FETAL-GAUGE: A Benchmark for Assessing Vision-Language Models in Fetal Ultrasound
Pith reviewed 2026-05-16 20:03 UTC · model grok-4.3
The pith
Current vision-language models achieve only 55% accuracy on fetal ultrasound tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
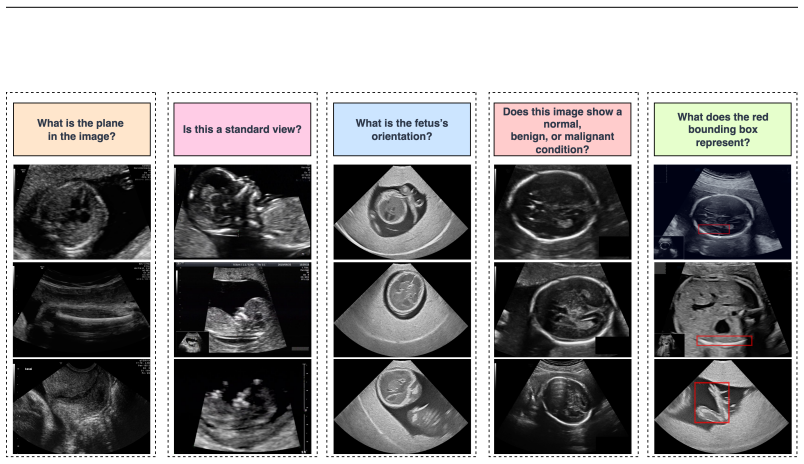
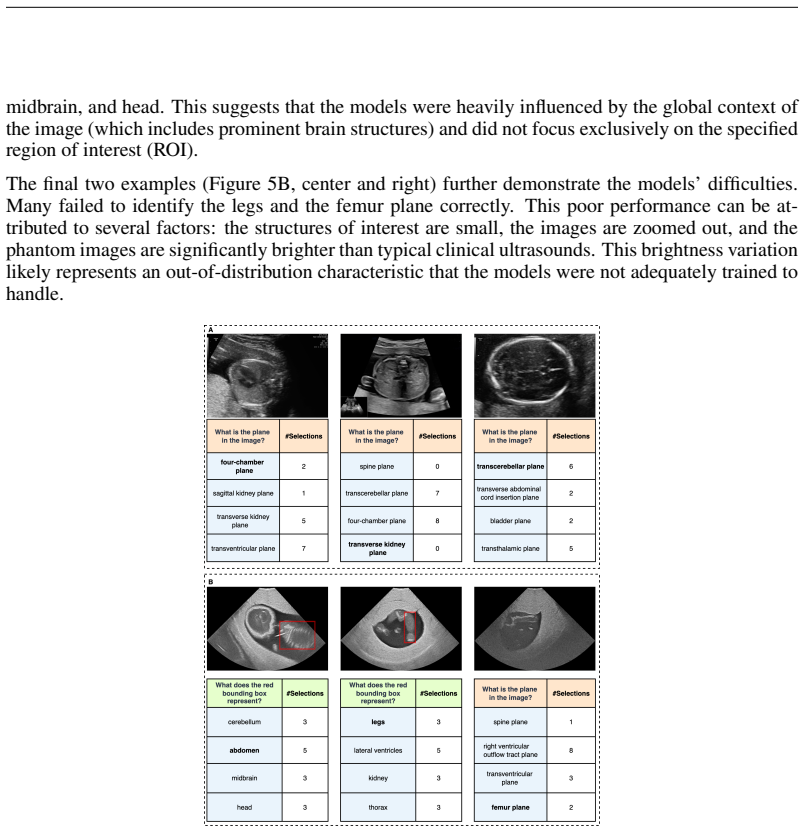
Fetal-Gauge provides the first standardized benchmark for vision-language models in fetal ultrasound, built from over 42,000 images and 93,000 question-answer pairs across anatomical plane identification, visual grounding of structures, fetal orientation, clinical view conformity, and diagnosis. Systematic testing of state-of-the-art general-purpose and medical VLMs reveals that the best model attains only 55% accuracy, demonstrating substantial limitations in interpreting operator-dependent ultrasound images and establishing the requirement for domain-adapted architectures and training methods.
What carries the argument
The Fetal-Gauge benchmark, a collection of ultrasound images paired with question-answer pairs that tests five specific clinical tasks in a single multimodal evaluation framework.
Load-bearing premise
The benchmark's constructed question-answer pairs and tasks faithfully represent real clinical challenges in fetal ultrasound without introducing annotation biases or unrealistic simplifications.
What would settle it
A vision-language model trained specifically on fetal ultrasound data that achieves substantially higher accuracy than 55% across the full set of tasks in Fetal-Gauge would show that the observed performance gap can be closed.
