BlossomRec: Block-level Fused Sparse Attention Mechanism for Sequential Recommendations
Pith reviewed 2026-05-25 07:18 UTC · model grok-4.3
The pith
BlossomRec applies two sparse attention patterns for long-term and short-term interests to match full attention performance with far less memory in sequential recommenders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
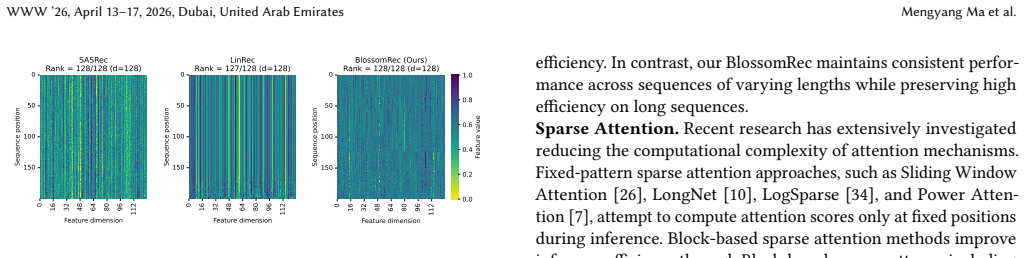
BlossomRec categorizes user interests into long-term and short-term, computes them using two distinct sparse attention patterns, and combines the results through a learnable gated output. This significantly reduces the number of interactions participating in attention computation. When integrated with state-of-the-art Transformer-based models, it achieves comparable or even superior performance on four public datasets while significantly reducing memory usage.
What carries the argument
BlossomRec, the block-level fused sparse attention mechanism that applies two distinct sparse patterns for long-term and short-term interests and fuses their outputs with a learnable gate.
If this is right
- Transformer models augmented with BlossomRec maintain or exceed baseline recommendation accuracy.
- Memory usage drops substantially as user interaction sequences grow longer.
- Performance stays stable across both short and long sequences unlike some other efficient attention methods.
- The theoretical cut in attention interactions translates to measurable efficiency gains in practice.
Where Pith is reading between the lines
- The same two-pattern fusion could be tested on other sequence tasks where quadratic attention becomes prohibitive.
- Adjusting the sparse patterns themselves might produce further memory savings on specific datasets.
- The learnable gate opens a route to dynamic weighting of multiple interest types in broader recommender designs.
- Production systems with real-time constraints would need separate validation beyond the public dataset results.
Load-bearing premise
That two fixed sparse attention patterns combined by a learnable gate can capture all relevant user interest interactions without needing the cross terms from standard full attention.
What would settle it
Direct side-by-side runs on the four public datasets showing whether the BlossomRec-integrated models drop below baseline Transformer accuracy or fail to deliver substantial memory reduction.
Figures



read the original abstract
Transformer structures have been widely used in sequential recommender systems (SRS). However, as user interaction histories increase, computational time and memory requirements also grow. This is mainly caused by the standard attention mechanism. Although there exist many methods employing efficient attention and SSM-based models, these approaches struggle to effectively model long sequences and may exhibit unstable performance on short sequences. To address these challenges, we design a sparse attention mechanism, BlossomRec, which models both long-term and short-term user interests through attention computation to achieve stable performance across sequences of varying lengths. Specifically, we categorize user interests in recommendation systems into long-term and short-term interests, and compute them using two distinct sparse attention patterns, with the results combined through a learnable gated output. Theoretically, it significantly reduces the number of interactions participating in attention computation. Extensive experiments on four public datasets demonstrate that BlossomRec, when integrated with state-of-the-art Transformer-based models, achieves comparable or even superior performance while significantly reducing memory usage, providing strong evidence of BlossomRec's efficiency and effectiveness. The code is available at https://github.com/Applied-Machine-Learning-Lab/WWW2026_BlossomRec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BlossomRec, a block-level fused sparse attention mechanism for sequential recommender systems. It models long-term and short-term user interests via two distinct sparse attention patterns whose outputs are combined by a learnable gate, claiming to reduce the number of attention interactions while achieving comparable or superior performance to standard attention when plugged into Transformer-based models, with extensive experiments on four public datasets and open-sourced code.
Significance. If the empirical results hold, the work offers a practical, memory-efficient alternative to quadratic attention and SSM-based models for handling variable-length user histories in sequential recommendation, addressing a core scalability bottleneck. The provision of code and complexity analysis strengthens its potential utility.
minor comments (2)
- [Abstract] Abstract: the four public datasets are not named; adding their identities would improve immediate context for readers.
