Context-Aware Semantic Segmentation via Stage-Wise Attention
Pith reviewed 2026-05-16 13:29 UTC · model grok-4.3
The pith
A dual-branch Swin transformer adds low-resolution context to high-resolution features through stage-wise cross-attention for ultra-high-resolution semantic segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CASWiT is a dual-branch Swin-based architecture that injects low-resolution contextual information into fine-grained high-resolution features through lightweight stage-wise cross-attention, combined with a SimMIM-style masked reconstruction pretraining of the high-resolution image.
What carries the argument
Stage-wise cross-attention between a low-resolution context branch and a high-resolution detail branch inside a dual Swin transformer.
If this is right
- The architecture reaches 66.37 percent mIoU on the FLAIR-HUB aerial dataset under an RGB-only ultra-high-resolution protocol while improving boundary quality over strong baselines.
- The same model records 49.2 percent mIoU on the URUR benchmark under the official protocol.
- The pretrained weights transfer directly to medical ultra-high-resolution segmentation tasks without retraining the core attention blocks.
- Memory usage stays linear in the number of high-resolution tokens because the low-resolution branch supplies context at fixed cost.
Where Pith is reading between the lines
- The same stage-wise injection pattern could be tested on video or 3-D volumetric data where one axis supplies cheap context for another.
- If the cross-attention layers remain stable across sensors, the method may reduce the need for task-specific architectural search in remote-sensing pipelines.
- Replacing the Swin backbone with other hierarchical encoders might reveal whether the performance gain is tied to the specific token-merging schedule.
Load-bearing premise
Stage-wise cross-attention between low- and high-resolution branches reliably transfers useful context without adding noise or requiring per-dataset retuning.
What would settle it
Training the same dual-branch model on the FLAIR-HUB dataset but replacing the stage-wise cross-attention blocks with simple concatenation or addition, then measuring whether mIoU falls below the reported single-branch baselines and boundary metrics degrade.
Figures







read the original abstract
Semantic ultra-high-resolution (UHR) image segmentation is essential in remote sensing applications such as aerial mapping and environmental monitoring. Transformer-based models remain challenging in this setting because memory grows quadratically with the number of tokens, limiting either spatial resolution or contextual scope. We introduce CASWiT (Context-Aware Stage-Wise Transformer), a dual-branch Swin-based architecture that injects low-resolution contextual information into fine-grained high-resolution features through lightweight stage-wise cross-attention. To strengthen cross-scale learning, we also propose a SimMIM-style pretraining strategy based on masked reconstruction of the high-resolution image. Extensive experiments on the large-scale FLAIR-HUB aerial dataset demonstrate the effectiveness of CASWiT. Under our RGB-only UHR protocol, CASWiT reaches 66.37% mIoU with a SegFormer decoder, improving over strong RGB baselines while also improving boundary quality. On the URUR benchmark, CASWiT reaches 49.2% mIoU under the official evaluation protocol, and it also transfers effectively to medical UHR segmentation benchmarks. Code and pretrained models are available at https://huggingface.co/collections/heig-vd-geo/caswit
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CASWiT, a dual-branch Swin-based architecture for ultra-high-resolution semantic segmentation. It injects low-resolution contextual information into high-resolution features via lightweight stage-wise cross-attention and uses a SimMIM-style masked reconstruction pretraining strategy. Experiments report 66.37% mIoU on FLAIR-HUB under an RGB-only UHR protocol (with SegFormer decoder) and 49.2% mIoU on URUR, with claims of improved boundary quality and effective transfer to medical benchmarks; code and models are released.
Significance. If the stage-wise cross-attention demonstrably adds signal rather than noise or redundancy, the method could meaningfully address quadratic memory scaling in transformers for remote-sensing UHR tasks while preserving fine detail. Code and pretrained-model release is a clear strength for reproducibility. Significance is currently limited by the absence of controls that isolate the attention mechanism from pretraining and dual-branch design.
major comments (2)
- [Experiments] Experiments section (results on FLAIR-HUB and URUR): the headline mIoU gains (66.37% and 49.2%) are reported without ablations that hold SimMIM pretraining, decoder choice, and dual-branch structure fixed while toggling only the stage-wise cross-attention blocks. This leaves open the possibility that observed deltas arise from pretraining or the mere presence of a low-resolution branch rather than context injection.
