PAL*M: Property Attestation for Large Generative Models
Pith reviewed 2026-05-16 11:33 UTC · model grok-4.3
The pith
PAL*M enables property attestation for large generative models with under 11% overhead while preserving security.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
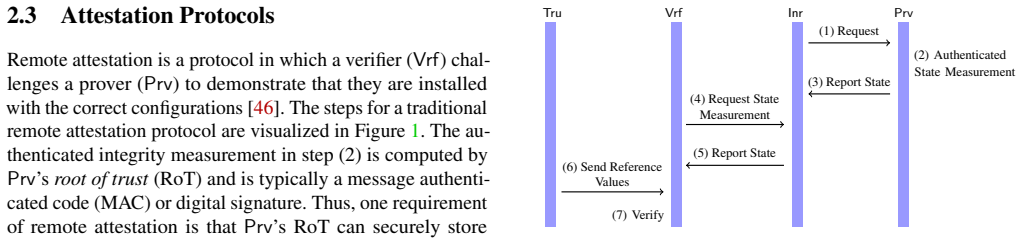
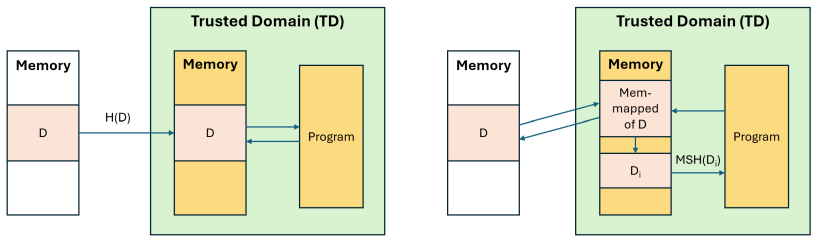
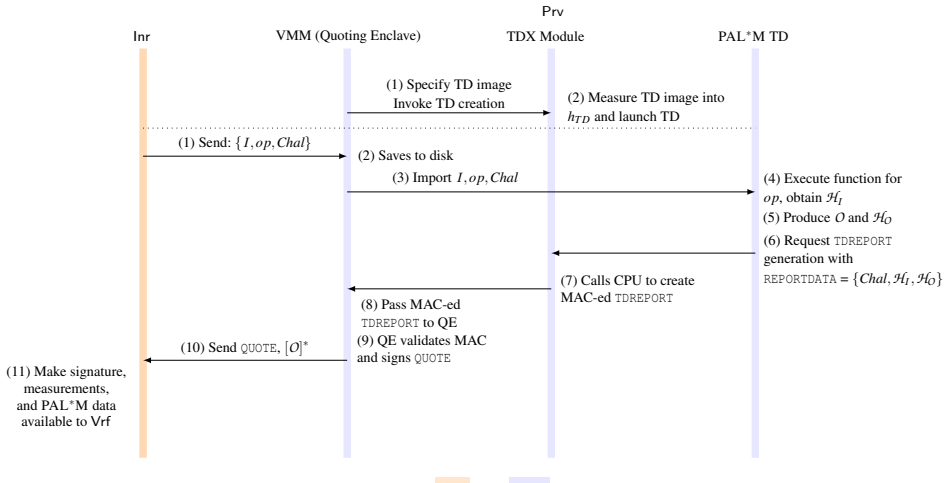
PAL*M defines properties across training and inference for large generative models. It uses confidential virtual machines with security-aware GPUs to isolate and cover CPU-GPU operations and incremental multiset hashing over memory-mapped datasets to track integrity efficiently. The implementation on Intel TDX and NVIDIA H100 shows less than 11% overhead for common operations, and formal modeling with the Tamarin Prover confirms security guarantees under the defined threat model.
What carries the argument
Confidential virtual machines paired with security-aware GPUs, together with incremental multiset hashing for dataset integrity.
Load-bearing premise
The Intel TDX confidential VM and NVIDIA H100 security-aware GPU must correctly isolate CPU-GPU operations, and the threat model must account for all relevant attacks on the attestation protocol.
What would settle it
A concrete falsifier would be successfully tampering with attested model properties or dataset contents undetected while operating within the confidential VM and GPU setup, or the discovery of a protocol flaw by the Tamarin Prover.
