Multivariate Uncertainty Quantification with Tomographic Quantile Forests
Pith reviewed 2026-05-16 21:39 UTC · model grok-4.3
The pith
A single tree model estimates full multivariate conditional distributions from directional quantiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tomographic Quantile Forests learn conditional quantiles of directional projections as functions of the input and direction using a single tree model. At inference time, these quantiles are aggregated over many directions and the multivariate conditional distribution is reconstructed by minimizing the sliced Wasserstein distance through an alternating optimization scheme whose subproblems are convex. This single-model approach covers all directions and avoids the convexity restrictions typical of classical directional quantile methods.
What carries the argument
Tomographic Quantile Forests that learn directional conditional quantiles and reconstruct the joint distribution by sliced Wasserstein minimization.
If this is right
- Supports nonparametric estimation of arbitrary multivariate conditional distributions.
- Uses a single model for all projection directions instead of training separate models.
- Enables reconstruction without imposing convexity on the quantile regions.
- Provides an efficient inference procedure based on alternating convex optimizations.
- Validated on both synthetic data and real-world datasets with released code.
Where Pith is reading between the lines
- The method could be combined with other tree-based or ensemble techniques to further improve calibration in high-stakes applications.
- Extensions to streaming or online learning scenarios might follow naturally from the tree structure.
- Applications in fields like autonomous driving or medical diagnosis could benefit from full distributional predictions for better risk assessment.
- Scalability to very high-dimensional outputs remains an open question that future work could address through dimension reduction techniques.
Load-bearing premise
That minimizing the sliced Wasserstein distance over aggregated directional quantiles from a single tree model will recover the true multivariate conditional distribution without large approximation errors.
What would settle it
A test on synthetic data where the true conditional distribution has a known non-convex shape, checking whether the TQF reconstruction matches the ground truth quantiles or moments more closely than convex-restricted baselines.
Figures

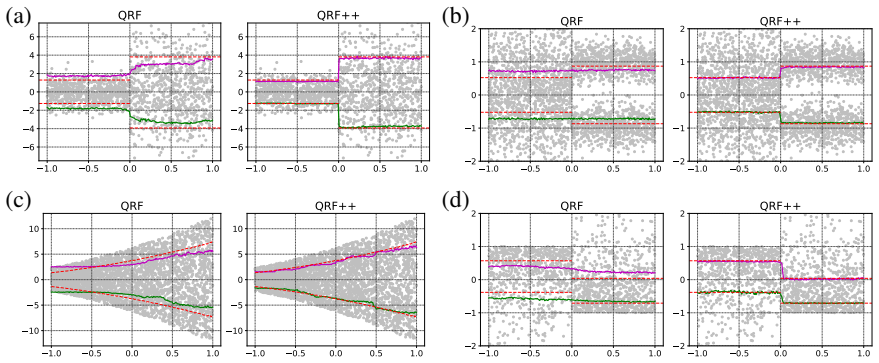


















read the original abstract
Quantifying predictive uncertainty is essential for safe and trustworthy real-world AI deployment. Yet, fully nonparametric estimation of conditional distributions remains challenging for multivariate targets. We propose Tomographic Quantile Forests (TQF), a nonparametric, uncertainty-aware, tree-based regression model for multivariate targets. TQF learns conditional quantiles of directional projections $\mathbf{n}^{\top}\mathbf{y}$ as functions of the input $\mathbf{x}$ and the unit direction $\mathbf{n}$. At inference, it aggregates quantiles across many directions and reconstructs the multivariate conditional distribution by minimizing the sliced Wasserstein distance via an efficient alternating scheme with convex subproblems. Unlike classical directional-quantile approaches that typically produce only convex quantile regions and require training separate models for different directions, TQF covers all directions with a single model without imposing convexity restrictions. We evaluate TQF on synthetic and real-world datasets, and release the source code on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Tomographic Quantile Forests (TQF), a nonparametric tree-based model for multivariate uncertainty quantification. TQF learns conditional quantiles of directional projections n^T y as functions of input x and unit direction n using a single forest. At inference, quantiles are aggregated over many directions and the full multivariate conditional distribution of y|x is reconstructed by minimizing the sliced Wasserstein distance via an efficient alternating optimization scheme whose subproblems are convex. The method avoids convexity restrictions on quantile regions that affect classical directional approaches and is evaluated on synthetic and real-world datasets, with source code released.