- [Method] Method description of cross-attention: no quantitative analysis (e.g., attention-map statistics, noise-injection tests, or failure-case examination) is provided to confirm that low-to-high resolution context transfer reliably adds useful signal without introducing boundary or class-label degradation.
minor comments (1)
- [Abstract] Abstract: the phrase 'improving over strong RGB baselines' should name the specific baselines and their scores for immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper accordingly to strengthen the experimental validation and analysis of the cross-attention mechanism.
read point-by-point responses
-
Referee: [Experiments] Experiments section (results on FLAIR-HUB and URUR): the headline mIoU gains (66.37% and 49.2%) are reported without ablations that hold SimMIM pretraining, decoder choice, and dual-branch structure fixed while toggling only the stage-wise cross-attention blocks. This leaves open the possibility that observed deltas arise from pretraining or the mere presence of a low-resolution branch rather than context injection.
Authors: We agree that isolating the contribution of the stage-wise cross-attention is essential. In the revised manuscript we will add a controlled ablation on FLAIR-HUB that keeps SimMIM pretraining, the SegFormer decoder, and the dual-branch structure fixed, comparing performance with and without the cross-attention blocks. This will directly address whether the reported gains arise from context injection rather than the other design elements. revision: yes
-
Referee: [Method] Method description of cross-attention: no quantitative analysis (e.g., attention-map statistics, noise-injection tests, or failure-case examination) is provided to confirm that low-to-high resolution context transfer reliably adds useful signal without introducing boundary or class-label degradation.
Authors: We acknowledge the need for quantitative evidence on the cross-attention behavior. In the revision we will add (i) attention-map visualizations from multiple stages with corresponding statistics (e.g., entropy and spatial correlation with ground-truth edges), (ii) a controlled noise-injection experiment on the low-resolution branch, and (iii) a failure-case study highlighting any boundary or label degradation. These additions will demonstrate that the context transfer adds useful signal. revision: yes
Circularity Check
No significant circularity; empirical results on public benchmarks
full rationale
The paper introduces CASWiT as a dual-branch Swin architecture using stage-wise cross-attention and SimMIM-style pretraining, then reports mIoU numbers (66.37% on FLAIR-HUB RGB-only UHR, 49.2% on URUR) against public benchmarks. No equations, fitted parameters, or derivations are presented that reduce by construction to the inputs; the central claims rest on external dataset performance rather than self-referential definitions or self-citation chains. The architecture description and pretraining strategy are independent of the reported metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- cross-attention parameters and training hyperparameters
axioms (1)
- domain assumption Swin transformer blocks can be extended with lightweight cross-attention to fuse multi-resolution features without destabilizing training.
Reference graph
Works this paper leans on
-
[1]
