weakens the strength of the cross-lingual scaling conclusion.
minor comments (2)
- [Abstract] The abstract and §1 could more explicitly define the 70×69 direction count (e.g., whether self-translations are excluded) to avoid ambiguity.
- [§5] Figure captions and tables in the experimental section would benefit from clearer indication of which results are zero-shot vs. fine-tuned and which languages are low-resource.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the changes we will make in the revised manuscript to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Optimized Speech Adapter): The central efficiency claim rests on the assertion that the adapter compresses speech to 30 tokens without systematic information loss. No ablation is reported that directly compares BLEU or other metrics for 30-token vs. longer sequences (e.g., 100+ tokens) on FLEURS low-resource language subsets; without this, it remains unclear whether the reported average gains mask quality degradation in specific directions.
Authors: We acknowledge that a direct ablation of token length on low-resource subsets would provide stronger support for the claim of no systematic information loss. The 30-token length was selected based on internal trade-off experiments balancing compression and quality, but these were not reported in detail. In the revision we will add an ablation table comparing 30-, 60-, and 100-token variants on selected low-resource FLEURS directions to demonstrate that performance remains competitive at 30 tokens. revision: yes
-
Referee: [§5] §5 (Experiments): The claim that MCAT surpasses SOTA end-to-end models across all 70×69 directions is load-bearing for the paper’s contribution, yet the manuscript provides only aggregate results without per-direction breakdowns, statistical significance tests, or detailed baseline hyper-parameter matching. This weakens the strength of the cross-lingual scaling conclusion.
Authors: We agree that aggregate results alone limit the ability to assess consistency across directions. The original submission reported averages due to space constraints. We will expand the experimental section to include (i) per-direction BLEU scores for a representative sample of directions, (ii) statistical significance tests on the main comparisons, and (iii) explicit clarification of baseline hyper-parameter settings and any adaptations made for fair comparison. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper describes an empirical framework: curriculum learning plus data balancing to scale to 70 languages, plus an optimized adapter compressing speech to 30 tokens. Performance is shown via direct comparison to external SOTA end-to-end models on the FLEURS dataset across 70x69 directions. No equations, first-principles derivations, or predictions appear that reduce by construction to fitted parameters or self-definitions. No load-bearing self-citations or uniqueness theorems are invoked. The central results are falsifiable against independent benchmarks and therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Curriculum learning and data balancing can effectively extend MLLM translation capabilities across a large set of languages without major quality loss
- domain assumption Compressing speech sequences to 30 tokens preserves sufficient information for high-quality translation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
an optimized speech adapter module is designed to reduce the length of the speech sequence to only 30 tokens... Q-Former for feature extraction, pooling for compression, and an MLP
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage curriculum learning strategy... ASR pre-training, SMT enhancement, SRT activation... data balancing strategy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Making llms better many-to-many speech-to-text translators with curriculum learning,
Y . Du, Y . Pan, Z. Ma, B. Yang, Y . Yang, K. Deng, X. Chen, Y . Xiang, M. Liu, and B. Qin, “Making llms better many-to-many speech-to-text translators with curriculum learning,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 12 466–12 478. 1, 2
work page 2025
-
[2]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449– 12 460, 2020. 1
work page 2020
-
[3]
Breaking the data barrier: Towards robust speech translation via adversarial stability training,
Q. Cheng, M. Fang, Y . Han, J. Huang, and Y . Duan, “Breaking the data barrier: Towards robust speech translation via adversarial stability training,”arXiv preprint arXiv:1909.11430, 2019. 1
-
[4]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models,”arXiv preprint arXiv:2311.07919,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Speech translation and the end-to-end promise: Taking stock of where we are,
M. Sperber and M. Paulik, “Speech translation and the end-to-end promise: Taking stock of where we are,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 7409–7421. 1
