Geometric Scaling of Bayesian Inference in LLMs
Pith reviewed 2026-05-21 16:05 UTC · model grok-4.3
The pith
Large language models retain the low-dimensional geometric substrate that supports approximate Bayesian inference, organizing their value representations along an entropy-correlated axis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
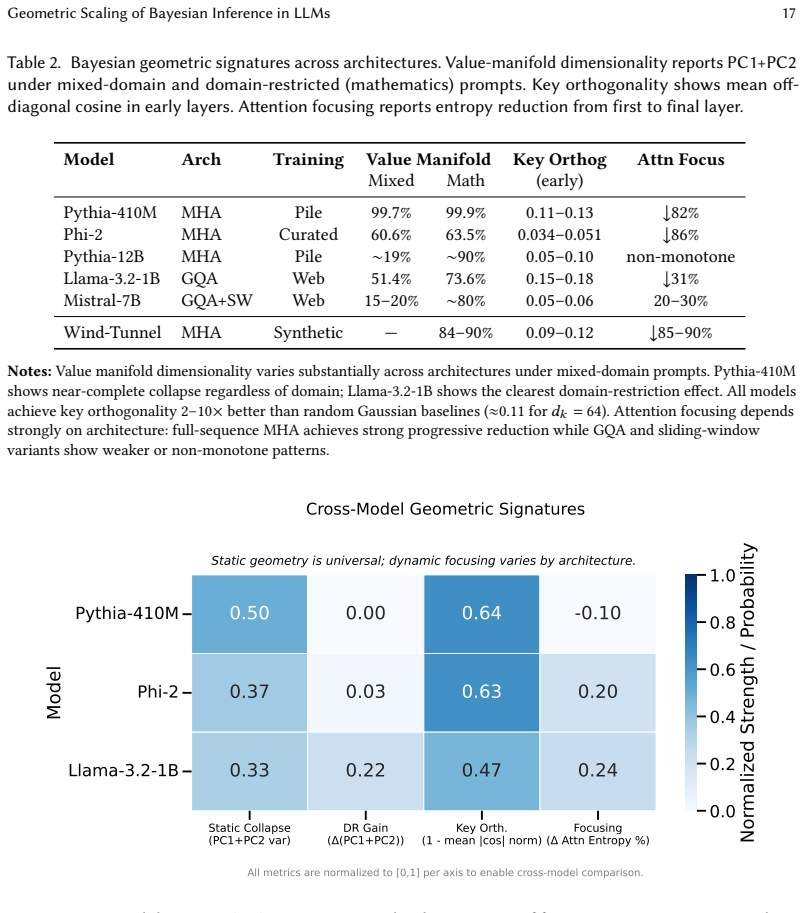
Across Pythia, Phi-2, Llama-3 and Mistral families, last-layer value representations organize along a single dominant axis whose position correlates strongly with predictive entropy. Domain-restricted prompts cause this structure to collapse into the low-dimensional manifolds previously observed in wind-tunnel settings. Interventions that remove or perturb the entropy-aligned axis disrupt the local uncertainty geometry, whereas matched interventions on random axes leave it intact, although the single-layer changes do not yield proportionally specific degradation in overall Bayesian-like performance.
What carries the argument
The single dominant axis in last-layer value representations that correlates with predictive entropy, acting as a readout of the low-dimensional geometric substrate for posterior structure.
If this is right
- Domain-restricted prompts collapse the representation structure into the same low-dimensional manifolds seen in controlled settings.
- Perturbing the entropy-aligned axis selectively disrupts local uncertainty geometry while random-axis perturbations do not.
- The geometry serves as a privileged readout of uncertainty rather than the sole computational bottleneck for Bayesian-like updates.
- Approximate Bayesian behavior in scaled models continues to rely on the same geometric organization observed in smaller models.
Where Pith is reading between the lines
- Monitoring or editing the dominant axis could provide a practical lever for adjusting uncertainty estimates without retraining the full model.
- The preservation of this geometry across scales suggests that in-context posterior updates in large models may remain geometrically interpretable.
- Similar axes may exist in other architectures or modalities, offering a route to test whether the substrate is architecture-specific or more universal.
- If the axis can be isolated reliably, it could inform lightweight methods for detecting or mitigating over in deployed systems.
Load-bearing premise
The dominant axis found in production models encodes the same low-dimensional geometric substrate for posterior structure that was identified in the smaller synthetic wind-tunnel models.
What would settle it
Observing either no statistical correlation between axis position and predictive entropy in additional model families or that axis perturbations produce no measurable change in any downstream uncertainty metric.
