Recognition: 2 theorem links
· Lean TheoremMirai: Autoregressive Visual Generation Needs Foresight
Pith reviewed 2026-05-16 12:12 UTC · model grok-4.3
The pith
Autoregressive image generators gain coherence and speed when foresight from future tokens is aligned to their 2D grid representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that autoregressive visual generation improves when foresight signals are aligned with the model's unidirectional 2D representations on the image grid. Mirai-E supplies explicit foresight from multiple future positions within the same unidirectional stream, while Mirai-I draws implicit foresight from matched bidirectional representations. Both variants are applied during training only, leave the architecture untouched, and produce no extra inference cost, yielding up to 10 times faster convergence and an FID reduction from 5.34 to 4.34 on class-conditional ImageNet generation.
What carries the argument
The Mirai framework, which injects foresight by aligning future-token signals with the model's internal 2D grid representations at chosen levels and layouts.
If this is right
- Existing autoregressive visual models such as LlamaGen-B converge up to ten times faster under the same training budget.
- Generation quality improves, lowering FID from 5.34 to 4.34 on the ImageNet class-conditional benchmark.
- The same training procedure applies to any autoregressive visual backbone without modifying its layers or adding inference cost.
- Both explicit and implicit forms of foresight produce measurable gains once the 2D alignment condition is met.
Where Pith is reading between the lines
- The result suggests that flat next-token supervision is a mismatch for data whose natural structure is two-dimensional.
- The same alignment principle could be tested on autoregressive models for video or 3D data where grid or spatial layout is also present.
- If the 2D alignment is the decisive factor, then positional encodings that explicitly preserve grid geometry may further amplify the gains.
Load-bearing premise
Foresight signals can be added at selected levels and layouts to match the unidirectional 2D representations without causing training instability or requiring any architecture change.
What would settle it
Train a standard autoregressive model such as LlamaGen-B on ImageNet both with and without the Mirai foresight injection at the reported levels, then check whether convergence speed stays the same and final FID remains at 5.34 instead of dropping to 4.34.
Figures




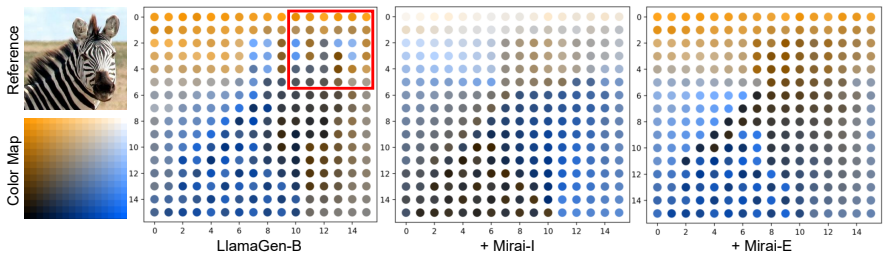


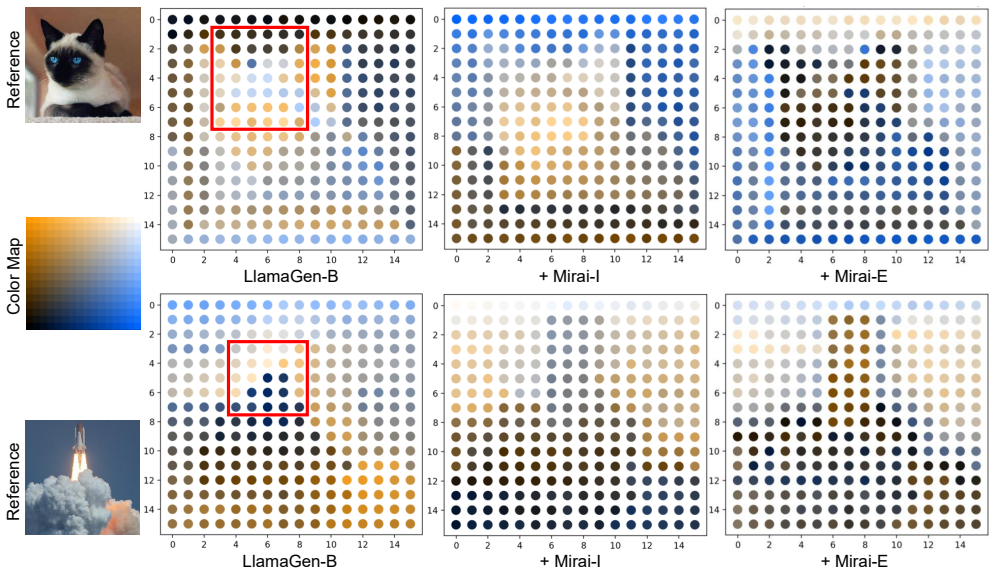




read the original abstract
Autoregressive (AR) visual generators model images as sequences of discrete tokens and are trained with a next-token likelihood objective. This strict causal supervision optimizes each step based only on the immediate next token, which can weaken global coherence and slow convergence. We investigate whether foresight, training signals that originate from later tokens, can improve autoregressive visual generation. We conduct a series of controlled diagnostics along the injection level, foresight layout, and foresight source axes, revealing a key insight: aligning foresight with AR models' internal representations on the 2D image grid improves causal modeling. We formulate this insight with Mirai (meaning "future" in Japanese), a general framework that injects