Significance. If the reconstruction step accurately recovers the target conditional law, TQF would offer a scalable, fully nonparametric alternative for multivariate predictive uncertainty that combines the flexibility of quantile forests with tomographic ideas. The single-model coverage of all directions and the convex subproblems in the alternating scheme are practical advantages. Public code release supports reproducibility. Significance is tempered by the need to confirm that finite directional sampling and forest-based quantile estimates do not introduce substantial bias for non-convex or multimodal conditionals.
major comments (2)
- [Method (reconstruction and alternating optimization)] The central claim that the sliced-Wasserstein minimization recovers the true multivariate conditional distribution from finite directional quantiles is load-bearing, yet the manuscript provides no statistical consistency result or explicit error bound on the bias arising from (i) finite directional sampling (sliced Wasserstein converges to Wasserstein only in the limit) and (ii) the single forest's generalization over both x and the continuous sphere of n. This gap is especially relevant for multimodal or heavy-tailed targets; see the description of the alternating scheme and the reconstruction procedure.
- [Experiments] In the experimental evaluation, the synthetic and real-data comparisons should report quantitative distribution-recovery metrics (e.g., empirical sliced or full Wasserstein distances, or proper scoring rules for the reconstructed law) rather than relying primarily on visual or qualitative assessment; without these, it is difficult to judge whether the approximation error remains negligible as claimed.
minor comments (2)
- [Abstract and Method] Clarify the precise number of directions used in the aggregation step and the convergence tolerance of the alternating scheme; these implementation details affect reproducibility.
- [Introduction] Notation for the unit vector n should be introduced consistently in the introduction to distinguish it from other vector quantities.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below and will revise the manuscript accordingly to strengthen both the theoretical discussion and the experimental evaluation.
read point-by-point responses
-
Referee: The central claim that the sliced-Wasserstein minimization recovers the true multivariate conditional distribution from finite directional quantiles is load-bearing, yet the manuscript provides no statistical consistency result or explicit error bound on the bias arising from (i) finite directional sampling (sliced Wasserstein converges to Wasserstein only in the limit) and (ii) the single forest's generalization over both x and the continuous sphere of n. This gap is especially relevant for multimodal or heavy-tailed targets.
Authors: We agree that a formal consistency analysis would strengthen the paper. While the sliced Wasserstein distance is known to converge to the Wasserstein distance as the number of projections tends to infinity (with explicit rates available in the literature), the manuscript does not derive finite-sample bounds that also account for the quantile forest estimation error. In the revision we will add a dedicated limitations subsection that (a) cites the relevant sliced-Wasserstein convergence results, (b) discusses the additional bias introduced by finite directional sampling and by the single forest’s generalization over the sphere, and (c) highlights the empirical behavior on the multimodal synthetic examples already present in the paper. We do not claim a new theoretical guarantee at this stage. revision: yes
-
Referee: In the experimental evaluation, the synthetic and real-data comparisons should report quantitative distribution-recovery metrics (e.g., empirical sliced or full Wasserstein distances, or proper scoring rules for the reconstructed law) rather than relying primarily on visual or qualitative assessment.
