Recognition: 2 theorem links
· Lean TheoremAutoregressive Language Models are Secretly Energy-Based Models: Insights into the Lookahead Capabilities of Next-Token Prediction
Pith reviewed 2026-05-16 21:25 UTC · model grok-4.3
The pith
Autoregressive language models are equivalent to energy-based models in function space through a bijection from the chain rule of probability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Taking the chain rule of probability as starting point yields an explicit bijection between autoregressive models and energy-based models in function space; this bijection is a special case of the soft Bellman equation from maximum-entropy reinforcement learning. Supervised learning on next-token prediction is therefore equivalent to learning the corresponding energy-based model, and theoretical error bounds exist for distilling energy-based models into autoregressive ones. The result supplies a concrete account of why next-token predictors can exhibit lookahead despite their local training objective.
What carries the argument
The explicit bijection in function space that maps the autoregressive chain-rule factorization to an energy function, shown to be identical to a special case of the soft Bellman equation.
If this is right
- Supervised learning of autoregressive models is formally identical to supervised learning of the corresponding energy-based models.
- Distillation of an energy-based model into an autoregressive model admits explicit theoretical error bounds.
- Next-token prediction can recover the same lookahead behavior as optimal policies in maximum-entropy reinforcement learning.
- The soft-Bellman correspondence lets any analysis of one model class transfer directly to the other.
Where Pith is reading between the lines
- Techniques developed for sampling from energy-based models, such as MCMC, could be repurposed to improve autoregressive decoding on tasks that require global consistency.
- Alignment methods that optimize energy-based objectives may be applied to autoregressive models without architectural change.
- The unification suggests that chain-of-thought prompting in language models works by implicitly minimizing an energy over future tokens.
Load-bearing premise
The chain rule of probability directly produces the claimed bijection in function space with no further restrictions on model capacity, training dynamics, or the form of the energy function.
What would settle it
A simple finite vocabulary and short sequence length where the next-token probabilities of a trained autoregressive model cannot be rearranged into a sequence-level energy function that satisfies the soft Bellman optimality condition.
Figures


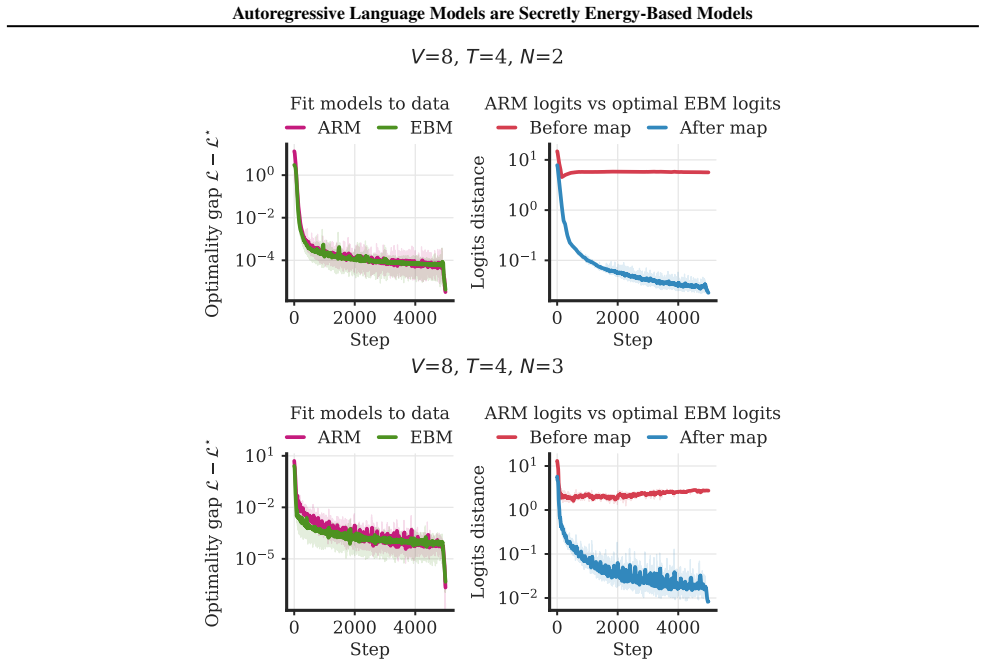


read the original abstract
Autoregressive models (ARMs) currently constitute the dominant paradigm for large language models (LLMs). Energy-based models (EBMs) represent another class of models, which have historically been less prevalent in LLM development, yet naturally characterize the optimal policy in post-training alignment. In this paper, we provide a unified view of these two model classes. Taking the chain rule of probability as a starting point, we establish an explicit bijection between ARMs and EBMs in function space, which we show to correspond to a special case of the soft Bellman equation in maximum entropy reinforcement learning. Building upon this bijection, we derive the equivalence between supervised learning of ARMs and EBMs. Furthermore, we analyze the distillation of EBMs into ARMs by providing theoretical error bounds. Our results provide insights into the ability of ARMs to plan ahead, despite being based on the next-token prediction paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish an explicit bijection between autoregressive language models (ARMs) and energy-based models (EBMs) in function space by starting from the chain rule of probability, showing that this bijection corresponds to a special case of the soft Bellman equation from maximum-entropy reinforcement learning. It derives the equivalence of supervised learning objectives for ARMs and EBMs, provides theoretical error bounds on distilling EBMs into ARMs, and uses the framework to explain the lookahead capabilities of next-token prediction.