Figures


read the original abstract
Machine learning property attestations allow provers (e.g., model providers or owners) to attest properties of their models/datasets to verifiers (e.g., regulators, customers), enabling accountability towards regulations and policies. But, current approaches do not support generative models or large datasets. We present PAL*M, a property attestation framework for large generative models, illustrated using large language models. PAL*M defines properties across training and inference, leverages confidential virtual machines with security-aware GPUs for coverage of CPU-GPU operations, and proposes using incremental multiset hashing over memory-mapped datasets to efficiently track their integrity. We implement PAL*M on Intel TDX+NVIDIA H100 and evaluate it using state-of-the-art models and datasets, showing PAL*M is efficient, incurring < 11% overhead for common operations. Finally, we use the Tamarin Prover symbolic verification tool to formally model PAL*M's property attestation protocol, confirming that its security guarantees are upheld under the defined threat model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PAL*M, a property attestation framework for large generative models (illustrated with LLMs) that defines properties over training and inference phases, leverages confidential VMs with security-aware GPUs to cover CPU-GPU operations, and uses incremental multiset hashing over memory-mapped datasets for efficient integrity tracking. It reports a concrete implementation on Intel TDX + NVIDIA H100 hardware showing <11% overhead for common operations and uses the Tamarin Prover to symbolically verify that the attestation protocol upholds its security guarantees under the stated threat model.
Significance. If the hardware isolation assumptions hold, PAL*M fills an important gap by enabling practical property attestation for large-scale generative models, supporting regulatory accountability. The combination of a real-hardware implementation with measured overhead and Tamarin-based protocol verification provides concrete support for the efficiency and security claims.
major comments (2)
- [Threat model and security analysis] Threat model and security analysis section: the claim that security guarantees are upheld rests on the assumption that Intel TDX and NVIDIA H100 fully isolate and attest all CPU-GPU operations (including model weights, activations, and dataset mappings); Tamarin verifies only the symbolic protocol, leaving potential side-channel leakage or incomplete GPU state measurement unaddressed, which is load-bearing for the central security claim.
- [Evaluation] Evaluation section: the <11% overhead result for common operations is reported without specifying the exact operations measured (e.g., particular training steps vs. inference batches), model sizes, or baseline comparisons, making it difficult to evaluate generality across generative workloads.
minor comments (2)
- [Abstract] Abstract: the statement of <11% overhead would benefit from naming the models and datasets used in the evaluation to give readers immediate context.
- [Framework description] Notation for incremental multiset hashing: an inline example or small diagram would clarify how the hashing tracks dataset integrity during memory-mapped access.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation. We address each major comment below and will revise the manuscript to improve clarity on the scope of the security analysis and the details of the evaluation.
read point-by-point responses
-
Referee: Threat model and security analysis section: the claim that security guarantees are upheld rests on the assumption that Intel TDX and NVIDIA H100 fully isolate and attest all CPU-GPU operations (including model weights, activations, and dataset mappings); Tamarin verifies only the symbolic protocol, leaving potential side-channel leakage or incomplete GPU state measurement unaddressed, which is load-bearing for the central security claim.
Authors: We agree that the central security claim depends on the hardware isolation and attestation properties of Intel TDX and NVIDIA H100 as defined in the threat model. The Tamarin analysis verifies only that the attestation protocol upholds the stated properties assuming the hardware behaves according to its specification. Side-channel leakage and potential gaps in GPU state measurement are indeed outside the scope of the symbolic verification. In the revised manuscript we will expand the threat model section to explicitly state these limitations, clarify the boundary between protocol verification and hardware trust assumptions, and cite relevant work on side-channel risks in confidential computing. revision: yes
-
Referee: Evaluation section: the <11% overhead result for common operations is reported without specifying the exact operations measured (e.g., particular training steps vs. inference batches), model sizes, or baseline comparisons, making it difficult to evaluate generality across generative workloads.