Authors: We accept this point. The current experiments emphasize visual comparisons and downstream task performance. In the revised version we will augment the experimental section with quantitative tables that report (i) empirical sliced Wasserstein distances between the reconstructed conditional distributions and the ground-truth distributions on the synthetic benchmarks, and (ii) proper scoring rules (energy score and variogram score) on the real-world datasets. These metrics will be computed for TQF as well as the competing methods to allow direct numerical comparison of distribution-recovery quality. revision: yes
Circularity Check
No circularity: directional quantile learning and sliced-Wasserstein reconstruction are independently defined and externally evaluated
full rationale
The paper defines TQF as a single tree model that learns conditional quantiles of n^Ty for input x and direction n, then aggregates and inverts via sliced-Wasserstein minimization with an alternating convex scheme. No equation or claim reduces the reconstruction to a quantity defined by the fit itself, nor does any load-bearing step rely on a self-citation chain or imported uniqueness theorem. The method is evaluated on synthetic and real-world datasets with released code, providing external grounding. This matches the default non-circular case.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A review of uncertainty quantification in deep learning: Techniques, applications and challenges
Abdar, Moloud, Farhad Pourpanah, Sadiq Hussain, Dana Rezazadegan, Li Liu, Mohammad Ghavamzadeh, Paul Fieguth, Xiaochun Cao, Abbas Khosravi, U. Rajendra Acharya, Vladimir Makarenkov & Saeid Nahavandi (2021). “A review of uncertainty quantification in deep learning: Techniques, applications and challenges”. In:Information Fusion76, pp. 243–297. Alexander, C...
work page 2021
-
[2]
Nonparametric Multiple-Output Center- Outward Quantile Regression
22 Barrio, Eustasio del, Alberto González Sanz & Marc Hallin (2024). “Nonparametric Multiple-Output Center- Outward Quantile Regression”. In:Journal of the American Statistical Association120.550, pp. 818–
work page 2024
-
[3]
A Practical Guide to Sample-based Statistical Distances for Evaluating Generative Models in Science
Biewen, Martin & Stefan Glaisner (2025).Using Distributional Random Forests for the Analysis of the Income Distribution. IZA Discussion Papers 17774. Bonn: Institute of LaborEconomics (IZA). Bischoff, Sebastian, Alana Darcher, Michael Deistler, Richard Gao, Franziska Gerken, Manuel Glöckler, Lisa Haxel, Jaivardhan Kapoor, Janne K. Lappalainen, Jakob H. Ma...
-
[4]
Some Theorems on Distribution Functions
Proceedings of Machine Learning Research. PMLR, pp. 999–1008. Cramér, H. & H. Wold (1936). “Some Theorems on Distribution Functions”. In:Journal of the London Mathematical Society11.4, pp. 290–294. Csiszár, I. & P. C. Shields (2004). “Information Theory and Statistics: A Tutorial”. In:Foundations and Trends in Communications and Information Theory1.4, pp....
work page 1936
-
[5]
Wasserstein Random Forests and Applications in Heterogeneous Treatment Effects
Bejing, China: PMLR, pp. 665–673. Dheur, Victor, Matteo Fontana, Yorick Estievenart, Naomi Desobry & Souhaib Ben Taieb (2025).A Unified Comparative Study with Generalized Conformity Scores for Multi-Output Conformal Regression. arXiv: 2501.10533. Du, Qiming, Gérard Biau, Francois Petit & Raphaël Porcher (2021). “Wasserstein Random Forests and Applications...
-
[6]
NGBoost: Natural Gradient Boosting for Probabilistic Prediction
Proceedings of Machine Learning Research. PMLR, pp. 1729–1737. Duan, Tony, Anand Avati, Daisy Yi Ding, Khanh K. Thai, Sanjay Basu, Andrew Y . Ng & Alejandro Schuler (2020). “NGBoost: Natural Gradient Boosting for Probabilistic Prediction”. In:Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event. V ol
work page 2020
-
[7]
Calibrated Multiple-Output Quantile Regression with Representation Learning
Proceedings of Machine Learning Research. PMLR, pp. 2690–2700. Feldman, Shai, Stephen Bates & Yaniv Romano (2023). “Calibrated Multiple-Output Quantile Regression with Representation Learning”. In:J. Mach. Learn. Res.24, pp. 1–48. 23 Fontana, Matteo, Gianluca Zeni & Simone Vantini (2023). “Conformal prediction: A unified review of theory and new challenge...