Figures



read the original abstract
The growing demand for prenatal ultrasound imaging has intensified a global shortage of trained sonographers, creating barriers to essential fetal health monitoring. Deep learning has the potential to enhance sonographers' efficiency and support the training of new practitioners. Vision-Language Models (VLMs) are particularly promising for ultrasound interpretation, as they can jointly process images and text to perform multiple clinical tasks within a single framework. However, despite the expansion of VLMs, no standardized benchmark exists to evaluate their performance in fetal ultrasound imaging. This gap is primarily due to the modality's challenging nature, operator dependency, and the limited public availability of datasets. To address this gap, we present Fetal-Gauge, the first and largest visual question answering benchmark specifically designed to evaluate VLMs across various fetal ultrasound tasks. Our benchmark comprises over 42,000 images and 93,000 question-answer pairs, spanning anatomical plane identification, visual grounding of anatomical structures, fetal orientation assessment, clinical view conformity, and clinical diagnosis. We systematically evaluate several state-of-the-art VLMs, including general-purpose and medical-specific models, and reveal a substantial performance gap: the best-performing model achieves only 55\% accuracy, far below clinical requirements. Our analysis identifies critical limitations of current VLMs in fetal ultrasound interpretation, highlighting the urgent need for domain-adapted architectures and specialized training approaches. Fetal-Gauge establishes a rigorous foundation for advancing multimodal deep learning in prenatal care and provides a pathway toward addressing global healthcare accessibility challenges. Our benchmark will be publicly available once the paper gets accepted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Fetal-Gauge, the first large-scale VQA benchmark for fetal ultrasound, comprising over 42,000 images and 93,000 QA pairs across five tasks (anatomical plane identification, visual grounding, fetal orientation assessment, clinical view conformity, and diagnosis). It evaluates multiple general-purpose and medical VLMs, reports that the best model reaches only 55% accuracy, interprets this as far below clinical requirements, identifies limitations in current VLMs, and calls for domain-adapted architectures and training.
Significance. If the benchmark tasks are shown to be solvable at high accuracy by experts and the evaluation protocol is fully specified, the work could usefully document current VLM shortcomings in a clinically relevant but operator-dependent modality and motivate targeted improvements for prenatal imaging. The scale of the dataset and multi-task coverage are positive features, but the absence of any human expert baseline or inter-rater metrics on the same items limits the ability to interpret the 55% figure as evidence of model inadequacy versus benchmark noise.
major comments (2)
- [Abstract] Abstract: the central claim that 55% accuracy is 'far below clinical requirements' is load-bearing yet unanchored, because no expert sonographer performance, inter-annotator agreement, or clinical accuracy target is reported on the Fetal-Gauge QA pairs; without this baseline it is impossible to separate model limitations from inherent ultrasound ambiguity.
- [Experiments / Evaluation] Evaluation protocol (described in the abstract and experiments section): the manuscript supplies no details on dataset curation, QA validation steps, statistical testing of the performance gap, or error analysis, rendering the reported 55% figure difficult to interpret or reproduce.
minor comments (2)
- [Abstract] The abstract states the benchmark 'will be publicly available once the paper gets accepted' but provides no repository link, license, or access instructions.
- [Introduction / Benchmark Description] Notation for the five tasks is introduced without a summary table mapping task names to exact question templates or answer formats.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript introducing Fetal-Gauge. We address each of the major comments below and describe the revisions we intend to make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 55% accuracy is 'far below clinical requirements' is load-bearing yet unanchored, because no expert sonographer performance, inter-annotator agreement, or clinical accuracy target is reported on the Fetal-Gauge QA pairs; without this baseline it is impossible to separate model limitations from inherent ultrasound ambiguity.
Authors: We acknowledge the validity of this point. The manuscript does not include direct expert baselines on the Fetal-Gauge QA pairs, which limits the strength of the claim. In the revised version, we will qualify the statement in the abstract to indicate that the 55% performance is substantially lower than typical clinical expectations for sonographers in fetal ultrasound tasks (citing relevant literature on sonographer accuracy), and we will add a dedicated limitations section discussing the potential for inherent ambiguity in the modality and the absence of direct inter-rater metrics on these specific items. We will also compute and report inter-annotator agreement for the QA pairs where multiple annotations exist. revision: yes
-
Referee: [Experiments / Evaluation] Evaluation protocol (described in the abstract and experiments section): the manuscript supplies no details on dataset curation, QA validation steps, statistical testing of the performance gap, or error analysis, rendering the reported 55% figure difficult to interpret or reproduce.
