Generative Giants, Retrieval Weaklings: Why do Multimodal Large Language Models Fail at Multimodal Retrieval?
Pith reviewed 2026-05-16 20:18 UTC · model grok-4.3
The pith
Multimodal large language models fail at zero-shot retrieval because textual semantics dominate their embeddings and drown out visual distinctions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
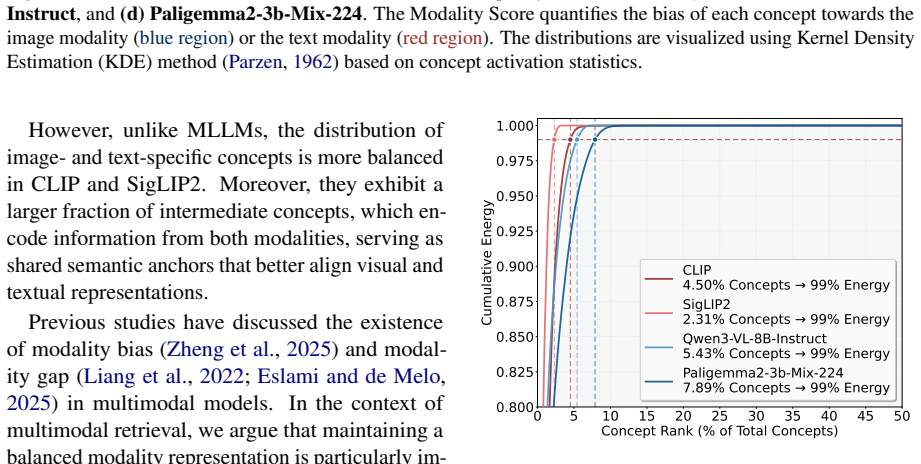
The representation space of MLLMs is overwhelmingly dominated by textual semantics while visual semantics essential for multimodal retrieval form only a small portion; the heavy emphasis on bridging image-text modalities homogenizes embeddings and reduces discriminative power, and the feature components that contribute most to similarity computations function as distractors that degrade retrieval performance. ReAlign counters this by applying a whitening transformation to adjust the geometry of MLLM representation spaces, yielding consistent gains in zero-shot multimodal retrieval.
What carries the argument
Sparse autoencoder decomposition of MLLM output representations to isolate and interpret semantic concepts, combined with ReAlign, a test-time whitening transformation that rebalances embedding geometry.
If this is right
- ReAlign delivers consistent gains in zero-shot multimodal retrieval across diverse MLLMs with no fine-tuning required.
- The same feature components that drive similarity scores also reduce retrieval accuracy when left unadjusted.
- Strong modality bridging during training improves generation but erodes the embedding separability needed for retrieval.
- Visual semantics occupy only a small fraction of the total representation space compared with textual semantics.
Where Pith is reading between the lines
- Future training objectives could add explicit penalties for visual feature collapse to better balance generation and retrieval goals.
- The same representation imbalance may limit performance on other tasks that require distinguishing fine visual details, such as visual question answering.
- Geometric corrections like ReAlign could be tested on unimodal embedding models or other cross-modal tasks where alignment has homogenized the space.
Load-bearing premise
The sparse autoencoder decomposition faithfully isolates the semantic concepts responsible for retrieval failure and the identified distractor features are causal rather than merely correlated with poor performance.
What would settle it
Selectively zeroing out the distractor feature components identified by the sparse autoencoders and measuring whether zero-shot retrieval accuracy rises on standard multimodal benchmarks.
Figures



read the original abstract
Despite the remarkable success of multimodal large language models (MLLMs) in generative tasks, we observe that they exhibit a counterintuitive deficiency in the zero-shot multimodal retrieval task. In this work, we investigate the underlying mechanisms that hinder MLLMs from being effective retrievers. With the help of sparse autoencoders (SAEs), we decompose MLLM output representations into interpretable semantic concepts to probe their intrinsic behavior. Our analysis reveals that the representation space of MLLMs is overwhelmingly dominated by textual semantics; and the visual semantics essential for multimodal retrieval only constitute a small portion. We find that this imbalance is compounded by the heavy focus of MLLMs on bridging image-text modalities, which facilitates generation but homogenizes embeddings and finally diminishes the discriminative power required for multimodal retrieval. We further discover that the specific feature components that contribute most to the similarity computations of MLLMs are actually distractors that greatly reduce retrieval performance. Building on these insights, we propose ReAlign, a test-time adaptation approach that applies a whitening transformation to adjust the geometry of MLLM representation spaces. Empirical results show that this simple intervention consistently improves zero-shot multimodal retrieval performance across diverse MLLMs without fine-tuning efforts. The code is available at https://github.com/Heinz217/mllm-retrieval-analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MLLMs excel at generation but fail at zero-shot multimodal retrieval because their representation spaces are dominated by textual semantics (with visual semantics forming only a small portion), as shown via SAE decomposition; modality-bridging homogenizes embeddings and reduces discriminative power; and specific high-contributing features act as distractors. It proposes ReAlign, a test-time whitening transformation on the representation geometry, which yields consistent empirical gains in retrieval across diverse MLLMs without any fine-tuning.