T. Baltru ˇsaitis, C. Ahuja, and L.-P. Morency. Multimodal machine learning: A survey and taxonomy.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 41(2): 423–443, 2019. 2
work page 2019
-
[2]
Crossvit: Cross-attention multi-scale vision trans- former for image classification
Chun-Fu (Richard) Chen, Quanfu Fan, and Rameswar Panda. Crossvit: Cross-attention multi-scale vision trans- former for image classification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 357–366, 2021. 1
work page 2021
-
[3]
Lijia Chen, Honghui Chen, Yanqiu Xie, Tianyou He, Jing Ye, and Yushan Zheng. An efficient and light transformer- based segmentation network for remote sensing images of landscapes.Forests, 14(11), 2023. 2
work page 2023
-
[4]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vi- sion (ECCV), 2018. 7
work page 2018
-
[5]
Wuyang Chen, Ziyu Jiang, Zhangyang Wang, Kexin Cui, and Xiaoning Qian. Collaborative global-local networks for memory-efficient segmentation of ultra-high resolution im- ages. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2019. 2, 7
work page 2019
-
[6]
Bowen Cheng, Ross Girshick, Piotr Doll ´ar, Alexander C. Berg, and Alexander Kirillov. Boundary iou: Improving object-centric image segmentation evaluation, 2021. 6
work page 2021
-
[7]
Schwing, Alexan- der Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation, 2022. 1, 8
work page 2022
-
[8]
Ho Kei Cheng, Jihoon Chung, Yu-Wing Tai, and Chi-Keung Tang. Cascadepsp: Toward class-agnostic and very high- resolution segmentation via global and local refinement. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2020. 2, 7
work page 2020
-
[9]
Deepglobe 2018: A challenge to parse the earth through satellite images
Ilke Demir, Krzysztof Koperski, David Lindenbaum, Guan Pang, Jing Huang, Saikat Basu, Forest Hughes, Devis Tuia, and Ramesh Raskar. Deepglobe 2018: A challenge to parse the earth through satellite images. InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR) Workshops, 2018. 5
work page 2018
-
[10]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations,
-
[11]
Rethinking bisenet for real-time semantic segmentation
Mingyuan Fan, Shenqi Lai, Junshi Huang, Xiaoming Wei, Zhenhua Chai, Junfeng Luo, and Xiaolin Wei. Rethinking bisenet for real-time semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 9716–9725, 2021. 7
work page 2021
-
[12]
Anatol Garioud, Nicolas Gonthier, Loic Landrieu, Apolline De Wit, Marion Valette, Marc Poup ´ee, Sebastien Giordano, and boris Wattrelos. Flair : a country-scale land cover se- mantic segmentation dataset from multi-source optical im- agery. InAdvances in Neural Information Processing Sys- tems, pages 16456–16482. Curran Associates, Inc., 2023. 4
work page 2023
-
[13]
Flair-hub: Large-scale multimodal dataset for land cover and crop mapping, 2025
Anatol Garioud, S ´ebastien Giordano, Nicolas David, and Nicolas Gonthier. Flair-hub: Large-scale multimodal dataset for land cover and crop mapping, 2025. 1, 2, 4, 6, 3
work page 2025
-
[14]
Isdnet: Integrating shallow and deep networks for efficient ultra-high resolution segmenta- tion
Shaohua Guo, Liang Liu, Zhenye Gan, Yabiao Wang, Wuhao Zhang, Chengjie Wang, Guannan Jiang, Wei Zhang, Ran Yi, Lizhuang Ma, and Ke Xu. Isdnet: Integrating shallow and deep networks for efficient ultra-high resolution segmenta- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 4361– 4370, 2022. 2, 3, 7
work page 2022
-
[15]