work page 2023
-
[8]
A survey of uncertainty in deep neural networks
Curran Associates, Inc., pp. 489–496. Garnett, Roman (2023).Bayesian Optimization. Cambridge: Cambridge University Press. Gawlikowski, Jakob, Cedrique Rovile Njieutcheu Tassi, Mohsin Ali, Jongseok Lee, Matthias Humt, Jianxiang Feng, Anna M. Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, Muhammad Shahzad, Wen Yang, Richard Bamler & Xiaoxiang Zhu (202...
work page 2023
-
[9]
Why do tree-based models still outperform deep learning on typical tabular data?
Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States. Ed. by Peter L. Bartlett, Fernando C. N. Pereira, Christopher J. C. Burges, Léon Bottou & Kilian Q. Weinberger, pp. 1214–1222. Grinsztajn, Léo, Edouard Oyallon & Gaël Varoquaux (2022). “Why do tree-based models still outperform deep learning on typical tabular data?” In:A...
work page 2012
-
[10]
Hallin, Marc, Eustasio del Barrio, Juan Cuesta-Albertos & Carlos Matrán (2021). “Distribution and quantile functions, ranks and signs in dimension d: A measure transportation approach”. In:Ann. Statist.49.2, pp. 1139–1165. Hallin, Marc, Davy Paindaveine & Miroslav Šiman (2010). “Multivariate quantiles and multiple-output regres- sion quantiles: From L1 op...
-
[11]
Sample-based Uncertainty Quantification with a Single Deter- ministic Neural Network
Proceedings of Machine Learning Research. PMLR, pp. 10603– 10621. Kanazawa, Takuya & Chetan Gupta (2022). “Sample-based Uncertainty Quantification with a Single Deter- ministic Neural Network”. In:Proceedings of the 14th International Joint Conference on Computational Intelligence, IJCCI 2022, Valletta, Malta, October 24-26,
work page 2022
-
[12]
LightGBM: a highly efficient gradient boosting decision tree
SCITEPRESS, pp. 292–304. Ke, Guolin, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye & Tie-Yan Liu (2017). “LightGBM: a highly efficient gradient boosting decision tree”. In:Proceedings of the 31st International Conference on Neural Information Processing Systems. NIPS’17. Long Beach, California, USA, pp. 3149–
work page 2017
-
[13]
Sparse spatial autoregressions
Kelley Pace, R. & Ronald Barry (1997). “Sparse spatial autoregressions”. In:Statistics& Probability Letters 33.3, pp. 291–297. Klebanov, Lev B. (2005).N-distances and Their Applications. Prague: Charles University, Karolinum Press. Klein, Nadja (2024). “Distributional Regression for Data Analysis”. In:Annual Review of Statistics and Its Application11, pp....
-
[14]
When Do Neural Nets Outperform Boosted Trees on Tabular Data?
McElfresh, Duncan C., Sujay Khandagale, Jonathan Valverde, Vishak Prasad C., Ganesh Ramakrishnan, Micah Goldblum & Colin White (2023). “When Do Neural Nets Outperform Boosted Trees on Tabular Data?” In:Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, ...
work page 2023
-
[15]
Meinshausen, N. (2006). “Quantile Regression Forests”. In:Journal of Machine Learning Research7.35, pp. 983–999. Meinshausen, Nicolai & Loris Michel (2017).quantregForest.URL: https://cran.r-project.org/web /packages/quantregForest/index.html. Montesuma, Eduardo Fernandes, Fred Maurice Ngolè Mboula & Antoine Souloumiac (2025). “Recent Ad- vances in Optima...
