TPV: Parameter Perturbations Through the Lens of Test Prediction Variance
Pith reviewed 2026-05-21 16:53 UTC · model grok-4.3
The pith
Training-set sensitivity to parameter perturbations converges to the test-set value in overparameterized models, independent of generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
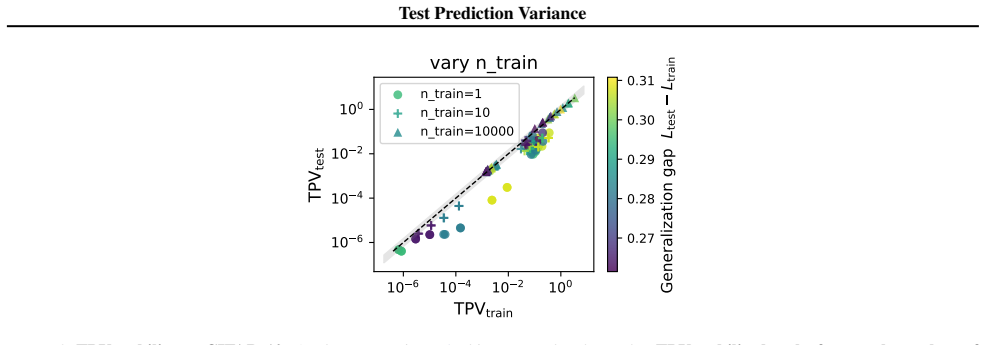
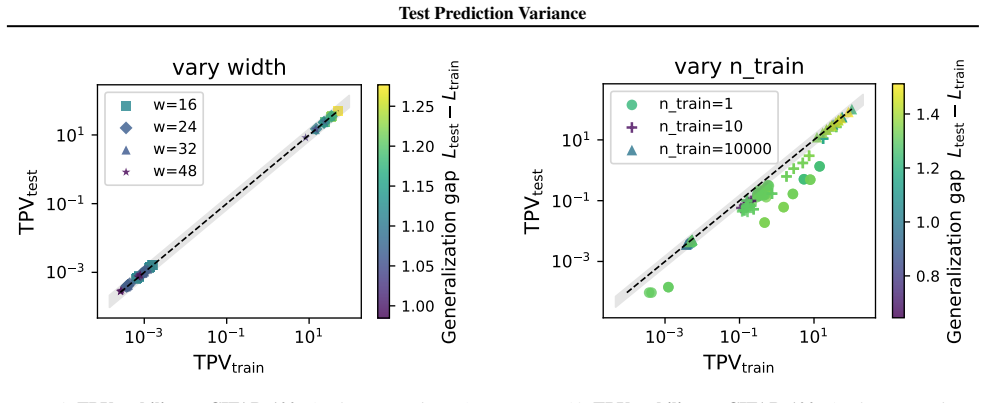
The paper proves that training-set TPV converges to its test-set counterpart in the overparameterized limit, irrespective of generalization performance. This supplies the first demonstration that prediction variance under local parameter perturbations can be inferred from training inputs alone. The trace form of TPV recovers the wide-minima hypothesis for SGD and quantization noise while producing a distinct Jacobian-spectral characterization for label noise that links to benign overfitting in nonlinear networks.
What carries the argument
Test prediction variance (TPV), the first-order sensitivity of trained model outputs to parameter perturbations, expressed in a trace form that isolates the Jacobian geometry of the trained model from the specific perturbation mechanism.
If this is right
- TPV recovers the wide-minima hypothesis for both SGD and quantization perturbations.
- Label-noise TPV yields a Jacobian-spectral view that connects to benign overfitting.