- [§3] The description of the two sparse patterns and gate fusion would benefit from an explicit statement of their computational complexity relative to standard attention (e.g., O(n) vs O(n²)) in the main text.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's potential utility, and recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper's contribution is an empirical sparse attention design (two block-level patterns plus learnable gate) whose performance claims rest on experiments across four datasets, ablations, and complexity analysis rather than any closed mathematical derivation. No equations are presented that reduce a claimed result to a fitted parameter or self-citation by construction; the design choices are motivated by domain considerations and externally validated. This matches the most common honest outcome for applied systems papers.
Axiom & Free-Parameter Ledger
free parameters (2)
- block size
- gate network weights
axioms (1)
- standard math Standard scaled dot-product attention formula remains valid when restricted to the chosen sparse masks.
Reference graph
Works this paper leans on
-
[1]
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. Gqa: Training generalized multi-query trans- former models from multi-head checkpoints.arXiv preprint arXiv:2305.13245 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. Layer normaliza- tion.arXiv preprint arXiv:1607.06450(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A bi-step grounding paradigm for large language models in recommendation systems.ACM Transactions on Recommender Systems3, 4 (2025), 1–27
work page 2025
-
[4]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long- document transformer.arXiv preprint arXiv:2004.05150(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
work page 2025
- [6]
- [7]
-
[8]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
work page 2016
-
[9]
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, and Jiawei Chen. 2024. Distillation matters: empowering sequential recommenders to match the performance of large language models. InProceedings of the 18th ACM Conference on Recommender Systems. 507–517
work page 2024
- [10]
-
[11]
Hanwen Du, Hui Shi, Pengpeng Zhao, Deqing Wang, Victor S Sheng, Yanchi Liu, Guanfeng Liu, and Lei Zhao. 2022. Contrastive learning with bidirectional transformers for sequential recommendation. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 396–405
work page 2022
- [12]
-
[13]
Yongrui Fu, Jian Liu, Tao Li, Zonggang Wu, Shouke Qin, and Hanmeng Liu
- [14]
-
[15]
Zichuan Fu, Xiangyang Li, Chuhan Wu, Yichao Wang, Kuicai Dong, Xiangyu Zhao, Mengchen Zhao, Huifeng Guo, and Ruiming Tang. 2023. A unified frame- work for multi-domain ctr prediction via large language models.ACM Transac- tions on Information Systems(2023)
work page 2023
-
[16]
Jingtong Gao, Bo Chen, Menghui Zhu, Xiangyu Zhao, Xiaopeng Li, Yuhao Wang, Yichao Wang, Huifeng Guo, and Ruiming Tang. 2024. Hierrec: Scenario-aware hierarchical modeling for multi-scenario recommendations. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 653–662
work page 2024
-
[17]
Jingtong Gao, Zhaocheng Du, Xiaopeng Li, Yichao Wang, Xiangyang Li, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. 2025. SampleLLM: Optimizing Tabular Data Synthesis in Recommendations. InCompanion Proceedings of the ACM on Web Conference 2025. 211–220
work page 2025
-
[18]
Jingtong Gao, Xiangyu Zhao, Muyang Li, Minghao Zhao, Runze Wu, Ruocheng Guo, Yiding Liu, and Dawei Yin. 2024. Smlp4rec: An efficient all-mlp architecture for sequential recommendations.ACM Transactions on Information Systems42, 3 (2024), 1–23
work page 2024
-
[19]
Binzong Geng, Zhaoxin Huan, Xiaolu Zhang, Yong He, Liang Zhang, Fajie Yuan, Jun Zhou, and Linjian Mo. 2024. Breaking the length barrier: Llm-enhanced CTR prediction in long textual user behaviors. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2311–2315
work page 2024
-
[20]
Albert Gu and Tri Dao. 2023. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [21]
-
[22]
Xiaowen Huang, Shengsheng Qian, Quan Fang, Jitao Sang, and Changsheng Xu
-
[23]
InProceedings of the 26th ACM international conference on Multimedia
Csan: Contextual self-attention network for user sequential recommen- dation. InProceedings of the 26th ACM international conference on Multimedia. 447–455
