Differential ML with a Difference
Pith reviewed 2026-05-17 01:23 UTC · model grok-4.3
The pith
Likelihood ratio method lets Differential ML handle options with discontinuous payoffs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using differential labels from the likelihood ratio method instead of pathwise adjoints expands Differential ML to discontinuous payoffs. The hybrid incorporation of gamma estimates alongside delta estimates supplies additional regularization for the learned price function.
What carries the argument
Likelihood ratio sensitivities used as training labels in the Differential ML objective, with optional gamma augmentation for regularization.
Load-bearing premise
Likelihood ratio sensitivities remain stable and unbiased enough to serve as training labels for neural networks on discontinuous payoffs.
What would settle it
A numerical test on digital options where the pricing and delta errors with the likelihood ratio method are not lower than with pathwise Differential ML would falsify the claim that it expands the scope.
Figures




read the original abstract
Differential ML (Huge and Savine 2020) is a technique for training neural networks to provide fast approximations to complex simulation-based models for derivatives pricing and risk management. It uses price sensitivities calculated through pathwise adjoint differentiation to reduce pricing and hedging errors. However, for options with discontinuous payoffs, such as digital or barrier options, the pathwise sensitivities are biased, and incorporating them into the loss function can magnify errors. We consider alternative methods for estimating sensitivities and find that they can substantially reduce test errors in prices and in their sensitivities. Using differential labels calculated through the likelihood ratio method expands the scope of Differential ML to discontinuous payoffs. A hybrid method incorporates gamma estimates as well as delta estimates, providing further regularization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends Differential ML (Huge and Savine 2020) to options with discontinuous payoffs by replacing pathwise adjoint sensitivities with likelihood-ratio (LR) estimates as training labels. It further introduces a hybrid loss that augments delta labels with gamma estimates for additional regularization and reports that these changes substantially reduce test errors in both prices and sensitivities for digital and barrier options.
Significance. If the empirical claims hold, the work meaningfully widens the practical scope of Differential ML to a large class of path-dependent and exotic contracts where standard pathwise differentiation is biased. The hybrid delta-plus-gamma regularization is a concrete, implementable idea that could improve stability of neural-network pricing engines in production risk systems.
major comments (3)
- [§3.2] §3.2 (Likelihood-ratio delta): the unbiasedness of the LR estimator is correctly recalled, yet no variance bound, control-variate scheme, or importance-sampling adjustment is supplied. Because LR variance scales with the square of the payoff jump, the resulting training labels may be too noisy to deliver the claimed error reductions on discontinuous payoffs.
- [Table 2] Table 2 (hybrid vs. baseline rows): the reported RMSE improvements lack standard errors, number of Monte-Carlo paths used for the LR labels, or cross-validation folds; without these the statistical significance of the hybrid gain cannot be assessed and the regularization benefit remains unquantified.
- [§4.3] §4.3 (hybrid loss): the relative weighting between the delta and gamma penalty terms is introduced without an ablation or sensitivity analysis; it is therefore unclear whether the reported improvement is robust to the choice of the gamma coefficient or whether it merely trades one bias for another.
minor comments (2)
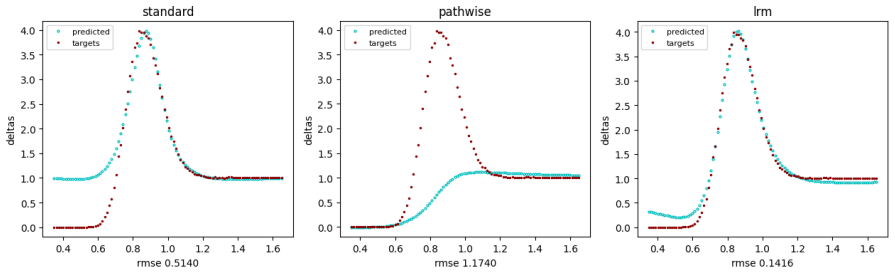
- [Figure 3] Figure 3 caption should state the exact number of training paths and the discontinuity location used for the digital-option example.
- [Eq. (12)] The notation for the hybrid loss (Eq. 12) mixes the symbol λ for both the LR weight and the gamma coefficient; a distinct symbol would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Likelihood-ratio delta): the unbiasedness of the LR estimator is correctly recalled, yet no variance bound, control-variate scheme, or importance-sampling adjustment is supplied. Because LR variance scales with the square of the payoff jump, the resulting training labels may be too noisy to deliver the claimed error reductions on discontinuous payoffs.
