NASTaR: NovaSAR Automated Ship Target Recognition Dataset
Pith reviewed 2026-05-16 20:15 UTC · model grok-4.3
The pith
The NASTaR dataset supplies 3415 AIS-labeled NovaSAR ship patches to support deep learning classification of ship types from SAR images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
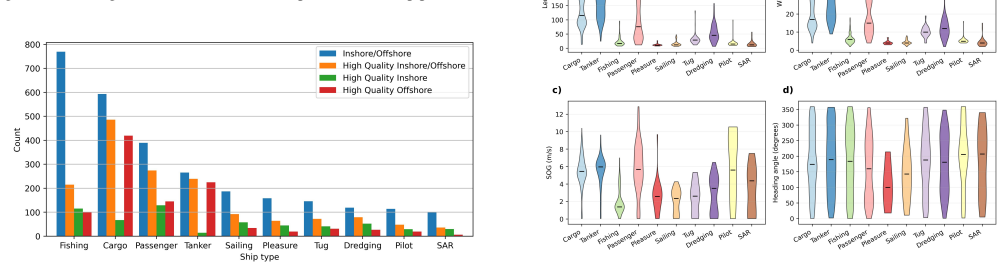
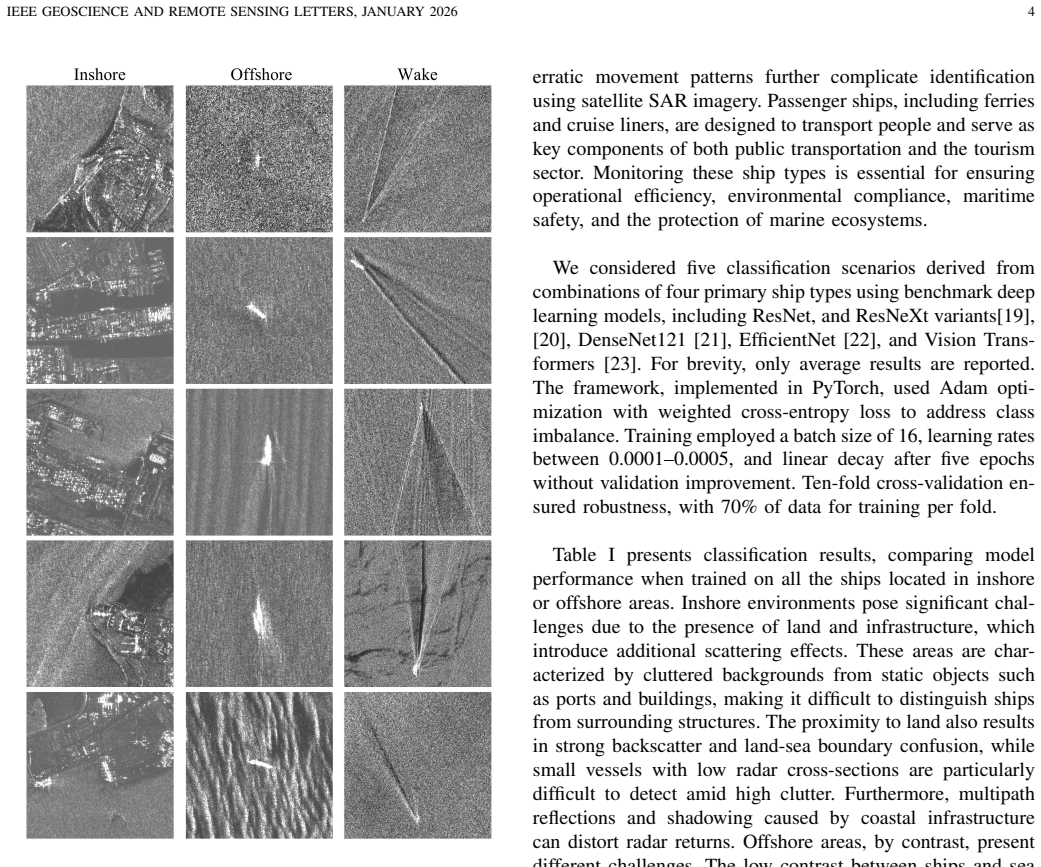
The NASTaR dataset comprises 3415 ship patches from NovaSAR S-band imagery with labels matched to AIS data. It includes 23 unique classes, inshore/offshore separation, and an auxiliary wake dataset. Validation across benchmark deep learning models yields over 60 percent accuracy for classifying four major ship types, over 70 percent for a three-class scenario, more than 75 percent for distinguishing cargo from tanker ships, and over 87 percent for identifying fishing vessels.