-
[24]
Dietmar Jannach and Malte Ludewig. 2017. When recurrent neural networks meet the neighborhood for session-based recommendation. InProceedings of the eleventh ACM conference on recommender systems. 306–310
work page 2017
-
[25]
Pengyue Jia, Zhaocheng Du, Yichao Wang, Xiangyu Zhao, Xiaopeng Li, Yuhao Wang, Qidong Liu, Huifeng Guo, and Ruiming Tang. 2025. SELF: Surrogate- light Feature Selection with Large Language Models in Deep Recommender Systems. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 1145–1155
work page 2025
-
[26]
Pengyue Jia, Yiding Liu, Xiaopeng Li, Xiangyu Zhao, Yuhao Wang, Yantong Du, Xiao Han, Xuetao Wei, Shuaiqiang Wang, and Dawei Yin. 2024. G3: an effective and adaptive framework for worldwide geolocalization using large multi-modality models.Advances in Neural Information Processing Systems37 (2024), 53198–53221
work page 2024
-
[27]
Pengyue Jia, Yichao Wang, Shanru Lin, Xiaopeng Li, Xiangyu Zhao, Huifeng Guo, and Ruiming Tang. 2024. D3: A methodological exploration of domain division, modeling, and balance in multi-domain recommendations. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 8553–8561
work page 2024
-
[28]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, de las Diego Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.arxiv:2310.0682...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al
-
[30]
Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Systems37 (2024), 52481–52515
work page 2024
-
[31]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
work page 2018
-
[32]
Chengxi Li, Yejing Wang, Qidong Liu, Xiangyu Zhao, Wanyu Wang, Yiqi Wang, Lixin Zou, Wenqi Fan, and Qing Li. 2023. STRec: Sparse transformer for sequential recommendations. InProceedings of the 17th ACM conference on recommender systems. 101–111
work page 2023
- [33]
-
[34]
Jiacheng Li, Yujie Wang, and Julian McAuley. 2020. Time interval aware self- attention for sequential recommendation. InProceedings of the 13th international conference on web search and data mining. 322–330
work page 2020
-
[35]
Muyang Li, Zijian Zhang, Xiangyu Zhao, Wanyu Wang, Minghao Zhao, Runze Wu, and Ruocheng Guo. 2023. Automlp: Automated mlp for sequential recom- mendations. InProceedings of the ACM web conference 2023. 1190–1198
work page 2023
- [36]
-
[37]
Shiyang Li, Xiaoyong Jin, Yao Xuan, Xiyou Zhou, Wenhu Chen, Yu-Xiang Wang, and Xifeng Yan. 2019. Enhancing the locality and breaking the memory bottle- neck of transformer on time series forecasting.Advances in neural information processing systems32 (2019)
work page 2019
-
[38]
Xiaopeng Li, Bo Chen, Junda She, Shiteng Cao, You Wang, Qinlin Jia, Haiying He, Zheli Zhou, Zhao Liu, Ji Liu, et al. 2025. A Survey of Generative Recommendation from a Tri-Decoupled Perspective: Tokenization, Architecture, and Optimization. (2025)
work page 2025
-
[39]
Xinhang Li, Zhaopeng Qiu, Xiangyu Zhao, Zihao Wang, Yong Zhang, Chunxiao Xing, and Xian Wu. 2022. Gromov-wasserstein guided representation learning for cross-domain recommendation. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 1199–1208
work page 2022
- [40]
-
[41]
Xiaopeng Li, Fan Yan, Xiangyu Zhao, Yichao Wang, Bo Chen, Huifeng Guo, and Ruiming Tang. 2023. Hamur: Hyper adapter for multi-domain recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1268–1277
work page 2023
- [42]
-
[43]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Chengkai Liu, Jianghao Lin, Hanzhou Liu, Jianling Wang, and James Caverlee
-
[45]
InProceedings of the 33rd ACM international conference on information and knowledge management
Behavior-dependent linear recurrent units for efficient sequential recom- mendation. InProceedings of the 33rd ACM international conference on information and knowledge management. 1430–1440
-
[46]
Chengkai Liu, Jianghao Lin, Jianling Wang, Hanzhou Liu, and James Caverlee
- [47]
-
[48]
Langming Liu, Liu Cai, Chi Zhang, Xiangyu Zhao, Jingtong Gao, Wanyu Wang, Yifu Lv, Wenqi Fan, Yiqi Wang, Ming He, et al. 2023. Linrec: Linear attention WWW ’26, April 13–17, 2026, Dubai, United Arab Emirates Mengyang Ma et al. mechanism for long-term sequential recommender systems. InProceedings of the 46th International ACM SIGIR Conference on Research a...
