Universal Transient Stability Analysis: A Pre-trained Generative Transformer-Enabled Power System Dynamics Prediction Framework
Pith reviewed 2026-05-22 12:23 UTC · model grok-4.3
The pith
A pre-trained generative Transformer predicts power system transient dynamics across different grids with zero-shot transfer and minimal fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Uni-TSA is a pre-trained generative Transformer framework that models multivariate transient dynamics prediction as a univariate generative task. It employs channel independence decomposition, sample-wise normalization, and temporal patching to handle dimensional heterogeneity and long sequences, combined with a parameter-efficient freeze-and-finetune strategy and a two-stage scheme using teacher forcing followed by scheduled sampling. Trained solely on the New England 39-bus system, it achieves zero-shot generalization to mixed stability conditions and unseen faults, matches expert performance on the Iceland 189-bus system with only 5 percent fine-tuning data, and demonstrates strong cross-
What carries the argument
The generative Transformer backbone with parameter-efficient freeze-and-finetune, driven by a data processing pipeline that converts multivariate time series into independent univariate generative sequences via channel decomposition and temporal patching.
If this is right
- Zero-shot generalization to mixed stability conditions and unseen faults when trained only on the New England 39-bus system.
- Matching expert performance on the Iceland 189-bus system using only 5 percent fine-tuning data.
- Strong zero-shot transferability shown on IEEE 68-bus and IEEE 118-bus systems.
- Elimination of separate modeling pipelines for stable versus unstable scenarios through sample-wise normalization.
- Reduced cumulative error in long-horizon predictions via the shift from teacher forcing to scheduled sampling.
Where Pith is reading between the lines
- The method could allow grid operators to deploy a single predictive model across multiple regional networks instead of maintaining system-specific simulators.
- If extended to real-time streaming data, the approach might support online stability monitoring in grids with variable renewable generation.
- Combining the generative predictions with physics-based constraints could improve reliability on rare edge-case faults not seen in training.
- Validation against operational logs from actual utilities rather than simulated data would test whether the observed transfer holds outside controlled test cases.
Load-bearing premise
The data processing pipeline of channel independence decomposition, sample-wise normalization, and temporal patching successfully resolves dimensional heterogeneity and removes the need for separate stable/unstable modeling pipelines across heterogeneous power systems and fault scenarios.
What would settle it
A demonstration that Uni-TSA requires substantially more than 5 percent fine-tuning data to match expert accuracy on the Iceland 189-bus system or exhibits large prediction errors in zero-shot tests on mixed stability conditions and unseen faults on the New England 39-bus system would falsify the universality claim.
Figures





read the original abstract
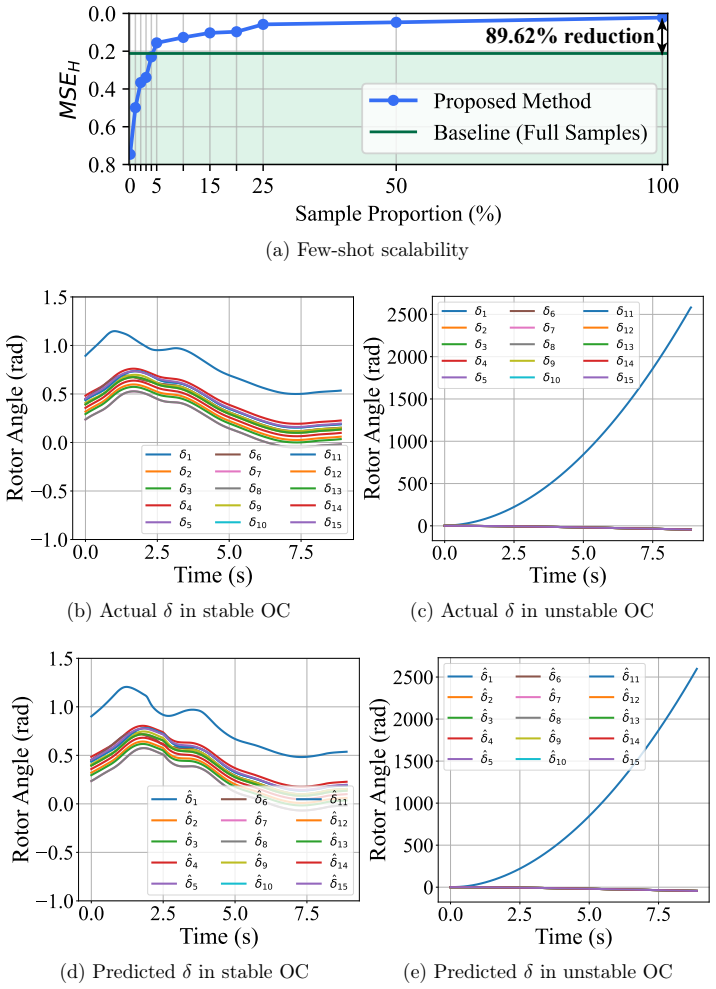