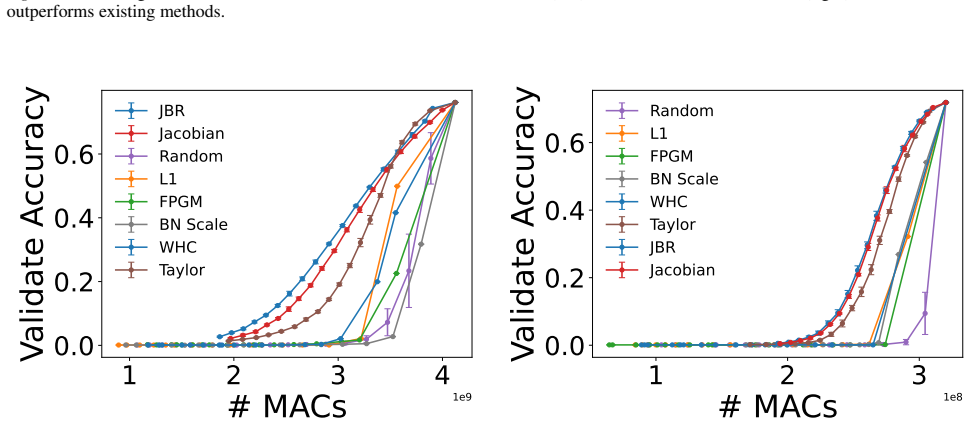
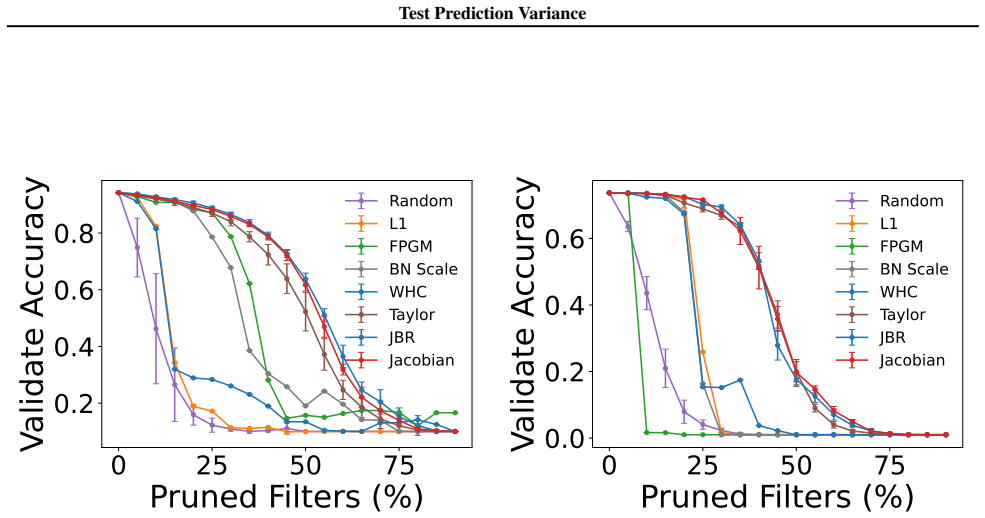
- A TPV-derived pruning criterion matches leading label-free baselines on standard tasks.
- Training-set TPV provides a usable signal for model selection in both in-distribution and transfer settings.
Where Pith is reading between the lines
- The observed stability at low widths suggests TPV could serve as a cheap diagnostic even when models are not extremely overparameterized.
- Because TPV separates geometry from perturbation type, the same machinery might apply to other post-training changes such as quantization-aware fine-tuning.
- The link to benign overfitting raises the possibility that TPV could flag regimes where overparameterized networks remain robust to label noise.
Load-bearing premise
The first-order Taylor approximation around the trained parameters suffices to capture the relevant robustness behavior for SGD noise, label noise, quantization, and pruning.
What would settle it
A concrete counter-example would be an overparameterized network on a standard image dataset where training-set TPV and test-set TPV differ by a large relative amount after training to convergence.