future information into AR training with no architecture change and no extra inference overhead: Mirai-E uses explicit foresight from multiple future positions of unidirectional representations, whereas Mirai-I leverages implicit foresight from matched bidirectional representations. Extensive experiments show that Mirai significantly accelerates convergence and improves generation quality. For instance, Mirai can speed up LlamaGen-B's convergence by up to 10$\times$ and reduce the generation FID from 5.34 to 4.34 on the ImageNet class-condition image generation benchmark. Our study highlights that visual autoregressive models need foresight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoregressive visual generators suffer from weak global coherence due to strict next-token supervision and that injecting foresight signals (from future tokens) aligned with the model's internal 2D image-grid representations improves causal modeling. It introduces the Mirai framework (Mirai-E using explicit multi-position foresight from unidirectional representations; Mirai-I using implicit foresight from matched bidirectional representations) that requires no architecture changes and adds no inference cost. Controlled diagnostics along injection level, layout, and source axes are presented, with experiments showing up to 10× faster convergence and FID reduction from 5.34 to 4.34 on ImageNet class-conditional generation using LlamaGen-B.
Significance. If the alignment insight is isolated, the result would be significant for AR visual generation: it offers a lightweight training-time intervention that accelerates convergence and improves sample quality on existing models without architectural or inference overhead. The paper's emphasis on controlled diagnostics across multiple axes and direct application to LlamaGen-B provides a practical contribution that could be adopted broadly.
major comments (1)
- [§4 (Experiments), Foresight Layout Ablation] §4 (Experiments), Foresight Layout Ablation: the diagnostics vary injection level, layout, and source but do not hold foresight signal count, weighting, and source fixed while randomizing only the spatial layout relative to the 2D token grid. Consequently the reported gains (10× convergence speedup and FID drop from 5.34 to 4.34) cannot be unambiguously attributed to 2D-grid alignment rather than the general benefit of additional future-token supervision.
minor comments (1)
- [§3 (Method)] The method section should explicitly state the exact number of foresight tokens, loss weighting coefficients, and injection positions used in the main LlamaGen-B runs so that the 10× convergence claim can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our experimental design. We address the major comment below and will revise the manuscript to strengthen the isolation of the 2D-grid alignment effect.
read point-by-point responses
-
Referee: [§4 (Experiments), Foresight Layout Ablation] §4 (Experiments), Foresight Layout Ablation: the diagnostics vary injection level, layout, and source but do not hold foresight signal count, weighting, and source fixed while randomizing only the spatial layout relative to the 2D token grid. Consequently the reported gains (10× convergence speedup and FID drop from 5.34 to 4.34) cannot be unambiguously attributed to 2D-grid alignment rather than the general benefit of additional future-token supervision.
