Fast-BEV++: Fast by Algorithm, Deployable by Design
Pith reviewed 2026-05-21 18:37 UTC · model grok-4.3
The pith
Fast-BEV++ achieves 0.488 NDS on nuScenes while running real-time above 134 FPS by redesigning the view transformation for standard hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
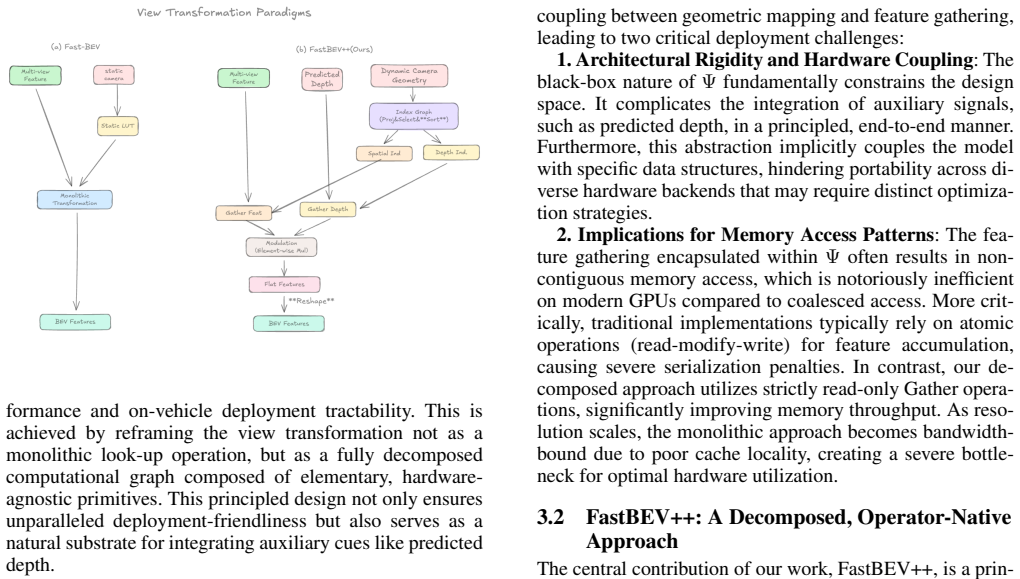
Fast-BEV++ resolves the accuracy-efficiency tension in BEV perception by decomposing the view transformation module into a hardware-oriented standard Index-Gather-Reshape pipeline. This approach eliminates the need for custom kernels and delivers at least three times the speed of the Fast-BEV baseline on edge platforms. On the nuScenes 3D object detection benchmark, it sets a new state-of-the-art with 0.488 NDS while achieving more than 134 FPS in real-time inference. The integrated learnable depth module provides consistent improvements, leading to the highest accuracy among similar methods.
What carries the argument
The decomposition of the core view transformation module into a hardware-oriented standard Index-Gather-Reshape pipeline.
If this is right
- Achieves at least three times speedup over the Fast-BEV baseline across mainstream edge platforms.
- Enables seamless real-time deployment across diverse production-grade automotive platforms.
- Alleviates hardware limitations without compromising perception accuracy or inference efficiency.
- The learnable depth module yields consistent gains while maintaining the highest accuracy among comparable methods.
Where Pith is reading between the lines
- This decomposition approach could extend to other BEV tasks such as semantic segmentation or motion prediction.
- It might lower the barrier for deploying advanced perception models on a wider range of hardware beyond specialized automotive chips.
- Combining the pipeline with further optimizations like model quantization could push frame rates even higher in practice.
Load-bearing premise
The Index-Gather-Reshape pipeline can replace custom kernels without losing the geometric accuracy needed for 3D detection.
What would settle it
Running the model on the nuScenes validation set and measuring either an NDS below 0.488 or inference speed below 134 FPS on the claimed edge platforms would disprove the central claims.
