RubberDuckBench: A Benchmark for AI Coding Assistants
Pith reviewed 2026-05-16 12:13 UTC · model grok-4.3
The pith
Even the best AI coding assistants fail to provide consistent correct answers on a benchmark of real GitHub pull request questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
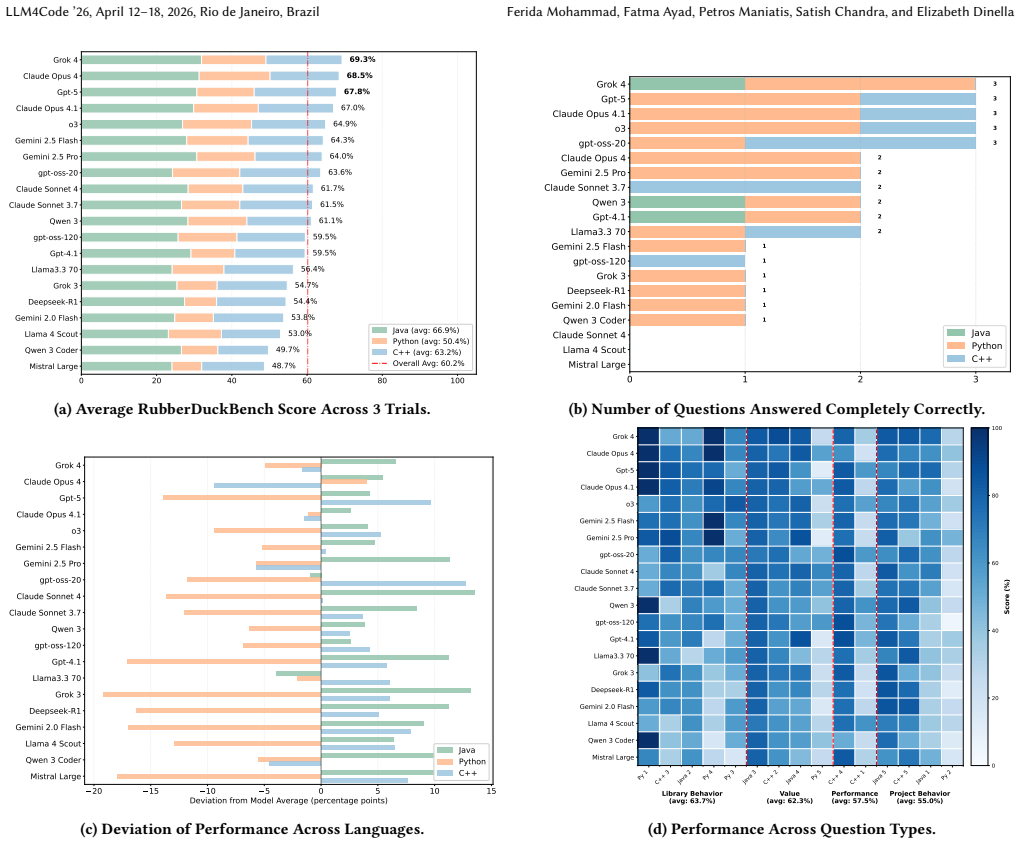
RubberDuckBench is a multilingual collection of contextualized questions about code drawn from GitHub pull request comments, together with rubrics for evaluating answers. Evaluation of twenty LLMs finds that even the highest-scoring models (Grok 4 at 69.29 percent, Claude Opus 4 at 68.5 percent, GPT-5 at 67.8 percent) show no statistically significant advantage over the next nine models, earn most credit through partial answers, fully solve at most two questions per model across trials, and hallucinate incorrect statements in 58.3 percent of responses on average, with no correlation between performance and expense.
What carries the argument
RubberDuckBench, a benchmark of real-world code questions extracted from GitHub pull request comments together with detailed evaluation rubrics.
If this is right
- Top models do not show pairwise statistically significant superiority over the next nine best models.
- Even the strongest models fully answer at most two questions correctly across all trials.
- Models produce hallucinations in 58.3 percent of responses on average.
- No correlation exists between model performance and either API price or parameter count.
Where Pith is reading between the lines
- Benchmarks focused on full correctness rather than partial credit may better expose reliability gaps.
- High hallucination rates suggest current systems need built-in verification steps for code-related answers.
- Developers relying on AI assistants for code questions should routinely check outputs against source material.
Load-bearing premise
The questions taken from GitHub pull request comments are representative of the kinds of questions programmers typically ask AI coding assistants.