Figures









read the original abstract
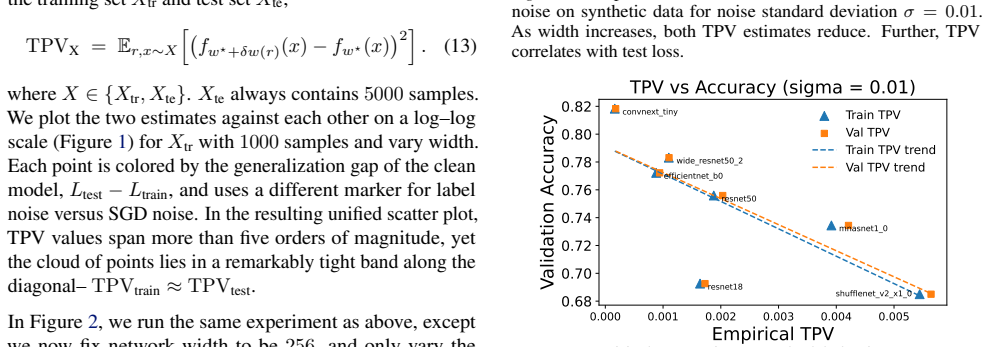
We introduce test prediction variance (TPV)--the first-order sensitivity of a trained model's outputs to parameter perturbations--as a unifying framework for analyzing post-training robustness. TPV is a fully label-free object whose trace form separates the geometry of the trained model from the specific perturbation mechanism, placing SGD noise, label noise, quantization, and pruning under a single lens. The resulting expressions recover the wide-minima hypothesis for SGD and quantization noise, and yield a distinct Jacobian-spectral characterization for label noise connecting label-noise TPV with benign overfitting in nonlinear networks. Theoretically, we prove that training-set TPV converges to its test-set counterpart in the overparameterized limit, irrespective of generalization performance, providing the first result that prediction variance under local parameter perturbations can be inferred from training inputs alone. Empirically, this stability holds far more broadly, including at very low widths. Further, TPV correlates well with test loss, enabling practical applications: JBR, a label-free pruning criterion derived from TPV geometry matching state-of-the-art baselines; and training-set based model selection signal for in-distribution and transfer learning scenarios. Code available at github.com/devansharpit/TPV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Test Prediction Variance (TPV) as the first-order sensitivity of a trained model's outputs to parameter perturbations around the trained weights. TPV is presented as a label-free unifying framework whose trace form separates model geometry from the perturbation mechanism, recovering the wide-minima hypothesis for SGD and quantization while providing a Jacobian-spectral characterization for label noise. The central theoretical result is a proof that training-set TPV converges to its test-set counterpart in the overparameterized limit irrespective of generalization performance. Empirically, this convergence is shown to hold more broadly (including low widths), TPV correlates with test loss, and it yields a pruning criterion (JBR) competitive with state-of-the-art baselines plus a training-set-based signal for model selection.
Significance. If the convergence theorem and the first-order approximation are rigorously justified across mechanisms, the work offers a novel label-free route to analyzing post-training robustness and benign overfitting in nonlinear networks. The explicit separation of geometry from perturbation type and the availability of code for reproducibility are strengths. The result that prediction variance under local perturbations can be inferred from training inputs alone would be a useful addition to the literature on sensitivity analysis and model compression.
major comments (2)
- [§3] §3 (TPV definition and Taylor expansion): The framework defines TPV via the first-order Jacobian trace and claims unification for pruning and quantization. However, pruning (hard zeroing) and quantization (finite discrete shifts) induce finite perturbations where the Taylor remainder is not necessarily negligible. No explicit bounds on the remainder term or regime of validity are provided showing that the linear term dominates uniformly for both training and test inputs; if the higher-order contributions differ across distributions, the claimed train-to-test convergence would not transfer to these mechanisms.
- [Theorem 1] Theorem 1 (overparameterized convergence): The proof establishes convergence of training-set TPV to test-set TPV under the first-order approximation. It is unclear whether the argument extends when the perturbation operator itself (e.g., the discrete mask for pruning) introduces distribution-dependent higher-order effects that are not controlled by the overparameterization assumption alone.
minor comments (2)
- [Abstract] The abstract states that TPV 'recovers the wide-minima hypothesis'; a brief pointer to the precise recovered statement (e.g., which prior result on flatness) would help readers.
- [Empirical evaluation] In the empirical sections, clarify whether the reported correlations between TPV and test loss are computed on the same models used for the convergence plots or on held-out architectures.