Authors: We agree that the manuscript would benefit from explicit discussion of the variance properties of the LR estimator. Although we correctly state unbiasedness, we did not derive bounds or introduce control variates because the primary contribution is the empirical demonstration that LR labels enable Differential ML on discontinuous payoffs. In the revision we will add a short paragraph in §3.2 noting that the neural-network loss averages the noisy labels across many paths and that the observed error reductions remain substantial despite this noise. We view importance sampling and control variates as natural extensions rather than prerequisites for the current claims. revision: partial
-
Referee: [Table 2] Table 2 (hybrid vs. baseline rows): the reported RMSE improvements lack standard errors, number of Monte-Carlo paths used for the LR labels, or cross-validation folds; without these the statistical significance of the hybrid gain cannot be assessed and the regularization benefit remains unquantified.
Authors: We will update Table 2 to report standard errors obtained from ten independent training runs with different random seeds. The LR labels were generated with 1 000 000 Monte-Carlo paths per contract; this figure will be stated in the table caption and in the experimental section. We also employed 5-fold cross-validation for hyper-parameter selection and will document this procedure explicitly. revision: yes
-
Referee: [§4.3] §4.3 (hybrid loss): the relative weighting between the delta and gamma penalty terms is introduced without an ablation or sensitivity analysis; it is therefore unclear whether the reported improvement is robust to the choice of the gamma coefficient or whether it merely trades one bias for another.
Authors: We accept that an ablation study is required to substantiate the robustness of the hybrid loss. In the revised manuscript we will add a sensitivity plot in §4.3 that varies the gamma coefficient over a factor of 100 around the chosen value and shows that the reported error reductions persist across this range. The original coefficient was selected so that the delta and gamma penalty terms have comparable magnitude on the training set; the new analysis will quantify whether this choice merely trades one bias for another or genuinely improves generalization. revision: yes
Circularity Check
No significant circularity; derivation relies on independent standard methods.
full rationale
The paper extends Differential ML (citing Huge and Savine 2020, an external reference) by incorporating the likelihood ratio method for sensitivities on discontinuous payoffs. This LR approach is a well-established Monte Carlo technique independent of the neural network training and not derived from the paper's own fitted parameters or self-citations. The hybrid delta-plus-gamma regularization is presented as an additional empirical step without reducing claims to quantities defined by construction within the current work. No load-bearing steps collapse to self-definition, fitted inputs renamed as predictions, or self-citation chains. The central claims remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pathwise adjoint differentiation produces biased sensitivities for options with discontinuous payoffs such as digital and barrier options.
Reference graph
Works this paper leans on
-
[1]
Asmussen, S., and P. W. Glynn (2007)Stochastic Simulation, Springer, New York
work page 2007
-
[2]
Chen, N., and P. Glasserman (2007) Malliavin Greeks without Malliavin calculus, Stochastic Processes and their Applications117(1), 1689–1723
work page 2007
-
[3]
Dixon, M., I. Halperin, and P. Bilokon (2020),Machine Learning in Finance, Springer Nature, Switzerland
work page 2020
-
[4]
Horvath, B., A. Muguruza, and M. Tomas (2021), Deep learning volatility,Quantitative Finance21(1), 11–27
work page 2021
-
[5]
Fourni´ e, E., J. M. Lasry, J. Lebuchoux, P. L. Lions, and N. Touzi (1999). Applications of Malliavin calculus to Monte Carlo methods in finance,Finance and Stochastics3(4), 391–412
work page 1999
-
[6]
(2004)Monte Carlo Methods in Financial Engineering, Springer, New York
Glasserman, P. (2004)Monte Carlo Methods in Financial Engineering, Springer, New York
work page 2004
-
[7]
Goodfellow, I., Y. Bengio, and A. Courville (2016)Deep Learning, MIT Press
work page 2016
-
[8]
Savine (2020) The shape of things to come,Risk.net, October
Huge, B., and A. Savine (2020) The shape of things to come,Risk.net, October
work page 2020
-
[9]
Raissi, M., P. Perdikaris, and G. E. Karniadakis (2019) Physics-informed neural net- works: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics378, 686–707. 15
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.