Existing dynamics prediction frameworks for transient stability analysis (TSA) fail to achieve multi-scenario "universality": the inherent ability of a single, pre-trained architecture to generalize across diverse operating conditions, unseen faults, and heterogeneous systems. To address this, this paper proposes Uni-TSA, a pre-trained generative Transformer-enabled universal framework that models multivariate transient dynamics prediction as a univariate generative task with three key innovations: First, a novel data processing pipeline featuring channel independence decomposition to resolve dimensional heterogeneity, sample-wise normalization to eliminate separate stable/unstable pipelines, and temporal patching for efficient long-sequence modeling; Second, a parameter-efficient freeze-and-finetune strategy that augments the pre-trained generative Transformer backbone with dedicated input embedding and output projection layers while freezing core transformer blocks to preserve generic feature extraction capabilities; Third, a two-stage fine-tuning scheme that combines teacher forcing, which feeds the model ground-truth data during initial training, with scheduled sampling, which gradually shifts to leveraging model-generated predictions, to mitigate cumulative errors in long-horizon iterative prediction. Comprehensive testing demonstrates the framework's universality, as Uni-TSA trained solely on the New England 39-bus system achieves zero-shot generalization to mixed stability conditions and unseen faults, and matches expert performance on the Iceland 189-bus system with only 5% fine-tuning data. Additional cross-system experiments on the IEEE 68-bus and IEEE 118-bus systems, together with stability metrics and PEBS comparison, further confirm Uni-TSA's strong zero-shot transferability and data-efficient adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Uni-TSA, a pre-trained generative Transformer framework for universal transient stability analysis (TSA) in power systems. It models multivariate dynamics prediction as a univariate generative task via a data processing pipeline (channel independence decomposition, sample-wise normalization, temporal patching), a parameter-efficient freeze-and-finetune strategy on a Transformer backbone, and a two-stage fine-tuning scheme (teacher forcing followed by scheduled sampling). The central claim is that a model pre-trained solely on the New England 39-bus system achieves zero-shot generalization to mixed stability conditions, unseen faults, and other systems (IEEE 68-bus, 118-bus), while matching expert performance on the Iceland 189-bus system using only 5% fine-tuning data, with supporting stability metrics and PEBS comparisons.
Significance. If the empirical results and generalization claims hold under rigorous validation, this would be a notable contribution to power system dynamics modeling by offering a single pre-trained architecture that reduces reliance on system-specific pipelines and enables data-efficient adaptation across heterogeneous networks and fault scenarios.
major comments (2)
- [Data Processing Pipeline] Data Processing Pipeline (as described in the abstract and the methods section detailing channel independence decomposition): Transient stability is governed by the coupled swing equations and the network admittance matrix, where perturbations propagate across buses. Treating channels independently risks discarding these topology-dependent interactions; the zero-shot transfer from the 39-bus New England system to the 189-bus Iceland system (different inertia distribution and inter-area modes) therefore rests on an untested premise that sample-wise normalization and temporal patching suffice without explicit cross-channel modeling.
- [Experimental Results] Experimental Results (abstract and the section reporting cross-system experiments): The universality and 'matches expert performance' claims are presented without quantitative metrics, error bars, or full details on how zero-shot generalization and PEBS comparisons were quantified across stability conditions. This makes it impossible to assess whether the data support the load-bearing claim of strong transferability with only 5% fine-tuning data.
minor comments (2)
- [Methods] Clarify the exact definition and implementation of 'channel independence decomposition' with a small illustrative example or pseudocode to aid reproducibility.