Renlong Hang, Ping Yang, Feng Zhou, and Qingshan Liu. Multiscale progressive segmentation network for high- resolution remote sensing imagery.IEEE Transactions on Geoscience and Remote Sensing, 60:1–12, 2022. 2
work page 2022
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 7
work page 2016
-
[17]
Masked autoencoders are scalable vision learners, 2021
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021. 4
work page 2021
-
[18]
Ziyan Huang, Haoyu Wang, Zhongying Deng, Jin Ye, Yanzhou Su, Hui Sun, Junjun He, Yun Gu, Lixu Gu, Shaot- ing Zhang, and Yu Qiao. Stu-net: Scalable and transferable medical image segmentation models empowered by large- scale supervised pre-training, 2023. 2
work page 2023
-
[19]
Progressive semantic segmentation
Chuong Huynh, Anh Tuan Tran, Khoa Luu, and Minh Hoai. Progressive semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 16755–16764, 2021. 2
work page 2021
-
[20]
Deyi Ji, Feng Zhao, and Hongtao Lu. Guided patch-grouping wavelet transformer with spatial congruence for ultra-high resolution segmentation, 2023. 1, 2
work page 2023
-
[21]
Ultra-high resolution segmentation with ultra-rich con- text: A novel benchmark
Deyi Ji, Feng Zhao, Hongtao Lu, Mingyuan Tao, and Jieping Ye. Ultra-high resolution segmentation with ultra-rich con- text: A novel benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23621–23630, 2023. 1, 2, 4, 6, 7
work page 2023
-
[22]
Yuyang Ji and Lianlei Shan. Ldnet: Semantic segmentation of high-resolution images via learnable patch proposal and dynamic refinement. In2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6, 2024. 2
work page 2024
-
[23]
Antoine Labatie, Michael Vaccaro, Nina Lardiere, Ana- tol Garioud, and Nicolas Gonthier. Maestro: Masked au- toencoders for multimodal, multitemporal, and multispectral earth observation data, 2025. 2, 6 9
work page 2025
-
[24]
Qi Li, Jiaxin Cai, Jiexin Luo, Yuanlong Yu, Jason Gu, Jia Pan, and Wenxi Liu. Memory-constrained semantic segmen- tation for ultra-high resolution uav imagery.IEEE Robotics and Automation Letters, 9(2):1708–1715, 2024. 2
work page 2024
-
[25]
ESNet: Evolution and suc- cession network for high-resolution salient object detection
Hongyu Liu, Runmin Cong, Hua Li, Qianqian Xu, Qing- ming Huang, and Wei Zhang. ESNet: Evolution and suc- cession network for high-resolution salient object detection. InForty-first International Conference on Machine Learn- ing, 2024. 3
work page 2024
-
[26]
Wenshu Liu, Nan Cui, Luo Guo, Shihong Du, and Weiyin Wang. Desformer: A dual-branch encoding strategy for se- mantic segmentation of very-high-resolution remote sensing images based on feature interaction and multiscale context fusion.IEEE Transactions on Geoscience and Remote Sens- ing, 62:1–20, 2024. 2
work page 2024
-
[27]
Yatong Liu, Yu Zhu, Ying Xin, Yanan Zhang, Dawei Yang, and Tao Xu. Mestrans: Multi-scale embedding spatial trans- former for medical image segmentation.Computer Methods and Programs in Biomedicine, 233:107493, 2023. 2
work page 2023
-
[28]
Swin trans- former: Hierarchical vision transformer using shifted win- dows, 2021
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin trans- former: Hierarchical vision transformer using shifted win- dows, 2021. 1, 2, 3
work page 2021
-
[29]
Swin transformer v2: Scaling up capacity and resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, and Baining Guo. Swin transformer v2: Scaling up capacity and resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12009–12019, 2022. 2