Authors: We agree that the current layout ablation does not fully isolate spatial alignment because signal count, weighting, and source are not held fixed across all comparisons. In the revised manuscript we will add a new controlled experiment that fixes the number of foresight signals, their weighting scheme, and the source representation while only randomizing the spatial positions relative to the 2D token grid. This will allow direct attribution of performance differences to layout alignment. We will report the updated results and revise the discussion in §4 accordingly. revision: yes
Circularity Check
No significant circularity; empirical validation independent of inputs
full rationale
The paper derives its central insight from a series of controlled diagnostic experiments on injection level, layout, and source, then implements the Mirai framework (Mirai-E and Mirai-I) to inject foresight without architecture changes. Improvements (e.g., 10× convergence speedup and FID reduction from 5.34 to 4.34) are demonstrated via direct training and evaluation on LlamaGen-B and ImageNet benchmarks. No equations or parameters are shown to reduce to the target metric by construction, no self-citations are load-bearing for the uniqueness of the 2D alignment claim, and no ansatz or renaming of known results occurs. The chain remains self-contained through external experimental falsification rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- foresight injection hyperparameters
axioms (1)
- domain assumption Next-token likelihood is the base training objective for autoregressive visual models
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
aligning foresight with AR models' internal representations on the 2D image grid improves causal modeling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Unilmv2: Pseudo-masked language models for unified language model pre-training
Hangbo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Yang, Xiaodong Liu, Yu Wang, Jianfeng Gao, Songhao Piao, Ming Zhou, et al. Unilmv2: Pseudo-masked language models for unified language model pre-training. InICML, pages 642– 652, 2020. 8
work page 2020
-
[2]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018. 8, 13
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Maskgit: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. In CVPR, pages 11315–11325, 2022. 8, 14
work page 2022
-
[4]
Generative pre- training from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Hee- woo Jun, David Luan, and Ilya Sutskever. Generative pre- training from pixels. InICML, pages 1691–1703, 2020. 1
work page 2020
-
[5]
Generating Long Sequences with Sparse Transformers
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019. 1
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[6]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, pages 248–255, 2009. 5
work page 2009
-
[7]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. InNeurIPS, pages 8780–8794,
-
[8]
Cogview: Mastering text- to-image generation via transformers
Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, and Jie Tang. Cogview: Mastering text- to-image generation via transformers. InNeurIPS, pages 19822–19835, 2021. 1
work page 2021
-
[9]
Cogview2: Faster and better text-to-image generation via hi- erarchical transformers
Ming Ding, Wendi Zheng, Wenyi Hong, and Jie Tang. Cogview2: Faster and better text-to-image generation via hi- erarchical transformers. InNeurIPS, pages 16890–16902,
-
[10]
Glm: General language model pretraining with autoregressive blank infilling
Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. In ACL, pages 320–335, 2022. 8
work page 2022
-
[11]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InCVPR, pages 12873–12883, 2021. 2, 5, 7, 8, 14
work page 2021
-
[12]
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi`ere, David Lopez-Paz, and Gabriel Synnaeve. Better & faster large language models via multi-token prediction.arXiv preprint arXiv:2404.19737, 2024. 1, 3, 5, 8
work page internal anchor Pith review arXiv 2024
-
[13]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InCVPR, pages 16000–16009, 2022. 6
work page 2022
-
[14]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InNeurIPS, pages 6629–6640, 2017. 5, 12
work page 2017
-
[15]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InNeurIPS, pages 6840–6851,
-
[17]
Scaling up gans for text-to-image synthesis
Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, and Taesung Park. Scaling up gans for text-to-image synthesis. InCVPR, pages 10124– 10134, 2023. 8, 13
work page 2023
-
[18]
Elucidating the design space of diffusion-based generative models.NeurIPS, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.NeurIPS, 35:26565–26577, 2022. 7
work page 2022
-
[19]
Improved precision and recall met- ric for assessing generative models
Tuomas Kynk ¨a¨anniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall met- ric for assessing generative models. InNeurIPS, pages 3927– 3936, 2019. 5, 12
work page 2019
-
[20]
Autoencoding beyond pixels using a learned similarity metric