Figures







read the original abstract
Recent work has shown that small transformers trained in controlled "wind-tunnel'' settings can implement exact Bayesian inference, and that their training dynamics produce a geometric substrate -- low-dimensional value manifolds and progressively orthogonal keys -- that encodes posterior structure. We investigate whether this geometric signature persists in production-grade language models. Across Pythia, Phi-2, Llama-3, and Mistral families, we find that last-layer value representations organize along a single dominant axis whose position strongly correlates with predictive entropy, and that domain-restricted prompts collapse this structure into the same low-dimensional manifolds observed in synthetic settings. To probe the role of this geometry, we perform targeted interventions on the entropy-aligned axis of Pythia-410M during in-context learning. Removing or perturbing this axis selectively disrupts the local uncertainty geometry, whereas matched random-axis interventions leave it intact. However, these single-layer manipulations do not produce proportionally specific degradation in Bayesian-like behavior, indicating that the geometry is a privileged readout of uncertainty rather than a singular computational bottleneck. Taken together, our results show that modern language models preserve the geometric substrate that enables Bayesian inference in wind tunnels, and organize their approximate Bayesian updates along this substrate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that production-grade LLMs (Pythia, Phi-2, Llama-3, Mistral) preserve the low-dimensional geometric substrate for Bayesian inference previously identified in synthetic wind-tunnel transformers—specifically, last-layer value representations collapse along a single dominant axis strongly correlated with predictive entropy, and domain-restricted prompts induce the same manifold structure. Targeted interventions on this axis in Pythia-410M disrupt local uncertainty geometry while matched random interventions do not; however, these manipulations do not produce proportionally specific degradation in Bayesian-like behavior, which the authors interpret as evidence that the geometry is a privileged readout rather than a computational bottleneck. The overall conclusion is that modern LLMs preserve this substrate and organize their approximate Bayesian updates along it.
Significance. If the single-axis structure can be shown to be quantitatively equivalent to the multi-dimensional value manifolds and orthogonal keys of the wind-tunnel setting, and if the intervention results can be reconciled with the 'enables' and 'organize along this substrate' language, the work would usefully bridge controlled synthetic findings to real LLMs and provide a geometric account of uncertainty representation during in-context learning. The absence of such equivalence metrics and the interpretive tension noted below limit the strength of this bridge at present.
major comments (2)
- [Abstract] Abstract: the central claim that LLMs 'preserve the geometric substrate that enables Bayesian inference in wind tunnels, and organize their approximate Bayesian updates along this substrate' is in tension with the reported intervention results on Pythia-410M. The abstract states that single-layer manipulations of the entropy-aligned axis 'do not produce proportionally specific degradation in Bayesian-like behavior,' leading to the interpretation that the geometry is a 'privileged readout of uncertainty rather than a singular computational bottleneck.' This directly undercuts the 'enables' and 'organize their approximate Bayesian updates along' phrasing without additional quantitative evidence that the axis is causally load-bearing for the Bayesian-like computations.
- [Abstract] Abstract and methods (intervention section): no quantitative metric is described that equates the observed single dominant entropy-correlated axis (and its collapse under domain-restricted prompts) in last-layer value representations to the multi-dimensional value manifolds with progressively orthogonal keys documented in the synthetic wind-tunnel transformers. Without such a metric (e.g., a distance between manifold geometries or a shared dimensionality measure), the assertion that the LLM structure 'constitutes the same low-dimensional geometric substrate' remains unverified.
minor comments (2)
- [Abstract] Abstract and methods: the summary reports correlations and targeted interventions but provides no details on controls, statistical tests, or full experimental methods for the entropy-axis measurements and Bayesian-like behavior assays. These should be expanded for reproducibility.
- The paper should clarify whether the 'Bayesian-like behavior' metrics used in the intervention experiments are the same as those validated in the original wind-tunnel work or are new proxies.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help clarify the presentation of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that LLMs 'preserve the geometric substrate that enables Bayesian inference in wind tunnels, and organize their approximate Bayesian updates along this substrate' is in tension with the reported intervention results on Pythia-410M. The abstract states that single-layer manipulations of the entropy-aligned axis 'do not produce proportionally specific degradation in Bayesian-like behavior,' leading to the interpretation that the geometry is a 'privileged readout of uncertainty rather than a singular computational bottleneck.' This directly undercuts the 'enables' and 'organize their approximate Bayesian updates along' phrasing without additional quantitative evidence that the axis is causally load-bearing for the Bayesian-like computations.