- Add missing references to prior work on generative models for time-series in power systems and on PEBS methods for transient stability.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which have helped us strengthen the manuscript. We address each major comment point by point below, providing clarifications and indicating revisions where appropriate to improve rigor and transparency.
read point-by-point responses
-
Referee: [Data Processing Pipeline] Data Processing Pipeline (as described in the abstract and the methods section detailing channel independence decomposition): Transient stability is governed by the coupled swing equations and the network admittance matrix, where perturbations propagate across buses. Treating channels independently risks discarding these topology-dependent interactions; the zero-shot transfer from the 39-bus New England system to the 189-bus Iceland system (different inertia distribution and inter-area modes) therefore rests on an untested premise that sample-wise normalization and temporal patching suffice without explicit cross-channel modeling.
Authors: We appreciate the referee's emphasis on the coupled nature of swing dynamics. Our channel-independence decomposition is specifically motivated by the need to accommodate dimensional heterogeneity across systems of different sizes, allowing a single pre-trained model to process univariate series per bus while preserving the ability to handle varying numbers of channels. Sample-wise normalization and temporal patching focus the model on learning transferable temporal patterns from the pre-training data, with system-specific interactions implicitly encoded via initial conditions and the fine-tuning stage on target systems. To address the concern directly, we have revised Section III-B to include an expanded discussion of this implicit capture mechanism and have added a limitations paragraph noting that explicit topology-aware extensions (e.g., graph neural components) represent a promising direction for future work. This revision clarifies the design rationale without altering the core claims. revision: partial
-
Referee: [Experimental Results] Experimental Results (abstract and the section reporting cross-system experiments): The universality and 'matches expert performance' claims are presented without quantitative metrics, error bars, or full details on how zero-shot generalization and PEBS comparisons were quantified across stability conditions. This makes it impossible to assess whether the data support the load-bearing claim of strong transferability with only 5% fine-tuning data.
Authors: We agree that additional quantitative details and statistical rigor are necessary to fully substantiate the generalization claims. In the revised manuscript, we have expanded the experimental results section with detailed tables reporting MSE, stability classification accuracy, and PEBS deviation metrics for zero-shot and fine-tuned scenarios across all systems and stability conditions. We now include error bars (standard deviation over 10 independent runs with varied random seeds) and a step-by-step description of the evaluation protocol, including how the 5% fine-tuning data was selected and how PEBS comparisons were performed. These additions directly support the transferability claims with transparent metrics. revision: yes
Circularity Check
No circularity: empirical ML framework with experimental validation
full rationale
The paper proposes an empirical pre-trained Transformer framework for power system dynamics prediction, relying on data processing innovations (channel independence, normalization, patching), freeze-and-finetune strategy, and two-stage training with teacher forcing/scheduled sampling. Claims of universality and zero-shot generalization are supported by experiments across New England 39-bus, Iceland 189-bus, and other systems, not by any mathematical derivation or first-principles result. No equations reduce to self-defined quantities, fitted parameters renamed as predictions, or load-bearing self-citations. The approach is self-contained through pre-training on one system and empirical testing on others, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained Transformer blocks preserve generic feature extraction capabilities when frozen and augmented only with task-specific embedding and projection layers.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
models multivariate transient dynamics prediction as a univariate generative task with ... channel independence decomposition ... sample-wise normalization ... temporal patching
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GPT architecture ... causal attention mechanisms ... two-stage fine-tuning scheme (teacher forcing + scheduled sampling)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
C. Shen, K. Zuo, M. Sun, Physics-following neural network for online dynamic security assessment, IEEE Transactions on Power Systems (2025)