-
[16]
Lecture Notes in Computer Science. Springer, pp. 435–446. Ramachandran, G. N. & A. V . Lakshminarayanan (1971). “Three-dimensional Reconstruction from Radio- graphs and Electron Micrographs: Application of Convolutions instead of Fourier Transforms”. In:Proceed- ings of the National Academy of Sciences68.9, pp. 2236–2240. Rasmussen, Carl Edward & Christop...
work page 1971
-
[17]
The Cross-Entropy Method for Combinatorial and Continuous Optimization
Ren, Weijieying, Tianxiang Zhao, Yuqing Huang & Vasant G. Honavar (2025).Deep Learning within Tabular Data: Foundations, Challenges, Advances and Future Directions. arXiv:2501.03540. Rubinstein, R. (1999). “The Cross-Entropy Method for Combinatorial and Continuous Optimization”. In: Methodology and Computing in Applied Probability1, pp. 127–190. Russell, ...
-
[18]
Solving Inverse Problems in Medical Imaging with Score-Based Generative Models
Somvanshi, Shriyank, Subasish Das, Syed Aaqib Javed, Gian Antariksa & Ahmed Hossain (2024).A Survey on Deep Tabular Learning. arXiv:2410.12034. Song, Yang, Liyue Shen, Lei Xing & Stefano Ermon (2022). “Solving Inverse Problems in Medical Imaging with Score-Based Generative Models”. In:The Tenth International Conference on Learning Representations, ICLR 20...
-
[19]
Hilbert Space Embeddings and Metrics on Probability Measures
OpenReview.net. Sriperumbudur, Bharath K., Arthur Gretton, Kenji Fukumizu, Bernhard Schölkopf & Gert R. G. Lanckriet (2010). “Hilbert Space Embeddings and Metrics on Probability Measures”. In:J. Mach. Learn. Res.11, pp. 1517–1561. Szabo, A., K. Boucher, W. L. Carroll, L. B. Klebanov, A. D. Tsodikov & A. Y . Yakovlev (2002). “Variable selection and pattern...
work page 2010
-
[20]
Continuous Vector Quantile Regression
26 Vedula, S., I. Tallini, A. A. Rosenberg, M. Pegoraro, E. Rodolà, Y . Romano & A. Bronstein (2023). “Continuous Vector Quantile Regression”. In:ICML Workshop on New Frontiers in Learning, Control, and Dynamical Systems. Villani, Cédric (2003).Topics in Optimal Transportation. V ol
work page 2023
-
[21]
Graduate Studies in Mathematics. American Mathematical Society. – (2009).Optimal Transport—Old and New. V ol
work page 2009
-
[22]
Proper scoring rules for estimation and forecast evaluation
Grundlehren der mathematischen Wissenschaften. Heidelberg: Springer-Verlag Berlin. Virtanen, Pauli, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelso...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[23]
Proceedings of Machine Learning Research. PMLR, pp. 8814–8836. Willemink, M. J. & P. B. Noël (2019). “The evolution of image reconstruction for CT—from filtered back projection to artificial intelligence”. In:European Radiology29, pp. 2185–2195. Wu, Nailong (1997).The Maximum Entropy Method. V ol
work page 2019
-
[24]
Survey on Multi-Output Learning
Springer Series in Information Sciences. Springer Berlin, Heidelberg. Xu, Donna, Yaxin Shi, Ivor W. Tsang, Yew-Soon Ong, Chen Gong & Xiaobo Shen (2020). “Survey on Multi-Output Learning”. In:IEEE Transactions on Neural Networks and Learning Systems31.7, pp. 2409–
work page 2020
-
[25]
Multi-target regression via target combinations using principal component analysis
Yamaguchi, Takafumi & Yoshiyuki Yamashita (2024). “Multi-target regression via target combinations using principal component analysis”. In:Computers & Chemical Engineering181, p. 108510. Zabërgja, Guri, Arlind Kadra & Josif Grabocka (2024).Is Deep Learning finally better than Decision Trees on Tabular Data?arXiv:2402.03970. Zhao, Quanshui (2000). “Restric...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.