0
Deep learning prices path-dependent convertible bonds
A deep learning approach for pricing convertible bonds with path-dependent reset and call provisions
Contract terms outweigh asset models, with calls truncating upside and resets lowering call thresholds.
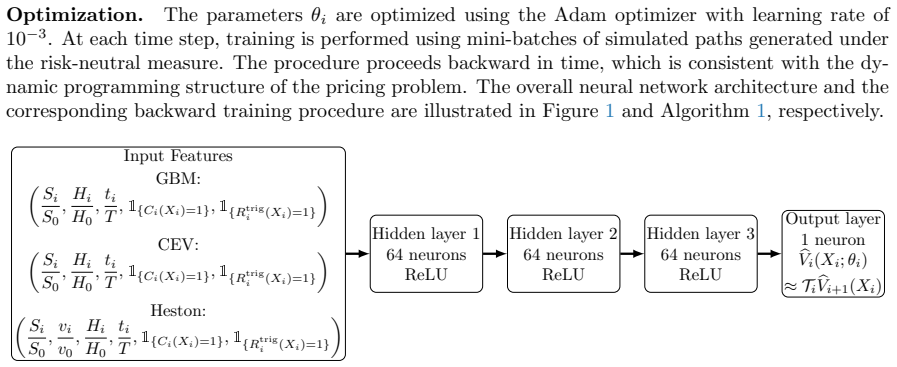 full image
full image
abstract click to expand
This paper develops a deep learning-based framework for pricing convertible bonds with path-dependent contractual features, namely downward conversion price reset and issuer call clauses under rolling-window trigger rules, which are widespread in the convertible bond market. We formulate the valuation problem as a path-dependent partial differential equation (PPDE), which explicitly captures the dependence of the convertible bond value on the historical path of the underlying asset and the dynamic evolution of the conversion price. We derive consistent PPDE formulations for three canonical underlying dynamics: geometric Brownian motion (GBM), constant elasticity of variance (CEV) and Heston stochastic volatility. We then construct a discrete-time dynamic programming scheme in which conditional expectations are approximated by neural networks, which remains tractable in such high-dimensional path-dependent setting. Empirical tests on China CITIC Bank Convertible Bond show that our framework produces stable and accurate prices and sensitivity patterns across all model specifications. Three key economic insights emerge: 1. Contractual features dominate underlying dynamics in determining convertible bond values. 2. The call provision decreases convertible bonds prices by truncating upside gains. 3. Counterintuitively, despite improving conversion terms, the downward reset provision further decreases the price of convertible bonds by lowering the effective call threshold and making early redemption more likely. The proposed PPDE-deep learning approach provides an efficient, flexible tool for pricing convertible bonds with complex path-dependent structures.