Authors: We accept this observation. While the manuscript reports results on state-of-the-art models and datasets, the precise mapping of the <11% overhead figures to specific operations (e.g., inference forward passes versus particular training steps), exact model sizes, and direct baseline comparisons is not sufficiently detailed. In the revision we will add a breakdown table and accompanying text that specifies the measured operations, model parameter counts, dataset sizes, and comparisons against non-attested baselines to better support claims of generality. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines PAL*M via a protocol leveraging external hardware (Intel TDX confidential VMs and NVIDIA H100 security-aware GPUs) for CPU-GPU isolation, incremental multiset hashing for dataset integrity tracking, and Tamarin Prover for symbolic verification of security properties under a stated threat model. Efficiency claims (<11% overhead) derive from direct empirical measurements on state-of-the-art models rather than any fitted parameters or self-referential definitions. No equations or steps reduce by construction to inputs; self-citations (if present) are not load-bearing for the core attestation guarantees, which rest on independent hardware primitives and formal tool output. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Intel TDX and NVIDIA H100 security features correctly isolate and attest CPU-GPU operations
- domain assumption Incremental multiset hashing correctly tracks dataset integrity without false negatives under the threat model
Reference graph
Works this paper leans on
-
[1]
Zero-knowledge proofs of training for deep neural networks
Kasra Abbaszadeh et al. Zero-knowledge proofs of training for deep neural networks. InACM SIGSAC Conference on Computer and Communications Security, CCS ’24, page 4316–4330, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[2]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin et al. Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs.CoRR, abs/2503.01743, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
The EU Artificial Intelli- gence Act.European Union, 2024
EU Artificial Intelligence Act. The EU Artificial Intelli- gence Act.European Union, 2024
work page 2024
-
[4]
Intel Trust Domain Extensions (TDX) security review.Google security review, 2023
Erdem Aktas et al. Intel Trust Domain Extensions (TDX) security review.Google security review, 2023
work page 2023
-
[5]
AMD secure encrypted virtualization (sev).http s://www.amd.com/en/developer/sev.html, 2020
AMD. AMD secure encrypted virtualization (sev).http s://www.amd.com/en/developer/sev.html, 2020
work page 2020
-
[6]
Confidential inference via trusted virtual machines
Anthropic and Pattern Labs. Confidential inference via trusted virtual machines. https://www.anthropic. com/research/confidential-inference-trust ed-vms , June 2025. Research report on confidential inference systems using trusted virtual machines
work page 2025
-
[7]
ARM. ARM TrustZone for Cortex-A. https://ww w.arm.com/technologies/trustzone-for-corte x-a, 2004
work page 2004
-
[8]
Findings of the 2014 Workshop on Statistical Machine Translation
Ondrej Bojar et al. Findings of the 2014 Workshop on Statistical Machine Translation. InProceedings of the Ninth Workshop on Statistical Machine Translation, pages 12–58, Baltimore, Maryland, USA, June 2014. Association for Computational Linguistics
work page 2014
-
[9]
TOCTOU, traps, and trusted comput- ing
Sergey Bratus et al. TOCTOU, traps, and trusted comput- ing. InInternational Conference on Trusted Computing, pages 14–32. Springer, 2008
work page 2008
-
[10]
Verifiable privacy and transparency: A new frontier for brave ai privacy
Brave Software. Verifiable privacy and transparency: A new frontier for brave ai privacy. https://brave. com/blog/browser-ai-tee/ , 11 2025. Accessed: 2025-11-26
work page 2025
-
[11]
Language Models are Few-Shot Learn- ers
Tom Brown et al. Language Models are Few-Shot Learn- ers. InAdvances in Neural Information Processing Sys- tems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020
work page 1901
-
[12]
Canonical TDX Github Repository
Canonical. Canonical TDX Github Repository. https: //github.com/canonical/tdx, September 2025
work page 2025
-
[13]
Marcin Chrapek et al. Confidential LLM inference: Performance and cost across CPU and GPU TEEs.arXiv preprint arXiv:2509.18886, 2025