Authors: We agree that more detailed information is necessary for reproducibility and interpretation. Although the full manuscript contains a section on benchmark construction, we will significantly expand the Experiments section to include: (1) a detailed description of the dataset curation process, including sources and selection criteria; (2) explicit steps for QA validation, such as expert review of question-answer pairs; (3) statistical analysis including confidence intervals and tests for performance differences; and (4) a comprehensive error analysis breaking down failure modes across tasks and models. These additions will make the evaluation protocol fully transparent. revision: yes
Circularity Check
Empirical benchmark reporting with no derivations or self-referential reductions
full rationale
The paper constructs a VQA benchmark (42k images, 93k QA pairs) across five tasks and directly measures VLM accuracies, with the highest at 55%. No equations, fitted parameters, or first-principles derivations exist whose outputs are defined by the inputs. The performance numbers are raw empirical results on the released items, not predictions forced by construction or renamed fits. No self-citations are invoked to justify uniqueness theorems or ansatzes. The central claim of a performance gap is therefore an independent measurement rather than a tautology, satisfying the default expectation of no significant circularity for a benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ultrasound fetus dataset.https://doi.org/10.17632/yrzzw9m6kk.1,
A Anitha. Ultrasound fetus dataset.https://doi.org/10.17632/yrzzw9m6kk.1,
-
[2]
S. Belciug. Fetal planes and organs.https://doi.org/10.5281/zenodo.14093338,
-
[3]
Data set. Smaranda Belciug. 3vessels + gallbladder.https://doi.org/10.5281/zenodo. 7323401,
-
[4]
InPro- ceedings of CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes. 9-12 September 2019,
work page 2019
-
[5]
Fetal abdominal structures segmentation dataset using ultrasonic images
Karine Souza Da Correggio, Roberto Noya Galluzzo, Lu ´ıs Ot´avio Santos, Felipe Soares Muy- laert Barroso, Thiago Zimmermann Loureiro Chaves, Alexandre Sherlley Casimiro Onofre, and Aldo von Wangenheim. Fetal abdominal structures segmentation dataset using ultrasonic images. https://doi.org/10.17632/4gcpm9dsc3.1,
-
[6]
Aya vision: Advancing the frontier of multilingual multimodality.arXiv preprint arXiv:2505.08751,
Saurabh Dash, Yiyang Nan, John Dang, Arash Ahmadian, Shivalika Singh, Madeline Smith, Bharat Venkitesh, Vlad Shmyhlo, Viraat Aryabumi, Walter Beller-Morales, et al. Aya vision: Advancing the frontier of multilingual multimodality.arXiv preprint arXiv:2505.08751,
-
[7]
Annual population births by country in 2024,
Database Earth. Annual population births by country in 2024,
work page 2024
-
[8]
URLhttps://database. earth/population/births/2024. Accessed: 2025-08-16. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pp. arXiv–2407,
work page 2024
-
[9]
doi: 10.1590/1516-3180.2019.026906082019. 10 D. Gonz´alez, J. P. Barrientos, M. Perez, J. Fajardo, F. Reyna, and A. Lara. Natalia: Pbf-us1 (phan- tom blind-sweeps for fetal ultrasound scanning),
-
[10]
PathVQA: 30000+ Questions for Medical Visual Question Answering
URLhttps://doi.org/10.5281/ zenodo.14193949. [Data set]. Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arxiv 2021.arXiv preprint arXiv:2106.09685, 10,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Fadillah Maani, Numan Saeed, Tausifa Saleem, Zaid Farooq, Hussain Alasmawi, Werner Diehl, Ameera Mohammad, Gareth Waring, Saudabi Valappi, Leanne Bricker, et al. Fetalclip: A visual- language foundation model for fetal ultrasound image analysis.arXiv preprint arXiv:2502.14807,
-
[13]
Gpt-image-1.https://openai.com/index/image-generation-api/, 2025a
Large language model. Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. Medvlm-r1: Incentivizing medical reasoning capability of vision- language models (vlms) via reinforcement learning.arXiv preprint arXiv:2502.19634,
-
[14]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C ´ıan Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Belay Susu, Kibir Temesgen, Sindu Ayalew, Selam Yibeltal, Tadele Emagneneh, Adem Yesuf, and Chalie Mulugeta. Prenatal ultrasound utilization and associated factors among pregnant women attending antenatal care in south wollo zone public hospitals, north east, ethiopia, 2023.Frontiers in Digital Health, 7:1547547,
work page 2023
-
[16]
URL https://arxiv.org/abs/2508.15298. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.ar...
-
[17]
Songxiong Wu, Hongyuan Zhang, Tingting Ye, Haoyu Xie, Ping Zeng, Qingjun Sun, Panying Wang, Bingsheng Huang, Lei Du, and Guangyao Wu. Focus: Four-chamber ultrasound image dataset for fetal cardiac biometric measurement.https://doi.org/10.5281/zenodo.14597550,
-
[18]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Cheng- hao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foun- dation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Guiming Chen, Jianquan Li, Xiangbo Wu, Zhang Zhiyi, Qingying Xiao, Xiang Wan, Benyou Wang, and Haizhou Li. Hu- atuoGPT, towards taming language model to be a doctor. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.),Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 10...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.findings-emnlp.725 2023
-
[20]
12 7 APPENDIX Table 3: Dataset-wise distribution of images and corresponding questions across training and testing splits. The values represent the number of images, with the number of associated questions shown in parentheses. Dataset Name Train Test Total 3-Vessel View Dataset Belciug (2022) 0(0) 253(253) 253(253) FASS Da Correggio et al. (2023) 1,265(4...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.