What carries the argument
The NASTaR collection of 3415 AIS-matched NovaSAR S-band ship patches that serves as training and test data for deep learning ship-type classifiers.
If this is right
- Deep learning models reach over 60 percent accuracy on four major ship types when trained on NASTaR.
- Accuracy exceeds 70 percent in three-class ship classification tasks using the same data.
- Cargo and tanker ships can be separated at more than 75 percent accuracy.
- Fishing vessels can be identified at over 87 percent accuracy.
- The dataset enables development of models for all-weather, space-based ship monitoring.
Where Pith is reading between the lines
- Combining NASTaR with patches from other SAR satellites could reduce domain shift when models must handle multiple frequencies and resolutions.
- The auxiliary wake images open the possibility of training models that jointly detect ships and estimate their speed or direction from wake signatures.
- Automated AIS matching demonstrated here could be applied to create similar labeled sets for other remote-sensing targets, lowering the cost of manual annotation.
- Models trained on NASTaR may support real-time maritime traffic analysis for collision avoidance and security screening.
Load-bearing premise
AIS records supply accurate and timely ground-truth labels for the extracted SAR patches without mismatches caused by timing offsets or data gaps.
What would settle it
Independent manual verification of a sample of patches against high-resolution optical imagery or port records to check whether the assigned AIS ship-type labels match the actual vessels shown in the SAR patches.
Figures


read the original abstract
Synthetic Aperture Radar (SAR) offers a unique capability for all-weather, space-based maritime activity monitoring by capturing and imaging strong reflections from ships at sea. A well-defined challenge in this domain is ship type classification. Due to the high diversity and complexity of ship types, accurate recognition is difficult and typically requires specialized deep learning models. These models, however, depend on large, high-quality ground-truth datasets to achieve robust performance and generalization. Furthermore, the growing variety of SAR satellites operating at different frequencies and spatial resolutions has amplified the need for more annotated datasets to enhance model accuracy. To address this, we present the NovaSAR Automated Ship Target Recognition (NASTaR) dataset. This dataset comprises of 3415 ship patches extracted from NovaSAR S-band imagery, with labels matched to AIS data. It includes distinctive features such as 23 unique classes, inshore/offshore separation, and an auxiliary wake dataset for patches where ship wakes are visible. We validated the dataset applicability across prominent ship-type classification scenarios using benchmark deep learning models. Results demonstrate over 60% accuracy for classifying four major ship types, over 70% for a three-class scenario, more than 75% for distinguishing cargo from tanker ships, and over 87% for identifying fishing vessels. The NASTaR dataset is available at https://doi.org/10.5523/bris.2tfa6x37oerz2lyiw6hp47058, while relevant codes for benchmarking and analysis are available at https://github.com/benyaminhosseiny/nastar.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the NASTaR dataset comprising 3415 ship patches extracted from NovaSAR S-band SAR imagery, with labels matched to AIS records across 23 unique classes, plus inshore/offshore separation and an auxiliary wake dataset. Benchmark experiments with deep learning models are presented for ship-type classification tasks, reporting accuracies exceeding 60% on four major classes, 70% on a three-class scenario, 75% for cargo vs. tanker discrimination, and 87% for fishing vessel identification. The dataset and benchmarking code are made publicly available via DOI and GitHub.
Significance. If the AIS-derived labels prove reliable, the release supplies a new, publicly available S-band SAR ship dataset with multi-class annotations and wake information that can support development of maritime surveillance models. The reported benchmark numbers provide an initial indication of dataset utility for common classification scenarios, though the absence of detailed experimental protocols limits immediate adoption.
major comments (2)
- [Abstract / Dataset Construction] Abstract and Dataset Construction section: The headline benchmark accuracies (>60% 4-class, >70% 3-class, >75% cargo/tanker, >87% fishing) rest entirely on the assumption that AIS records supply accurate, time-aligned ground truth for the extracted patches. No quantitative validation (error-rate estimates, manual audit statistics, temporal offset distributions, or AIS gap analysis) is provided; any non-negligible label noise would render the reported figures uninterpretable as evidence of dataset quality.
- [Benchmarking Experiments] Benchmarking Experiments section: The abstract and main text supply no details on the specific model architectures, training protocols, data splits, cross-validation procedure, or error bars used to obtain the reported accuracies. This omission prevents independent verification or reproduction of the central performance claims that are used to demonstrate dataset applicability.
minor comments (2)
- [Dataset Description] The inshore/offshore separation criterion and wake visibility definition should be stated explicitly with quantitative thresholds (e.g., distance from shore or wake pixel count) to allow users to replicate the auxiliary annotations.