Significance. If the causal mechanism holds, the work provides a useful diagnostic of why generative MLLMs underperform on retrieval and a lightweight, training-free intervention that could be widely adopted. The SAE-based interpretability analysis and cross-model empirical consistency are strengths that could inform future balanced multimodal architectures. The result is practically relevant for retrieval-augmented systems but its significance is tempered by the correlational nature of the key mechanistic claims.
major comments (2)
- [SAE decomposition and distractor analysis sections] The central claim that specific SAE-identified feature components are causal distractors (rather than merely correlated with poor retrieval) rests on contribution analysis to similarity scores. No ablation, feature-masking, or targeted intervention experiments are reported that directly modify those components and measure the resulting change in zero-shot retrieval metrics; without such tests the causal link remains unestablished.
- [ReAlign method and experimental results] ReAlign applies a whitening transformation motivated by the SAE observations, yet the manuscript does not compare it against generic decorrelation baselines (e.g., standard PCA whitening or covariance shrinkage) that do not rely on the SAE-derived distractor identification. This leaves open whether the performance lift is specifically due to the proposed mechanism or to any decorrelating adjustment.
minor comments (2)
- [Abstract] The abstract states that ReAlign yields 'consistent empirical gains' but does not name the exact retrieval metrics (e.g., Recall@K, mAP) or the benchmark datasets; adding one sentence with these details would improve immediate readability.
- [Methods] Sparse-autoencoder training details (layer selection, sparsity coefficient, dictionary size, training corpus) are essential for reproducibility; if they are only in the appendix, a brief pointer or summary in the main methods section would help readers evaluate the decomposition fidelity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments help us clarify the strength of our mechanistic claims and the specificity of ReAlign. We provide point-by-point responses below and will revise the manuscript to incorporate the suggested analyses.
read point-by-point responses
-
Referee: [SAE decomposition and distractor analysis sections] The central claim that specific SAE-identified feature components are causal distractors (rather than merely correlated with poor retrieval) rests on contribution analysis to similarity scores. No ablation, feature-masking, or targeted intervention experiments are reported that directly modify those components and measure the resulting change in zero-shot retrieval metrics; without such tests the causal link remains unestablished.
Authors: We acknowledge that our current evidence for the causal role of the SAE-identified features as distractors is based on their contribution to the similarity scores, which is correlational. To strengthen the causal claim, we will perform additional ablation experiments in the revised version. Specifically, we will mask or zero out the top contributing features identified by the SAE analysis and report the changes in zero-shot retrieval performance. This will provide direct evidence of their impact. revision: yes
-
Referee: [ReAlign method and experimental results] ReAlign applies a whitening transformation motivated by the SAE observations, yet the manuscript does not compare it against generic decorrelation baselines (e.g., standard PCA whitening or covariance shrinkage) that do not rely on the SAE-derived distractor identification. This leaves open whether the performance lift is specifically due to the proposed mechanism or to any decorrelating adjustment.
Authors: We agree that comparing against generic decorrelation methods is important to isolate the benefit of our SAE-informed approach. In the revised manuscript, we will add experiments comparing ReAlign to standard PCA whitening and covariance shrinkage baselines. We anticipate that ReAlign will show superior performance because it specifically targets the textual dominance and distractor features identified in our analysis, rather than applying a generic transformation. revision: yes
Circularity Check
No significant circularity; analysis and proposal remain independent of inputs
full rationale
The paper applies standard sparse autoencoders to decompose MLLM representations, performs empirical observations on textual dominance and feature contributions to similarity, and proposes ReAlign as a post-hoc whitening transformation derived from those observations. No step reduces a claimed prediction or result to a fitted parameter by construction, no self-citation forms the load-bearing premise, and the whitening adjustment is presented as an external geometric correction rather than an algebraic identity with the SAE decomposition. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- whitening covariance estimate
axioms (1)
- domain assumption Sparse autoencoders decompose MLLM output representations into interpretable semantic concepts
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
With the help of sparse autoencoders (SAEs), we decompose MLLM output representations into interpretable semantic concepts... the specific feature components that contribute most to the similarity computations of MLLMs are actually distractors
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the representation space of MLLMs is overwhelmingly dominated by textual semantics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dreamsim: Learning new dimensions of hu- man visual similarity using synthetic data.arXiv preprint arXiv:2306.09344. Leo Gao, Tom Dupr’e la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. 2024. Scaling and evaluating sparse autoencoders.ArXiv, abs/2406.04093. Robert Huben, Hoagy Cunningham, Logan Rigg...
-
[2]
Lamra: Large multimodal model as your ad- vanced retrieval assistant. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 4015–4025. Computer Vision Foundation / IEEE. Zhenghao Liu, Chenyan Xiong, Yuanhuiyi Lv, Zhiyuan Liu, and Ge Yu. 2023b. Universal vision-language dense retrieval: Lea...
work page 2025
-
[3]
Towards principled evaluations of sparse au- toencoders for interpretability and control.arXiv preprint arXiv:2405.08366. Alireza Makhzani and Brendan Frey. 2014. k-sparse autoencoders.Preprint, arXiv:1312.5663. Neel Nanda. 2023. Open Source Replication & Com- mentary on Anthropic’s Dictionary Learning Paper. Bruno A. Olshausen and David J. Field. 1997. S...
-
[4]
Uniir: Training and benchmarking univer- sal multimodal information retrievers. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Pro- ceedings, Part LXXXVII, page 387–404, Berlin, Hei- delberg. Springer-Verlag. Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.