Significance. If the bijection and derivations are correct, the work supplies a clean theoretical unification of the dominant LLM paradigm with EBMs that are already known to characterize optimal policies under alignment objectives. The explicit RL link offers a principled explanation for why next-token ARMs can exhibit planning behavior, and the distillation error bounds are directly usable for practical model compression. The derivation is parameter-free and rests only on the chain rule plus the standard soft Bellman equation, which are strengths.
major comments (2)
- [§3] §3 (bijection derivation): the manuscript must explicitly verify that the mapping E(x) = −∑_t log p(x_t | x_<t) is bijective in function space for arbitrary joint distributions and that the resulting energy satisfies the soft Bellman equation without hidden restrictions on model capacity or the form of the energy function; this step is load-bearing for all subsequent claims.
- [§4] §4 (error bounds): the stated theoretical error bounds for EBM-to-ARM distillation are central to the practical contribution; the proof should be expanded to show the precise dependence on the number of distillation steps and any assumptions on the proposal distribution.
minor comments (3)
- [Notation] Notation for the energy function and the soft Bellman operator should be introduced once in §2 and used consistently thereafter to avoid reader confusion.
- [Abstract] The abstract asserts 'explicit bijection' and 'theoretical error bounds' but does not preview the key equations; adding one or two displayed equations in the abstract or introduction would improve accessibility.
- [Discussion] A short discussion of how the bijection behaves under finite-capacity neural-network parameterizations (as opposed to the infinite-capacity function-space case) would strengthen the bridge to practical LLMs.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. The comments help clarify the presentation of the core bijection and strengthen the error bounds. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (bijection derivation): the manuscript must explicitly verify that the mapping E(x) = −∑_t log p(x_t | x_<t) is bijective in function space for arbitrary joint distributions and that the resulting energy satisfies the soft Bellman equation without hidden restrictions on model capacity or the form of the energy function; this step is load-bearing for all subsequent claims.
Authors: We agree that an explicit verification strengthens the load-bearing step. In the revised manuscript we will insert a short lemma in §3 proving bijectivity in function space: given any joint distribution p over finite-length sequences, the chain rule yields a unique E(x) = −log p(x) = −∑_t log p(x_t | x_<t); conversely, any real-valued energy E induces a unique normalized p(x) ∝ exp(−E(x)) whose autoregressive factorization recovers the original conditionals. The same E satisfies the soft Bellman equation E(x) = −log ∑_{x'} exp(−E(x')) (up to additive constants independent of x) by direct substitution of the normalization, with no restrictions on model capacity or energy functional form required—the identity holds pointwise for arbitrary positive measures. revision: yes
-
Referee: [§4] §4 (error bounds): the stated theoretical error bounds for EBM-to-ARM distillation are central to the practical contribution; the proof should be expanded to show the precise dependence on the number of distillation steps and any assumptions on the proposal distribution.