work page 2022
-
[30]
Chen Lu, Xian Zhang, Kaile Du, Han Xu, and Guangcan Liu. Ctcfnet: Cnn-transformer complementary and fusion network for high-resolution remote sensing image semantic segmentation.IEEE Transactions on Geoscience and Re- mote Sensing, 62:1–17, 2024. 2
work page 2024
-
[31]
Can semantic labeling methods general- ize to any city? the inria aerial image labeling benchmark
Emmanuel Maggiori, Yuliya Tarabalka, Guillaume Charpiat, and Pierre Alliez. Can semantic labeling methods general- ize to any city? the inria aerial image labeling benchmark. In2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), pages 3226–3229, 2017. 5
work page 2017
-
[32]
Jishnu Mukhoti, Andreas Kirsch, Joost van Amersfoort, Philip H.S. Torr, and Yarin Gal. Deep deterministic un- certainty: A new simple baseline. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24384–24394, 2023. 3
work page 2023
-
[33]
Qi, Lin Xindai, Yang Weixiang, He Shengfeng, Yu Yuan- long Liu Wenxi, and Li. Ultra-high resolution image seg- mentation via locality-aware context fusion and alternating local enhancement.International Journal of Computer Vi- sion, 132:5030–5047, 2024. 2, 7
work page 2024
-
[34]
Rong Qin, Xingyu Liu, Jinglei Shi, Liang Lin, and Jufeng Yang. Boosting the dual-stream architecture in ultra-high resolution segmentation with resolution-biased uncertainty estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25960–25970, 2025. 1, 3, 5, 6, 7, 4
work page 2025
-
[35]
Yanzhou Su, Jian Cheng, Haiwei Bai, Haijun Liu, and Changtao He. Semantic segmentation of very-high- resolution remote sensing images via deep multi-feature learning.Remote Sensing, 14, 2022. 2
work page 2022
-
[36]
Yihao Sun, Mingrui Wang, Xiaoyi Huang, Chengshu Xin, and Yinan Sun. Fast semantic segmentation of ultra-high- resolution remote sensing images via score map and fast transformer-based fusion.Remote Sensing, 16(17), 2024. 2
work page 2024
-
[37]
Full contextual attention for multi-resolution transformers in semantic segmentation
Loic Themyr, Cl ´ement Rambour, Nicolas Thome, Toby Collins, and Alexandre Hostettler. Full contextual attention for multi-resolution transformers in semantic segmentation. InProceedings of the IEEE/CVF Winter Conference on Ap- plications of Computer Vision (WACV), pages 3224–3233,
-
[38]
Sub-ensembles for fast uncer- tainty estimation in neural networks
Matias Valdenegro-Toro. Sub-ensembles for fast uncer- tainty estimation in neural networks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 4119–4127, 2023. 3
work page 2023
-
[39]
Hongzhen Wang, Ying Wang, Qian Zhang, Shiming Xiang, and Chunhong Pan. Gated convolutional neural network for semantic segmentation in high-resolution images.Remote Sensing, 9(5), 2017. 3
work page 2017
-
[40]
Sai Wang, Yutian Lin, Yu Wu, and Bo Du. Toward real ul- tra image segmentation: Leveraging surrounding context to cultivate general segmentation model. InAdvances in Neu- ral Information Processing Systems, pages 129227–129249. Curran Associates, Inc., 2024. 2
work page 2024
-
[41]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 568–578, 2021. 2
work page 2021
-
[42]
Pvt v2: Improved baselines with pyramid vision transformer
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pvt v2: Improved baselines with pyramid vision transformer. Computational Visual Media, 8(3):415–424, 2022. 1, 2