- [Figures] Figure captions for the sample patches and class distribution plots should include the exact number of samples per class and the train/validation/test split sizes used in the benchmarks.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript describing the NASTaR dataset. We address each major comment below and will revise the manuscript to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [Abstract / Dataset Construction] Abstract and Dataset Construction section: The headline benchmark accuracies (>60% 4-class, >70% 3-class, >75% cargo/tanker, >87% fishing) rest entirely on the assumption that AIS records supply accurate, time-aligned ground truth for the extracted patches. No quantitative validation (error-rate estimates, manual audit statistics, temporal offset distributions, or AIS gap analysis) is provided; any non-negligible label noise would render the reported figures uninterpretable as evidence of dataset quality.
Authors: We acknowledge that the manuscript does not provide quantitative validation metrics for the AIS labels. In the revised version we will add a new subsection under Dataset Construction that details the AIS-to-image matching procedure, reports the distribution of temporal offsets between SAR acquisition and AIS timestamps in our dataset, and cites prior literature on AIS accuracy for maritime targets. We will also explicitly discuss potential sources of label noise as a limitation and its possible impact on the benchmark accuracies. A full-scale manual audit was not feasible within the scope of this dataset release, so we cannot supply error-rate estimates from such an audit. revision: partial
-
Referee: [Benchmarking Experiments] Benchmarking Experiments section: The abstract and main text supply no details on the specific model architectures, training protocols, data splits, cross-validation procedure, or error bars used to obtain the reported accuracies. This omission prevents independent verification or reproduction of the central performance claims that are used to demonstrate dataset applicability.
Authors: We agree that the current text lacks sufficient experimental detail. In the revised manuscript we will expand the Benchmarking Experiments section to specify the exact model architectures (including backbone networks and any modifications), training hyperparameters (optimizer, learning rate schedule, batch size, number of epochs), data split ratios and stratification strategy, whether cross-validation was used, and the method for computing error bars or confidence intervals on the reported accuracies. The public GitHub repository will be updated to ensure the released code exactly reproduces the revised description. revision: yes
Circularity Check
No circularity: empirical dataset release with direct benchmarking
full rationale
The paper contains no derivations, equations, fitted parameters, or predictions. It describes extraction of 3415 SAR patches from NovaSAR imagery, AIS-based labeling, and direct application of benchmark deep learning models to report empirical accuracies (e.g., >60% for 4-class, >70% for 3-class). These results are straightforward train/test measurements on the released data and do not reduce to any self-definitional, fitted-input, or self-citation chain. The AIS ground-truth assumption is a standard labeling caveat but introduces no circular reduction in any claimed derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AIS data supplies reliable ground-truth ship type labels for matched SAR patches
Reference graph
Works this paper leans on
-
[1]
W. G. Pichel, P. Clemente-Colon, C. C. Wackerman, and K. S. Friedman, “Ship and wake detection,” inSynthetic Aperture Radar Marine User’s Manual, C. R. Jackson and J. R. Apel, Eds. NOAA/NESDIS, U.S. Department of Commerce, 2004, ch. 12, pp. 277–303
work page 2004
-
[2]
On the modelling of ship wakes in S-band SAR images and an application to ship identification,
K. Kamirul, O. Pappas, I. G. Rizaev, and A. Achim, “On the modelling of ship wakes in S-band SAR images and an application to ship identification,” in2024 IEEE Int. Geosci. Remote Sens. Symp. (IGARSS), 2024, pp. 10 599–10 603
work page 2024
-
[3]
A sur- vey on SAR ship classification using deep learning,
C. M. Awais, M. Reggiannini, D. Moroni, and E. Salerno, “A sur- vey on SAR ship classification using deep learning,”arXiv preprint arXiv:2503.11906, 2025
-
[4]
Development and application of ship detection and classification datasets: A review,
C. Zhang, X. Zhang, G. Gao, H. Lang, G. Liu, C. Cao, Y . Song, Y . Guan, and Y . Dai, “Development and application of ship detection and classification datasets: A review,”IEEE Geosci. Remote Sens. Mag., 2024