Authors: We thank the referee for this request. In the revision we will expand the proof of Theorem 4 to derive the explicit dependence of the total variation (or KL) error on the number of distillation steps K, obtaining a contraction of the form O(ρ^K) where ρ < 1 depends on the temperature and the minimal probability mass of the proposal. We will also state the standing assumptions on the proposal distribution q (full support over the sequence space and finite second moments) that are used to control the variance of the importance weights. revision: yes
Circularity Check
No significant circularity; derivation self-contained from chain rule
full rationale
The paper starts from the standard chain rule of probability to define an explicit bijection in function space between the autoregressive factorization p(x) = ∏ p(x_t | x_<t) and an energy function E(x) = -∑ log p(x_t | x_<t). This is shown to satisfy a special case of the soft Bellman equation by sequential decomposition of the log-probability, which is a direct algebraic identity holding for any joint distribution. No step renames a fitted parameter as a prediction, imports uniqueness via self-citation, or defines the target result in terms of itself. The RL link follows from established maximum-entropy RL without requiring the present paper's result as an assumption. The central claim therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Chain rule of probability
- domain assumption Soft Bellman equation in maximum-entropy RL
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Taking the chain rule of probability as a starting point, we establish an explicit bijection between ARMs and EBMs in function space, which we show to correspond to a special case of the soft Bellman equation
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
q(st, yt) := r(st, yt) + Vq(st ⊕ yt) (recursive mapping M)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
LoopUS: Recasting Pretrained LLMs into Looped Latent Refinement Models
LoopUS converts pretrained LLMs into looped latent refinement models via block decomposition, selective gating, random deep supervision, and confidence-based early exiting to improve reasoning performance.
-
Ontology-Constrained Neural Reasoning in Enterprise Agentic Systems: A Neurosymbolic Architecture for Domain-Grounded AI Agents
Ontology grounding improves accuracy and role consistency of enterprise LLM agents, with larger gains in domains poorly covered by training data.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Ackley, D. H., Hinton, G. E., and Sejnowski, T. J. A learning algorithm for Boltzmann machines. Cognitive Science, 9 0 (1): 0 147--169, 1985
work page 1985
-
[3]
Better estimation of the KL divergence between language models
Amini, A., Vieira, T., and Cotterell, R. Better estimation of the KL divergence between language models. In Advances in Neural Information Processing Systems, 2025
work page 2025
-
[4]
Planning by probabilistic inference
Attias, H. Planning by probabilistic inference. In International Workshop on Artificial Intelligence and Statistics, pp.\ 9--16. PMLR, 2003
work page 2003
-
[5]
G., G \'o mez, V., and Kappen, H
Azar, M. G., G \'o mez, V., and Kappen, H. J. Dynamic policy programming. The Journal of Machine Learning Research, 13 0 (1): 0 3207--3245, 2012
work page 2012
-
[6]
Bachmann, G. and Nagarajan, V. The pitfalls of next-token prediction. In Proceedings of the International Conference on Machine Learning. PMLR, 2024
work page 2024
-
[7]
Flow network based generative models for non-iterative diverse candidate generation
Bengio, E., Jain, M., Korablyov, M., Precup, D., and Bengio, Y. Flow network based generative models for non-iterative diverse candidate generation. Advances in Neural Information Processing Systems, 34: 0 27381--27394, 2021
work page 2021
-
[8]
Bengio, Y., Lahlou, S., Deleu, T., Hu, E. J., Tiwari, M., and Bengio, E. GFlowNet foundations. Journal of Machine Learning Research, 24 0 (210): 0 1--55, 2023
work page 2023
-
[9]
Blondel, M. and Roulet, V. The E lements of D ifferentiable P rogramming. arXiv preprint arXiv:2403.14606, 2024
-
[10]
Approximate inference in discrete distributions with Monte Carlo tree search and value functions