-
[14]
Incremental multiset hash functions and their application to memory integrity checking
Dwaine Clarke et al. Incremental multiset hash functions and their application to memory integrity checking. In International conference on the theory and application of cryptology and information security, pages 188–207. Springer, 2003
work page 2003
-
[15]
Michael Han Daniel Han and Unsloth team. Unsloth. https://github.com/unslothai/unsloth, 2023
work page 2023
-
[16]
Attesting distributional properties of training data for machine learning
Vasisht Duddu et al. Attesting distributional properties of training data for machine learning. InEuropean Symposium on Research in Computer Security, pages 3–23. Springer, 2024
work page 2024
-
[17]
Lamina- tor: Verifiable ml property cards using hardware-assisted attestations
Vasisht Duddu, Lachlan J Gunn, and N Asokan. Lamina- tor: Verifiable ml property cards using hardware-assisted attestations. InProceedings of the Fifteenth ACM Con- ference on Data and Application Security and Privacy, pages 317–328, 2024
work page 2024
-
[18]
Proof-of-learning is currently more broken than you think
Congyu Fang et al. Proof-of-learning is currently more broken than you think. In2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P), pages 797–816. IEEE, 2023
work page 2023
-
[19]
Secure and confidential certifi- cates of online fairness
Olive Franzese et al. Secure and confidential certifi- cates of online fairness. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[20]
Secure noise sampling for differ- entially private collaborative learning
Olive Franzese et al. Secure noise sampling for differ- entially private collaborative learning. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 4649–4663, 2025
work page 2025
-
[21]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao et al. The Pile: An 800GB Dataset of Di- verse Text for Language Modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[22]
Leo Gao et al. The Language Model Evaluation Harness. https://zenodo.org/records/12608602 , July 2024
-
[23]
Experimenting with zero-knowledge proofs of training
Sanjam Garg et al. Experimenting with zero-knowledge proofs of training. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS ’23, page 1880–1894, New York, NY , USA, 2023. Association for Computing Machinery
work page 2023
-
[24]
Jinnan Guo et al. ExclaveFL: Providing transparency to federated learning using exclaves.arXiv preprint arXiv:2412.10537, 2024
-
[25]
General avail- ability: Azure confidential VMs with NVIDIA H100 tensor core GPUs, 2024
Krishnaprasad Hande and Microsoft team. General avail- ability: Azure confidential VMs with NVIDIA H100 tensor core GPUs, 2024
work page 2024
-
[26]
Casper Hansen. AutoAWQ. https://github.com/c asper-hansen/AutoAWQ, 2023. 14
work page 2023
-
[27]
Measuring Massive Multitask Language Understanding
Dan Hendrycks et al. Measuring Massive Multitask Language Understanding. InICLR. OpenReview.net, 2021
work page 2021
-
[28]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models. InNeurIPS, 2020
work page 2020
- [29]
-
[30]
Yaqi Hu et al. LLM-based misbehavior detection ar- chitecture for enhanced traffic safety in connected au- tonomous vehicles.IEEE Transactions on Vehicular Technology, 2025
work page 2025
-
[31]
zkMLaaS: a verifiable scheme for machine learning as a service
Chenyu Huang et al. zkMLaaS: a verifiable scheme for machine learning as a service. InGLOBECOM 2022- 2022 IEEE Global Communications Conference, pages 5475–5480. IEEE, 2022
work page 2022
-
[32]
Hugging Face. Datasets Arrow. https://huggingfac e.co/docs/datasets/v4.1.1/about_arrow , 2025. Accessed: 2025-10-01
work page 2025
-
[33]
Hugging Face. Preprocess. https://huggingface.co /docs/datasets/en/use_dataset, 2025. Accessed: 2025-01-19
work page 2025
-
[34]
Hugging Face. Trainer. https://huggingface.co/d ocs/transformers/main_classes/trainer#tran sformers.Trainer.get_train_dataloader , 2025. Accessed: 2025-01-15
work page 2025
-
[35]
Intel Provisining Certification Service for ECDSA Attestation
Intel. Intel Provisining Certification Service for ECDSA Attestation. https://api.portal.trustedservic es.intel.com/provisioning-certification
-
[36]
Intel Software Guard Extensions (Intel SGX)
Intel. Intel Software Guard Extensions (Intel SGX). https://www.intel.com/content/www/us/en/de veloper/tools/software-guard-extensions/ov erview.html, 2015