What would settle it
An experiment in which a new model achieves scores above 80 percent and at least ten fully correct answers across repeated trials on an expanded set of similar pull-request questions would challenge the reported performance limits.
Figures




read the original abstract
Programmers are turning to AI coding assistants to answer questions about their code. Benchmarks are needed to soundly evaluate these systems and understand their performance. To enable such a study, we curate a benchmark of real-world contextualized questions derived from Github pull request comments. Out of this work, we present RubberDuckBench: a multilingual benchmark of questions about code, along with detailed rubrics for evaluating answers. We evaluate a diverse set of 20 LLMs (proprietary & open-source) on answering these questions. We find that even state of the art models fail to give consistent, correct responses across the benchmark. Grok 4 (69.29%), Claude Opus 4 (68.5%), and GPT-5 (67.8%) perform best overall, but do not exhibit pairwise significant superiority over the next 9 best performing models. Most models obtain points through partial credit, with the best performing models only answering at most 2 questions completely correctly across all trials. Furthermore, models often hallucinate with lies in 58.3\% of responses on average. Cost analysis reveals no correlation between expense (API pricing or parameter count) and performance. We intend this benchmark to be a target for future research in trustworthy and correct AI coding assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RubberDuckBench, a multilingual benchmark of real-world contextualized questions extracted from GitHub pull request comments, along with detailed rubrics for scoring. It evaluates 20 LLMs (proprietary and open-source) and reports that even top models achieve only 67-69% overall (Grok 4 at 69.29%, Claude Opus 4 at 68.5%, GPT-5 at 67.8%), with no pairwise significant superiority over the next nine models, most points earned via partial credit (at most two fully correct answers), an average hallucination rate of 58.3%, and no correlation between performance and cost or parameter count.
Significance. If the benchmark construction and scoring prove robust, the work supplies a practical, reproducible target for improving trustworthy AI coding assistants and documents concrete limitations in current systems on contextualized queries. The absence of a cost-performance link is a useful empirical observation for practitioners.
major comments (3)
- [§3] §3 (Benchmark Curation): The central claim that PR-comment questions are representative of typical programmer-AI interactions lacks supporting evidence such as distributional comparisons to IDE telemetry, Stack Overflow threads, or usage logs. This assumption is load-bearing for the reported scores and 58.3% hallucination rate; without it, generalizability remains unverified.
- [§4] §4 (Rubric and Scoring): The manuscript provides insufficient detail on rubric construction, inter-rater reliability statistics, and the exact criteria for awarding partial credit. Given that the headline result rests on aggregate scores driven largely by partial credit, these omissions prevent full assessment of scoring objectivity.
- [§5] §5 (Statistical Claims): The statement that the top three models show no pairwise significant superiority over the next nine requires explicit reporting of the test used, degrees of freedom, and adjusted p-values. The current presentation leaves the non-significance claim difficult to evaluate.
minor comments (2)
- [Abstract] Abstract and §5: The phrase 'hallucinate with lies' should be replaced by a precise operational definition of hallucination (e.g., factual fabrication vs. unsupported inference) to avoid ambiguity.
- [Tables] Tables: Ensure consistent formatting of model names, confidence intervals, and trial counts across all result tables and the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Curation): The central claim that PR-comment questions are representative of typical programmer-AI interactions lacks supporting evidence such as distributional comparisons to IDE telemetry, Stack Overflow threads, or usage logs. This assumption is load-bearing for the reported scores and 58.3% hallucination rate; without it, generalizability remains unverified.
Authors: We acknowledge that the manuscript does not contain explicit distributional comparisons against IDE telemetry, Stack Overflow, or usage logs. The choice of GitHub PR comments was driven by their status as naturally occurring, context-rich questions arising during code review, a setting that frequently involves programmer-AI interaction. In the revision we will add a new subsection under §3 that (a) articulates this rationale, (b) explicitly states the absence of comparative distributional data, and (c) discusses the resulting limitations on generalizability together with concrete suggestions for future validation work. We do not claim the benchmark is universally representative; we present it as a reproducible target for contextualized coding queries. revision: partial
-
Referee: [§4] §4 (Rubric and Scoring): The manuscript provides insufficient detail on rubric construction, inter-rater reliability statistics, and the exact criteria for awarding partial credit. Given that the headline result rests on aggregate scores driven largely by partial credit, these omissions prevent full assessment of scoring objectivity.