Buesing, L., Heess, N., and Weber, T. Approximate inference in discrete distributions with Monte Carlo tree search and value functions. In Proceedings of the International Conference on Artificial Intelligence and Statistics, pp.\ 624--634. PMLR, 2020
work page 2020
-
[11]
D., Tarassov, E., Pietquin, O., Richemond, P
Clavier, P., Grinsztajn, N., Avalos, R., Flet-Berliac, Y., Ergun, I., Domingues, O. D., Tarassov, E., Pietquin, O., Richemond, P. H., Strub, F., et al. ShiQ: Bringing back Bellman to LLMs . arXiv preprint arXiv:2505.11081, 2025
-
[12]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Formal Aspects of Language Modeling
Cotterell, R., Svete, A., Meister, C., Liu, T., and Du, L. Formal aspects of language modeling. arXiv preprint arXiv:2311.04329, 2023
-
[14]
BERT : Pre-training of deep bidirectional transformers for language understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT : Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics, 2019
work page 2019
-
[15]
Introduction to Natural Language Processing
Eisenstein, J. Introduction to Natural Language Processing. The MIT Press, 2019
work page 2019
-
[16]
The mystery of the pathological path-star task for language models
Frydenlund, A. The mystery of the pathological path-star task for language models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2024
work page 2024
-
[17]
Furuya, T., de Hoop, M. V., and Peyr \'e , G. Transformers are universal in-context learners. In Proceedings of the International Conference on Learning Representations, 2025
work page 2025
-
[18]
A theory of regularized Markov Decision Processes
Geist, M., Scherrer, B., and Pietquin, O. A theory of regularized Markov Decision Processes . In Proceedings of the International Conference on Machine Learning, 2019
work page 2019
-
[19]
Aligning language models with preferences through f -divergence minimization
Go, D., Korbak, T., Kruszewski, G., Rozen, J., Ryu, N., and Dymetman, M. Aligning language models with preferences through f -divergence minimization. In Proceedings of the International Conference on Machine Learning, 2023
work page 2023
-
[20]
Reinforcement learning with deep energy-based policies
Haarnoja, T., Tang, H., Abbeel, P., and Levine, S. Reinforcement learning with deep energy-based policies. In Proceedings of the International Conference on Machine Learning, 2017
work page 2017
-
[21]
Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, pp.\ 1861--1870, 2018
work page 2018
-
[22]
F lax: A neural network library and ecosystem for JAX , 2024
Heek, J., Levskaya, A., Oliver, A., Ritter, M., Rondepierre, B., Steiner, A., and van Z ee, M. F lax: A neural network library and ecosystem for JAX , 2024. URL http://github.com/google/flax
work page 2024
-
[23]
Ho, J. and Ermon, S. Generative adversarial imitation learning. In Advances in Neural Information Processing Systems, 2016
work page 2016
-
[24]
Kingma, D. P. and Ba, J. Adam: a method for stochastic optimization. In Proceedings of the International Conference on Machine Learning, 2014
work page 2014
-
[25]
RL with KL penalties is better viewed as bayesian inference
Korbak, T., Perez, E., and Buckley, C. RL with KL penalties is better viewed as bayesian inference. In Findings of the Association for Computational Linguistics: EMNLP 2022, pp.\ 1083--1091, 2022
work page 2022
-
[26]
LeCun, Y., Chopra, S., Hadsell, R., Ranzato, M., and Huang, F. J. A tutorial on energy-based models. In Predicting Structured Data. The MIT Press, 2007
work page 2007
-
[27]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Levine, S. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Trajectory balance: Improved credit assignment in GFlowNets
Malkin, N., Jain, M., Bengio, E., Sun, C., and Bengio, Y. Trajectory balance: Improved credit assignment in GFlowNets . In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[29]
Mensch, A. and Blondel, M. Differentiable dynamic programming for structured prediction and attention. In Proceedings of the International Conference on Machine Learning, pp.\ 3462--3471. PMLR, 2018
work page 2018
-
[30]
Bridging the gap between value and policy based reinforcement learning