Figures
read the original abstract
The advancement of vision-only Bird's-Eye-View (BEV) perception, a core paradigm for cost-effective autonomous driving, is hindered by the long-standing fundamental trade-off between perception accuracy and on-device deployment efficiency. In this work, we introduce Fast-BEV++, a BEV perception framework that resolves this tension through two fundamental design principles: Fast by Algorithm and Deployable by Design. By decomposing the core view transformation module into a hardware-oriented standard Index-Gather-Reshape pipeline, Fast-BEV++ eliminates dependencies on custom kernels while achieving no less than 3 times speedup over the Fast-BEV baseline across mainstream edge platforms. Empirically, Fast-BEV++ establishes a new state-of-the-art result of 0.488 NDS on the nuScenes 3D object detection benchmark, simultaneously delivering real-time inference at more than 134 FPS via our acceleration design. In particular, our integrated, learnable depth module yields consistent performance gains, maintaining the highest accuracy among comparable methods. Overall, this inherently decomposed architecture enables seamless real-time deployment across diverse production-grade automotive platforms, alleviating hardware limitations without compromising perception accuracy or inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Fast-BEV++, a vision-only BEV perception framework for 3D object detection in autonomous driving. It resolves the accuracy-efficiency trade-off via two principles: 'Fast by Algorithm' through decomposition of the view transformation module into a hardware-oriented Index-Gather-Reshape pipeline, and 'Deployable by Design' with an integrated learnable depth module. The work reports a new state-of-the-art 0.488 NDS on the nuScenes benchmark, real-time inference exceeding 134 FPS, and at least 3x speedup over the Fast-BEV baseline on edge platforms, while claiming consistent gains from the depth module and seamless deployment without custom kernels.
Significance. If the empirical claims hold under rigorous verification, the result would be significant for practical autonomous driving by demonstrating that high-accuracy BEV perception can be achieved in real time on production-grade hardware without relying on specialized operators. The emphasis on standard hardware primitives and reproducible deployment considerations strengthens its potential impact beyond academic benchmarks.
major comments (2)
- [§3] §3 (Method), view transformation decomposition: The central claim that the Index-Gather-Reshape pipeline eliminates custom kernels while preserving or improving the 0.488 NDS accuracy relative to Fast-BEV rests on an unverified assumption of geometric equivalence. No equations, pseudocode, or feature-map comparison is provided to confirm that the decomposition performs exact sampling without implicit interpolation or indexing deviations that could silently degrade BEV feature fidelity on nuScenes.
- [§4] §4 (Experiments): The reported 3x speedup and >134 FPS are presented without an ablation isolating the contribution of the Index-Gather-Reshape pipeline versus the learnable depth module, nor with error bars, multiple runs, or platform-specific kernel counts. This leaves the load-bearing claim that accuracy is maintained while achieving the speedups unsupported by the current experimental evidence.
minor comments (1)
- [Abstract] The abstract states 'no less than 3 times speedup' and 'more than 134 FPS' but does not define the exact baseline configurations, input resolutions, or hardware platforms used for these measurements.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable suggestions. We address each major comment below and have updated the manuscript accordingly to improve clarity and experimental rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method), view transformation decomposition: The central claim that the Index-Gather-Reshape pipeline eliminates custom kernels while preserving or improving the 0.488 NDS accuracy relative to Fast-BEV rests on an unverified assumption of geometric equivalence. No equations, pseudocode, or feature-map comparison is provided to confirm that the decomposition performs exact sampling without implicit interpolation or indexing deviations that could silently degrade BEV feature fidelity on nuScenes.
Authors: We appreciate the referee pointing out the need for explicit verification of the geometric equivalence in our view transformation decomposition. The Index-Gather-Reshape pipeline is constructed to replicate the original transformation using standard hardware operations that perform exact indexing and gathering without any interpolation. To address this, we will include in the revised Section 3 a set of equations formalizing the decomposition, demonstrating that it is mathematically equivalent to the baseline view transformation. We will also add pseudocode outlining the pipeline steps and a comparison of BEV feature maps before and after the transformation to confirm fidelity. These additions will ensure that the preservation of accuracy is rigorously supported. revision: yes
-
Referee: [§4] §4 (Experiments): The reported 3x speedup and >134 FPS are presented without an ablation isolating the contribution of the Index-Gather-Reshape pipeline versus the learnable depth module, nor with error bars, multiple runs, or platform-specific kernel counts. This leaves the load-bearing claim that accuracy is maintained while achieving the speedups unsupported by the current experimental evidence.