work page 2024
-
[5]
Ship classification in TerraSAR-X images with feature space based sparse representation,
X. Xing, K. Ji, H. Zou, W. Chen, and J. Sun, “Ship classification in TerraSAR-X images with feature space based sparse representation,” IEEE Geosci. Remote Sens. Lett., vol. 10, no. 6, pp. 1562–1566, 2013
work page 2013
-
[6]
OpenSARShip: A dataset dedicated to Sentinel-1 ship interpretation,
L. Huang, B. Liu, B. Li, W. Guo, W. Yu, Z. Zhang, and W. Yu, “OpenSARShip: A dataset dedicated to Sentinel-1 ship interpretation,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 11, no. 1, pp. 195–208, 2017
work page 2017
-
[7]
B. Li, B. Liu, L. Huang, W. Guo, Z. Zhang, and W. Yu, “OpenSARShip 2.0: A large-volume dataset for deeper interpretation of ship targets in Sentinel-1 imagery,” in2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA). IEEE, 2017, pp. 1–5
work page 2017
-
[8]
xView3-SAR: Detecting dark fishing activity using Synthetic Aperture Radar imagery,
F. Paolo, T.-t. T. Lin, R. Gupta, B. Goodman, N. Patel, D. Kuster, D. Kroodsma, and J. Dunnmon, “xView3-SAR: Detecting dark fishing activity using Synthetic Aperture Radar imagery,”Adv. Neural Inf. Process. Syst., vol. 35, pp. 37 604–37 616, 2022
work page 2022
-
[9]
X. Hou, W. Ao, Q. Song, J. Lai, H. Wang, and F. Xu, “FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition,”Sci. China Inf. Sci., vol. 63, no. 4, p. 140303, 2020
work page 2020
-
[10]
Ship classification and detection based on CNN using GF-3 SAR images,
M. Ma, J. Chen, W. Liu, and W. Yang, “Ship classification and detection based on CNN using GF-3 SAR images,”Remote Sensing, vol. 10, no. 12, p. 2043, 2018
work page 2043
-
[11]
C. Xu and X. Wang, “OpenSARWake: A large-scale SAR dataset for ship wake recognition with a feature refinement oriented detector,”IEEE Geosci. Remote Sens. Lett., vol. 21, pp. 1–5, 2024
work page 2024
-
[12]
SynthwakeSAR: A synthetic SAR dataset for deep learning classification of ships at sea,
I. G. Rizaev and A. Achim, “SynthwakeSAR: A synthetic SAR dataset for deep learning classification of ships at sea,”Remote Sensing, vol. 14, no. 16, p. 3999, 2022
work page 2022
-
[13]
Imbalanced high-resolution SAR ship recognition method based on a lightweight CNN,
Y . Zhang, Z. Lei, H. Yu, and L. Zhuang, “Imbalanced high-resolution SAR ship recognition method based on a lightweight CNN,”IEEE Geosci. Remote Sens. Lett., vol. 19, pp. 1–5, 2021
work page 2021
-
[14]
SAR ship target recognition via multiscale feature attention and adaptive- weighed classifier,
C. Wang, J. Pei, S. Luo, W. Huo, Y . Huang, Y . Zhang, and J. Yang, “SAR ship target recognition via multiscale feature attention and adaptive- weighed classifier,”IEEE Geosci. Remote Sens. Lett., vol. 20, pp. 1–5, 2023
work page 2023
-
[15]
H. Zheng, Z. Hu, J. Liu, Y . Huang, and M. Zheng, “MetaBoost: A novel heterogeneous DCNNs ensemble network with two-stage filtration for SAR ship classification,”IEEE Geosci. Remote Sens. Lett., vol. 19, pp. 1–5, 2022
work page 2022
-
[16]
Danish Maritime Authority, “Historical AIS Data,” Available online at http://aisdata.ais.dk/, accessed: 25 Nov. 2025
work page 2025
-
[17]
Natural Earth, “Natural earth vector 10m map,” Available online at https://www.naturalearthdata.com/, accessed: 25 Nov. 2025
work page 2025
-
[18]
Satellite mapping reveals extensive industrial activity at sea,
F. S. Paolo, D. Kroodsma, J. Raynor, T. Hochberg, P. Davis, J. Cleary, L. Marsaglia, S. Orofino, C. Thomas, and P. Halpin, “Satellite mapping reveals extensive industrial activity at sea,”Nature, vol. 625, no. 7993, pp. 85–91, 2024
work page 2024
-
[19]
Deep Residual Learning for Image Recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,”arXiv preprint arXiv:1512.03385, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Aggregated Residual Transformations for Deep Neural Networks
S. Xie, R. Girshick, P. Doll ´ar, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,”arXiv preprint arXiv:1611.05431, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” inProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition, 2017
work page 2017
-
[22]
Efficientnetv2: Smaller models and faster training,
M. Tan and Q. Le, “Efficientnetv2: Smaller models and faster training,” inInternational conference on machine learning. PMLR, 2021, pp. 10 096–10 106
work page 2021
-
[23]
TinyViT: Fast pretraining distillation for small vision transformers,
K. Wu, J. Zhang, H. Peng, M. Liu, B. Xiao, J. Fu, and L. Yuan, “TinyViT: Fast pretraining distillation for small vision transformers,” inEuropean conference on computer vision (ECCV), 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.