work page 2022
-
[43]
Honglin Wu, Peng Huang, Min Zhang, Wenlong Tang, and Xinyu Yu. Cmtfnet: Cnn and multiscale transformer fusion network for remote-sensing image semantic segmentation. IEEE Transactions on Geoscience and Remote Sensing, 61: 1–12, 2023. 2
work page 2023
-
[44]
Tong Wu, Zhenzhen Lei, Bingqian Lin, Cuihua Li, Yanyun Qu, and Yuan Xie. Patch proposal network for fast semantic segmentation of high-resolution images.Proceedings of the AAAI Conference on Artificial Intelligence, 34(07):12402– 12409, 2020. 2, 3
work page 2020
-
[45]
Unified perceptual parsing for scene understand- ing, 2018
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understand- ing, 2018. 3
work page 2018
-
[46]
Simmim: A simple framework for masked image modeling
Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9653–9663, 2022. 1, 3, 4
work page 2022
-
[47]
Fei Yang, Fenlong Jiang, Jianzhao Li, and Lei Lu. Mstrans: Multi-scale transformer for building extraction from hr re- mote sensing images.Electronics, 13, 2024. 2 10
work page 2024
-
[48]
Zhan Zhang, Daoyu Shu, Guihe Gu, Wenkai Hu, Ru Wang, Xiaoling Chen, and Bingnan Yang. Ringformer-seg: A scal- able and context-preserving vision transformer framework for semantic segmentation of ultra-high-resolution remote sensing imagery.Remote Sensing, 17:3064, 2025. 2 11 Context-Aware Semantic Segmentation via Stage-Wise Attention Supplementary Material
work page 2025
-
[49]
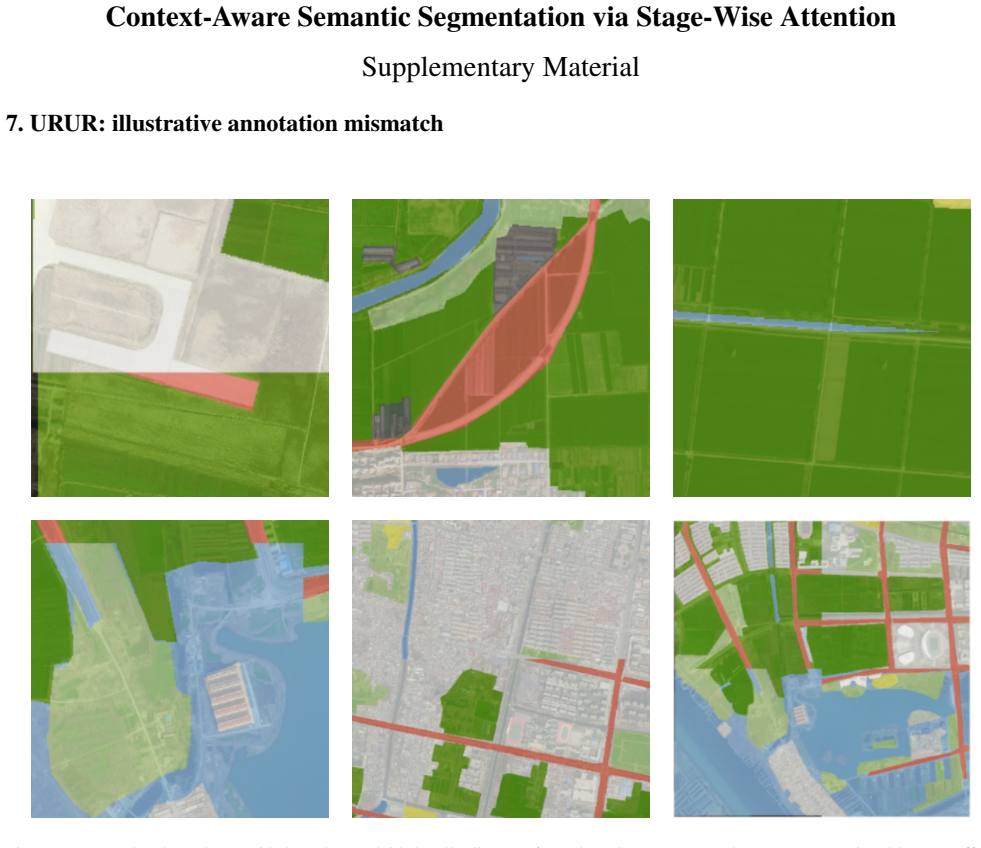
URUR: illustrative annotation mismatch Figure 7. Example where the provided mask (overlaid) locally diverges from the RGB content; such cases are occasional but can affect evaluation metrics. Visible classes include:others,building,greenhouse,woodland,farmland,bareland,water,road. 1
-
[50]
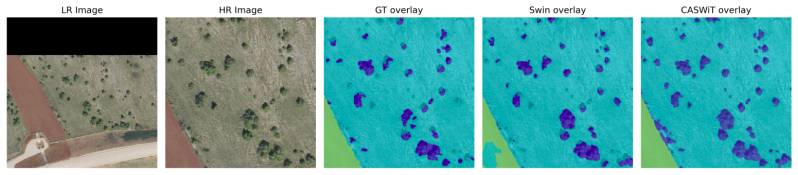
Qualitative analysis on FLAIR-HUB 2 Figure 8. Comparison of LR/HR images, ground truth overlays, Swin Base predictions, and CASWiT predictions on eight test patches
-
[51]
Per-class IoU (%) on the FLAIRHUB RGB test set for Swin-Base and our CASWiT variants
Supplementary results (IoUs) Class Swin-Base [13] CASWiT-B (ours) CASWiT-B-SSL (ours) CASWiT-B-SSL-aug (ours) Building 83.77 84.54 84.58 85.47 Greenhouse 77.89 78.87 78.61 79.46 Swimming pool 61.59 61.45 60.93 62.12 Impervious surface 75.03 76.24 76.48 76.78 Pervious surface 56.97 58.33 58.65 58.86 Bare soil 65.21 65.99 66.70 66.95 Water 90.08 89.37 90.26...
-
[52]
Dataset FLAIR-HUB merge Figure 9. Examples of data pre-processing, on the left are the HR patches and on the right are the merged patches obtained from the available neighbors. 4
-
[53]
Self-supervised SimMIM-style inference results on the CASWiT-Base architecture
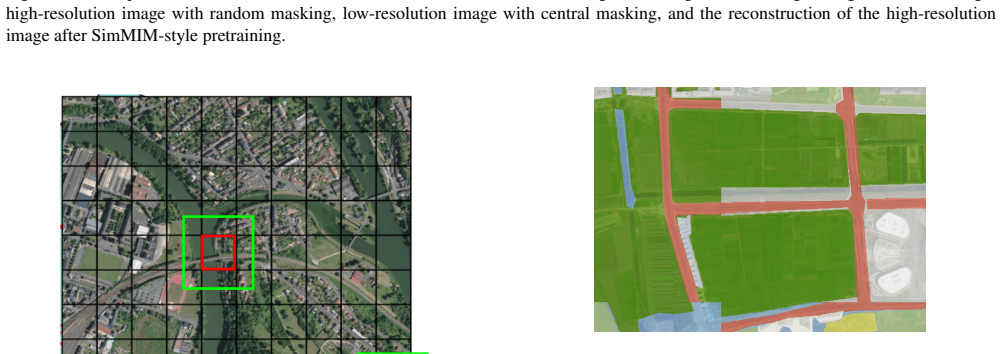
SSL results 5 Figure 10. Self-supervised SimMIM-style inference results on the CASWiT-Base architecture. Each row (left to right) shows: original high-resolution image, high-resolution image with random masking, low-resolution image with central masking, and the reconstruction of the high-resolution image. 6
-
[54]
Visualization of cross-attention maps for each stage of the model on four test patches
Cross-attention visualization Figure 11. Visualization of cross-attention maps for each stage of the model on four test patches. 7
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.