Simulated Author's Rebuttal
We thank the referee for their careful reading and insightful comments on the scope of the first-order approximation. We address each major point below and will incorporate clarifications into the revised manuscript to better delineate the regime in which TPV serves as a unifying lens.
read point-by-point responses
-
Referee: [§3] §3 (TPV definition and Taylor expansion): The framework defines TPV via the first-order Jacobian trace and claims unification for pruning and quantization. However, pruning (hard zeroing) and quantization (finite discrete shifts) induce finite perturbations where the Taylor remainder is not necessarily negligible. No explicit bounds on the remainder term or regime of validity are provided showing that the linear term dominates uniformly for both training and test inputs; if the higher-order contributions differ across distributions, the claimed train-to-test convergence would not transfer to these mechanisms.
Authors: TPV is defined in Section 3 precisely as the first-order term Tr(J Σ J^T) obtained from the linearization of the network output around the trained weights. The unification claim is therefore with respect to this local sensitivity measure: different mechanisms enter only through the choice of the perturbation second-moment matrix Σ (or its empirical counterpart), while the geometry is captured by the Jacobian. For finite perturbations such as hard pruning or quantization steps, the full change in prediction indeed includes higher-order terms; however, the manuscript positions TPV as a computationally tractable, label-free proxy for local robustness rather than an exact global characterization. We agree that the absence of explicit remainder bounds leaves open the question of when the linear term dominates uniformly. In the revision we will add a short paragraph in Section 3 stating that the framework applies directly when perturbations are small relative to the local curvature (e.g., low-bit quantization or pruning of low-magnitude weights) and will cite the empirical success of the JBR pruning rule in Section 5 as supporting evidence that the first-order signal remains informative even for finite masks. We will also clarify that Theorem 1 concerns convergence of the first-order TPV itself and does not automatically extend to the full nonlinear prediction change under data-dependent masks. revision: partial
-
Referee: [Theorem 1] Theorem 1 (overparameterized convergence): The proof establishes convergence of training-set TPV to test-set TPV under the first-order approximation. It is unclear whether the argument extends when the perturbation operator itself (e.g., the discrete mask for pruning) introduces distribution-dependent higher-order effects that are not controlled by the overparameterization assumption alone.
Authors: The proof of Theorem 1 proceeds by showing that, in the overparameterized regime, the empirical Jacobian on the training set concentrates around its population counterpart, causing the trace expression for TPV to coincide for train and test inputs irrespective of the particular perturbation covariance Σ. Because the argument is formulated entirely at the level of the first-order term, it does not claim control over higher-order remainders that would arise from a nonlinear perturbation operator (such as a data-dependent pruning mask). We will revise the statement of Theorem 1 and the paragraph immediately following it to emphasize that the result applies to any fixed perturbation distribution Σ and that, for pruning, the mask is chosen on the basis of the TPV geometry itself; any additional distribution shift induced by the mask selection step lies outside the current theorem. The manuscript already reports that the observed train-to-test stability of TPV holds empirically well beyond the overparameterized regime (including low-width networks), which provides practical reassurance even if a fully rigorous extension to nonlinear operators remains open. revision: partial
Circularity Check
No significant circularity: TPV convergence theorem is a self-contained mathematical result from sensitivity analysis
full rationale
The paper defines TPV explicitly as the first-order sensitivity (Jacobian trace) of model outputs to parameter perturbations around trained weights. It then derives unifying expressions for SGD noise, label noise, quantization, and pruning by separating this geometry from the perturbation mechanism. The central theoretical result—a proof that training-set TPV converges to test-set TPV in the overparameterized limit irrespective of generalization—is presented as an independent mathematical statement, not obtained by fitting parameters to target data or by renaming inputs. No self-citations are invoked as load-bearing premises, no ansatz is smuggled via prior work, and no prediction reduces by construction to a fitted quantity. The framework remains self-contained against external benchmarks; applications such as the JBR pruning criterion are downstream uses rather than definitional. This is the expected honest non-finding for a sensitivity-analysis paper whose derivations do not tautologically reproduce their inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption First-order Taylor expansion around trained parameters suffices to characterize robustness to the listed perturbation mechanisms
- domain assumption Overparameterized limit in which training-set TPV converges to test-set TPV
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
TPV≈Tr(Heff C) where Heff:=E_x[J(x)^⊤J(x)] and C=E[δw δw^⊤]
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2.1 (TPV Trace Stability) via NTK stability and LLN in overparameterized limit
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL http://proceedings.mlr.press/ v97/allen-zhu19a/allen-zhu19a.pdf. Arora, S., Du, S. S., Hu, W., Li, Z., Salakhutdinov, R. R., and Wang, R. On exact computation with an infinitely wide neural net.Advances in neural information process- ing systems, 32, 2019. Bar, A., Mulayoff, R., Michaeli, T., and Talmon, R. The ex- pected loss of preconditioned langev...