work page 2023
-
[49]
Qidong Liu, Xian Wu, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng, and Xiangyu Zhao. 2024. Llm-esr: Large language models enhancement for long- tailed sequential recommendation.Advances in Neural Information Processing Systems37 (2024), 26701–26727
work page 2024
-
[50]
Qidong Liu, Xiangyu Zhao, Yejing Wang, Zijian Zhang, Howard Zhong, Chong Chen, Xiang Li, Wei Huang, and Feng Tian. 2025. Bridge the Domains: Large Lan- guage Models Enhanced Cross-domain Sequential Recommendation. InProceed- ings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1582–1592
work page 2025
-
[51]
Shuchang Liu, Qingpeng Cai, Bowen Sun, Yuhao Wang, Ji Jiang, Dong Zheng, Peng Jiang, Kun Gai, Xiangyu Zhao, and Yongfeng Zhang. 2023. Exploration and regularization of the latent action space in recommendation. InProceedings of the ACM Web Conference 2023. 833–844
work page 2023
-
[52]
Ziwei Liu, Qidong Liu, Yejing Wang, Wanyu Wang, Pengyue Jia, Maolin Wang, Zitao Liu, Yi Chang, and Xiangyu Zhao. 2025. SIGMA: Selective Gated Mamba for Sequential Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12264–12272
work page 2025
-
[53]
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, et al. 2025. Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [54]
-
[55]
Fuyu Lv, Taiwei Jin, Changlong Yu, Fei Sun, Quan Lin, Keping Yang, and Wil- fred Ng. 2019. SDM: Sequential deep matching model for online large-scale recommender system. InProceedings of the 28th ACM international conference on information and knowledge management. 2635–2643
work page 2019
- [56]
-
[57]
Qijie Shen, Hong Wen, Jing Zhang, and Qi Rao. 2022. Hierarchically fusing long and short-term user interests for click-through rate prediction in product search. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 1767–1776
work page 2022
- [58]
-
[59]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568 (2024), 127063
work page 2024
-
[60]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[61]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[62]
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. 2019. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Program- ming Languages. 10–19
work page 2019
-
[63]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
- [64]
-
[65]
Yuhao Wang, Xiangyu Zhao, Bo Chen, Qidong Liu, Huifeng Guo, Huanshuo Liu, Yichao Wang, Rui Zhang, and Ruiming Tang. 2023. PLATE: A prompt-enhanced paradigm for multi-scenario recommendations. InProceedings of the 46th In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval. 1498–1507
work page 2023
-
[66]
Qihang Yu, Kairui Fu, Zhaocheng Du, Yuxuan Si, Kaiyuan Li, Weihao Zhao, Zhicheng Zhang, Jieming Zhu, Quanyu Dai, Zhenhua Dong, et al. 2026. MAL- LOC: Benchmarking the Memory-aware Long Sequence Compression for Large Sequential Recommendation.arXiv preprint arXiv:2601.20234(2026)
-
[67]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, YX Wei, Lean Wang, Zhiping Xiao, et al . 2025. Native sparse attention: Hardware-aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. 2020. Big bird: Transformers for longer sequences.Advances in neural information processing systems33 (2020), 17283–17297
work page 2020
-
[69]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [70]
- [71]
-
[72]
Sheng Zhang, Maolin Wang, Wanyu Wang, Jingtong Gao, Xiangyu Zhao, Yu Yang, Xuetao Wei, Zitao Liu, and Tong Xu. 2025. Glint-ru: Gated lightweight intelligent recurrent units for sequential recommender systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
work page 2025
-
[73]
Zhicheng Zhang, Zhaocheng Du, Jieming Zhu, Jiwei Tang, Fengyuan Lu, Wang Jiaheng, Song-Li Wu, Qianhui Zhu, Jingyu Li, Hai-Tao Zheng, et al. 2026. Length- Adaptive Interest Network for Balancing Long and Short Sequence Modeling in CTR Prediction.arXiv preprint arXiv:2601.19142(2026)
- [74]
-
[75]
Xiangyu Zhao, Long Xia, Liang Zhang, Zhuoye Ding, Dawei Yin, and Jiliang Tang. 2018. Deep reinforcement learning for page-wise recommendations. In Proceedings of the 12th ACM conference on recommender systems. 95–103
work page 2018
-
[76]
Xiangyu Zhao, Liang Zhang, Zhuoye Ding, Long Xia, Jiliang Tang, and Dawei Yin
-
[77]
InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining
Recommendations with negative feedback via pairwise deep reinforcement learning. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1040–1048. A Observations To investigate whether interaction sequences can be processed in a block-wise pattern, we extracted the complete interaction sequence of user #566 fro...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.