Nachum, O., Norouzi, M., Xu, K., and Schuurmans, D. Bridging the gap between value and policy based reinforcement learning. In Advances in Neural Information Processing Systems, 2017
work page 2017
-
[31]
A unified view of entropy-regularized Markov Decision Processes
Neu, G., Jonsson, A., and G \'o mez, V. A unified view of entropy-regularized Markov Decision Processes . In Advances in Neural Information Processing Systems, 2017
work page 2017
-
[32]
Combining policy gradient and Q-learning
O'Donoghue, B., Munos, R., Kavukcuoglu, K., and Mnih, V. Combining policy gradient and Q-learning . In Proceedings of the International Conference on Learning Representations, 2017
work page 2017
-
[33]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[34]
Richemond, P. H. and Maginnis, B. A short variational proof of equivalence between policy gradients and soft Q learning . arXiv preprint arXiv:1712.08650, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
H., Tang, Y., Guo, D., Calandriello, D., Azar, M
Richemond, P. H., Tang, Y., Guo, D., Calandriello, D., Azar, M. G., Rafailov, R., Pires, B. A., Tarassov, E., Spangher, L., Ellsworth, W., et al. Offline regularised reinforcement learning for large language models alignment. arXiv preprint arXiv:2405.19107, 2024
-
[36]
Roulet, V., Liu, T., Vieillard, N., Sander, M. E., and Blondel, M. Loss functions and operators generated by f -divergences. In Proceedings of the International Conference on Machine Learning, 2025
work page 2025
-
[37]
E., Roulet, V., Liu, T., and Blondel, M
Sander, M. E., Roulet, V., Liu, T., and Blondel, M. Joint learning of energy-based models and their partition function. In Proceedings of the International Conference on Machine Learning, 2025
work page 2025
-
[38]
Equivalence Between Policy Gradients and Soft Q-Learning
Schulman, J., Chen, X., and Abbeel, P. Equivalence between policy gradients and soft Q-learning . arXiv preprint arXiv:1704.06440, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Song, Y. and Kingma, D. P. How to train your energy-based models. arXiv preprint arXiv:2101.03288, 2021
-
[40]
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., Radford, A., Amodei, D., and Christiano, P. F. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems, volume 33, 2020
work page 2020
-
[41]
Tiapkin, D., Morozov, N., Naumov, A., and Vetrov, D. P. Generative flow networks as entropy-regularized RL . In Proceedings of the International Conference on Artificial Intelligence and Statistics, pp.\ 4213--4221. PMLR, 2024
work page 2024
-
[42]
General duality between optimal control and estimation
Todorov, E. General duality between optimal control and estimation. In Proceedings of the IEEE conference on decision and control, 2008
work page 2008
-
[43]
Toussaint, M. et al. Probabilistic inference as a model of planned behavior. K \"u nstliche Intell. , 23 0 (3): 0 23--29, 2009
work page 2009
-
[44]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, 2017
work page 2017
-
[45]
Wainwright, M. J., Jordan, M. I., et al. Graphical models, exponential families, and variational inference. Foundations and Trends in Machine Learning , 1 0 (1--2): 0 1--305, 2008
work page 2008
-
[46]
Beyond reverse KL : Generalizing direct preference optimization with diverse divergence constraints
Wang, C., Jiang, Y., Yang, C., Liu, H., and Chen, Y. Beyond reverse KL : Generalizing direct preference optimization with diverse divergence constraints. In Proceedings of the International Conference on Learning Representations, 2024
work page 2024
-
[47]
Probabilistic inference in language models via twisted sequential Monte Carlo
Zhao, S., Brekelmans, R., Makhzani, A., and Grosse, R. Probabilistic inference in language models via twisted sequential Monte Carlo . In Proceedings of the International Conference on Machine Learning, 2024
work page 2024
-
[48]
Ziebart, B. D. Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010
work page 2010
-
[49]
Ziebart, B. D., Maas, A. L., Bagnell, J. A., Dey, A. K., et al. Maximum entropy inverse reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence , 2008
work page 2008
-
[50]
Fine-Tuning Language Models from Human Preferences
Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.