work page 2020
-
[6]
SpeechGPT : E mpowering large language models with intrinsic cross-modal conversational abilities
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross- modal conversational abilities,”arXiv preprint arXiv:2305.11000, 2023. 1, 2
-
[7]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024. 1, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Covost 2 and massively multilingual speech-to-text translation,
C. Wang, A. Wu, and J. Pino, “Covost 2 and massively multilingual speech-to-text translation,”arXiv preprint arXiv:2007.10310, 2020. 1, 2, 5
-
[9]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34 892– 34 916, 2023. 1
work page 2023
-
[10]
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742. 1, 3
work page 2023
-
[11]
Fleurs: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, Y . Zhang, V . Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,”arXiv preprint arXiv:2205.12446, 2022. [Online]. Available: https://arxiv.org/abs/2205. 12446 2, 5
-
[12]
Robust speech recognition via large-scale weak super- vision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak super- vision,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 28 492–28 518. 2, 3
work page 2023
-
[13]
Scaling neural machine translation to 200 languages,
“Scaling neural machine translation to 200 languages,”Nature, vol. 630, no. 8018, pp. 841–846, 2024. 2, 6, 11, 12
work page 2024
-
[14]
C. Wang, J. Pino, and J. Gu, “Improving cross-lingual transfer learn- ing for end-to-end speech recognition with speech translation,”arXiv preprint arXiv:2006.05474, 2020. 2
-
[15]
Joint speech and text machine translation for up to 100 languages,
“Joint speech and text machine translation for up to 100 languages,” Nature, vol. 637, no. 8046, pp. 587–593, 2025. 2, 6, 7, 12
work page 2025
-
[16]
Perception, reason, think, and plan: A survey on large multimodal reasoning models,
Y . Li, Z. Liu, Z. Li, X. Zhang, Z. Xu, X. Chen, H. Shi, S. Jiang, X. Wang, J. Wanget al., “Perception, reason, think, and plan: A survey on large multimodal reasoning models,”arXiv e-prints, pp. arXiv–2505, 2025. 2
work page 2025
-
[17]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “Salmonn: Towards generic hearing abilities for large language models,”arXiv preprint arXiv:2310.13289, 2023. 2
work page internal anchor Pith review arXiv 2023
- [18]
-
[19]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025. 2, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” inProceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), 2020, pp. 4211–4215. 5
work page 2020
-
[21]
M. Cui, P. Gao, W. Liu, J. Luan, and B. Wang, “Multilingual machine translation with open large language models at practical scale: An empirical study,”arXiv preprint arXiv:2502.02481, 2025. 5, 11
-
[22]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ram ´e, M. Rivi `ereet al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025. 5, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021. 5
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Seamlessm4t- massively multilingual & multimodal machine translation
L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, P.-A. Duquenne, H. Elsahar, H. Gong, K. Heffernan, J. Hoffmanet al., “Seamlessm4t-massively multilingual & multimodal machine transla- tion,”arXiv preprint arXiv:2308.11596, 2023. 5
-
[25]
Comet-22: Unbabel-ist 2022 submission for the metrics shared task,
R. Rei, J. G. De Souza, D. Alves, C. Zerva, A. C. Farinha, T. Glushkova, A. Lavie, L. Coheur, and A. F. Martins, “Comet-22: Unbabel-ist 2022 submission for the metrics shared task,” inProceedings of the Seventh Conference on Machine Translation (WMT), 2022, pp. 578–585. 5, 11
work page 2022
-
[26]
A call for clarity in reporting BLEU scores,
M. Post, “A call for clarity in reporting BLEU scores,” in Proceedings of the Third Conference on Machine Translation: Research Papers. Belgium, Brussels: Association for Computational Linguistics, Oct. 2018, pp. 186–191. [Online]. Available: https: //www.aclweb.org/anthology/W18-6319 5, 11
work page 2018
-
[27]
Y . Lu, W. Zhu, L. Li, Y . Qiao, and F. Yuan, “Llamax: Scaling linguistic horizons of llm by enhancing translation capabilities beyond 100 lan- guages,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 10 748–10 772. 6, 12
work page 2024
-
[28]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles,
-
[30]
9 JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 11 APPENDIX A. Language Coverage The MLLM’s S2TT capability is contingent upon the upper bound of the underlying LLM’s MT performance. Conse- quently, the MT capability of the base model directly deter- mines the ceiling of our translation quality and guides our final selection of supported la...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.