Anders Boesen Lindbo Larsen, Søren Kaae Sønderby, Hugo Larochelle, and Ole Winther. Autoencoding beyond pixels using a learned similarity metric. InICML, pages 1558– 1566, 2016. 8
work page 2016
-
[21]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. InCVPR, pages 11523–11532, 2022. 8, 14
work page 2022
-
[22]
Tianhong Li, Dina Katabi, and Kaiming He. Return of unconditional generation: A self-supervised representation generation method.arXiv preprint arXiv:2312.03701, 2024. 8, 14
-
[23]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 1, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5, 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Sit: Exploring flow and diffusion-based generative models with scalable in- terpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable in- terpolant transformers. InECCV, pages 23–40, 2024. 8, 14
work page 2024
-
[26]
Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008. 6, 12, 13
work page 2008
-
[27]
Charlie Nash, Jacob Menick, Sander Dieleman, and Peter W Battaglia. Generating images with sparse representations. arXiv preprint arXiv:2103.03841, 2021. 5, 12
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Im- age transformer. InICML, pages 4055–4064. PMLR, 2018. 1
work page 2018
-
[30]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, pages 4195–4205, 2023. 7, 8, 14
work page 2023
-
[31]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InICML, pages 8821– 8831, 2021. 1, 7 9
work page 2021
-
[32]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gen- eration with clip latents.arXiv preprint arXiv:2204.06125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, and Liang-Chieh Chen. Beyond next-token: Next-x pre- diction for autoregressive visual generation.arXiv preprint arXiv:2502.20388, 2025. 8
-
[34]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 7, 8, 13
work page 2022
-
[35]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InNeurIPS, pages 2234–2242, 2016. 5, 8, 12
work page 2016
-
[36]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024. 1, 2, 3, 5, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Rethinking the inception ar- chitecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception ar- chitecture for computer vision. InCVPR, pages 2818–2826,
-
[39]
Visual autoregressive modeling: Scalable image gen- eration via next-scale prediction
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image gen- eration via next-scale prediction. InNeurIPS, pages 84839– 84865, 2024. 8, 14
work page 2024
-
[40]
Conditional image genera- tion with pixelcnn decoders
Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image genera- tion with pixelcnn decoders. InNeurIPS, pages 4797–4805,
-
[41]
Pixel recurrent neural networks
A ¨aron Van Den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. InICML, pages 1747–1756, 2016. 7
work page 2016
-
[42]
Neural dis- crete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural dis- crete representation learning. InNeurIPS, pages 6309–6318,
-
[43]
Parallelized autoregressive visual generation
Yuqing Wang, Shuhuai Ren, Zhijie Lin, Yujin Han, Haoyuan Guo, Zhenheng Yang, Difan Zou, Jiashi Feng, and Xihui Liu. Parallelized autoregressive visual generation. InCVPR, pages 12955–12965, 2025. 12
work page 2025
-
[44]
Xlnet: General- ized autoregressive pretraining for language understanding
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. Xlnet: General- ized autoregressive pretraining for language understanding. InNeurIPS, pages 5753–5763, 2019. 8
work page 2019
-
[45]
Vector-quantized Image Modeling with Improved VQGAN
Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved vqgan.arXiv preprint arXiv:2110.04627, 2021. 8, 14
work page internal anchor Pith review arXiv 2021
-
[46]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gun- jan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yin- fei Yang, Burcu Karagol Ayan, et al. Scaling autoregres- sive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
Lili Yu, Bowen Shi, Ramakanth Pasunuru, Benjamin Muller, Olga Golovneva, Tianlu Wang, Arun Babu, Binh Tang, Brian Karrer, Shelly Sheynin, et al. Scaling autoregressive multi- modal models: Pretraining and instruction tuning.arXiv preprint arXiv:2309.02591, 2023. 1
-
[48]
Randomized autoregressive visual generation
Qihang Yu, Ju He, Xueqing Deng, Xiaohui Shen, and Liang- Chieh Chen. Randomized autoregressive visual generation. InICCV, pages 18431–18441, 2025. 8
work page 2025
-
[49]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffu- sion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024. 5, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Xiaoyu Yue, Zidong Wang, Yuqing Wang, Wenlong Zhang, Xihui Liu, Wanli Ouyang, Lei Bai, and Luping Zhou. Understand before you generate: Self-guided train- ing for autoregressive image generation.arXiv preprint arXiv:2509.15185, 2025. 8 10 Mirai: Autoregressive Visual Generation Needs Foresight Supplementary Material Table 7.Alignment coefficientλselection...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.