Authors: We appreciate the referee highlighting the potential inconsistency in the abstract's language. The intervention experiments on Pythia-410M demonstrate that perturbing the entropy-aligned axis disrupts the local uncertainty geometry but does not cause a proportional degradation in the overall Bayesian-like behavior. This leads us to conclude that the geometry acts as a privileged readout rather than a singular bottleneck. The claim that LLMs 'preserve the geometric substrate that enables Bayesian inference in wind tunnels' refers to the continuity with the synthetic findings, and 'organize their approximate Bayesian updates along this substrate' is supported by the observed correlations and manifold structures. To address the tension, we will revise the abstract to more precisely state that the geometry is preserved and serves as an organizing principle for uncertainty representations, while clarifying the implications of the intervention results. revision: yes
-
Referee: [Abstract] Abstract and methods (intervention section): no quantitative metric is described that equates the observed single dominant entropy-correlated axis (and its collapse under domain-restricted prompts) in last-layer value representations to the multi-dimensional value manifolds with progressively orthogonal keys documented in the synthetic wind-tunnel transformers. Without such a metric (e.g., a distance between manifold geometries or a shared dimensionality measure), the assertion that the LLM structure 'constitutes the same low-dimensional geometric substrate' remains unverified.
Authors: We agree that the manuscript would benefit from a quantitative metric to establish equivalence between the LLM observations and the wind-tunnel results. Currently, the connection is drawn through the shared low-dimensional collapse and entropy correlation. In the revision, we will introduce a metric, for example, by comparing the fraction of variance explained by the dominant axis in LLMs to the effective dimensionality in the synthetic models, or by applying a subspace similarity measure. This will be added to the methods and results sections to verify that the LLM structure constitutes the same low-dimensional geometric substrate. revision: yes
Circularity Check
No significant circularity in empirical observations and interventions
full rationale
The paper reports direct empirical measurements of last-layer value representations across multiple LLM families, their correlation with predictive entropy, and the effects of targeted interventions on Pythia-410M. These observations and ablation results are independent of any fitted parameters or self-referential definitions within the present work. The comparison to wind-tunnel settings is framed as an external benchmark rather than a derivation that reduces to the current inputs by construction. No equations, predictions, or ansatzes are shown to collapse into prior fits or self-citations in a load-bearing manner.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Position along the dominant value axis encodes predictive entropy and thereby posterior structure.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
last-layer value representations organize along a single dominant axis whose position strongly correlates with predictive entropy, and that domain-restricted prompts collapse this structure into the same low-dimensional manifolds observed in synthetic settings
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
value manifolds: last-layer value vectors form low-dimensional trajectories parameterized by predictive entropy (PC1 explains 84–90%)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gradient Dynamics of Attention: How Cross-Entropy Sculpts Bayesian Manifolds
Naman Agarwal, Siddhartha R. Dalal, and Vishal Misra. 2025. Gradient Dynamics of Attention: How Cross-Entropy Sculpts Bayesian Manifolds. arXiv:2512.22473 [cs.LG] https://arxiv.org/abs/2512.22473 Paper II of the Bayesian Attention Trilogy
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. Layer Normalization.arXiv preprint arXiv:1607.06450 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Nathan Belrose, Minjoon Huh, Anca Dragan, and Dylan Hadfield-Menell. 2023. Tuned Lens: Identifying and Manipu- lating Interpretable Representations in Language Models.arXiv preprint arXiv:2303.08112(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Moham- mad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. 2023. Pythia: A suite for analyzing large language models across training and scaling.International Conference on Machine Learning(2023), 2397–2430
work page 2023
-
[5]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, et al. 2020. Language Models are Few-Shot Learners.Advances in Neural Information Processing Systems33 (2020), 1877–1901
work page 2020
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. What Does BERT Look At? An Analysis of BERT’s Attention. InProceedings of the 2019 ACL Workshop BlackboxNLP. 276–286
work page 2019
-
[8]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, et al. 2021. A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread, Anthropic. https://transformer-circuits.pub/2021/ framework/index.html
work page 2021
-
[9]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. 2...
work page 2021
- [10]
-
[11]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, et al. 2022. In-Context Learning and Induction Heads. Transformer Circuits Thread, Anthropic. https://transformer-circuits.pub/2022/in-context-learning- and-induction-heads/index.html
work page 2022
-
[12]
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, et al. 2022. In-Context Learning and Induction Heads. Transformer Circuits Thread, Anthropic. https://transformer- circuits.pub/2022/in-contex...
work page 2022
-
[13]
OpenAI. 2024. OpenAI o1: A New Class of Reasoning Models.OpenAI Technical Report(2024)
work page 2024
-
[14]
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 5797–5808. , Vol. 1, No. 1, Article . Publication date: January
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.