-
[2]
Pruning Convolutional Neural Networks for Resource Efficient Inference
PMLR, 2021. Liu, Z., Li, J., Shen, Z., Huang, G., Yan, S., and Zhang, C. Learning efficient convolutional networks through net- work slimming. InProceedings of the IEEE international conference on computer vision, pp. 2736–2744, 2017. Mandt, S., Hoffman, M. D., and Blei, D. M. A variational analysis of stochastic gradient algorithms. InProceed- ings of th...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Start from the reference parametersθ ⋆
-
[4]
Perturb the training labels:˜y=y+ε
-
[5]
Retrain for a small number of steps using the objective Lnoisy(θ) + γ 2 ∥w−w ⋆∥2 2, which ensures optimization remains in the local neighborhood where the linearized approximation is valid
-
[6]
Evaluate prediction changes ontest data, implicitly incorporating the test JacobianJ te
-
[7]
Estimate TPV as the empirical variance of the test predictions across multiple independent perturbations. While it does not yield theexactminimum–norm linearized solution, it provides a robust local approximation to the TPV dynamics in regimes where the exact computation is infeasible. Important Practical Considerations:There are a couple of important pra...
-
[8]
Models need to be trained in eval mode: we perturb the logits of the clean model’s prediction with Gaussian noise and train a copy of the reference model to fit these new targets, which act as infinitesimal change in targets. To achieve this faithfully, training must be done in eval mode, i.e., modules like batch norm and dropout should not be active. The...
-
[9]
different mini-batch in each epoch)
Mini-batch shuffling: All sources of randomness other than label noise should be removed as much as possible to isolate the effect of label noise when measuring TPV (e.g. different mini-batch in each epoch). In practice, we do use mini-batch SGD for noisy label fine-tuning for efficiency and to make the training loss go down in some cases. However, we ens...
-
[10]
MSE training loss must go down during training. This can be easily overlooked, and if the loss does not go down or diverges, it can easily lead to incorrect TPV estimates. We found this to be especially true in the case of ImageNet experiments, where is was extremely difficult to fit noisy target logits. E. TPV for SGD Stationary Noise Setup.Consider a sc...
work page 2022
-
[11]
Vary Width Experiment Details: We describe the details for the CIFAR-10 experiment in Fig 3 below. Details for CIFAR-100 (Fig. 9) are similar except the output has 100 dimensional logits and we use analogous CIFAR-100 pre-trained architectures. Dataset and preprocessing.We use the standard CIFAR-10 per-channel normalization. From these, we randomly subsam...
-
[12]
8), we use pretrained ResNet–20/32/44/56 models on CIFAR-10
Vary Number of Samples Experiment Details: For the experiment with varying number of training samples (Fig. 8), we use pretrained ResNet–20/32/44/56 models on CIFAR-10. Notice these architectures have different depth, which is not a consideration in the TPV theory, and is merely used as a source of variation in our experiments. The experimental details ar...
-
[13]
and can be seen as a label-free version of JC. Both JBR and JC assign a score to each parameter group g of the form score(wg) =E x w⊤ g Jg(x)⊤ m(x)m(x)⊤ Jg(x)wg =E x (m(x)⊤vg(x))2 , where vg(x) =J g(x)wg is the logit-space direction induced by group g, and the only difference between the two methods lies in the choice of the logit–space vectorm(x): mJC(x)...
work page 1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.