Authors: We agree that the current description is insufficient. The revised manuscript will expand §4 with: (1) the iterative process by which the rubrics were constructed and refined by the author team, (2) inter-rater reliability statistics (Cohen’s kappa) computed on a held-out subset of responses scored independently by two annotators, and (3) the precise decision rules used for partial credit (e.g., awarding credit for correctly locating the relevant code region or identifying the core defect even when a complete fix is not supplied). These additions will make the scoring procedure fully auditable. revision: yes
-
Referee: [§5] §5 (Statistical Claims): The statement that the top three models show no pairwise significant superiority over the next nine requires explicit reporting of the test used, degrees of freedom, and adjusted p-values. The current presentation leaves the non-significance claim difficult to evaluate.
Authors: We will revise §5 to report the full statistical procedure: pairwise Wilcoxon rank-sum tests with Bonferroni correction for the 12 relevant comparisons, including test statistics, degrees of freedom, and adjusted p-values. The revised text will also include a brief justification for the choice of non-parametric test given the score distributions. revision: yes
Circularity Check
No circularity: direct empirical benchmark evaluation
full rationale
The paper curates questions from GitHub PR comments and runs direct LLM evaluations with rubrics, reporting accuracy, partial credit, hallucination rates, and cost correlations. No equations, fitted parameters, predictions, uniqueness theorems, or self-citation chains exist. All results follow from the test outcomes on the fixed dataset; the derivation chain is empty and self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pull request comments on GitHub represent typical questions programmers ask AI coding assistants
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
2025. Claude Opus 4.1. https://www.anthropic.com/news/claude-opus-4-1
work page 2025
- [4]
-
[5]
2025. Cursor. https://cursor.com/. Accessed: 2025-10-10
work page 2025
-
[6]
2025. Gemini 2.5 Flash. https://deepmind.google/models/gemini/flash/
work page 2025
- [7]
-
[8]
2025. GitHub Copilot. https://github.com/features/copilot. Accessed: 2025-10-10
work page 2025
-
[9]
2025. gpt-4.1. https://platform.openai.com/docs/models/gpt-4.1
work page 2025
-
[10]
2025. gpt-5. https://openai.com/index/introducing-gpt-5. Accessed: 2025-10-10
work page 2025
-
[11]
2025. gpt-oss-120b. https://platform.openai.com/docs/models/gpt-oss-120b
work page 2025
- [12]
-
[13]
2025. Grok 3. https://x.ai/news/grok-3. Accessed: 2025-10-10
work page 2025
-
[14]
2025. Grok 4. https://x.ai/news/grok-4. Accessed: 2025-10-10
work page 2025
-
[15]
2025. Kiro. https://kiro.dev/. Accessed: 2025-10-10
work page 2025
- [16]
-
[17]
2025. llama-4. https://www.llama.com/models/llama-4/. Accessed: 2025-10-10
work page 2025
-
[18]
2025. Mistral. https://mistral.ai/news/mistral-large. Accessed: 2025-10-10
work page 2025
-
[19]
2025. o3. https://platform.openai.com/docs/models/o3. Accessed: 2025-10-10
work page 2025
-
[20]
2025. Tabnine. https://www.tabnine.com/. Accessed: 2025-10-10
work page 2025
-
[21]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program Synthesis with Large Language Models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavar...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Ria Galanos, Timothy Gallagher, and Briana Morrison. 2019. An Afternoon with an AP Computer Science A Exam Reader. InProceedings of the 50th ACM Technical Symposium on Computer Science Education(Minneapolis, MN, USA) (SIGCSE ’19). Association for Computing Machinery, New York, NY, USA, 1242. doi:10.1145/3287324.3287549
-
[25]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [26]
- [27]
-
[28]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. 2021. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understan...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Elise Paradis, Kate Grey, Quinn Madison, Daye Nam, Andrew Macvean, Vahid Meimand, Nan Zhang, Ben Ferrari-Church, and Satish Chandra. 2024. How much does AI impact development speed? An enterprise-based randomized controlled trial. arXiv:2410.12944 [cs.SE] https://arxiv.org/abs/2410.12944
-
[30]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2025. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. arXiv:2402.07927 [cs.AI] https: //arxiv.org/abs/2402.07927
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [31]
-
[32]
Patrick E Shrout and Joseph L Fleiss. 1979. Intraclass correlations: uses in assess- ing rater reliability.Psychological Bulletin86, 2 (1979), 420–428
work page 1979
- [33]
-
[34]
Stack Overflow. 2025. Stack Overflow Developer Survey 2025. https://survey. stackoverflow.co/2025/. Accessed: 10-06-2025
work page 2025
- [35]
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agar- wal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 248...
work page 2022
- [37]
- [38]
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [40]
- [41]
- [42]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.