work page 2015
-
[37]
Intel Trust Domain Extensions (Intel TDX)
Intel. Intel Trust Domain Extensions (Intel TDX). ht tps://www.intel.com/content/www/us/en/deve loper/tools/trust-domain-extensions/overvi ew.html, 2023
work page 2023
-
[38]
Intel Trust Domain Extensions (Intel TDX) mod- ule base architecture specification
Intel. Intel Trust Domain Extensions (Intel TDX) mod- ule base architecture specification. https://cdrdv2 -public.intel.com/853286/intel-tdx-module-b ase-spec-348549006.pdf, Apr 2025
work page 2025
-
[39]
Heterogeneous isolated execution for commodity GPUs
Insu Jang et al. Heterogeneous isolated execution for commodity GPUs. InProceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 455–468, 2019
work page 2019
-
[40]
ARM Limited. Overview: Realms. https://learn. arm.com/learning-paths/servers-and-cloud-c omputing/cca-container/overview/
-
[41]
zkCNN: Zero knowledge proofs for convolutional neural net- work predictions and accuracy
Tianyi Liu, Xiang Xie, and Yupeng Zhang. zkCNN: Zero knowledge proofs for convolutional neural net- work predictions and accuracy. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Com- munications Security, pages 2968–2985, 2021
work page 2021
-
[42]
MirrorNet: A TEE-friendly frame- work for secure on-device DNN inference
Ziyu Liu et al. MirrorNet: A TEE-friendly frame- work for secure on-device DNN inference. In2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), pages 1–9. IEEE, 2023
work page 2023
-
[43]
Holding secrets accountable: Au- diting privacy-preserving machine learning
Hidde Lycklama et al. Holding secrets accountable: Au- diting privacy-preserving machine learning. InUSENIX Security Symposium, 2024
work page 2024
-
[44]
PEFT: State-of-the-art Parameter-Efficient Fine-Tuning methods
Sourab Mangrulkar et al. PEFT: State-of-the-art Parameter-Efficient Fine-Tuning methods. https: //github.com/huggingface/peft, 2022
work page 2022
-
[45]
DarkneTZ: towards model privacy at the edge using trusted execution environments
Fan Mo et al. DarkneTZ: towards model privacy at the edge using trusted execution environments. InInterna- tional Conference on Mobile Systems, Applications, and Services, MobiSys ’20, page 161–174, New York, NY , USA, 2020. Association for Computing Machinery
work page 2020
-
[46]
Toward remotely verifiable software integrity in resource-constrained iot devices
Ivan De Oliveira Nunes et al. Toward remotely verifiable software integrity in resource-constrained iot devices. IEEE Communications Magazine, 62(7):58–64, 2024
work page 2024
-
[47]
AI Security With Confidential Computing
NVIDIA. AI Security With Confidential Computing. https://www.nvidia.com/en-us/data-center/ solutions/confidential-computing/
-
[48]
NVIDIA Deployment Guide for SecureAI
NVIDIA. NVIDIA Deployment Guide for SecureAI. https://docs.nvidia.com/cc-deployment-gui de-tdx.pdf, February 2025
work page 2025
-
[49]
NVIDIA. NVIDIA attestation. https://docs.nvidi a.com/attestation/index.html, [Accessed] 2025
work page 2025
-
[50]
Reimagining secure infrastructure for ad- vanced ai
OpenAI. Reimagining secure infrastructure for ad- vanced ai. https://openai.com/index/reimagini ng-secure-infrastructure-for-advanced-ai/ , 5 2024. Accessed: 2025-11-26
work page 2024
-
[51]
torch.utils.data — PyTorch 2.9 documentation
PyTorch. torch.utils.data — PyTorch 2.9 documentation. https://docs.pytorch.org/docs/stable/data. html, 2025. Accessed: 2026-01-15
work page 2025
-
[52]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019. 15
work page 2019
-
[53]
Norrathep Rattanavipanon and Ivan De Oliveira Nunes Nunes. SLAPP: Poisoning prevention in federated learn- ing and DP via stateful proofs of execution.IEEE Trans- actions on Information Forensics and Security (TIFS), 2025
work page 2025
-
[54]
Siva Reddy, Danqi Chen, and Christopher D. Manning. CoQA: A conversational question answering challenge. Transactions of the Association for Computational Lin- guistics, 7:249–266, 2019
work page 2019
-
[55]
A stochastic ap- proximation method.The annals of mathematical statis- tics, pages 400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic ap- proximation method.The annals of mathematical statis- tics, pages 400–407, 1951
work page 1951
-
[56]
ZK- LoRA: Efficient zero-knowledge proofs for LoRA veri- fication