work page 2025
-
[2]
X. Ye, A. Radovanovic, J. V. Milanovic, The use of machine learning for prediction of post-fault rotor angle trajectories, IEEE Transactions on Power Systems 39 (5) (2024) 6496–6507
work page 2024
-
[3]
T. Zhao, M. Yue, J. Wang, Structure-informed graph learning of net- worked dependencies for online prediction of power system transient dynamics, IEEE Transactions on Power Systems 37 (6) (2022) 4885– 4895
work page 2022
-
[4]
Z. Qiu, C. Duan, W. Yao, P. Zeng, L. Jiang, Adaptive lyapunov function method for power system transient stability analysis, IEEE Transactions on Power Systems 38 (4) (2022) 3331–3344
work page 2022
-
[5]
S. K. Azman, Y. J. Isbeih, M. S. El Moursi, K. Elbassioni, A unified online deep learning prediction model for small signal and transient stability, IEEE transactions on power systems 35 (6) (2020) 4585–4598
work page 2020
-
[6]
Q. Zhou, J. Davidson, A. Fouad, Application of artificial neural networks inpowersystemsecurityandvulnerabilityassessment, IEEETransactions on Power Systems 9 (1) (1994) 525–532
work page 1994
-
[7]
F. R. Gomez, A. D. Rajapakse, U. D. Annakkage, I. T. Fernando, Support vector machine-based algorithm for post-fault transient stability status prediction using synchronized measurements, IEEE Transactions on Power systems 26 (3) (2010) 1474–1483
work page 2010
-
[8]
K. Sun, S. Likhate, V. Vittal, V. S. Kolluri, S. Mandal, An online dynamic security assessment scheme using phasor measurements and decision trees, IEEE Transactions on Power Systems 22 (4) (2007) 1935– 1943.doi:10.1109/TPWRS.2007.908476
-
[9]
Q. Chen, N. Lin, S. Bu, H. Wang, B. Zhang, Interpretable time-adaptive transient stability assessment based on dual-stage attention mechanism, IEEE Transactions on Power Systems 38 (3) (2022) 2776–2790. 31
work page 2022
-
[10]
C. Ren, Y. Xu, R. Zhang, An interpretable deep learning method for power system transient stability assessment via tree regularization, IEEE Transactions on Power Systems 37 (5) (2021) 3359–3369
work page 2021
-
[11]
L. Zhu, W. Wen, J. Li, Y. Hu, Integrated data-driven power system transient stability monitoring and enhancement, IEEE Transactions on Power Systems 39 (1) (2023) 1797–1809
work page 2023
- [12]
-
[13]
L. Zhu, D. J. Hill, C. Lu, Hierarchical deep learning machine for power system online transient stability prediction, IEEE Transactions on Power Systems 35 (3) (2019) 2399–2411
work page 2019
-
[14]
L. Zhu, D. J. Hill, Networked time series shapelet learning for power sys- tem transient stability assessment, IEEE Transactions on Power Systems 37 (1) (2021) 416–428
work page 2021
-
[15]
G. S. Misyris, A. Venzke, S. Chatzivasileiadis, Physics-informed neural networks for power systems, in: 2020 IEEE power & energy society general meeting (PESGM), IEEE, 2020, pp. 1–5
work page 2020
-
[16]
W. Cui, W. Yang, B. Zhang, A frequency domain approach to predict power system transients, IEEE Transactions on Power Systems 39 (1) (2023) 465–477
work page 2023
-
[17]
B. Tan, J. Zhao, Bayesian post-fault power system dynamic trajectory prediction, IEEE Transactions on Power Systems (2025)
work page 2025
-
[18]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al., Gpt-4 technical report, arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
S. Tu, Y. Zhang, J. Zhang, Z. Fu, Y. Zhang, Y. Yang, Powerpm: Founda- tion model for power systems, Advances in Neural Information Processing Systems 37 (2024) 115233–115260
work page 2024
-
[20]
Y. Liu, H. Zhang, C. Li, X. Huang, J. Wang, M. Long, Timer: generative pre-trained transformers are large time series models, in: Proceedings 32 of the 41st International Conference on Machine Learning, 2024, pp. 32369–32399
work page 2024
-
[21]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
work page 2017
-
[22]
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al., Language models are unsupervised multitask learners, OpenAI blog 1 (8) (2019) 9
work page 2019
-
[23]
A. M. Lamb, A. G. ALIAS PARTH GOYAL, Y. Zhang, S. Zhang, A. C. Courville, Y. Bengio, Professor forcing: A new algorithm for training recurrent networks, Advances in neural information processing systems 29 (2016)
work page 2016
-
[24]
H. Cai, H. Ma, D. J. Hill, A data-based learning and control method for long-term voltage stability, IEEE Transactions on Power Systems 35 (4) (2020) 3203–3212
work page 2020
-
[25]
G. Lu, S. Bu, Advanced probabilistic transient stability assessment for operational planning: A physics-informed graphical learning approach, IEEE Transactions on Power Systems (2024)
work page 2024
-
[26]
T. Zhou, P. Niu, L. Sun, R. Jin, et al., One fits all: Power general time series analysis by pretrained lm, Advances in neural information processing systems 36 (2023) 43322–43355
work page 2023
-
[27]
H. Kim, G. Papamakarios, A. Mnih, The lipschitz constant of self- attention, in: International Conference on Machine Learning, PMLR, 2021, pp. 5562–5571. 33
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.