Authors: We acknowledge that the current experimental presentation could benefit from more detailed ablations and statistical measures. In the revised manuscript, we will expand Section 4 with an ablation study that separately evaluates the impact of the Index-Gather-Reshape pipeline and the learnable depth module on both accuracy and inference speed. We will also include results from multiple runs with error bars (standard deviations) and provide platform-specific details including kernel counts for the speedup measurements. This will better substantiate the claims of maintained accuracy alongside the reported speedups. revision: yes
Circularity Check
No significant circularity in empirical benchmark claims
full rationale
The paper presents an engineering optimization for BEV perception via decomposition of view transformation into a standard Index-Gather-Reshape pipeline plus a learnable depth module. Central results (0.488 NDS SOTA on nuScenes and >134 FPS) are obtained through standard benchmark evaluation and reported speedups on edge platforms, not through any derivation chain that reduces by construction to fitted parameters, self-definitions, or self-citation load-bearing premises. No equations or uniqueness theorems are invoked that would create self-referential loops; the architecture choices are design decisions validated externally against nuScenes and deployment metrics.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decomposes the core view transformation module into a hardware-oriented standard Index-Gather-Reshape pipeline... fully TensorRT-Native implementation with zero custom plugins
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrated, learnable depth module yields consistent performance gains
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Still Camouflage, Moving Illusion: View-Induced Trajectory Manipulation in Autonomous Driving
Static adversarial camouflage exploits natural view-angle changes during relative motion to induce consistent feature drift in AV perception, leading to incorrect trajectory predictions and unnecessary braking.
Reference graph
Works this paper leans on
-
[1]
Bevformer: Learn- ing bird’s-eye-view representation from multi-camera im- ages via spatiotemporal transformers. InarXiv preprint arXiv:2203.17270. Huang, J., and Huang., G
-
[2]
InarXiv preprint arXiv:2203.17054
Bevdet4d: Exploit temporal cues in multi-camera 3d object detection. InarXiv preprint arXiv:2203.17054. Huang, J.; Huang, G.; Zhu, Z.; and Du, D
-
[3]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Bevdet: High-performance multi-camera 3d object detection in bird- eye-view. InarXiv preprint arXiv:2112.11790,. Huang, B.; Li, Y .; Xie, E.; Liang, F.; Wang, L.; Shen, M.; Liu, F.; Wang, T.; Luo, P.; and Shao, J
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
In arXiv preprint arXiv:2301.07870
Fast-bev: Towards real-time on-vehicle bird’s-eye view perception. In arXiv preprint arXiv:2301.07870. Lang, A. H.; V ora, S.; Caesar, H.; Zhou, L.; Yang, J.; and Beijbom, O
-
[5]
Inin Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp
Pointpillars: Fast encoders for ob- ject detection from point clouds. Inin Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12
work page 2019
-
[6]
Bevdepth: Acquisition of reliable depth for multi-view 3d object detec- tion
Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. InarXiv preprint arXiv:2206.10092. Li, B.; Huang, Z.; Chen, Y .; Cui, F.; Liang, M.; Shen, F.; Liu, E.; Xie, L.; Sheng, W.; Ouyang, J.; and Shao
-
[7]
Fast- bev: A fast and strong bird’s-eye view perception baseline. InPAMI. Liu, Y .; Wang, T.; Zhang, X.; and Sun, J. 2022a. Petr: Posi- tion embedding transformation for multi-view 3d object de- tection. InarXiv preprint arXiv:2203.05625. Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.; and Han, S. 2022b. Bevfusion: Multi-task multi-sensor fu- si...
-
[8]
Inin Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, 2019, pp
Pointrcnn: 3d object proposal generation and detection from point cloud. Inin Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, 2019, pp. 770–779. Wang, Y .; V .C.Guizilini; Zhang, T.; Wang, Y .; Zhao, H.; and Solomon, J
work page 2019
-
[9]
Inin Conference on Robot Learning
Detr3d: 3d object detection from multi- view images via 3d-to-2d queries. Inin Conference on Robot Learning. PMLR, 2022, pp. 180–191. Xie, E.; Yu, Z.; Zhou, D.; Philion, J.; Anandkumar, A.; Fidler, S.; Luo, P.; and Alvarez, J. M
work page 2022
-
[10]
InarXiv preprint arXiv:2204.05088
M2bev: Multi-camera joint 3d detection and segmentation with unified birds-eye view representation. InarXiv preprint arXiv:2204.05088. Zhou, Y ., and Tuzel, O
-
[11]
Inin Proceed- ings of the IEEE conference on computer vision and pattern recognition, 2018, pp
V oxelnet: End-to-end learn- ing for point cloud based 3d object detection. Inin Proceed- ings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4490–4499
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.