Bidhan Roy, Peter Potash, and Marcos Villagra. ZK- LoRA: Efficient zero-knowledge proofs for LoRA veri- fication. InChampioning Open-source DEvelopment in ML Workshop @ ICML25, 2025
work page 2025
-
[57]
Property- based attestation for computing platforms: caring about properties, not mechanisms
Ahmad-Reza Sadeghi and Christian Stüble. Property- based attestation for computing platforms: caring about properties, not mechanisms. InProceedings of the 2004 workshop on New security paradigms, pages 67–77, 2004
work page 2004
-
[58]
Vinnie Scarlata et al. Supporting third party attestation for Intel SGX with Intel data center attestation primi- tives.White paper, 12, 2018
work page 2018
-
[59]
Attestable audits: Verifiable AI safety benchmarks using trusted execution environ- ments
Christoph Schnabl et al. Attestable audits: Verifiable AI safety benchmarks using trusted execution environ- ments. InICML Workshop on Technical AI Governance (TAIG), 2025
work page 2025
-
[60]
Confidential-PROFITT: Confidential PROof of fair training of trees
Ali Shahin Shamsabadi et al. Confidential-PROFITT: Confidential PROof of fair training of trees. InThe Eleventh International Conference on Learning Repre- sentations, 2023
work page 2023
-
[61]
Confidential-DPproof: Confidential proof of differentially private training
Ali Shahin Shamsabadi et al. Confidential-DPproof: Confidential proof of differentially private training. In The Twelfth International Conference on Learning Rep- resentations, 2024
work page 2024
-
[62]
Marcin Spoczynski, Marcela S. Melara, and Sebastian Szyller. Atlas: A framework for ML lifecycle prove- nance & transparency. In2025 IEEE European Sympo- sium on Security and Privacy Workshops (EuroS&PW), pages 448–461. IEEE, 2025
work page 2025
-
[63]
zkLLM: Zero knowledge proofs for large language models
Haochen Sun, Jason Li, and Hongyang Zhang. zkLLM: Zero knowledge proofs for large language models. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 4405– 4419, 2024
work page 2024
-
[64]
TensorShield: Safeguarding on-device inference by shielding critical DNN tensors with TEE
Tong Sun et al. TensorShield: Safeguarding on-device inference by shielding critical DNN tensors with TEE. InACM SIGSAC Conference on Computer and Commu- nications Security (CCS), 2025
work page 2025
-
[65]
Rohan Taori et al. Stanford Alpaca: An instruction- following llama model.https://github.com/tatsu -lab/stanford_alpaca, 2023
work page 2023
-
[66]
Gemma Team. Gemma 3 Technical Report.CoRR, abs/2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Llama Team. The Llama 3 Herd of Models.CoRR, abs/2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Slalom: Fast, verifi- able and private execution of neural networks in trusted hardware
Florian Tramer and Dan Boneh. Slalom: Fast, verifi- able and private execution of neural networks in trusted hardware. InInternational Conference on Learning Representations, 2019
work page 2019
-
[69]
Ehsan Ullah et al. Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology–a recent scoping review.Diagnostic pathology, 19(1):43, 2024
work page 2024
-
[70]
Attention is all you need.Ad- vances in neural information processing systems, 30, 2017
Ashish Vaswani et al. Attention is all you need.Ad- vances in neural information processing systems, 30, 2017
work page 2017
-
[71]
Yangyang Yu et al. Fincon: A synthesized LLM multi- agent system with conceptual verbal reinforcement for enhanced financial decision making.Advances in Neural Information Processing Systems, 37:137010–137045, 2024
work page 2024
-
[72]
Rui Zhang et al. “Adversarial examples” for proof-of- learning. In2022 IEEE Symposium on Security and Privacy (SP), pages 1408–1422. IEEE, 2022
work page 2022
-
[73]
No privacy left outside: On the (in-) security of TEE-shielded DNN partition for on-device ML
Ziqi Zhang et al. No privacy left outside: On the (in-) security of TEE-shielded DNN partition for on-device ML. In2024 IEEE Symposium on Security and Privacy (SP), pages 3327–3345. IEEE, 2024
work page 2024
-
[74]
Yukun Zhu et al. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. InProceedings of the IEEE international conference on computer vision, pages 19–27, 2015. 16 A Operations and Properties in PAL ∗M Table 7 describes supported operations in PAL∗M and result- ing property attestations. Table 7: Operation...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.